






这是本人的期末大作业,题目要求如下:
对中国大学专业排名网站中2021年,计算机科学与技术专业,进行数据爬取和数据可视化。
URL地址:https://www.shanghairanking.cn/rankings/bcmr/2021/080901
设计要求:
使用requests库中的get方法获取网页。
提取出该专业的前15所大学的数据(排名、学校名称、总分),并保存到sqlite数据库。
使用matplotlib库绘制柱状图,实现数据可视化。
需求分析
首先对我们要爬取的页面进行分析,网页的URL地址为:https://www.shanghairanking.cn/rankings/bcmr/2021/080901,我们首先看看他的源代码如下图所示

单个大学的信息封装在 <div class="univ-item" data-v-4b3c74f3="">里面。
其中,排名信息在 <div class="rank-box" data-v-4b3c74f3="" style="width:60px">中。
大学信息在 <div class="univ-box" data-v-4b3c74f3=""style="width:565px">中。
最终确定我们要筛选的为:
Tag = 'div', attrs = 'ranking'图中绿色圆圈表示。
Tag = 'a', attrs = 'name-cn'图中蓝色圆圈表示。
Tag = 'div', attrs = 'score'图中黑色圆圈表示name-cn。
- 需要提取网页中有用的数据。
- 然后存入sqlite数据库
- 对sqlite中的数据进行可视化输出
- 需要加限制条件只爬取排名前15的学校。
- 设计sqlite数据库,创建包含排名、姓名、总分三列的表存取数据。
- 需要把学校名和总分进行柱形图可视化输出。
总体设计
通过主调函数按顺序调用如下函数:
- 使用getHTMLText()爬取内容,并返回给主调函数。
- 使用fillUnivList()把爬取成功的数据进行筛选分析出有用的数据。
- 使用init_db()函数把fillUnivList()处理好的数据保存到sqlite数据库中。
- 使用view()函数把可视化的数据从sqlite中提取出来进行柱形图可视化。
- 程序流程图如下

- 详细设计
- 导入所需要用到的库函数:使用requests函数对网页进行数据爬取、使用BeautifulSoup库对网页进行分析、matplotlib库函数绘图、导入sqlite3内置模块对数据进行读取。
- 编写主调用函数:分别建立三个列表,uinfo用于存取fillUnivList()函数所筛选出的信息,unifo1用于存取学校的名字、uinfo2用于保存学校的排名。编写一个html变量用来保存getHTMLText()函数返回的信息。最后通过一个if语句判断是否该继续执行其他函数调用,分别是fillUnivList()对数据解析、init_db函数对数据读取、view函数绘图。
- 首先调用getHTMLText()函数对网页进行爬取,并设置请求超时时间为30S,将爬取到的数据格式改为UTF-8格式。爬取成功则返回页面内容并保存到主调程序的html变量,爬取失败则返回0,在主调函数终止整个程序的执行。
- 爬取成功后主调程序再把html保存的数据通过调用fillUnivList()函数解析筛选出有用的数据。1、把uinfo列表作为参数传给fillUnivList()函数用于保存学校的有用信息。2、用包含网页内容的字符串来创建Beautifulsoup对象soup。3、遍历univ-ite标签,获得前15大学信息,然后在ranking标签中获得每个大学排名信息,在name-cn标签中获得每个大学校名信息,最后在score标签里获得大学的总分,把我们需要的相关数据通过主函数传过来的参数列表ulist列表保存。
- 通过前面一步已经得到筛选过的数据的列表uinfo,在主调函数中把uinfo列表和新建uinfo1、uinfo2两个空列表(作为单独保存校名和总分的列表)作为参数通过init_db()函数在数据库读写:1、新建好数据库,把保存学校信息通过ulist列表存进sqlite数据库中。2、数据存入数据库之后通过遍历查询数据库,并在查询过程中把查询出的校名和总分放进uinfo1和uinfo2列表保存用于返回给主调程序使用。
- 最后一步是在主调函数中把init_db()函数返回来的,保存有校名和总分的uinfo1和uinfo2两个列表作为参数,通过view()函数读取进行数据可视化,通过matplotlib库里的功能绘制图表,用保存有学校名的uinfo1列表作为x轴,保存有学校总分的uinfo2列表作为Y轴。最后完美输出试图,程序完美运行。
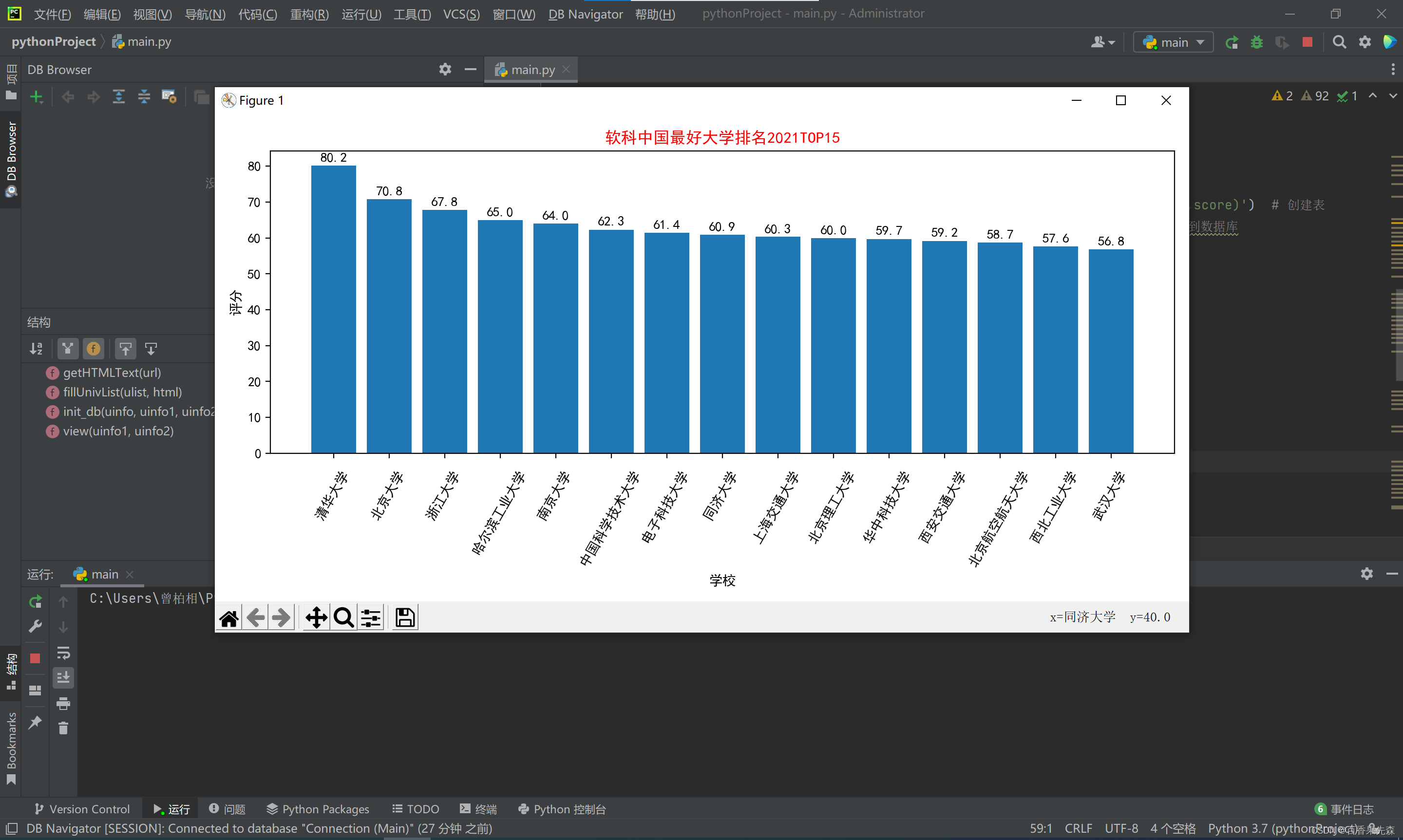
程序运行结果测试与分析
程序运行显示结果,对数据进行可视化输出
在pycharm中查询sqlite数据库中的信息

详细代码如下
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import matplotlib as mpl
import sqlite3
'''
getHTMLText函数是获取url的信息,如果获取时间超过30S则超时
获取成功返回一个r.txt文档,
失败则返回HTMLerror
'''
def getHTMLText(url): # 获取URL信息,返回html内容
try:
r = requests.get(url, timeout=30)#获取网页,并设置请求超时的时间为30s
r.raise_for_status() #返回请求后的状态
r.encoding = 'UTF-8' #更改为UTF-8格式
return r.text
except:
return 0
'''
fillUnivList函数的作用是把getHTMLText爬取到的数据进行解析,提取网页内容中信息到合适的数据结构.
把学校排名、校名和总分筛选出来,存到列表ulist中、分别把分数和校名分别独立
存到ulist1、ulist2这两个列表之中
'''
def fillUnivList(ulist, html): # 将提取的html信息放在列表ulist,ulist1,ulist2中
i=0;
soup = BeautifulSoup(html, 'html.parser')#使用包含网页内容的字符串来创建Beautifulsoup对象
# print(soup.find('div', attrs='body-container').prettify())
for div in soup.find_all('div', attrs='univ-item'):#使用遍历方法查找所需信息
if(i==15): #只爬取15条数据
break;
ranking = int(div.find('div', attrs='ranking').string) #把排名信息存入变量
name = div.find('a', attrs='name-cn').string #把学校名字存入变量
score = float(div.find('div', attrs='score').string) #把分数存入变量r.raise_for_status()
ulist.append((ranking,name,score)) #所有保存到列表list
i=i+1
'''
init_db函数功能是创建一个数据库,创建游标、创建表
把fillUnivList函数解析完,筛选出来的数据保存到数据库之中
'''
def init_db(uinfo,uinfo1,uinfo2):
date='C:/etc/ranking.db'# 建立数据库
con=sqlite3.connect(date)#连接到date数据库
cur= con.cursor() # 游标对象
cur.execute('create table IF NOT exists schoolRanking(ranking,name primary key,score)') # 创建表
cur.executemany('insert or ignore into schoolRanking values(?,?,?)',uinfo)#保存到数据库
for row in cur.execute("select * from schoolRanking"): #遍历数据库
uinfo1.append(row[1]) #将校名保存到列表
uinfo2.append(row[2]) #将总分保存到列表
#cur.execute("delete from schoolRanking") #删除表
con.commit() # 提交
cur.close() #关闭
con.close() # 关闭
'''
view函数的功能是把保存有学校名和学校总分对应的分数这两个列表
进行数据可视化
'''
def view(uinfo1,uinfo2): #可视化函数
plt.figure(figsize=(10, 5)) # 创建图表
plt.bar(uinfo1, uinfo2) # 引用2个列表来绘制条形图
plt.title("软科中国最好大学排名2021TOP15", color="red") #打印标题
plt.ylabel("评分") #y轴标题打印
plt.xlabel("学校") # y轴标题打印
plt.xticks(rotation=60) # x学校名字旋转60°
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 解决符号乱码问题
plt.tight_layout() #删除空白
for x, y in enumerate(list(uinfo2)): #遍历Y轴分数,打印显示每条柱形图显示分数
plt.text(x, y + 1, '%s' % round(y, 1), ha='center')
pass
plt.show()
if __name__ == '__main__':
uinfo = [] #保存学校信息
uinfo1 = [] #保存学校名字
uinfo2 = [] #保存学校排名
url = 'https://www.shanghairanking.cn/rankings/bcmr/2021/080901'#软科网址
html = getHTMLText(url) #调用爬取网页信息函数
if (html):
fillUnivList(uinfo,html) #对爬取到的数据解析
init_db(uinfo,uinfo1,uinfo2) #调用数据库函数进行读写数据
view(uinfo1,uinfo2) #调用函数用matplotlib画出可视化















 4429
4429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









