







学习网络爬虫不仅需要python基础,还需要对网络、HTTP、网页、爬虫原理等有一个全方位的认识。然鹅很多大佬的文章都是直接讲库和代码,对于非计算机专业、网页零基础的本菜鸟来说,真的是一头雾水。所以还是乖乖刨了本书来补些基础,这篇文章就作为自己的入门笔记啦。边学边粗糙记录一下。
1 爬虫基础
目录
(14条消息) DOM节点关系及基本操作_dckong的博客-CSDN博客
1.1 HTTP基本原理
参考:(14条消息) HTTP基本原理(简介)_Robin Hu的专栏-CSDN博客_http原理
在了解HTTP之前,科普一些名词:
1.1.1 URI和URL
URL是统一资源定位器,用于标识资源;URI(统一资源标识符)提供了更简单和可扩展的标识资源的方法。
(14条消息) URI和URL的区别比较与理解_小猛同学的博客-CSDN博客_uri
1.1.2 超文本
浏览器中的网页是由超文本(Hypertext)解析而成,网页源代码是一系列HTML代码,这些源代码HTML就被称为超文本。
1.1.3 HTTP和HTTPS
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议,它能保证高效而准确地传送超文本文档。
HTTPS(超文本安全传输协议),是在普通的HTTP下加入TLS(传输层安全协议),是HTTP的安全版。
1.1.4 HTTP请求过程

在浏览器输入URL,回车; 打开浏览器开发者模式下的Network监听组件(Ctrl+Shift+I,打开开发者选项,单击“Network”),可以看到Request和Response的信息。呕吼,没接触过网页的人感觉进入了新世界。里面Response Headers 和 Request Headers分别代表响应头和请求头,信息太多,看不懂呢,总之浏览器接收Response之后会解析里面的内容,生成网页内容。
1.1.5 请求
一个Request可划分为4部分:Request Method、Request URL(请求URL地址)、Request
Headers、Request Body
- Request Method:常见的有2种;GET和POST
GET:在浏览器中直接输入RUL,回车,就发起了一个GET请求
POST:大多为表单提交发起的请求,其数据常以表单形式传输,不会体现在URL中,也较为安全。
- Request URL:唯一确定我们想要的资源
Request Headers:用来说明服务器要使用的附加信息。是Request的重要组成部分,在爬虫时常常要设置请求头。HTTP常用头部信息 - 张啊咩 - 博客园 (cnblogs.com)
其中,在爬虫时要加上UA,可以伪装成浏览器。
- Request Body:一般承载的是POST请求中的表单数据,如果是GET请求则为空。
1.1.6响应
(14条消息) HTTP响应_liuurick的博客-CSDN博客_http响应
Response Body非常重要,是响应的正文数据,如请求一个网页,它的响应是网页的HTML代码;请求一张图片,则是图片的二进制数据。也是爬虫执行时主要解析的内容。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)
TCP : Transmission Control Protocol 传输控制协议和IP: Internet Protocol 网际协议。
HTML(Hyper Text Markup Language,即超文本标记语言)
1.2 网页基础
网站由若干网页组成,网页是构成整个网络的基石。
1.2.1 网页的组成
框架、文本、超链接、表单、
图片(一般为JPG和GIF格式,即后缀为.jpg和.gif的文件)
(英文输入法怎么又变成了这个样子,额这怎么调?~_~)
表格(网页排版的灵魂,HTML语言的一种元素)、
动画、其他(广告、字幕、音视频等)

(这个动画,看起来很好玩,又心动了~~)
1.2.2 网页的结构
(14条消息) HTML文档的基本结构_ks795820的博客-CSDN博客_html文档的基本结构
CTRL+U查看网页源代码
![挠头表情包 [蘑菇头挠头 排队挠头 根本停不下来]](https://img-blog.csdnimg.cn/img_convert/09cc6e57118ac51a05b75ed3b4dca7de.gif)
1.2.3 节点树及节点间的关系
(14条消息) DOM节点关系及基本操作_dckong的博客-CSDN博客
1、DOM节点树
文档对象模型(Document Object Model)是javascript操作网页的接口。
DOM节点树体现了文档的层次结构,有DOM文档节点树(包含文档中所有类型的节点)和DOM元素节点树(只包含元素节点)两种类型。
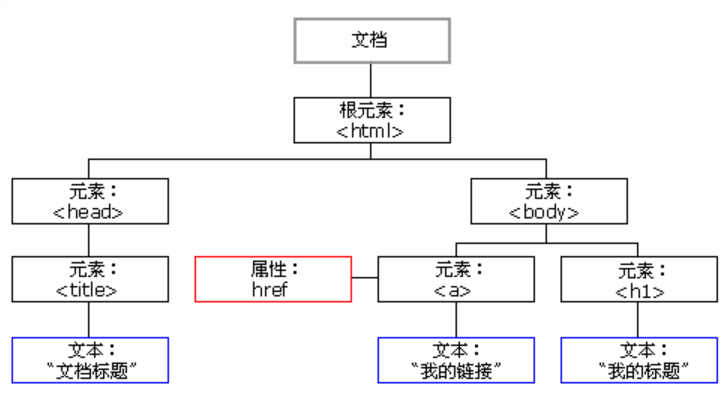
DOM提供的一些方法和属性可以实现遍历文档节点树.
首先来遍历所有Node节点。遍历DOM文档节点树的方法兼容所有浏览器。
- parentnode:获取父节
- chidnodes:获取所有子节点(包含元素节点和文本节点) firstchild:获取第一个子节点
- lastchild:获取最后一个子节点
- nextsibling:获取元素之后紧跟的节点 previoussibling:获取元素之前紧跟的节点
说明:可以使用 Javascript配合以上方法来获取相应的节点。
以下属性在遍历元素节点树时会使用到。只遍历元素节点,其余类型的节点忽略。除了 children方法外,其余方法在E8及以下版本的浏览器中都不兼容
parentelement:获取父元素children:获取所有子元素
childelementcount:获取子元素的数量firstelementchild:获取第一个子元素。
lastelementchild:获取最后一个子元素
nextelementsibling:获取元素后紧跟的元素 o
previouselementsibling:获取元素前紧跟的元素
下面演示如何使用演绎法获取一个元素的所有子结点
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<title>获取元素子节点</title>
</head>
<body>
<ul>
<li>子元素1</li>
<li>子元素2</li>
<li>子元素3</li>
<li>子元素4</li>
</ul>
<script language="javascript">
<!-- 获取标签“ul”元素 -->
obj=document.getElementsByTagName("ul")[0]
<!-- 通过children属性返回元素的所有子元素节点,即所有的“li” -->
lis=obj.children
num=lis.length
for(i=0;i<num;i++)
{
l=list[i]
alert(l.innerText)
}
</script>
</body>
</html>书上的代码,第一次写HTML,小兴奋

2、节点之间的关系
DOM将文档解析成一个由多层次节点组成的DOM结构,DOM节点包含12种类型,节点关系类似于家族关系,那节点数相当于家谱。
<html>
<head>
<title>DOM 教程</title>
</head>
<body>
<h1>DOM 第一课</h1>
<p>Hello world!</p>
</body>
</html>从上面的示例 HTML 代码中:
- <html> 节点没有父节点;它是根节点
- <head> 和 <body> 的父节点是 <html> 节点
- 文本节点 "Hello world!" 的父节点是 <p> 节点
并且:
- <html> 节点拥有两个子节点:<head> 和 <body>
- <head> 节点拥有一个子节点:<title> 节点
- <title> 节点也拥有一个子节点:文本节点 "DOM 教程"
- <h1> 和 <p> 节点是同胞节点,同时也是 <body> 的子节点
并且:
- <head> 元素是 <html> 元素的首个子节点
- <body> 元素是 <html> 元素的最后一个子节点
- <h1> 元素是 <body> 元素的首个子节点
- <p> 元素是 <body> 元素的最后一个子节点
只要清楚每个节点的结构是这种:<标签>内容</标签>结构就好了。看到一个<>就是一个节点,而且都是成对出现的,看到</>就表示这个节点结束。
节点的属性
(1)parentNode,父级属性。
每个节点都有,指向当前节点在节点树中的父节点。
(2)parentElement
指向父元素节点,IE浏览器中,只有元素节点有该属性,其他浏览器每个节点都有
(3)children子级属性
返回一个只读的NodeList集合(第一层子节点)
获取节点的父节点
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<title>获取元素父节点</title>
</head>
<body>
<div>
<strong></strong>
<span></span>
</div>
<script language="javascript">
var strong = document.getElementsByTagName("strong")[0];
console.log(strong.parentElement);
</script>
</body>
</html>
不知道为啥标题是乱码??
获取节点的子节点
<script language="javascript">
var div = document.getElementsByTagName("div")[0];
console.log(div.childNodes);
</script>
节点的方法
1. hasChildNodes()
判断当前节点是否包含子节点
2.contains(node)
判断node是否为当前节点的后代节点
1.2.4 选择器
(14条消息) DOM选择器_shi_1204的博客-CSDN博客
1.3爬虫的基本原理
1.3.1什么是爬虫
爬虫就是一段程序,这段程序的功能是从网络上采集需要的数据。
一个爬虫的工作流程:
1.发起请求
2.获取响应内容
3.解析内容
4.保存数据
爬虫也可以指完成这样一个流程的过程。
1.3.2能抓取什么样的数据
广义上只要能请求并且能获取响应的数据都能被抓取,具体包括:
(1)网页文本,如HTML文档、JSON、XML格式文本
(2)图片,JPEG、PNG等文件
(3)视频文件,MP4、WMV等文件
(4)其他
1.4会话和Cookies
爬虫基础——会话和Cookie - 知乎 (zhihu.com)














 7166
7166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









