







提示:以下是本篇文章正文内容,下面案例可供参考
1、基本术语和概念
(2条消息) 模型评估与优化1--基本概念与最优化问题_qiaoqiaomanman的博客-CSDN博客
简单理解,训练集用来生成模型,验证集是用来调参生成准确模型的,测试集则是用生成的模型来进行预测、评估训练好的模型的性能的。其中,验证集在实际项目中不是必须的。一般三种按6:2:2划分。
2、最优化模型
2.1 最优化模型的概述
(2条消息) 【数学建模】最优化模型_二进制 人工智能的博客-CSDN博客_最优化模型
最优化是数学建模的本质问题。注意:目标函数必须是凸函数,才能保证后续获得的最优结果是全局最优而不是局部最优,否则要进行凸优化。
2.2凸优化
凸优化笔记10:凸优化问题 - 知乎 (zhihu.com)

2.3损失函数

常见的损失函数(loss function)总结 - 知乎 (zhihu.com)
2.4最优化模型的分类(按约束条件)
- 无约束优化
- 解决方法:直接方法(费马定理);解析法(梯度下降法、牛顿法等)
- 无约束优化的应用:z

- 等式约束的优化。主要解决方法:消元法、拉格朗日乘子法
- 不等式约束的优化
含约束条件的优化问题要先用上述方法转化成无约束条件的优化问题。
3、模型评估与选择
- 数据集拆分
前面讲了训练、验证、测试三种数据集,数据集的划分方法见数据集划分方法 - 知乎 (zhihu.com)
常用的就是里面讲的留出法、交叉验证法、自助法。

独立同分布(iid,independently identically distribution)
最常用均方误差(mean square error,MSE)
python 方法:
MSE_1 = np.mean((y_test - prediction)**2)
print(MSE_1)
[out]:19.831323672063235使用sklearn.metrics模块: (metrics,度量)
from sklearn.metrics import mean_squared_error
MSE_2 = mean_squared_error(y_test,prediction)
print(MSE_2)
[out]:19.831323672063235
1.
在混淆矩阵中,错误率=(FP+FN)/(P+N) , 精度 =(TP+TN)/(P+N) ,错误率+精度=1
2.查准率(也叫精确度,precision)=TP/(TP+FP),
查全率(也叫召回率,recall)=TP/(TP+FN)
- recall:召回率=正确预测的个数(TP)/预测个数(TP+FN);人话也就是某个类别测试集中的总量,有多少样本预测正确了;
P和R是相互制约的
3.3f函数
若认为precision更重要,则增大系数
4.真正例率(TPR)=TP/(TP+FN)=TP/P=召回率
假正例率(FPR) = FP/(TN+FP)=FP/N
5.P-R曲线:以召回率R为横轴、以精确率P为纵轴
6.ROC曲线:以true positive rate 和 false positive rate为轴,取不同的threshold点画的线
7.AUC面积:ROC曲线下的面积,AUC越大证明分类的质量越好
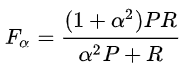
- 聚类模型评估

4、正则化
















 2741
2741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









