







LeNet5的结构比较简单,分类准确率只有50%左右。
ResNet属于中等规模复杂度的网络,性能比LeNet5会强大不少。
本例采用最简单的ResNet18模型,实现对CIFAR数据集的10分类。
还是按照之前的流程,分四步完成网络的搭建和训练。
编程过程中发现最好还是使用模块化编程,不然容易写bug出来。
代码如下:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import torch.optim as optim
from torch.nn import functional as F
import matplotlib.pyplot as plt
import time
# # 使用ResNet18网络训练CIFAR10数据集实现10分类
start = time.time()
# Step 1 : prepare dataset
batch_size = 32
cifar_train = datasets.CIFAR10("cifar", train=True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True) # 导入训练数据集 添加三个变换 第一个将图片裁剪至32*32大小;第二个将格式转变成tensor;第三个使用均值归一化,使数据均匀分布在0-1之间
cifar_train_loader = DataLoader(cifar_train, batch_size=batch_size, shuffle=True,) # 做打乱处理
cifar_test = datasets.CIFAR10("cifar", train=False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test_loader = DataLoader(cifar_test, batch_size=batch_size, shuffle=False, ) # 与上面相同,但测试集不需要打乱
# Step2: design model
# 先定义Res模块 res模块是残差神经网络中的残差运算单元
class ResBlock(nn.Module): # 同样继承至nn.Module
def __init__(self, ch_in, ch_out, stride=1):
super(ResBlock, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1) # stride对图片尺寸的大小有重要的影响
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out) # 两个卷积层 两个batchnorm
# shortcut 短接层
self.extra = nn.Sequential()
if ch_out != ch_in:
# let [b, ch_in, h, w] ----> [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride), # 此处的stride设置与conv1一样 保证大小一致 可以相加
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# extra shortcut
out = self.extra(x) + out
out = F.relu(out)
return out
# 再定义ResNet类
class ResNet(nn.Module):
def __init__(self):
super(ResNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
# follow 4 block
self.resblock = nn.Sequential(
ResBlock(64, 128, stride=2),
ResBlock(128, 256, stride=2),
ResBlock(256, 512, stride=2),
ResBlock(512, 512, stride=2), # 512是经验之谈 一般channel提升到512 同时图片尺寸需要减少
)
self.outlayer = nn.Linear(512, 10)
# 总的结构为:1个卷积[b, 3, 32, 32]-->[b, 64, 32, 32]+4个残差块[b, 64, 32, 32]-->[b, 512, 2, 2]+1个全连接层[b, 512]-->[b, 10]
# 4个残差块后还有一个全局池化的操作,实现[b, 512, 2, 2]-->[b, 512, 1, 1],并[b, 512, 1, 1]-->[b, 512*1*1]
def forward(self, x):
x = F.relu(self.conv1(x))
# [b, 64, h, w] ----> [b, 512, h, w]
x = self.resblock(x)
# print("after conv: ", x.shape) # [b, 512, 2, 2]
x = F.adaptive_max_pool2d(x, [1, 1]) # [b, 512, h, w] ---> [b, 512, 1, 1] 不管w,h是多少,都变成1*1的(均值)
# print("after pool: ", x.shape)
# flatten to 1 dim
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
model = ResNet()
print(model) # 打印模型结构
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # 放到GPU上
# Step3: construct Loss and Optimizer
criterion = torch.nn.CrossEntropyLoss() # 分类一般使用交叉熵
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Step4: Train and Test
def train(epoch):
running_loss = 0
model.train() # 设置为train模式
for batch_idx, (x, label) in enumerate(cifar_train_loader, 0):
x, label = x.to(device), label.to(device)
optimizer.zero_grad()
# forward
outputs = model(x)
loss = criterion(outputs, label)
# backward
loss.backward()
# update
optimizer.step()
print("Epoch: ", epoch, "Loss is: ", loss.item())
def test(epoch):
correct = 0
total = 0
model.eval() # 设置为test模式
with torch.no_grad(): # 以下内容不需要构建计算图,不需要计算梯度 这一句可加可不加
for data in cifar_test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
pred = outputs.argmax(dim=1)
total += labels.size(0) # 每次循环都把这一批的batch_size加上,就得到总的数量
correct += torch.eq(pred, labels).float().sum().item() # 对比预测和label相同的数量 即为预测正确的数量
print("Epoch", epoch, "Accuracy on test set: %d %%" % (100 * correct / total))
return correct / total
if __name__ == "__main__":
epoch_list = []
acc_list = []
for epoch in range(50):
train(epoch)
acc = test(epoch)
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list, acc_list)
plt.xlabel("Epoch")
plt.ylabel("Acc")
plt.grid()
plt.show()
end = time.time()
print("Total Time: ", end - start)
结果如图:
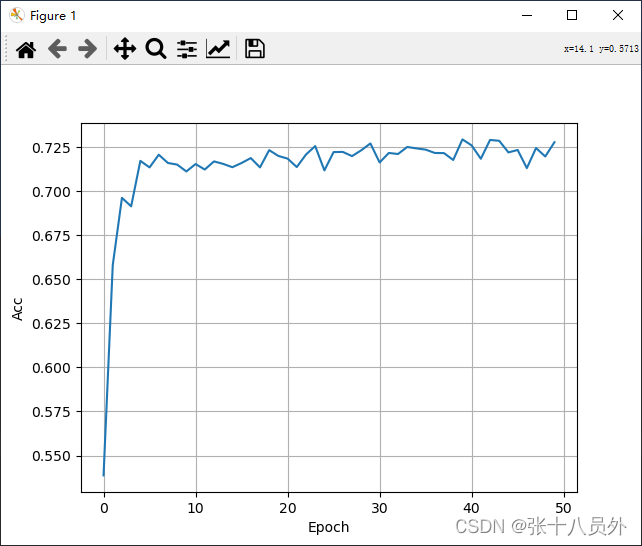
可以看出准确率大约在72%左右,相比LeNet5上升了20多个百分点。
训练50轮,总时间为2303秒。















 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









