






使用eBPF进行半虚拟化调度\动态vcpu优先级管理
参考
http://oldvger.kernel.org/bpfconf2024_material/paravirt_sched_lsfmm.pdf
动机
- 双重调度:
- 主机(Host)调度虚拟CPU(vcpu)线程。
- 客户机(Guest)调度在客户机内部运行的任务。
- 调度器之间的无知:
- 主机在调度vcpu线程时,不知道vcpu上正在运行什么任务。
- 客户机在调度任务时,不知道vcpu物理上在哪里运行。
- vCPU的运行问题:
- vCPU通常是主机中的常规CFS(完全公平调度)任务。当主机承受负载时,vCPU可能无法及时运行。
- 影响调度器的公平性,主机调度器试图保持公平,但不知道任务的优先级需求。
- 导致的问题:
- 这可能导致延迟、功耗、资源利用等问题。
概念
- 基于共享调度信息的高效任务调度决策:客机和主机之间共享调度信息,以便做出更有效的任务调度决策。
- 通过共享内存共享信息:客机和主机之间通过共享内存来共享信息。
- 内核中通过通用框架以共享内存的方式和客户机协商:在内核中有一个通用框架,用于共享内存和进行主机和客户机之间的协商。
- 调度策略可以作为客机和主机上的内核模块或bpf程序:调度策略可以在客机和主机上实施为内核模块或bpf程序。
框架
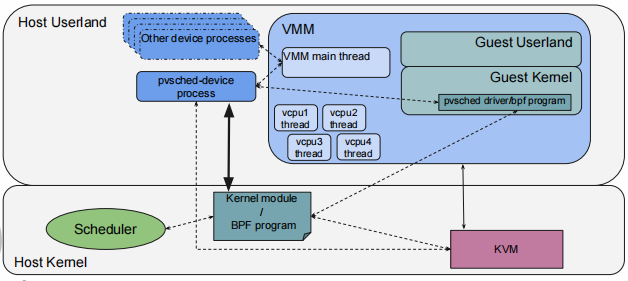
半虚拟化调度框架通过在主机用户态运行的 pvsched-device 进程 和内核中的 BPF 程序 协同工作,管理虚拟机的虚拟 CPU (vCPU) 调度。VMM 负责控制虚拟机的生命周期和 vCPU 线程,而 pvsched 驱动/BPF 程序 负责在客户机和主机之间传递调度信息,优化虚拟机的性能。整个系统通过 KVM 模块与主机的调度器紧密集成,确保虚拟 CPU 能高效利用物理 CPU 资源。
host pvsched device(半虚拟化调度设备)
-
与客户机进行交互,通过暴露一个 PCI 设备给客户机来实现。客户机可以通过可写的 BAR(Base Address Register)访问该设备,写入共享内存区域的基址。
-
该设计未来可以扩展,以支持功能和策略协商,使调度更加灵活和高效。
-
该原型在crosvm中实现(Crosvm是Chromebook用rust编写的虚拟机管理器)(相关链接:https://aya-rs.dev/)
-
Pvsched设备作为一个单独的沙箱进程运行。
-
它接收来自客户的共享内存GPA(客户机物理地址),并将其转换为进程地址空间中的主机虚拟地址。
-
它加载实现策略的内核模块或eBPF程序,并传递详细信息(如vCPU ID、PID、共享内存地址等)。
-
内核模块通过ioctl传递信息。
-
eBPF程序使用BPF_MAP_TYPE_HASH(通过vCPU PID索引)。
-
guest pvsched driver(半虚拟化调度驱动)
- 驱动绑定到设备
- 分配一页共享内存。
- 包含每个vCPU的结构数组。
- 将共享内存的GPA写入设备暴露的BAR(基地址寄存器)。
- 原型在pvsched驱动中内置了共享内存更新逻辑。
- 这可以分离出来并作为另一个内核模块或BPF程序实现。
- 适用于专业化用例。
注册到调度器和内核关键部分跟踪点:
sched_switch、sched_wake{nmi/irq/softirq}_{entry/exit}、preempt_{disable/enable}exit_to_user
在跟踪点回调时更新共享内存:
- 在内核关键部分,设置共享内存中的标志。
- 用被唤醒/切换的进程的优先级(策略、nice、rt_prio)更新共享内存。
调度策略
-
功能
-
可以作为内核模块或eBPF程序实现。
-
从VMM中检索VM和vcpu的详细信息(如nr_vcpus, vcpu_id, vcpu_pid等)。
-
注册VM事件回调(如VMENTER, VMEXIT, VCPU_HALT, INJ_INTR等)。
-
在接收到回调时执行调度策略。
-
-
需求
- 策略可以根据使用案例和需求进行自定义实现。
- 使用简单的策略来最小化延迟:
- 提升guest任务中对延迟敏感的工作负载的vcpu优先级。
- 将Linux调度参数从guest任务一对一地转换为主机中的vcpu任务。
- 对行为不端的vcpu实施vcpu节流。
延迟缓解策略
VMEXIT
- 功能:从虚拟机(VM)获取请求的调度参数。
- 检查:根据vCPU被提升的时间长度,检查是否需要对其进行限制(throttle)。
- 检查:根据vCPU被限制的时间长度,检查是否需要解除限制(unthrottle)。
- 优先级限制:根据管理员设置的限制,限制调度优先级。
- 应用优先级:如果虚拟机未被限制,则应用调度优先级(sched_setattr)。
VMENTER
- 功能:进行提升和限制的计时核算。
VCPU_HALT
- 功能:提升vCPU线程:将要被调度出,并且只有在响应延迟敏感事件(如中断)时才会被唤醒。
- 描述:客户机在完成优先级工作负载后会请求解除提升。
Interrupt Injection
- 功能:提升vCPU线程。
实现细节
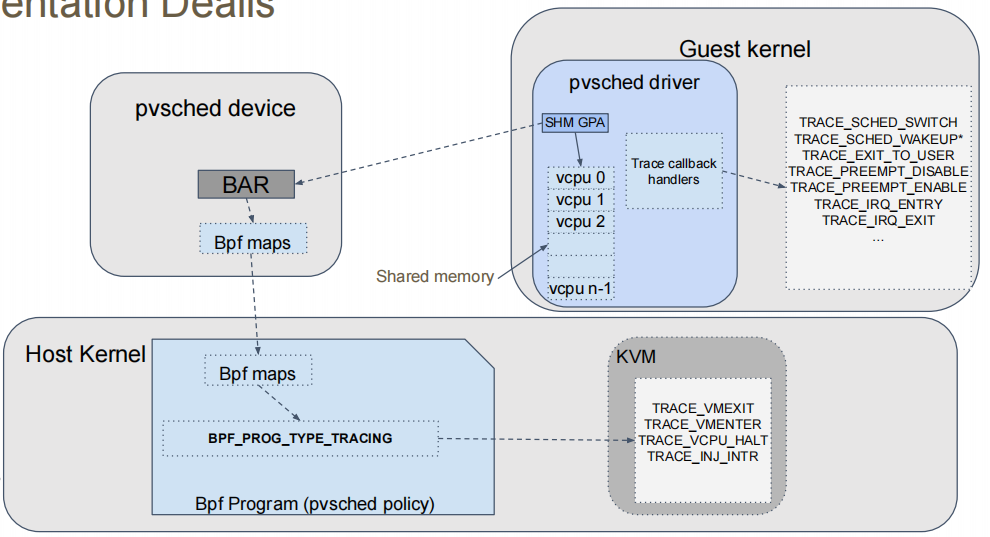
虚拟化环境中调度策略的实施过程,具体包括以下几个部分:
- pvsched设备:
- BAR(Base Address Register):这是与pvsched设备进行通信的基地址寄存器。
- Bpf maps:用于BPF(Berkeley Packet Filter)程序与硬件设备之间的数据映射。
- 宿主机内核:
- Bpf maps:宿主机内核中也定义了BPF映射,用于与访客内核和pvsched设备进行数据交换。
- Bpf Program (pvsched policy):这是基于BPF的调度策略程序,定义了具体的调度策略。
- 客户机内核:
- pvsched driver:这是运行在访客内核中的调度驱动程序,负责与pvsched设备和宿主机内核进行通信。
- SHM GPA(Shared Memory Guest Physical Address):共享内存的客户机物理地址。
- Trace callback handlers:跟踪回调处理程序,用于处理各种跟踪事件。
- vcpu 0, vcpu 1, vcpu 2:代表虚拟CPU实例,每个实例都有独立的调度策略和运行环境。
- KVM(Kernel-based Virtual Machine):
- TRACE事件:包括TRACE_VMEXIT、TRACE_VMENTER、TRACE_VCPU_HALT、TRACE_INJ_INTR等,用于跟踪虚拟机的行为和状态。
- 共享内存:
- 作为宿主机内核、访客内核和pvsched设备之间的桥梁,共享内存用于传递调度信息、追踪事件和数据映射。
共享内存
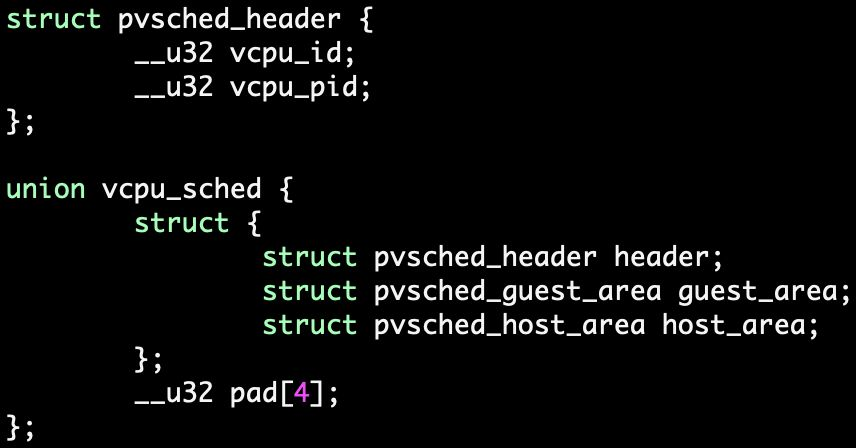

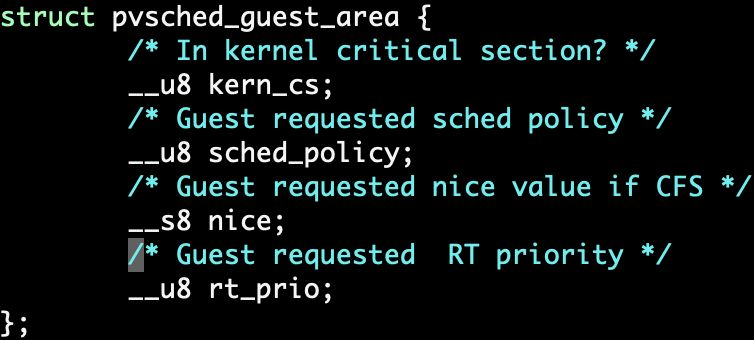
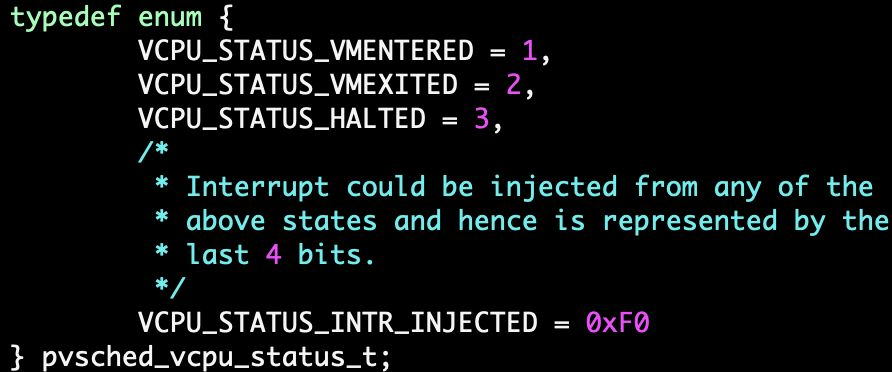
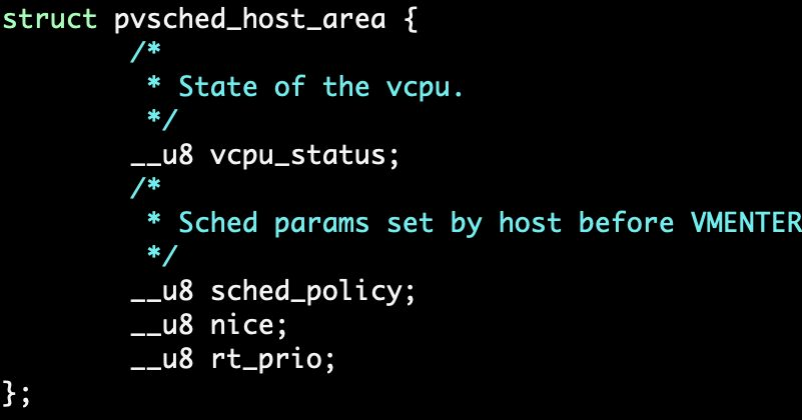
bpf程序
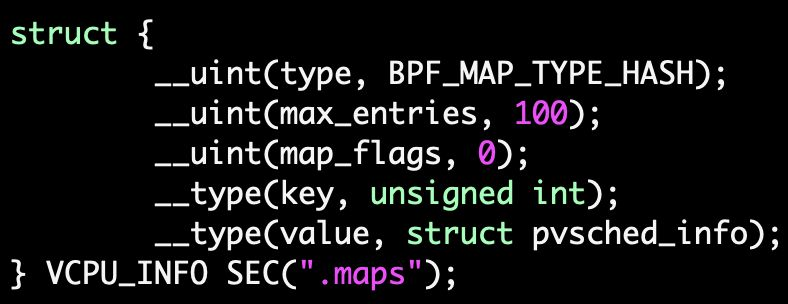
使用bpf hash map存储vcpu信息:
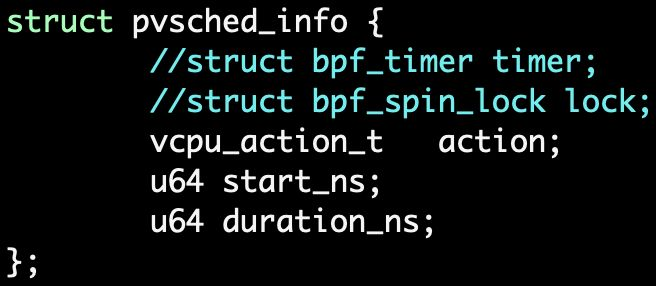
对vcpu的操作:

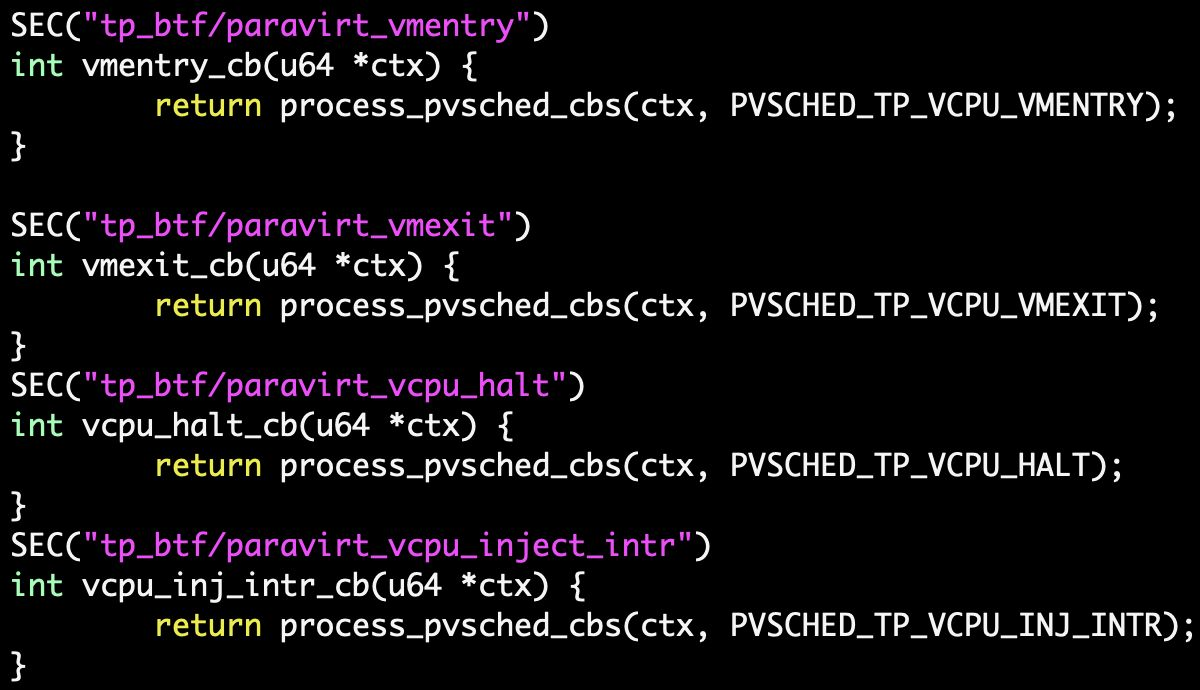
bpf程序和共享内存
- 理想情况:虚拟机管理器(VMM)应该能够与eBPF程序共享共享内存的虚拟地址。
- 现实限制:由于eBPF的安全约束,这种共享并不容易实现。
- 替代方案:
bpf_probe_{read/write}_user:可以在非进程上下文中发生跟踪点回调。bpf_probe_read_kernel:将进程虚拟地址空间映射到内核地址空间,但不支持写入内核地址。kptr:是否支持写入支持?BPF_MAP_TYPE_TASK_STORAGE:通过任务本地存储共享用户内存。https://lore.kernel.org/bpf/20240816191213.35573-4-thinker.li@gmail.com/T/
实现
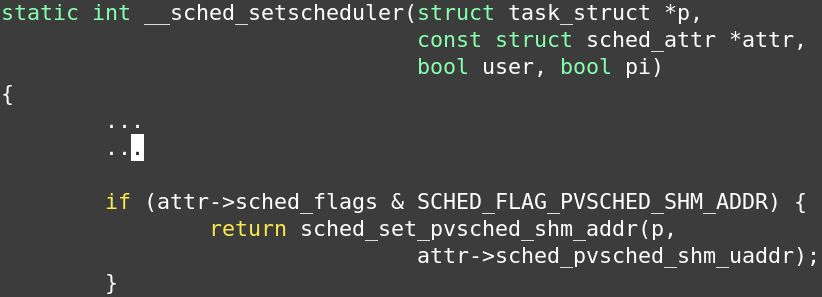
- 修改
task_struct结构体以包含内核地址和页面。 - 使用
sched_setscheduler来设置这些字段。 - VMM调用
set_scheduler为vCPU任务设置调度器。 - 使用BPF kfunc进行设置和获取
struct task_struct {
…
void *pvsched_shm_addr;
struct page *pvsched_shm_page;
…
};
ebpf和调度器
需要调度器修改调度参数
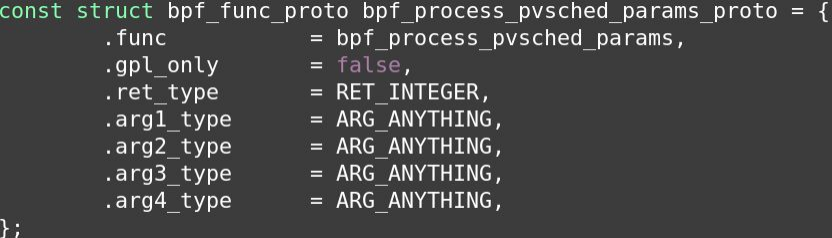
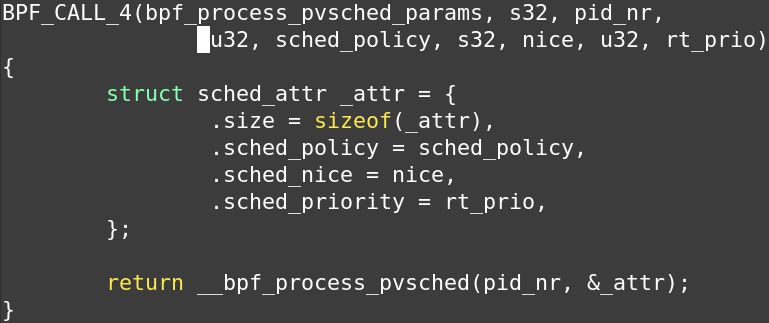
可调参数
- 通过BPF地图和VMM(虚拟机管理程序)来调整的。
- 当客户机处于内核关键区或主机正在注入中断时,vcpu任务的调度优先级。
- vcpu任务在被限制之前的最大提升时间。
- 限制持续时间。
- 调试级别。
ebpf限制
- 跟踪点无法使用计时器和自旋锁
- 共享内存访问问题
- 需要调度程序kfunc/帮助函数
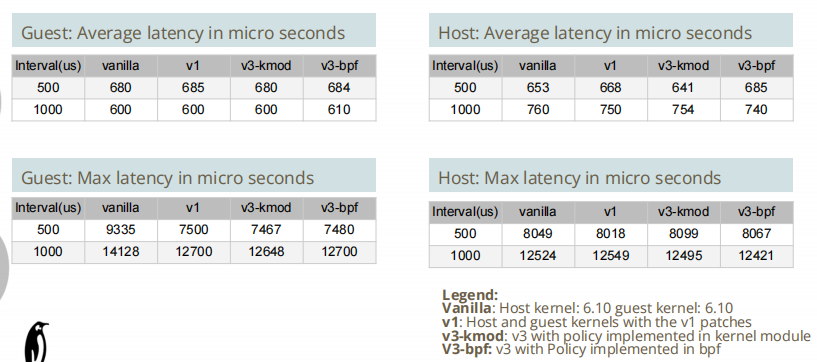
性能测试
快速综合测试
cyclictest --mlockall -q -p 8 --policy=rr
- 观察延迟对客户机的影响
- 观察是否对主机有任何影响
在空闲主机和繁忙主机上进行测试
使用stress-ng模拟繁忙主机
stress-ng --cpu 2 --iomix 1 --vm 1 --vm-bytes 128M --fork 1
空闲主机:

繁忙主机:
未来展望
-
上游合作以获取eBPF支持:如kfunc/helpers用于调度器集成。
-
上游合作以获取共享内存访问支持:
- 是否需要一种新的map直接在客户机和主机之间共享数据?
-
自旋锁和定时器支持:
- 使用bpf结构操作而不是跟踪点?
-
可定制性:
- 泛化共享内存区域(union vcpu_sched)以支持更多用例。
- 协议、版本等。
-
客户机侧的BPF?
- 客户机中的调度扩展?
-
使用调度事件而不是kvm事件:
- 为了减少延迟,我们只关心vCPU被抢占以及vCPU在被唤醒后尽快获得CPU。
- 因此,为什么不使用sched_switch和sched_wakeup,而是VMEXIT/VMENTER?
-
仍然需要hook中断注入路径:
- 在中断注入和VMENTER之间,vCPU可能会被调度出去,如果没有提升vCPU时间。
- 修改kvm_vcpu_kick()以提示调度器关于唤醒的原因——中断、IPI等。
结论
- 提供了一个通用的框架,帮助实现自定义策略,可以作为内核模块或BPF程序来实现
- 几乎完全消除了对KVM/虚拟机管理程序的依赖
- 主要是增加了跟踪点
- 内核中的更改最小
- 主要是跟踪点的增加

















 2225
2225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









