







BPF工具
BPF中用于分析CPU性能问题的工具如下图所示。
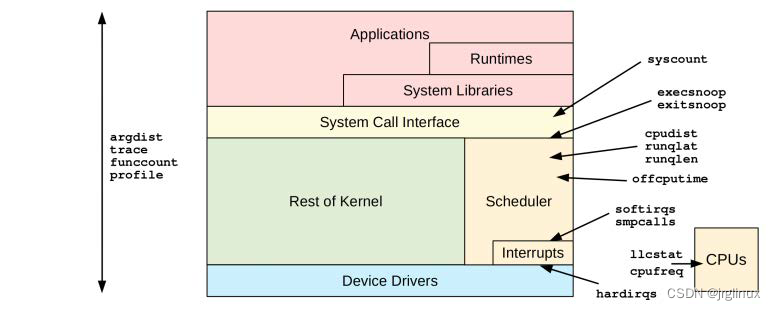
CPU分析命令清单
| 命令 | 来源 | 分析对象 | 描述 | 适用场景 |
|---|---|---|---|---|
| execsnoop | BCC/BT | 调度 | 列出新进程的运行信息 | 追踪高频出现、消耗资源的短期间进程 |
| exitsnoop | BCC | 调度 | 列出进程运行时长和退出的原因 | 协助调试短时进程的问题,从退出的角度定位问题 |
| runqlat | BCC/BT | 调度 | 统计CPU运行队列的延迟信息 | 当CPU资源处于饱和状态时,识别和量化问题的严重性 |
| runqlen | BCC/BT | 调度 | 统计CPU运行队列的长度 | 定位负载不均衡问题 |
| runqslower | BCC | 调度 | 运行队列latency超过阈值时打印信息 | 繁忙系统中,定位那些进程受到调度延迟的影响 |
| cpudist | BCC | 调度 | 统计在CPU上运行时间 | 可用于帮助分析CPU的使用率问题 |
| offcputime | BCC | 调度 | 统计线程脱离CPU时的跟踪信息和等待时长 | 分析为什么线程没有在CPU上执行,分析脱离CPU的运行时间 |
| profile | BCC | CPU | 采样CPU运行的调用栈信息 | 分析所有CPU的调用栈 |
| syscount | BCC/BT | 系统调用 | 按类型和进程统计系统调用次数 | 可以调查系统占用CPU时间长的问题 |
| funccount | BCC | 函数 | 统计函数调用次数 | 跟踪函数占用CPU的具体原因 |
| softirqs | BCC | 中断 | 统计软中断时间 | 对软中断统计计数,且可输出每个IRQ的处理时间 |
| hardirqs | BCC | 中断 | 统计硬中断时间 | 对硬中断统计计数,且可输出每个IRQ的处理时间 |
execsnoop
用于跟踪通过exec()系统调用产生的新进程的信息,包裹进程名、参数列表等。
execsnoop的原理是通过追踪execve()系统调用,可以直接打印execve()的调用参数和返回值,用于追踪由fork->exec方式产生的新进程以及那些主动自己调用exec的进程。但是有些进程是能绕过exec直接产生新进程,比如通过fork->clone方式生成worker processes(工作进程池)的进程,就没法通过execsnoop来追踪了。不过这种情况比较少见,一般都是创造线程池而非进程池。
假设后台在执行make编译命令,用execsnoop查看
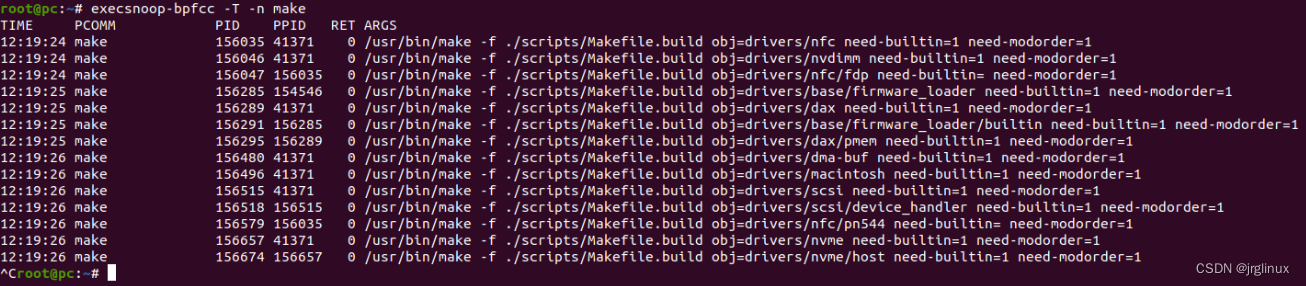
execsnoop适合定位什么问题?
execsnoop可用于寻找高频出现、消耗资源的短期进程,这类进程由于执行时间短,传统工具如top等工具在抓取监控信息之前这类进程就消失了,不容易定位问题,适合使用execsnoop来追踪查看。
自身消耗
由于进程创建的频率一般较低(小于1000/s),所以execsnoop自身的额外消耗可忽略不计。
exitsnoop
用于追踪短期进程的退出时间,打印进程的运行时长以及退出原因,运行时长(AGE参数)是指进程从创建到终止的时长,包括CPU实际运行时间和非运行时间。
如下图所示,可以追踪执行的ls、ping等命令的退出状态,其中ctrl+C结束的ping命令退出状态是code 1。
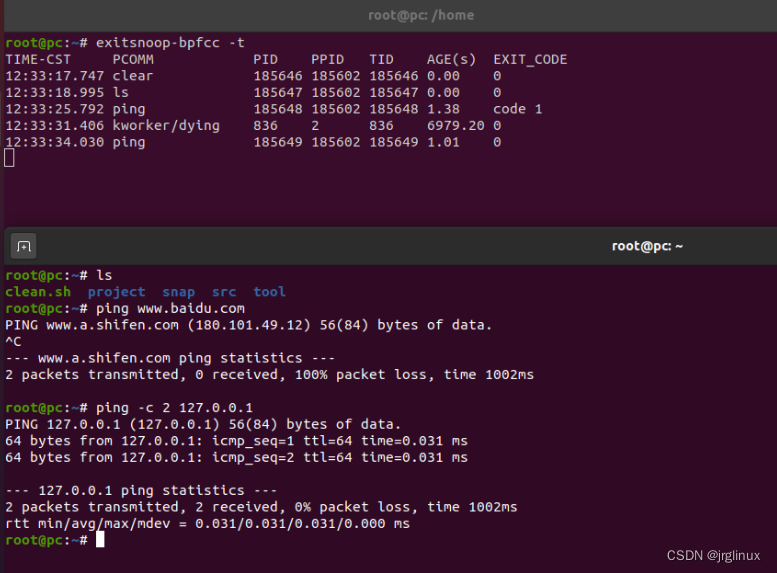
适用场景
exitsnoop适用协助调试短时进程的问题,从退出的角度定位问题。
自身消耗
exitsnoop原理是利用sched:sched_process_exit跟踪点和它的参数信息,同事利用bpf_get_current_task()以便从task结构体读取信息,由于跟踪点本身的执行频率不高,所以自身消耗可忽略不计。
runqlat
直方图统计调度器的runqueue的延时latency。
追踪两类runqueue latency:
- 进程从被加入队列到上下文切换以及开始执行的时间,追踪路径ttwu_do_wakeup()-,wake_up_new_task() -> finish_task_switch()。
- 进程从被动上下文切换且仍处于可执行状态开始到它的下一次开始执行的间隔时间,这是从finish_task_switch()开始监测。
在一个32-CPU的系统上,make -j96并行编译,延迟如下图所示。其高峰值在8~16ms之间,可见latency还是很显著的。
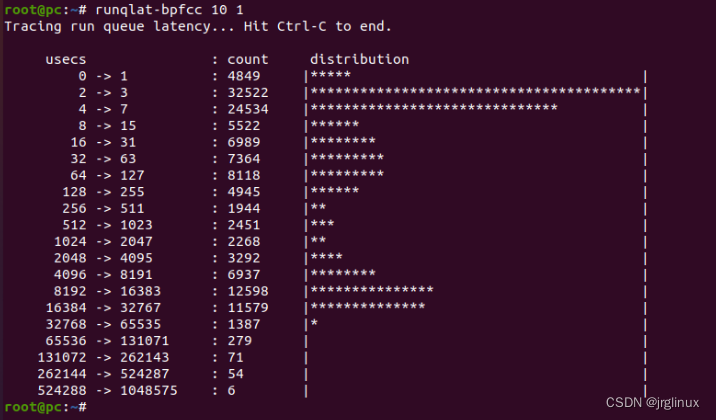
而同样的32-CPU系统上,make -j24并行编译任务时,延迟如下,可以看出latency超过1ms的占少数,大部分进程延迟都在1ms之内。
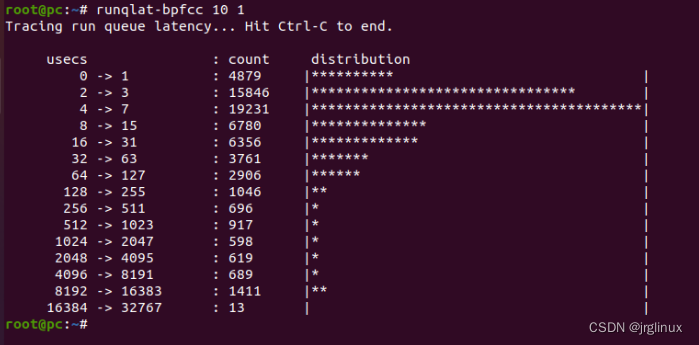
适用场景
当CPU资源处于饱和状态时,runqlat可以识别和量化问题的严重性所在点。
自身消耗
runqlat利用对CPU调度器的线程唤醒事件和线程上下文切换事件的跟踪来计算线程从唤醒到运行之间的时间间隔。当处于比较繁忙的系统中,这些事件发生的频率较高,能超过10000/s,这种情况下使用runqlat也会对系统造成不小的影响,需多加注意。
runqlen
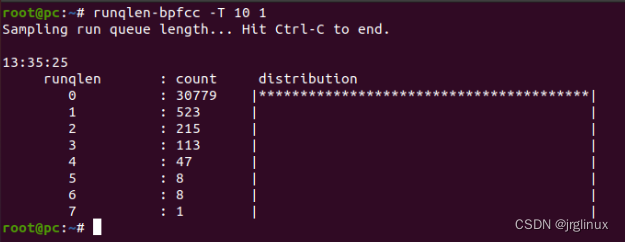
以直方图统计队列中有多少进程正在等待。
runqlen是定时采样,采样频率是99Hz。
32-CPU系统中,make -j24并行编译时,其队列等待数量则明显较少,大部分时间队列都是0长度,进程能得到立即执行。
32-CPU系统中,make -j96并行,则队列等待数量明显增加,队列长度不为0的时间比例达86%,意味着进程需要等待。
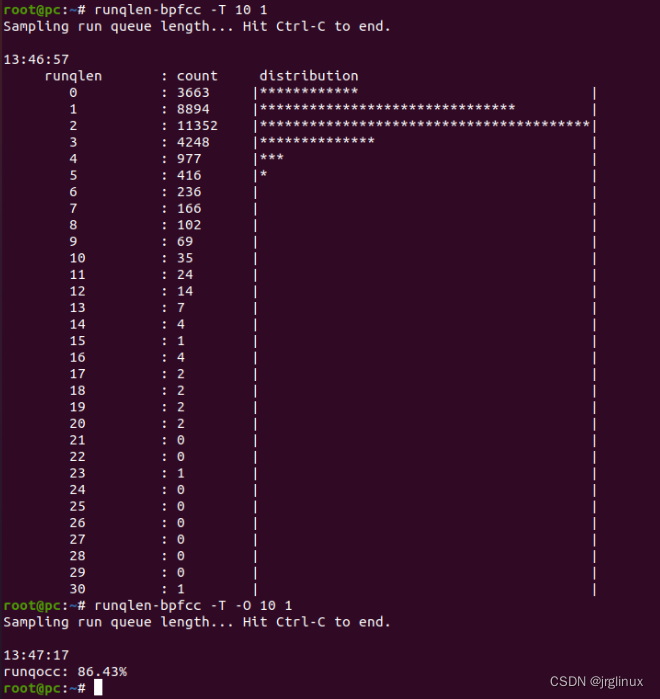
适用场景
定位负载不均衡问题,比如某些进程同时绑定在同一个CPU上,而其他CPU却空闲,导致进程在等待;
自身消耗
相比较于runqlat通过跟踪CPU调度器事件来说,runqlen定时采样的消耗就小的很多,可忽略不计。对于长时间监控的环境下,优先使用runqlen来定位问题。
runqslower
列出运行队列中等待延迟超过一定阈值的进程,输出进程名和延迟时长。默认阈值时10000us(10ms)。
在32-CPU上,make -j32并行编译任务时,看到延迟超过10ms的进程如下所示。
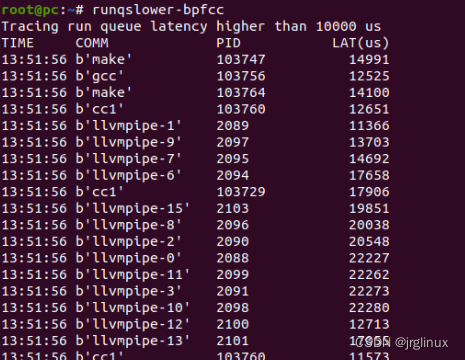
适用场景
繁忙系统中,定位那些进程受到调度延迟的影响。
自身消耗
与runqlat类似,runqslower在繁忙的系统上适用kprobes会造成不可忽视的性能损耗。
cpudist
用于统计每次线程唤醒之后在CPU上执行的时长分布。
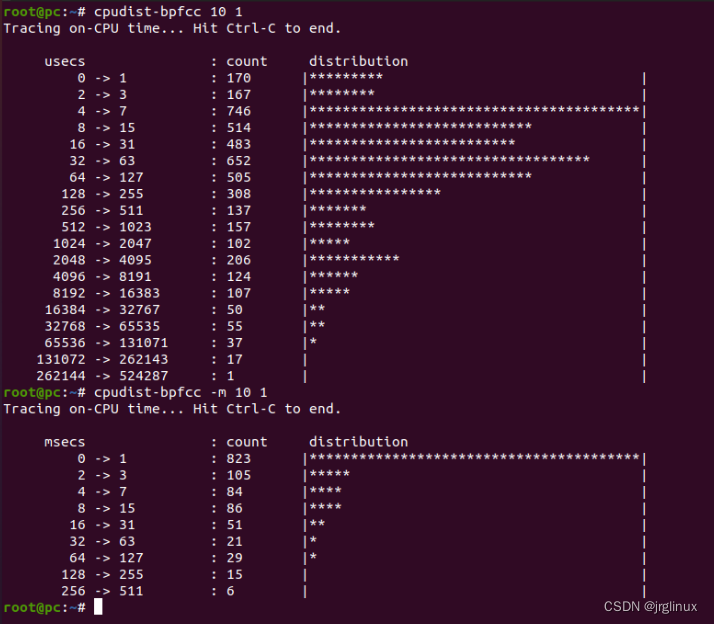
适用场景
可用于帮助分析CPU的使用率问题。
自身消耗
cpudist在内部跟踪CPU调度器的上下文切换事件,在繁忙的系统中,上下文切换事件发生频率非常高,因此cpudist的额外损耗不可忽视。
offcputime
用于统计线程阻塞和脱离CPU运行的时间,输出调用栈信息,定位阻塞原因。
执行命令offcputime-bpfcc 2,输入如下。
gdbus进程阻塞在poll上,阻塞时间1.9s;ibus-daemon进程阻塞在poll等待,阻塞1.9s;而自身offcputime-bpfcc任务阻塞在select选择上,阻塞时间2s
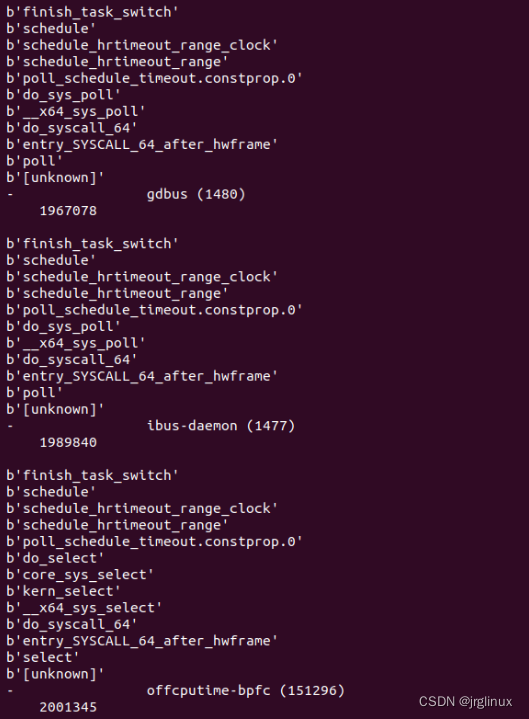
适用场景
可以分析为什么线程没有在CPU上执行,分析脱离CPU的运行时间。
自身消耗
offcputime也是通过跟踪上下文切换事件来记录脱离CPU的时间和返回CPU的时间,繁忙系统中,其损耗不能忽视。
profile
定时采样调用栈信息并且汇报调用栈出现频率信息的工具。只是BCC工具中粉刺CPU占有信息最有用的工具之一,因为该工具可以同时记录几乎所有占有CPU的代码调用栈。默认用49Hz频率采样所有CPU的用户态和内核态的调用栈。
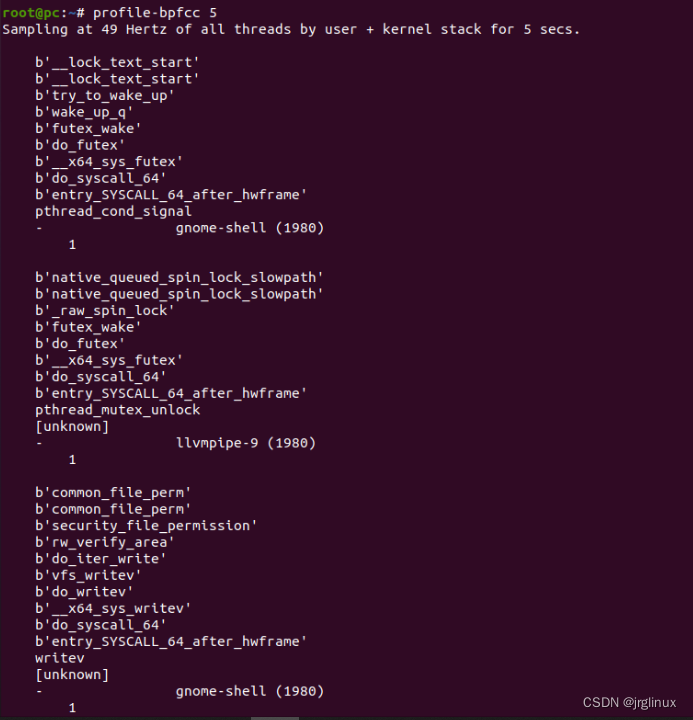
适用场景
分析所有CPU的调用栈。
自身消耗
因定时采样,额外消耗可忽略不计。profile采样统计是在内核态完成,十分高效,而perf等需要将所有的采样信息发送到内核态进行处理得出统计信息。
syscount
统计系统中的系统调用数量。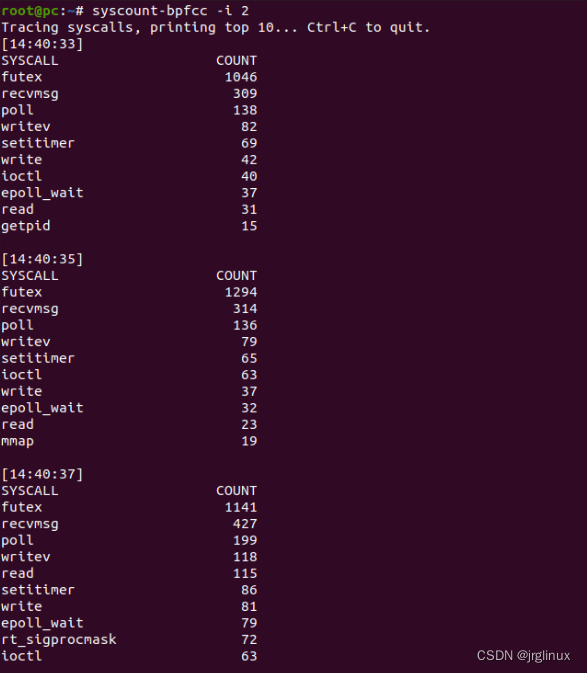
上图显示了每2秒之内的前10个系统调用,最频繁的是futex()。
适用场景
可以调查系统占用CPU时间长的问题。
自身消耗
在系统调用量大的情况下,该工具自身的消耗也很显著。
funccount
统计事件和函数调用频率。profile可能可以分析出哪个函数正在占用CPU,但不能解释原因是因为函数本身执行慢还是该函数被频繁调用。
函数应该是需要在/proc/kallsyms中的符号表有的才行,否则报错。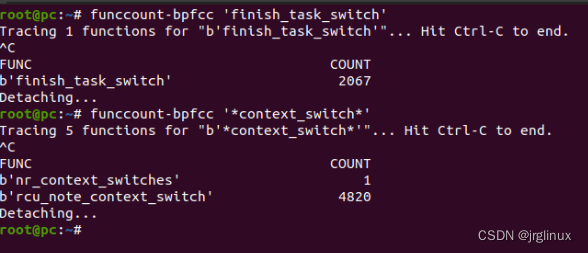
适用场景
跟踪函数占用CPU的具体原因。
自身消耗
funccount的实现是通过动态跟踪来统计,内核态函数使用kprobes,用户态函数使用uprobes,所以funccount的消耗跟监测的函数调用频率成正比,例如malloc()函数可能调用很频繁,如果跟踪malloc()函数则工具自身消耗也很大,所以一般要跟踪那些关键点且不是很频繁的函数。
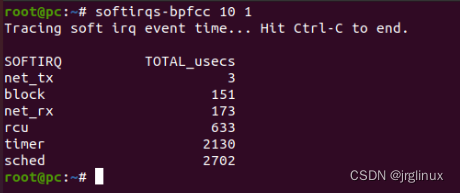
softirqs
统计软中断消耗CPU的时间。
适用场景
对软中断统计计数,且可输出每个IRQ的处理时间。
自身消耗
在繁忙系统、网络通信频繁的系统下,中断产生频率大增,该工具的消耗也会显著增加。
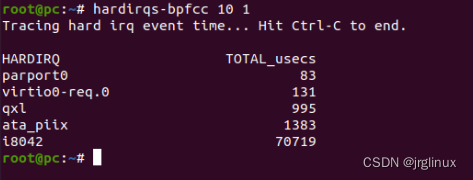
hardirqs
显示系统处理硬中断的时间。
适用场景
对硬中断统计计数,且可输出每个IRQ的处理时间。
自身消耗
hardirqs动态跟踪内核中的handle_irq_event_percpu()函数,不过未来可能切换到irq:irq_handler_entry和irq:irq_handler_exit两个函数,硬中断繁忙系统下,消耗增加。
参考文档
《BPF之巅》–Brendan Gregg.















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









