






记录一下读代码时的代码学习过程叭
目录
RECT类
句法
class Rect
成员表
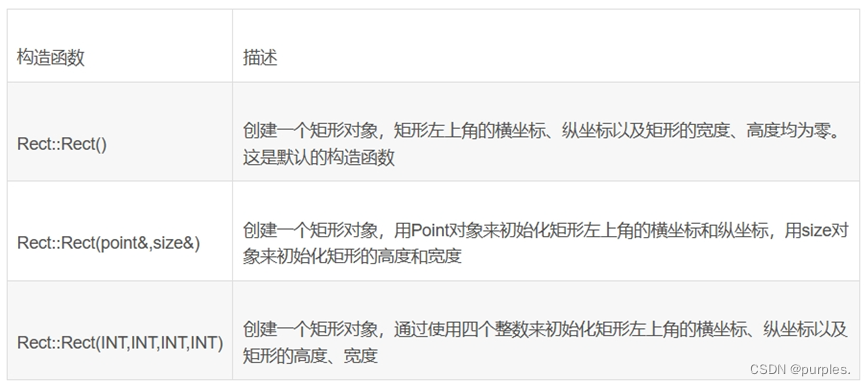
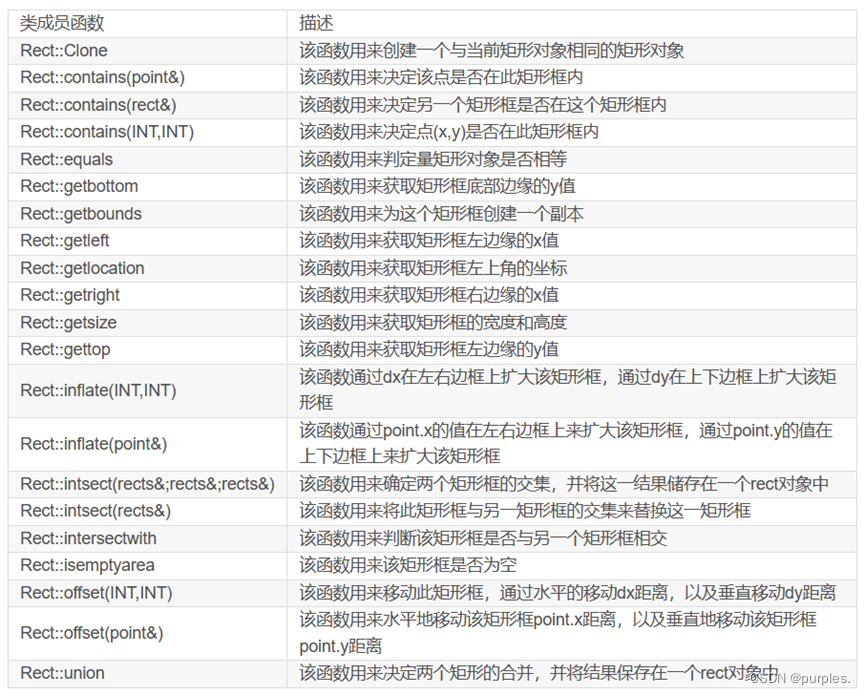
//如果创建一个Rect对象rect(100, 50, 50, 100),
Rect rect(100,50,50,100);
//rect的成员:
rect.left; //矩形框左上角的x坐标
rect.top; //矩形框左上角的y坐标
rect.right; //矩形框右下角的x坐标
rect.bottom; //矩形框右下角的y坐标
//那么rect会有以下几个功能:
rect.area(); //返回rect的面积 5000
rect.size(); //返回rect的尺寸 [50 × 100]
rect.tl(); //返回rect的左上顶点的坐标 [100, 50]
rect.br(); //返回rect的右下顶点的坐标 [150, 150]
rect.width(); //返回rect的宽度 50
rect.height(); //返回rect的高度 100
rect.contains(Point(x, y)); //返回布尔变量,判断rect是否包含Point(x, y)点
rect.push_front(); //在vector开头增加新的元素
rect.push_back(); //在vector最后添加一个元素(参数为要插入的值)
rect.pop_back(); //移除最后一个元素
rect.clear(); //清空所有元素
rect.empty(); //判断vector是否为空,如果返回true为空
rect.erase(); // 删除指定元素
rect.front(); //返回的是第一个元素的引用
rect.back(); //返回的的是最后一个元素的引用
rect.begin(); //从前往后遍历
rect.end(); //从后往前遍历
rect.reverse(); //将vect的元素翻转,即逆序排列
//还可以求两个矩形的交集和并集
rect = rect1 & rect2;
rect = rect1 | rect2;
//还可以对矩形进行平移和缩放
rect = rect + Point(-100, 100); //平移,也就是左上顶点的x坐标-100,y坐标+100
rect = rect + Size(-100, 100); //缩放,左上顶点不变,宽度-100,高度+100
//还可以对矩形进行对比,返回布尔变量
rect1 == rect2;
rect1 != rect2;
//OpenCV里貌似没有判断rect1是否在rect2里面的功能,所以自己写一个吧
bool isInside(Rect rect1, Rect rect2)
{
return (rect1 == (rect1&rect2));
}
//OpenCV貌似也没有获取矩形中心点的功能,还是自己写一个
Point getCenterPoint(Rect rect)
{
Point cpt;
cpt.x = rect.x + cvRound(rect.width/2.0);
cpt.y = rect.y + cvRound(rect.height/2.0);
return cpt;
}
//围绕矩形中心缩放
Rect rectCenterScale(Rect rect, Size size)
{
rect = rect + size;
Point pt;
pt.x = cvRound(size.width/2.0);
pt.y = cvRound(size.height/2.0);
return (rect-pt);
}
gtest
- 测试类, 即派生于::testing::Test的自定义派生类的类
- 测试分类名, 即未使用任何自定义测试类的测试的仅用于分类和筛选的名
- 测试类名/分类名, 定义测试时所用的第一个参数的内容, 原名测试套件
- 测试名, 定义测试时所用的第二个参数的内容
- 崩溃测试, 原名死亡测试
- 检查, 即ASSERT和EXPECT和统称
- 断言, 即ASSERT
- 期望, 即EXPECT
- 检查函数, 原名谓词, 谓词函数
- 失败, 即未通过,
- 成功, 即通过.
- n型检查函数, 原无此名, 因对函数签名有渐进性的要求, 为做区分而起
- 值测试模板, 原名参数化测试, 由于实际意义类似于模板而改名以模板为名称后缀
- 类型测试模板, 原名类型测试, 改名理由同上
注意, 每个测试既不是函数也不是类, 不应用测试函数等称呼. 而是专门用专有名词称呼.
使用
使用gtest需包含头文件 gtest/gtest.h, 并链接库 gtest_main.lib 和 gtest.lib.
#include "gtest/gtest.h"
测试
普通测试
使用测试分类名和测试名定义一个测试.
TEST(分类名, 测试名) {
测试代码
}
然后使用下面套路化的main函数启动测试.
int main(int argc, char** argv) {
testing::InitGoogleTest(&argc, argv);
return RUN_ALL_TESTS();
}
可在类中添加
FRIEND_TEST(分类名, 测试名);
检查
可在测试中使用检查. 检查包括断言与期望.
测试里若无检查失败则测试通过.
除个别检查外, 所有检查都带前缀, 可在下述两项中二选一.
- ASSERT_ : 断言, 不通过检查则中断测试, 当在测试外使用时要求函数返回void.
- EXPECT_ : 期望, 不通过检查并不中断测试.
数值
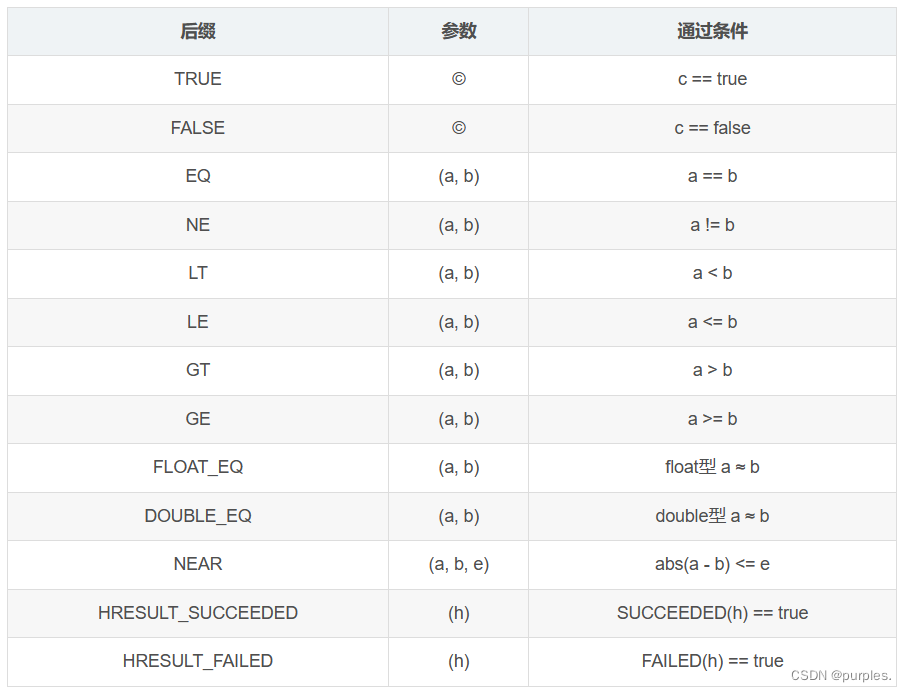
其余部分可查看此文章:[C++] gtest入门教程
C++的强制类型转换
搬运自:C/C++中的数据类型转换()/static_cast/dynamic_cast/const_cast/reinterpret_cast
C++中的四个强制static_caststatic_cast、dynamic_cast、const_cast、reinterpret_cast
使用语法:
XXXX_cast<new_type_name>(expression)
例如:
Rect<int> rect = static_cast<Rect<int>>(bbox);
static_cast
其作用主要表现在static上,时一种静态的转换,在编译期就能确定的转换,可以完成C语言中强制类型转换中的大部分工作,但不能转换表达式的const、volitale、_unaligned属性
主要用法:
- 用于基本数据类型之间的转换,如:把
int转换成char,把int转换成double
如:
int a = 100;
char b = static_cast<char>(a); //将int型a转换为char型,并赋值给b
double c = static_cast<double>(a); //将int型a转换为double型,并赋值给c
- 将表达式转换为
void型,并将转换后的结果丢弃:
int a = 100;
static_cast<void>(a);
- 可用于
void*和其他指针类类型之间的转换,但是不能用于两个无关指针类型的直接转换
如:
//正常转换
int *p = new int;
void* p1 = static_cast<void*>(p);
char* p2 = static_cast<char*>(p1);
//编译失败//error: invalid static_cast from type 'int*' to type 'char*'
char* p3 = static_cast<char*>(p);
- 可以用于类继承结构中基类和派生类之间指针或引用的转换,向上转型安全,向下转型由于没有动态类型检查,是不安全的
struct B { };
struct D : B { };
D d;
B& rb = d;
D& rd = static_cast<D&>(rb);
- 如果涉及左值到右值、数组到指针或函数到指针的转换,也可以通过static_cast显式执行。
template<typename _Tp>
inline typename std::remove_reference<_Tp>::type&&
move(_Tp&& __t)
{ return static_cast<typename std::remove_reference<_Tp>::type&&>(__t); }
dynamic_cast
这是一个“动态”转换函数,只能对指针和引用的进行转换,并且只用于类继承结构中基类和派生类之间指针或引用的转换,可以进行向上、向下,或者横向的转换。
相比于 static_cast 的编译时转换, dynamic_cast 的转换还会在运行时进行类型检查,转换的条件也比较苛刻,必须有继承关系的类之间才能转换,并且在基类中有虚函数才可以,有一种特殊的情况就是可以把类指针转换成 void* 类型。
主要用法:
- 普通类型的指针无法转换
int val = 100;
int *p = &val;
// 编译失败 //error: cannot dynamic_cast ‘p’ (of type ‘int*’) to type ‘char*’ (target is not pointer or reference to class)
char* pc = dynamic_cast<char*>(p);
- 继承结构中基类里面没有虚函数无法转换
struct B { };
struct D : B { };
D d;
B* pb = &d;
// 编译失败 //error: cannot dynamic_cast ‘pb’ (of type ‘struct test1()::B*’) to type ‘struct test1()::D*’ (source type is not polymorphic)
D* pd = dynamic_cast<D*>(pb)
- 指针或引用转换的类型不是正确的类型,如果参数类型是指针会返回目标类型空指针,如果参数类型是引用则会抛出
std::bad_cast异常。
struct B { virtual void test() {} };
struct D : B { };
B d;
B* pb = &d;
D* pd = dynamic_cast<D*>(pb);
// 编译成功,但是pb指针指向的类型是 B,向下转型失败,输出结果是0,也就是空指针
std::cout << pd << std::endl;
- 一个正常转换的例子,包含向上、向下、横向转换
struct B { virtual void test() {} };
struct D1 : virtual B { };
struct D2 : virtual B { };
struct MD : D1, D2 { };
D1* pd1 = new MD();
std::cout << pd1 << std::endl;
// 向上转型
B* pb = dynamic_cast<B*>(pd1);
std::cout << pb << std::endl;
// 向下转型
MD* pmd = dynamic_cast<MD*>(pd1);
std::cout << pmd << std::endl;
// 横向转型
D2* pd2 = dynamic_cast<D2*>(pd1);
std::cout << pd2 << std::endl;
运行结果如下,在横向转换时指针发生了变化,可以看出 dynamic_cast 不是简单的数据强转,还进行了指针的偏移:
albert@home-pc:/mnt/d/testconvert$ g++ cppconvert.cpp
albert@home-pc:/mnt/d/testconvert$ ./a.out
0x15c0c40
0x15c0c40
0x15c0c40
0x15c0c48
const_cast
const_cast 不能去除变量的常量性,只能用来去除指向常数对象的指针或引用的常量性,且去除常量性的对象必须为指针或引用。
常量指针被转化成非常量指针,并且仍然指向原来的对象,常量引用被转换成非常量引用,并且仍然指向原来的对象;常量对象可能被转换成非常量对象。
- 尝试去除非指针和引用的类型的常量性会编译失败
const int i = 6;
// 编译错误 //
int j = const_cast<int>(i);
- 企图用一个指针来修改常量:
const int val = 6;
//编译错误 //error: invalid conversion from ‘const int*’ to ‘int*’ [-fpermissive]
int* cp = &val;
- 修改一个指针的常量性:
const int val = 6;
std::cout << "&val=" << &val << ", val=" << val << std::endl;
const int* cp = &val;
int *p = const_cast<int*>(cp);
*p = 2;
std::cout << "&val=" << &val << ", val=" << val << std::endl;
std::cout << "p=" << p << ", *p=" << *p << std::endl;
运行结果:
&val=0x7ffff7446bd4, val=6
&val=0x7ffff7446bd4, val=6
p=0x7ffff7446bd4, *p=2
运行之后,变量 p 指向了变量val地址,并改变了地址所指向的内存数据,但是打印 val 的值并没有发生变化,这是因为 val 作为常量在编译期使用它的地方就进行了替换,接下来再看另一种情况。
int init = 6;
const int val = init;
std::cout << "&val=" << &val << ", val=" << val << std::endl;
const int* cp = &val;
int *p = const_cast<int*>(cp);
*p = 2;
std::cout << "&val=" << &val << ", val=" << val << std::endl;
std::cout << "p=" << p << ", *p=" << *p << std::endl;
代码逻辑不变,只在开始的位置使用 init 这个变量来代替 6 这个常数,运行结果如下:
val=0x7fffe8c71fa0, val=6
&val=0x7fffe8c71fa0, val=2
p=0x7fffe8c71fa0, *p=2
运行之后 val 本身的变化也应用到了使用它的地方,这里的编译器替换已经不起作用了。
实际上,使用const_cast通常是一种无奈之举,利用const_cast去掉指针或引用的常量性并且去修改原始变量的数值,这是一种非常不好的行为,如果可以的话,尽可能在程序设计阶段就规避这种情况。
reinterpret_cast
它被用于不同类型指针或引用之间的转换,或者指针和整数之间的转换,是对比特位的简单拷贝并重新解释,因此在使用过程中需要特别谨慎,比如前面提到的一个例子,static_cast 不能将 int* 直接强转成 char*,使用reinterpret_cast就可以办到。
- 不同基础类型指针类型之间转换:
int *p = new int;
// 编译失败 //error: invalid static_cast from type ‘int*’ to type ‘char*’
char* p1 = static_cast<char*>(p);
// 编译成功
char* p2 = reinterpret_cast<char*>(p1);
- 基础类型指针与类对象指针之间的转换:
struct B { int val;};
B b{100};
std::cout << "b.val=" << b.val << std::endl;
int* p = reinterpret_cast<int*>(&b);
std::cout << "*p=" << *p << std::endl;
运行之后可以得到 *p 的值为100,也就是重新解释了变量 b 的地址为整型指针。
- 将地址值转换成整数
struct B { int val;};
B b{101};
std::cout << "&b=" << &b << std::endl;
long addr = reinterpret_cast<long>(&b);
std::cout << "addr=" << addr << std::endl;
运行结果如下:
&b=0x7ffffdc4f270
addr=140737450930800
这里的地址 0x7ffffdc4f270 被解释成了整数 140737450930800,因为涉及到字节序,这也是很多文章提到的 reinterpret_cast 不具备一致性的问题,我们需要知道这一个点,只要代码不依赖主机字节序就没有问题。
Box2D
搬运自:Box2D入门教程(1.概述)
使用Box2D需要了解下面这些概念,这里仅简单说明,之后会对这些概念进行更为详细的说明。
形状(shape)
形状是一个2D几何对象,比如:圆和多边形。
刚体(rigid body)
一块不会发生形变的固体(类似钻石)。在后续的教程中,我们使用body指代刚体(rigid body)。
碰撞体(fixture)
我们通过碰撞体(fixture)来定义body的形状和材质属性(比如密度,摩擦力和恢复系数)。
约束(constraint)
约束(constraint)是一个可以减少body运动自由度的物理连接。一个2D body包含3个可以运动的维度(x轴运动,y轴运动和旋转运动)。考虑将一个body钉在墙上,body此时只能围绕钉子所在的位置旋转(也就是说钉子约束body减少了2个运动维度)。
接触约束(contact constraint)
接触约束(contact constraint)是由Box2D自动创建的用来避免刚体穿透,模拟摩擦力和恢复系数的约束。
关节(joint)
关节(joint)是用来将两个或多个body连接起来的约束(constraint)。
关节限制(joint limit)
关节限制约束了关节的运动范围。类似人类的肘部只能够在特定范围旋转。
关节马达(joint motor)
关节马达可以驱动关节在自由范围内运动。比如,我们可以使用关节马达来驱动肘部旋转。
世界(world)
一个包含了可以发生相互作用的body,fixture和constraint的集合。Box2D允许我们创建多个世界(world),但通常我们只需要一个即可。
求解器(solver)
用于求解接触约束和关节约束。Box2D的求解器非常高效,算法的时间复杂度为O(n),其中n为约束个数。
连续式碰撞(continuous collision)
求解器使用离散的时间点进行碰撞计算,因此对于高速运动的两个body,可能会出现穿透现象。
constexpr
constexpr变量
搬运自:C++11新特性:constexpr变量和constexpr函数
C++11新标准规定,允许将变量声明为constexpr类型以便由编译器验证变量的值是否是一个常量表达式。如果不是,编译器报错。同时,声明为constexpr的变量一定是常量,而且必须用常量表达式初始化。
- 常量表达式
指值不会改变并且在编译过程中就能够得到计算结果的值。
const int max_files = 20; //max_files是常量表达式
const int limit = max_files + 1; //limit是常量表达式
int staff_size = 27; //staff_size不是常量表达式,因为它的数据类型不是const
const int sz = get_size();
//sz不是常量表达式,因为get_size()只有到运行的时候才知道结果,除非它是constexpr修饰的(C++ 11标准)
- constexpr变量
C++11新标准规定,允许将变量声明为constexpr类型以便由编译器验证变量的值是否是一个常量表达式。如果不是,编译器报错。同时,声明为constexpr的变量一定是常量,而且必须用常量表达式初始化。
constexpr int mf = 20; //正确,20是常量表达式
constexpr int limit = mf + 1; //正确,mf + 1是常量表达式,因为mf为常量,故mf + 1也为常量
constexpr int sz = size(); //未知,若size()函数是一个constexpr函数时即正确,反之错误。
int i = 10;
constexpr int t = i; //错误,i不是常量
- 字面值类型
声明constexpr变量时用到的类型被称为字面值类型。算术类型、引用、指针、枚举和一些特殊的类都属于字面值类型,而IO库、string类型则不属于字面值类型,也就不能被定义为constexpr。 - 字面值常量
常量是指用const声明或定义一个变量,使之成为常量。如const int bufSize = 512;#bufSize在程序中将不允许被修改,是常量。而字面值常量是指只能用它的值来称呼的,不能被修改的值,如4、3.1415926、0x24、"BEIJING"。 - 指针与constexpr
对于指针而言,constexpr仅对指针本身有效,与指针所指对象无关。
const int *p = nullptr; //正确,p是一个指向整型常量的指针
constexpr int *q = nullptr; //正确,但q是一个指向 整数 的 常量指针
constexpr指针既可以指向常量也可以指向一个非常量。
constexpr int *np = nullptr; //正确,np是一个指向整数的常量指针,其值为空
int j = 0;
constexpr int i = 42;
//i和j都必须定义在函数体之外,否则constexpr指针无法指向。
constexpr const int *p = &i; /*p是常量指针,指向 整型常量i*/
constexpr int *p1 = &j; //p1是常量指针,指向 整数j(非常量)
constexpr函数
指能用于常量表达式的函数。该函数要遵循规定:函数的返回类型及所有形参的类型都得是字面值类型(声明constexpr变量时用到的类型),并且函数体中必须有且只有一条return语句。
constexpr int new_sz() { return 42; }//constexpr函数
constexpr int foo = new_sz();
//在对变量foo初始化时,编译器把对constexpr函数的调用替换成其结果值。为了能在编译过程中随时展开,constexpr函数被隐式地指定为内联函数。
constexpr函数体内也可以包含其他语句,只要这些语句在运行时不执行任何操作即可。如空语句、类型别名、using声明。
需要注意的是,我们允许constexpr函数的返回值并非一个常量
这里需要弄清楚字面值类型的意义。
//如果arg是常量表达式,则scale(arg)也是常量表达式
constexpr size_t scale(size_t cnt){ return new_sz() * cnt; }
//当scale的实参是常量表达式时,它的表达式也是常量表达式,反之则不然
int arr[scale(2)]; //正确:scale(2)是常量表达式
int i = 2; //i不是常量表达式
int a2[scale(i)]; //错误:scale(i)不是常量表达式
注意,我们要把内联函数和constexpr函数定义在头文件中。
size_t
搬运自:size_t 数据类型
size_t 是一些C/C++标准在stddef.h中定义的,size_t 类型表示C中任何对象所能达到的最大长度,它是无符号整数。
它是为了方便系统之间的移植而定义的,不同的系统上,定义size_t 可能不一样。size_t在32位系统上定义为 unsigned int,也就是32位无符号整型。在64位系统上定义为 unsigned long ,也就是64位无符号整形。size_t 的目的是提供一种可移植的方法来声明与系统中可寻址的内存区域一致的长度。
size_t 在数组下标和内存管理函数之类的地方广泛使用。例如,size_t 用做sizeof 操作符的返回值类型,同时也是很多函数的参数类型,包括malloc 和strlen。
在声明诸如字符数或者数组索引这样的长度变量时用size_t 是好的做法。它经常用于循环计数器、数组索引,有时候还用在指针算术运算上。size_t 的声明是实现相关的。它出现在一个或多个标准头文件中,比如stdio.h 和stblib.h,典型的定义如下:
#ifndef __SIZE_T
#define __SIZE_T
typedef unsigned int size_t;
#endif
define 指令确保它只被定义一次。实际的长度取决于实现。通常在32 位系统上它的长度是32 位,而在64 位系统上则是64 位。一般来说,size_t 可能的最大值是SIZE_MAX。
打印size_t 类型的值时要小心。这是无符号值,如果选错格式说明符,可能会得到不可靠的结果。推荐的格式说明符是%zu。不过,某些情况下不能用这个说明符, 作为替代,可以考虑%u 或%lu。下面这个例子将一个变量定义为size_t,然后用两种不同的格式说明符来打印:
size_t sizet = -5;
printf("%d\n",sizet);
printf("%zu\n",sizet);
因为size_t 本来是用于表示正整数的,如果用来表示负数就会出问题。如果为其赋一个负数,然后用%d 和%zu 格式说明符打印,就得到如下结果:
-5
4294967291
%d 把size_t 当做有符号整数,它打印出-5 因为变量中存放的就是-5。%zu 把size_t 当做无符号整数。当-5 被解析为有符号数时,高位置为1,表示这个数是负数。当它被解析为无符号数时,高位的1 被当做2 的乘幂。所以在用%zu 格式说明符时才会看到那个大整数。
sizet = 5;
printf("%d\n",sizet); // 显示5
printf("%zu\n",sizet); // 显示5
ssize_t
ssize_t 和size_t类似,但必需是signed(表示 signed size_t类型), 用来表示可以被执行读写操作的数据块的大小。
size_t 和 int 比较
- size_t在32位架构中定义为:typedef unsigned int size_t;
- size_t在64位架构中被定义为:typedef unsigned long size_t;
- size_t是无符号的,并且是平台无关的,表示0-MAXINT的范围;int为是有符号的;
- int在不同架构上都是4字节,size_t在32位和64位架构上分别是4字节和8字节,在不同架构上进行编译时需要注意这个问题。
- ssize_t是有符号整型,在32位机器上等同与int,在64位机器上等同与 long int.
explicit
搬运自:C++中explicit的用法
C++提供了关键字explicit,可以阻止不应该允许的经过转换构造函数进行的隐式转换的发生,声明为explicit的构造函数不能在隐式转换中使用。
C++中, 一个参数的构造函数(或者除了第一个参数外其余参数都有默认值的多参构造函数), 承担了两个角色。
1 是个构造;2 是个默认且隐含的类型转换操作符。
所以, 有时候在我们写下如 AAA = XXX, 这样的代码, 且恰好XXX的类型正好是AAA单参数构造器的参数类型, 这时候编译器就自动调用这个构造器, 创建一个AAA的对象。
这样看起来好象很酷, 很方便。 但在某些情况下, 却违背了程序员的本意。 这时候就要在这个构造器前面加上explicit修饰, 指定这个构造器只能被明确的调用/使用, 不能作为类型转换操作符被隐含的使用。
例:
#include <iostream>
using namespace std;
class Test1
{
public :
Test1(int num):n(num){}
private:
int n;
};
class Test2
{
public :
explicit Test2(int num):n(num){}
private:
int n;
};
int main()
{
Test1 t1 = 12;
Test2 t2(13);
Test2 t3 = 14;
return 0;
}
strings字符串工具库
absl::string_view
string_view,顾名思义,提供关联字符串数据的只读视图。通常在您需要访问字符串数据,但不需要拥有它,也不需要修改它是使用。使用时包含absl/strings/string_view.h。
string_view一般用于常量等,由于生命周期问题,string_view通常是返回值的糟糕选择,对于数据成员也是如此。 如果您确实以这种方式使用一个,那么您有责任确保string_view不会比它所指向的对象活得更久。
string_view对象是非常轻量级的,所以你应该总是在你的方法和函数中按值传递它们; 不要传递const absl::string_view &。 (传递absl::string_view而不是const absl::string_view &具有相同的算法复杂性,但由于寄存器分配和参数传递规则,在这种情况下通常按值传递更快。)
字符串分割:absl::StrSplit()
absl::StrSplit()函数提供了一种将字符串拆分为子字符串的简单方法。使用时包含absl/strings/str_split.h。函数使用如下:
// 参数1:要拆分的输入字符串
// 参数2:分隔符,有4中类型:
// ByString:指定分割的字符串,因字符串会被转换absel::ByString类,所以absl::ByString(",")和直接使用","等同。
// ByChar:指定分割的字符,absl::ByChar(',')和直接使用','等同。
// ByAnyChar:指定风格的字符串,只要要才分的输入字符串中包含分割字符串中的字符,都将被分割。absl::ByAnyChar(",=")
// ByLength:按指定的长度分割。absl::ByLenth(5)将会按5个字符的长度风格
// MaxSplits:分割指定次数,比如指定分割为:absl::MaxSplits(',', 1),
// 参数3:可选默认AllowEmpty。
// absl::AllowEmpty返回结果列表包含空字符串,
// absl::SkipEmpty返回结果列表不包含空,
// absl::SkipWhitespace():返回结果列表不包含空格的字符串,不包含空字符串;
// 返回值:所有标准的STL容器,包括std::vector, std::list, std::deque, std::set, std::multiset, std::map, std::multimap,甚至std::pair。容器的数据内容为字符串。
std::vector<std::string> v = absl::StrSplit(" a , ,,b,", absl::ByChar(','), absl::SkipWhitespace());
absl::StrCat()
-
absl::StrCat()将任意数量的字符串或数字合并到一个字符串中。使用时包含absl/strings/str_cat.h。
-
absl::StrCat()的优点:
-
高效:C++修改字符串的开销可能很大,因为字符串通常包含大量的数据,而且许多模式涉及到创建临时副本,这可能会带来很大的开销。absl::StrCat()和absl::StrAppend()通常比+=等操作符更高效,因为它们不需要创建临时std::string对象,并且在字符串构造过程中预先分配它们的内存。
-
支持数据类型格式化
支持的类型如下:
- std::string
- absl::string_view
- 字符串
- 数值类型 (floats, ints),浮点类型6位精度,当幅度小于0.001或大于或等于1e+6时使用“e”格式
- 布尔 (convert to “0” or “1”)
- 二进制:Hex values through use of the absl::Hex() conversion function
-
-
使用演示:
std::string s1 = "value1";
absl::string_view s2 = "value2";
auto result = absl::StrCat(s1, ",",
s2, ",",
"value3", ",",
4, ",",
5.1f, ",",
true, ",",
absl::Hex(10, absl::kZeroPad2), ",",
absl::Dec(11, absl::kZeroPad10));
std::cout << result << std::endl;
// 输出结果为:value1,value2,value3,4,5.1,1,0a,0000000011
字符串追加:absl::StrAppend()
将一个字符串或一组字符串追加到现有的字符串中 。使用时包含absl/strings/str_cat.h。其他使用同absl::StrCat()
std::string s1 = "value1";
absl::string_view s2 = "value2";
std::string result = "the result:";
absl::StrAppend(&result, ",",
s2, ",",
"value3", ",",
4, ",",
5.1f, ",",
true, ",",
absl::Hex(10, absl::kZeroPad2), ",",
absl::Dec(11, absl::kZeroPad10));
std::cout << result << std::endl;
// 输出结果为:the result:,value2,value3,4,5.1,1,0a,0000000011
字符串合并:absl::StrJoin()
字符串合并。使用时包含absl/strings/str_join.h。
#include "absl/strings/str_join.h"
#include <iostream>
#include <map>
#include <vector>
int main(int argc, char *argv[])
{
{
//Example 1:
// Joins a collection of strings. This pattern also works with a collection
// of `absl::string_view` or even `const char*`.
std::vector<std::string> v = {"foo", "bar", "baz"};
std::string s = absl::StrJoin(v, "-");
// 输出:foo-bar-baz
std::cout << s << std::endl;
}
{
//Example 2:
// Joins the values in the given `std::initializer_list<>` specified using
// brace initialization. This pattern also works with an initializer_list
// of ints or `absl::string_view` -- any `AlphaNum`-compatible type.
std::string s = absl::StrJoin({"foo", "bar", "baz"}, "-");
// 输出:foo-bar-baz
std::cout << s << std::endl;
}
{
//Example 3:
// Joins a collection of ints. This pattern also works with floats,
// doubles, int64s -- any `StrCat()`-compatible type.
std::vector<int> v = {1, 2, 3, -4};
std::string s = absl::StrJoin(v, "-");
// 输出:1-2-3--4
std::cout << s << std::endl;
}
{
//Example 4:
// Joins a collection of pointer-to-int. By default, pointers are
// dereferenced and the pointee is formatted using the default format for
// that type; such dereferencing occurs for all levels of indirection, so
// this pattern works just as well for `std::vector<int**>` as for
// `std::vector<int*>`.
int x = 1, y = 2, z = 3;
std::vector<int*> v = {&x, &y, &z};
std::string s = absl::StrJoin(v, "-");
// 输出:1-2-3
std::cout << s << std::endl;
}
{
//Example 5:
// Dereferencing of `std::unique_ptr<>` is also supported:
std::vector<std::unique_ptr<int>> v;
v.emplace_back(new int(1));
v.emplace_back(new int(2));
v.emplace_back(new int(3));
std::string s = absl::StrJoin(v, "-");
// 输出:1-2-3
std::cout << s << std::endl;
}
{
//Example 6:
// Joins a `std::map`, with each key-value pair separated by an equals
// sign. This pattern would also work with, say, a
// `std::vector<std::pair<>>`.
std::map<std::string, int> m = {
std::make_pair("a", 1),
std::make_pair("b", 2),
std::make_pair("c", 3)};
std::string s = absl::StrJoin(m, ",", absl::PairFormatter("="));
// 输出:a=1,b=2,c=3
std::cout << s << std::endl;
}
{
//Example 7:
// These examples show how `absl::StrJoin()` handles a few common edge
// cases:
std::vector<std::string> v_empty;
// 输出:
std::cout << absl::StrJoin(v_empty, "-") << std::endl;
std::vector<std::string> v_one_item = {"foo"};
// 输出:foo
std::cout << absl::StrJoin(v_one_item, "-") << std::endl;
std::vector<std::string> v_empty_string = {""};
// 输出:
std::cout << absl::StrJoin(v_empty_string, "-") << std::endl;
std::vector<std::string> v_one_item_empty_string = {"a", ""};
// 输出:a-
std::cout << absl::StrJoin(v_one_item_empty_string, "-") << std::endl;
std::vector<std::string> v_two_empty_string = {"", ""};
// 输出:-
std::cout << absl::StrJoin(v_two_empty_string, "-") << std::endl;
}
{
//Example 8:
// Joins a `std::tuple<T...>` of heterogeneous types, converting each to
// a std::string using the `absl::AlphaNum` class.
std::string s = absl::StrJoin(std::make_tuple(123, "abc", 0.456), "-");
// 输出:123-abc-0.456
std::cout << s << std::endl;
}
return 0;
}
格式字符串:absl::Substitute
格式化字符串。Substitute使用一个格式字符串,该格式字符串包含由美元符号($)表示的位置标识符和单个数字位置标识符,以指示在格式字符串中的该位置使用哪个替换参数。使用时包含absl/strings/str_format.h。
absl::Substitute与sprintf()有以下不同之处:
- 不需要管理格式化缓冲区的内存。
- 格式字符串不标识参数的类型。 相反,参数被隐式转换为字符串。
- 格式字符串中的替换由’ $ '后跟一个数字标识。 可以乱序使用参数,并多次使用同一个参数。
- 格式字符串中的’ $$ ‘序列意味着输出一个字面’ $ '字符。
- absl::Substitute()明显比sprintf()快。 对于非常大的字符串,可能要快几个数量级。
由于absl::Substitute()需要在运行时解析格式字符串,所以它比absl::StrCat()要慢。 只有当代码的清晰性比速度更重要时,才选择Substitute()而不是StrCat()。
支持类型:
absl::string_view,std::string,const char*(null is equivalent to “”)int32_t,int64_t,uint32_t,uint64_tfloat,doublebool(Printed as “true” or “false”)- pointer types other than char* (Printed as
0x<lower case hex string>, except that null is printed as “NULL”)
演示使用:
std::string s = absl::Substitute("$1 purchased $0 $2. Thanks $1!", 5, "Bob", "Apples");
// Produces the string "Bob purchased 5 Apples. Thanks Bob!"
std::string s = "Hi. ";
absl::SubstituteAndAppend(&s, "My name is $0 and I am $1 years old.", "Bob", 5);
// Produces the string "Hi. My name is Bob and I am 5 years old."
字符串匹配类
使用时包含absl/strings/match.h。
// Returns whether a given string `haystack` contains the substring `needle`.
inline bool StrContains(absl::string_view haystack,
absl::string_view needle) noexcept;
// Returns whether a given string `text` begins with `prefix`.
inline bool StartsWith(absl::string_view text,
absl::string_view prefix) noexcept;
// Returns whether a given string `text` ends with `suffix`.
inline bool EndsWith(absl::string_view text,
absl::string_view suffix) noexcept;
// Returns whether given ASCII strings `piece1` and `piece2` are equal, ignoring
// case in the comparison.
bool EqualsIgnoreCase(absl::string_view piece1,
absl::string_view piece2) noexcept;
// Returns whether a given ASCII string `text` starts with `prefix`,
// ignoring case in the comparison.
bool StartsWithIgnoreCase(absl::string_view text,
absl::string_view prefix) noexcept;
// Returns whether a given ASCII string `text` ends with `suffix`, ignoring
// case in the comparison.
bool EndsWithIgnoreCase(absl::string_view text,
absl::string_view suffix) noexcept;
字符串替换:absl::StrReplaceAll
使用时包含absl/strings/str_replace.h。
std::string s = absl::StrReplaceAll(
"$who bought $count #Noun. Thanks $who!",
{{"$count", absl::StrCat(5)},
{"$who", "Bob"},
{"#Noun", "Apples"}});
-
去掉固定字符串
使用时包含absl/strings/strip.h。
// 去掉字符串的固定字符的前缀
bool ConsumePrefix(absl::string_view* str, absl::string_view expected);
absl::string_view StripPrefix(absl::string_view str, absl::string_view prefix);
// 去掉字符串的固定字符的后缀
bool ConsumeSuffix(absl::string_view* str, absl::string_view expected);
absl::string_view StripSuffix(absl::string_view str, absl::string_view suffix)
-
字符串和数字之前的转换
-
字符串转数字
使用时包含absl/strings/numbers.h。
absl::SimpleAtoi()将字符串转换为整型。
absl::SimpleAtof()将字符串转换为浮点数。
absl::SimpleAtod()将字符串转换为double类型。
absl::SimpleAtob()将字符串转换为布尔值。
absl::SimpleHexAtoi将十六进制字符串转换为整数。
-
数字转字符串
要将数值类型转换为字符串,请使用absl::StrCat()和absl::StrAppend()。 可以使用StrCat/StrAppend将int32、uint32、int64、uint64、float和double类型转换为字符串。
-
内存缓冲区: absl::CordBuffer
CordBuffer为一些目的管理内存缓冲区,例如零复制api,以及构建大数据连接的应用程序,这些应用程序需要对连接数据的分配和大小进行细粒度控制。使用时包含absl/strings/cord_buffer.h。
字符串序列:absl::Cord
Cord是一个字符序列,在某些情况下设计成比’ std::string '更高效:也就是说,需要在其生命周期内更改或共享的大型字符串数据,特别是当这些数据跨API边界共享时。
字符串格式化: absl::str_format
str_format库是标准库标头中的printf()字符串格式化例程的类型安全替代品。 str_format库提供了printf()类型字符串格式化的大部分功能和一些额外的好处:
-
类型安全,包括对std::string和absl::string_view的本机支持
-
独立于标准库的可靠行为
-
支持POSIX位置扩展
-
本机支持Abseil类型,如absl::Cord,并可扩展以支持其他类型。
-
比本机printf函数快得多(通常快2到3倍)
-
可流化到各种现有的接收器
-
可扩展到自定义接收器
其他关于字符的工具库
详细可以参看absl/strings/ascii.h
// `ascii_isalnum()`, `ascii_isalpha()`, `ascii_isascii()`, `ascii_isblank()`,
// `ascii_iscntrl()`, `ascii_isdigit()`, `ascii_isgraph()`, `ascii_islower()`,
// `ascii_isprint()`, `ascii_ispunct()`, `ascii_isspace()`, `ascii_isupper()`,
// `ascii_isxdigit()`
// `ascii_tolower()`, `ascii_toupper()`
条件运算符
?:三目运算符
表达式1 ? 表达式2 : 表达式3
相当于:
if (表达式1)
表达式2
else
表达式3
inline
搬运自:C++ 中的 inline 用法
1、引入 inline 关键字的原因
在 c/c++ 中,为了解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题,特别的引入了 inline 修饰符,表示为内联函数。
栈空间就是指放置程序的局部数据(也就是函数内数据)的内存空间。
在系统下,栈空间是有限的,假如频繁大量的使用就会造成因栈空间不足而导致程序出错的问题,如,函数的死循环递归调用的最终结果就是导致栈内存空间枯竭。
下面我们来看一个例子:
#include <stdio.h>
inline const char *num_check(int v)
{
return (v % 2 > 0) ? "奇" : "偶";
}
int main(void)
{
int i;
for (i = 0; i < 100; i++)
printf("%02d %s\n", i, num_check(i));
return 0;
}
上面的例子就是标准的内联函数的用法,使用 inline 修饰带来的好处我们表面看不出来,其实,在内部的工作就是在每个 for 循环的内部任何调用 dbtest(i) 的地方都换成了 (i%2>0)?“奇”:“偶”,这样就避免了频繁调用函数对栈内存重复开辟所带来的消耗。
2、inline使用限制
inline 的使用是有所限制的,inline 只适合涵数体内代码简单的涵数使用,不能包含复杂的结构控制语句例如 while、switch,并且不能内联函数本身不能是直接递归函数(即,自己内部还调用自己的函数)。
3、inline仅是一个对编译器的建议
inline 函数仅仅是一个对编译器的建议,所以最后能否真正内联,看编译器的意思,它如果认为函数不复杂,能在调用点展开,就会真正内联,并不是说声明了内联就会内联,声明内联只是一个建议而已。
4、建议 inline 函数的定义放在头文件中
其次,因为内联函数要在调用点展开,所以编译器必须随处可见内联函数的定义,要不然就成了非内联函数的调用了。所以,这要求每个调用了内联函数的文件都出现了该内联函数的定义。
因此,将内联函数的定义放在头文件里实现是合适的,省却你为每个文件实现一次的麻烦。
声明跟定义要一致:如果在每个文件里都实现一次该内联函数的话,那么,最好保证每个定义都是一样的,否则,将会引起未定义的行为。如果不是每个文件里的定义都一样,那么,编译器展开的是哪一个,那要看具体的编译器而定。所以,最好将内联函数定义放在头文件中。
5、类中的成员函数与inline
定义在类中的成员函数默认都是内联的,如果在类定义时就在类内给出函数定义,那当然最好。如果在类中未给出成员函数定义,而又想内联该函数的话,那在类外要加上 inline,否则就认为不是内联的。
class A
{
public:void Foo(int x, int y) { } // 自动地成为内联函数
}
将成员函数的定义体放在类声明之中虽然能带来书写上的方便,但不是一种良好的编程风格,上例应该改成:
// 头文件
class A
{
public:
void Foo(int x, int y);
}
// 定义文件
inline void A::Foo(int x, int y){}
6、inline 是一种"用于实现的关键字"
关键字 inline 必须与函数定义体放在一起才能使函数成为内联,仅将 inline 放在函数声明前面不起任何作用。
如下风格的函数 Foo 不能成为内联函数:
inline void Foo(int x, int y); // inline 仅与函数声明放在一起
void Foo(int x, int y){}
而如下风格的函数 Foo 则成为内联函数:
void Foo(int x, int y);
inline void Foo(int x, int y) {} // inline 与函数定义体放在一起
所以说,inline 是一种"用于实现的关键字",而不是一种"用于声明的关键字"。一般地,用户可以阅读函数的声明,但是看不到函数的定义。尽管在大多数教科书中内联函数的声明、定义体前面都加了inline 关键字,但我认为inline不应该出现在函数的声明中。这个细节虽然不会影响函数的功能,但是体现了高质量C++/C 程序设计风格的一个基本原则:声明与定义不可混为一谈,用户没有必要、也不应该知道函数是否需要内联。
7、慎用 inline
内联能提高函数的执行效率,为什么不把所有的函数都定义成内联函数?如果所有的函数都是内联函数,还用得着"内联"这个关键字吗?
内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。
如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
以下情况不宜使用内联:
(1)如果函数体内的代码比较长,使用内联将导致内存消耗代价较高。
(2)如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开销大。类的构造函数和析构函数容易让人误解成使用内联更有效。要当心构造函数和析构函数可能会隐藏一些行为,如"偷偷地"执行了基类或成员对象的构造函数和析构函数。所以不要随便地将构造函数和析构函数的定义体放在类声明中。一个好的编译器将会根据函数的定义体,自动地取消不值得的内联(这进一步说明了 inline 不应该出现在函数的声明中)。
CHECK 宏
搬运自:Google glog 使用
当通过该宏指定的条件不成立的时候,程序会中止,并且记录对应的日志信息。功能类似于ASSERT,区别是 CHECK 宏不受 NDEBUG 约束,在 release 版中同样有效。
我个人感觉这类CHECK_XX宏比上面的LOG宏实现的还要隐晦难懂,当然设计的还是很巧妙的,值得学习一下,我尝试做个分析。
在测试工程的logging_unittest.cc文件line535的TestCHECK()函数中有如下代码:
CHECK_NE(1, 2);
CHECK_GE(1, 1);
CHECK_GE(2, 1);
CHECK_LE(1, 1);
CHECK_LE(1, 2);
定义如下:
#define CHECK_EQ(val1, val2) CHECK_OP(_EQ, ==,val1, val2)
#define CHECK_NE(val1, val2) CHECK_OP(_NE, !=,val1, val2)
#define CHECK_LE(val1, val2) CHECK_OP(_LE, <=,val1, val2)
#define CHECK_LT(val1, val2) CHECK_OP(_LT, < ,val1, val2)
#define CHECK_GE(val1, val2) CHECK_OP(_GE, >=,val1, val2)
#define CHECK_GT(val1, val2) CHECK_OP(_GT, > ,val1, val2)
其中CHECK_OP宏定义如下:
#define CHECK_OP(name, op, val1, val2) \
CHECK_OP_LOG(name, op, val1, val2, google::LogMessageFatal)
而CHECK_OP_LOG宏定义如下:
typedef std::string_Check_string;
#define CHECK_OP_LOG(name, op, val1, val2,log) \
while(google::_Check_string* _result = \
google::Check##name##Impl( \
google::GetReferenceableValue(val1), \
google::GetReferenceableValue(val2), \
#val1 " " #op " " #val2)) \
log(__FILE__, __LINE__, \
google::CheckOpString(_result)).stream()
接下来我们以CHECK_LE(1,2);为例,将其逐步扩展:
CHECK_LE(1, 2)
------>CHECK_OP(_LE, <=, 1, 2)
------>CHECK_OP_LOG(_LE, <=, 1, 2,google::LogMessageFatal)
------>#define CHECK_OP_LOG(_LE, <=, 1, 2,google::LogMessageFatal) \
while (std::string* _result = \
google::Check_LEImpl( \
1, \
2, \
"1<= 2")) \
log(__FILE__,__LINE__, \
google::CheckOpString(_result)).stream()
其中google::Check_LEImpl也是通过宏预先实现的,这个宏就是DEFINE_CHECK_OP_IMPL(Check_LE,<=):
#define DEFINE_CHECK_OP_IMPL(name, op) \
template<typename T1, typename T2> \
inlinestd::string* name##Impl(const T1& v1, const T2& v2, \
const char*exprtext) { \
if(GOOGLE_PREDICT_TRUE(v1 op v2)) return NULL; \
elsereturn MakeCheckOpString(v1, v2, exprtext); \
} \
inlinestd::string* name##Impl(int v1, int v2, const char* exprtext) { \
returnname##Impl<int, int>(v1, v2, exprtext); \
}
展开后就实现了google::Check_LEImpl函数(其他与此类似,这里只以“<=”为例说明):
CHECK_LE(1, 2) ------>
while (std::string* _result =google::Check_LEImpl(1, 2, "1<= 2"))
log(__FILE__,__LINE__,google::CheckOpString(_result)).stream()
其中google::Check_LEImpl又调用了模板实现的Check_LEImpl,该函数根据两个参数v1、v2和操作符op决定了要么返回NULL,要么返回一个string*,如果返回NULL,则不再执行下面的输出,否则则输出日志信息。
至此,就完成了CHECK_LE(1,2)的扩展,如果检测为true,则返回NULL,否则就会返回一个有明确提示信息的字符串指针,并输出该信息,然后是程序宕掉。
resize()函数
搬运自:C++中的resize()函数
函数原型
void resize (size_type n);
void resize (size_type n, const value_type& val);
作用
改变容器的大小,使得其包含n个元素。常见三种用法。
1、如果n小于当前的容器大小,那么则保留容器的前n个元素,去除(erasing)超过的部分。
2、如果n大于当前的容器大小,则通过在容器结尾插入(inserting)适合数量的元素使得整个容器大小达到n。且如果给出val,插入的新元素全为val,否则,执行默认构造函数。
3、如果n大于当前容器的容量(capacity)时,则会自动重新分配一个存储空间。
注意:如果发生了重新分配,则使用容器的分配器分配存储空间,这可能会在失败时抛出异常。
指针
指针的定义与使用
指针是高级编程语言中非常重要的概念,在高级语言的编程中发挥着非常重要的作用,它能使得不同区域的代码可以轻易的共享内存数据。指针使得一些复杂的链接性的数据结构的构建成为可能,有些操作必须使用指针,比如申请堆内存,还有C++或者C语言中函数的调用中值传递都是按值传递的,如果在函数中修改被传递的对象,就必须通过这个对象指针来完成。指针就是内存地址,指针变量就是用来存放内存地址的变量,不同类型的指针变量所占用的存储单元长度是相同的,而存放数据的变量因为数据类型不同,因此所占的存储空间长度也不同。使用指针不仅可以对数据本身,也可以对存储数据变量的地址进行操作。很多萌新在刚开始学习编程的时候会被指针搞蒙,那现在就让我给大家详细讲解指针的使用。
1、指针的引入(函数返回中return语句的局限性)
函数的缺陷:
一个函数只能返回一个值,就算我们在函数里面写多了return语句,但是只要执行任何一条return语句,整个函数调用就结束了。
数组可以帮助我们返回多个值,但是数组是相同数据类型的结合,对于不同数据类型则不能使用数组
使用指针可以有效解决这个问题,使用指针我们想反回几个值就能返回几个值,想返回什么类型就可以返回什么类型的值。在程序设计过程中,存入数据还是取出数据都需要与内存单元打交道,计算机通过地址编码来表示内存单元。指针类型就是为了处理计算机地址数据的,计算机将内存划分为若干个存储空间大小的单元,每个单元大小就是一个字节,即计算机将内存换分为一个一个的字节,然后为每一个字节分配唯一的编码,这个编码即为这个字节的地址。指针就是用来表示这些地址的,即指针型数据不是什么字符型数据,而存的是我们内存中的地址编码。指针可以提高程序的效率,更重要的是能使一个函数访问另一个函数的局部变量,指针是两个函数进行数据交换必不可少的工具。
地址及指针的概念:
程序中的数据(变量,数组等)对象总是存放在内存中,在生命期内这些对象占据一定的内存空间,有确定的存储位置,实际上,每个内存单元都有一个地址,即以字节为单位连续编码。编译器将程序中的对象名转换成机器指令识别的地址,通过地址来存储对象值。
int i; double f;
计算机为int 类型数据分配4个字节,为double 类型分配8个字节。按对象名称存取对象的方式成为对象直接访问,如:i=100; f=3.14; 通过对象地址存取对象的方式成为指针间接访问
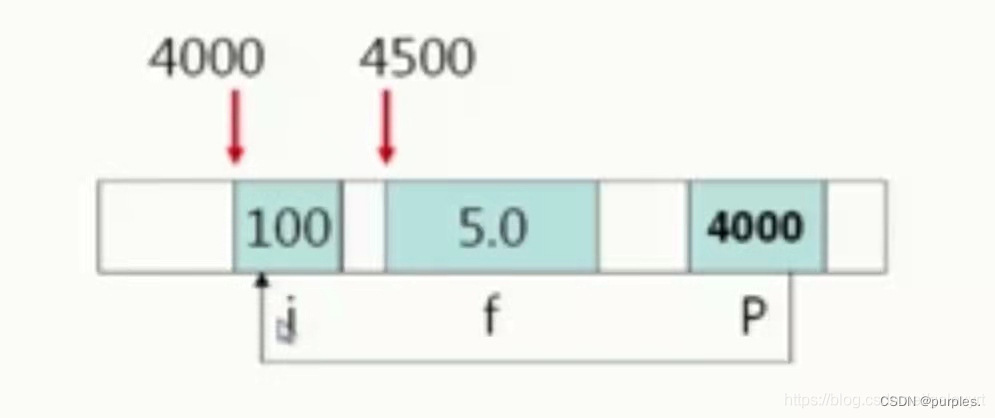
如图,这里有一个名为4000的存储空间它放的不是数值,而是 i 这个变量的地址,i 占有四个字节每个字节都有一个地址,这个变量的地址其实就是第一个字节的地址,在这里 i 的地址指就是他第一个字节的地址,假设第一个地址是4000,这里有一个p,先不管他是个啥东西,他占了一段存储空间,他里面放的就是 i 的地址,现在我们要访问 i 但是我们不直接访问,不出现 i 的名字,而是通过找到 p 得到了p里面放的 i 的地址以后就能间接的去访问 i ,就是说我们不是直接访问这个地址的,而是通过 P 这个量去访问 i 的值,这样的访问方式就叫做指针间接访问。即通过对象的地址来存储对象的方式称为指针间接访问。
2、指针的定义形式方法及其含义
c++将专门用来存放对象地址的变量叫做指针变量,下面是指针变量定义形式:
指针类型* 指针变量名;
例如:
int* p, i; //定义指针变量p,i为整形变量
p = &i; //指针变量p指向i
把 i 的地址放到p
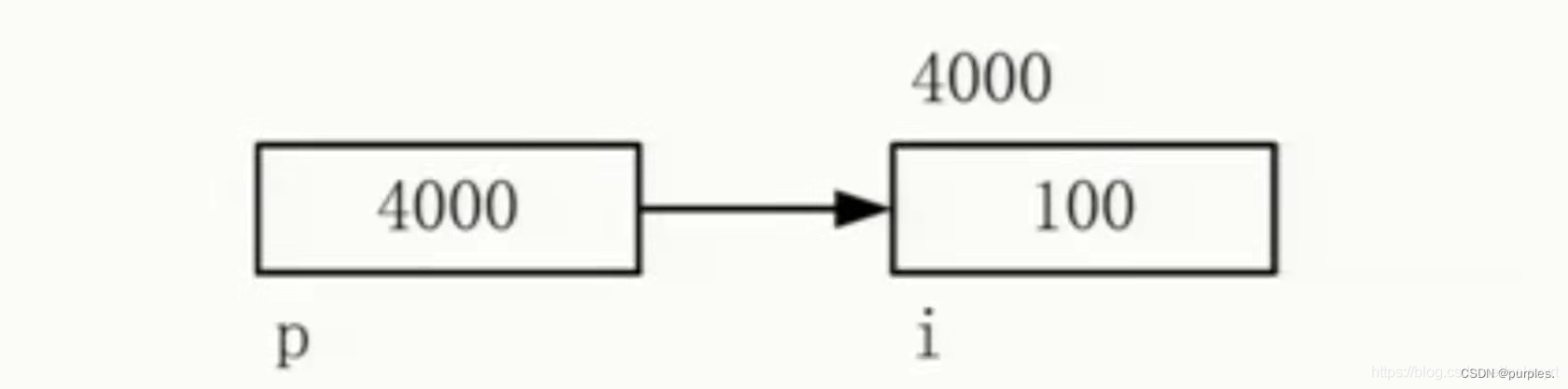
i 里放的是100这个数他的地址是4000,p里面放的就是i 的地址,然后就将p 指向i,他俩的关系即为p指向i,

假定指针变量p 的值是4000,三种写法:
char* p;
int* p;
double* p;
指针的类型其实就是它所指向的对象的类型
指针的类型:
指针的类型表明的就是他所指向的对象的类型,把p定义为char类型,即用char类型的指针P来间接访问它指向的对象时我们间接引用的是一个字节的空间,假设p放的是4000,则系统会默认p指向的是4000这一个字节里面的内容,若将p定义成整形那么意味着我们用间接引用的方式来用指针指向对象的时候,系统就会认为你 的指针占4个字节这个对象就是4000,4001, 4002, 4003 这四个字节共同组成这个对象,若定义为double类型,那么系统就会认为他指向的对象时8个字节的即4000~~4007这八个字节都认为是P所指向的对象。这就是指针类型的含义,指针的类型应该和他指向的对象的类型一致,即整形指针应该指向整形变量,实型指针指向实型的变量。
3、通过指针间接访问
通过间接引用运算 * 可以访问指针所指向的对象或者内存单元,即在指针前面加上一个 * 就表明指针所引用的东西
int a, * p = &a;
a = 100;//直接访问a(对象直接访问)
*p = 100;//*p就是a,间接访问a(指针间接访问)
*p = *p + 1;//等价于a=a+1
int a, b, * p1 = &a, * p2;
&*p1 的含义:
&和*都是自右向左运算符,因此先看p1是指针,*p1即为p1指向的对象,
因此*p1等价于a,因此a 的前面加一个&,表示的就是 a 的地址
因此:&*p1 ,p1 ,&a 三者等价
*&a 的含义:a的地址前加*表示的就是a本身,指针就是用来放地址的,地址前面加*表示的就是这个对象
因此: *&a ,a ,*p 三者等价
int main()
{
int i = 100, j = 200;
int* p1, * p2;
p1 = &i, p2 = &j;//p1指向i,p2指向j
*p1 = *p1 + 1;//等价于i=i+1
p1 = p2;//将p2的值赋给p1,则p1指向j
*p1 = *p1 + 1;//等价于j=j+1
return 0;
}
4、指针的初始化,可以在定义指针时对它进行初始化
指针类型* 指针变量名 = 地址初值,......
int a;
int* p = &a;//p的初值为变量a 的地址
int b, * p1 = &b;//p1初始化是变量b已有地址值
由于指针数据的特殊性,他的初始化和赋值运算是有约束条件的,只能使用以下四种值:
(1)0值常量表达式:
int a, z = 0;
int p1 = null; //指针允许0值常量表达式
p1 = 0;//指针允许0只常量表达式
下面三中形式是错误的:
int* p1 = a;//错误 地址初值不能是变量
int p1 = z;//错误 整形变量不能作为指针,即使值为0
p1 = 4000;//错误,指针允许0值常量表达式
(2)相同指向类型的对象的地址。
int a, * p1;
double f, * p3;
p1 = &a;
p3 = &f;
p1 = &f;//错误p1和f指向类型不同
(3)相同指向类型的另一个有效指针
int x, * px = &x;
int* py = px;//相同指向类型的另一个指针
(4)对象存储空间后面下一个有效地址,如数组下一个元素的地址
int a[10], * px = &a[2];
int* py = &a[++i];
5、指针运算
指针运算都是作用在连续存储空间上才有意义。
(1)指针加减整数运算
int x[10], n = 3, * p = &x[5];
p + 1 //指向内存空间中x[5]后面的第1个int 型存储单元
p + n //--------------------------n(3)个
p - 1 //-------------------前面-----1个
p - n //
(2)指针变量自增自减运算
int x[10], * p = &x[5];
p++ //p指向x[5]后面的第1个int型内存单元
++p //-----------------1--------------
p-- //p指向x[5]前面的第1个int型内存单元
--p //--------------------------------
(3)两个指针相减运算
设p1, p2是相同类型的两个指针,则p2 - p1的结果是两支针之间对象
的个数,如果p2指针地址大于p1则结果为正,否则为负
int x[5], * p1 = &x[0], * p2 = &x[4];
int n;
n = p2 - p1;//n 的值为4 即为他们之间间隔的元素的个数
运算方法:(p2储存的地址编码-p1储存的地址编码)/4 若是double类型则除以8 char类型除以1
(1)指针加减整数运算
int x[10], n = 3, * p = &x[5];
p + 1 //指向内存空间中x[5]后面的第1个int 型存储单元
p + n //--------------------------n(3)个
p - 1 //-------------------前面-----1个
p - n //
(4)指针的运算关系
设p1、p2是同一个指向类型的两个指针,则p1和p2可以进行关系运算,
用于比较这两个地址的位置关系即哪一个是靠前或者靠后的元素
int x[4], * p1 = &x[0], * p2 = &x[4];
p2 > p1; //表达式为真
6、指针的const限定
(1)一个指针变量可以指向只读型对象,称为指向const对象的指针定义形式是:
const 指向类型 *指针变量,...
即在指针变量前加const限定符,其含义是不允许通过指针来改变所指向的const对象的值,不能通过间接引用来改变它所指向的对象的值
const int a = 10, b = 20;
const int* p;
p = &a;//正确 p不是只读的,把a的地址赋给p,给p赋值是允许的
p = &b;//正确,p不是只读的
*p = 42;//把42赋给p所指向的对象。错误,*p是只读的
(2)把一个const对象的地址赋给一个非const对象的指针是错误的,例如:
const double pi = 3.14;
double* ptr = π//错误,ptr是非const所指向的变量
const double* cptr = π//正确,cptr是const指针变量
(3)允许把非const对象的地址赋给指向const对象的指针,不能使用指向const对象的指针修改指向对象,然而如果该指针指向的是一个非const对象,可以用其他方法修改其所指向的对象
const double pi = 3.14;
const double* cptrf = π//正确
double f = 3.14;//f是double类型(非const类型)
cptr = &f;//正确,允许将f的地址赋给cptrf
f = 1.68;//正确,允许修改f的值
*cptrf = 10.3;//错误不能通过引用cptr修改f的值
(4)实际编程过程中,指向const的指针常用作函数的形参,以此确保传递给函数的参数对象在函数中不能被修改
void fun(const int* p)
{
...
}
int main()
{
int a;
fun(&a);
}
/*
指针作为函数的形参,在主函数中,我们定义整形变量a然后将a的地址传递给了子函数,对于子函数来说,
他的形参就是用const修饰过 的整型变量p指向主函数里a这个变量
这样的一系列操作就使得我们不能在子函数中通过p间接引用a 来改变a 的值,因为a 是用const修饰过的作就使得我们不能在子函数中通过p间接引用a 来改变a 的值,因为a 是用const修饰过的
*/
7、const指针
一个指针变量可以是只读的,成为const指针它的定义形式:
指针类型* const 指针变量, ...;
注意观察将const放在变量名的前面,与上面的形式不同,
int a = 10, b = 20;
int* const pc = &a;//pc是const指针
pc = &b;//错误pc 是只读的
pc = pc;//错误pc是只读的
pc++;//错误pc是只读的
*pc = 100;//正确,a被修改
pc是指向int型对象的const指针
不能使pc再被赋值指向其他对象,任何企图给const指针赋值的操作都会导致编译错误
但是可以通过pc间接引用修改该对象的值
一维数组与指针
1、数组的首地址
数组有若干个元素组成,每个元素都有相应的地址,通过取地址运算符&可以得到每个元素的地址,数组的地址就是这一整块存储空间中,第一个元素的地址即a[0]
int a[10];
int* p = &a[0];//定义指向一维数组元素的指针,用a数组的地址来初始化p,称p指向a
p = &a[5];//指向a[5] 重新给p赋值,指针数组元素的地址跟取变量的地址是一样的效果,
c++中规定数组名既代表数组本身,又代表整个数组的地址,还是数组首元素的地址值即:与a第0个元素的地址& a[0]相同
例如:
下面两个语句是等价的:
p = a;
p = &a[0];
数组名是一个指针常量,因而他不能出现在左值和某些算数运算中
例如:
int a[10], b[10], c[10];
a = b;//错误,a是常量,不能出现在左值的位置
c = a + b;//错误,a,b是地址值,不允许加法运算
a++;//错误,a 是常量不能使用++运算
2、指向一维数组的指针变量
定义指向一维数组元素的指针变量时,指向类型应该与数组元素类型一致
int a[10], * p1;
double f[10], * p2;
p1 = a;//正确
p2 = f;//正确
p1 = f;//错误,指向类型不同不能赋值
3、通过指针访问一维数组
由于数组的元素地址是规律性增加的,根据指针 运算规律,可以利用指针及其运算来访问数组元素
int* p, a[10] = { 1,2,3,4,5,6,7,8,9,0 };
p = a;//指向数组a,其实就是让p指向了a[0]
p++;//指向了下一个数组元素即a[1]

根据上图,我们设:
a是一个一维数组,p是指针变量,且p=a;下面我们来访问一个数组元素 a[i];
(1)数组下标法:a[i];
(2)指针下标法:p[i]; p里面已经放了数组的地址了,因此数组名和p 是等价的所以 p[i]与a[i]含义相同
(3)地址引用法:(a+i); a表示的是下标为0 的元素的地址 (a+i) 即为a这个数组往后数第 i 个元素的地址 即第 i 个元素的地址 那么(a+i)相当于地址再加一个星号表示的就是这个地址对应的存储单元,或者说对应的对像即为 a[i]这个元素
(4)指针引用法:*(p+i);将a替换成p跟(3)含义相同
下面我们用多种方法来遍历一维数组元素:
(1)下标法:优点是程序写法直观,能直接知道访问的是第几个元素
#include<iostream>
using namespace std;
int main()
{
int a[4];
for (int i = 0; i < 4; i++)
cin >> a[i];
for (int i = 0; i < 4; i++)
cout << a[i] << " ";
return 0;
}
(2)通过地址间接访问数组元素
#include<iostream>
using namespace std;
int main()
{
int a[5],i;
for (i = 0; i < 5; i++)
cin >> *(a + i);
for (i = 0; i < 5; i++)
cout << *(a + i) << " ";
}
(3)通过指向数组的指针变量间接访问数组,用指针作为循环控制变量 优点是指针直接指向元素,不必每次都重新计算地址,能提高运行效率(我们用P某一个元素的时候p本身已经放了这个元素的地址,因此计算机就不用再去计算这个元素的地址,因为取一个元素的时候要先知道他的地址),将自增自减运算用于指针变量十分有效,可以使指针变量自动向前或者向后指向数组的下一个或前一个元素
#include<iostream>
using namespace std;
int main()
{
int a[5], * p;
for (p = a; p < a + 5; p++)
cin >> *p;
for (p = a; p < a + 5; p++)
cout << *p << " ";
}
指针p初值为a,即一开始指向元素a[0],指针可以进行比较运算 p
cin>>*p;即为间接的引用了p所指向的数组元素。
用指针来操纵字符串
可以利用一个字符型的指针来处理字符串,其中过程与通过指针访问数组元素相同,使用指针可以简化字符串的处理。
c++允许定义一个字符指针,初始化是指向一个字符常量,一般形式为:
char* p = "C Language";
或者
char* p;
p="C Language"
初始化时,p存储了这个字符串字符地址,而不是字符串常量本身,相当于char类型的指针指向"C Language"这个字符串的首地址,即第一个元素C的地址称p指向字符串
下面我们通过字符串指针来访问字符串
char str[] = "C Language", * p = str;//p指向字符串的指针相当于p指向了str[0]
cout << p << endl;//输出:C Language 跟cout<<str<<endl;效果相同
cout << p + 2 << endl;//输出:Language 从字符L开始输出直到结束
cout << &str[7] << endl;//输出:age 从第7个元素开始输出
#include<iostream>
using namespace std;
int main()
{
char str[] = "C language", * p = str;
cout << p << endl;
return 0;
}
//运行结果:C language
#include<iostream>
using namespace std;
int main()
{
char str[] = "C language";
char* p = str;
cout << p+2 << endl;
return 0;
}
//运行结果:language
#include<iostream>
using namespace std;
int main()
{
char str[] = "C Language";
char* p = str;
cout << p << endl;
cout << p+2 << endl;
cout << &str[7] << endl;
return 0;
}
//运行结果:
//C language
//language
//age
通过字符指针来遍历字符串
char str[] = "C Language", * p = str;
while (*p!='\0')cout << *p++;
判断p指向的元素是不是字符串结束的标志*p++ 的含义:先输出p指向的元素然后p++(后置增增,先做完其他事再自增)
假设从str[0]开始,p指向的是C满足(*p!='\0')因此执行循环,下一个循环p指向“空格”不是字符串结束的标志,继续
循环直到遇到字符串结束的标志后结束循环
举例:
#include<iostream>
using namespace std;
int main()
{
char str[100], * p = str;
cin >> str;
while (*p)p++;
cout << "strlen=" << p - str << endl;
return 0;
}
//输出:
//bjfu
//strlen=4
while(*p)p++;的含义:进入循环判断逻辑值p是否为真,(非零为真,零为假)即判断p是否指向字符串结束标志(字符串结束标志符ASLL码为0)若p指向的字符不是空字符则括号内容为真执行循环p++(p指向下一个字符),否则结束循环
p-str为指针相减运算即看这两个指针中间相隔了多少个元素,这里的p已经是字符串结束标志,str表示的str[0]
注意:
指针可以指向数组,这使得数组访问多了一种方式,单指针不能代替数组存储大批量元素
char s[100] = "Computer";
s是数组名不能赋值,自增自减运算
char* p = "Computer";
p是一个指针,他存放的是这个字符串的首地址
p是一个指针变量,他能指向这个字符串也能指向其他东西可以进行赋值和自增自减
1、存储内容不同
2、运算方式不同
3、赋值操作不同
s一旦赋初值之后就不能再用其他字符来赋值,然而p却能重新指向其他字符
int a = 10, * p;
int& b = a;
p = &a;
string s = "C++";
string* ps = &s;
cout << p << endl; //输出指针p的值,a变量的首地址
cout << b << endl; //输出b的值是10
cout << *p << endl; //输出指针p指向的变量,即a的值10
cout << ps << endl;; //输出指针ps的值,s变量的地址
cout << *ps << endl; //输出指针ps指向的变量的值,即“C++”
二维数组字符串:
char s[6][7] = { "C++","Java","C","PHP","CSharp","Basic" };
内存形式

615134
this指针
this指针的定义及用法
C++通过提供特殊的对象指针,this指针,解决上述问题。this指针指向被调用的成员函数所属的对象
this指针是隐含每一个非静态成员函数内的一种指针,this指针不需要定义,直接使用即可。
this指针的用途:
- 当形参和成员变量同名时,可用this指针来区分
- 在类的非静态成员函数中返回对象本身,可使用return *this
#include<iostream>
using namespace std;
class Person {
public:
Person(int age){
//1、当形参和成员变量同名时,可用this指针来区分
this->age = age;
}
Person& PersonAddPerson(Person p){
this->age += p.age;
//返回对象本身
return *this;
}
int age;
};
int main() {
Person p1(10);
cout << "p1.age = " << p1.age << endl;
Person p2(20);
p2.PersonAddPerson(p1).PersonAddPerson(p1); //20+10+10=40
cout << "p2.age = " << p2.age << endl;
return 0;
}
this指针的本质–指针常量
this指针的本质是一个指针常量:const Type* const pointer;
他储存了调用他的对象的地址,并且不可被修改。这样成员函数才知道自己修改的成员变量是哪个对象的。
例如:调用date.SetMonth(9) <===> SetMonth(&date, 9),this指针帮助完成了这一转换,使得this指针指向了调用对象data。
this指针的特点
1.只能在成员函数中使用,在全局函数、静态成员函数中都不能使用 this 。
(this始终指向当前对象,静态成员函数属于类)
- this 指针是在成员函数的开始前构造,并在成员函数的结束后清除 。
(和函数的其他参数生命周期一样)
- this 指针会因编译器不同而有不同的存储位置,可能是栈、寄存器或全局变量 。
(编译器在生成程序时加入了获取对象首地址的相关代码并把获取的首地址存放在了寄存器中)
- 关于this指针的一个经典回答:
当你进入一个房子后,你可以看见桌子、椅子、地板等,但是房子的全貌 ,你看不到了。
对于一个对象(也就是类的实例)来说,你可以看到它的成员函数、成员变量,但是看不到对象本身了。
所以有了this指针,它时时刻刻指向你这个对象本身。
重载运算符operate
operator 是 C++ 的一个关键字,它和运算符(如 =)一起使用,表示一个运算符重载函数,在理解时可将 operator 和待重载的运算符整体(如 operator=)视为一个函数名。
使用 operator 重载运算符,是 C++ 扩展运算符功能的方法。使用 operator 扩展运算符功能的原因如下:
使重载后的运算符的使用方法与重载前一致;
扩展运算符的功能只能通过函数的方式实现。(实际上,C++ 中各种“功能”都是通过函数实现的)
C++ 提供的运算符,通常只支持对于基本数据类型和标准库中提供的类进行操作,而对于用户自己定义的类,如果想要通过这些运算符实现一些基本操作(如比较大小、判断是否相等),就需要用户自己来定义这个运算符的具体实现了。
例如,我们设计了一个名为“person”的类,现在要判断 person 类的两个对象 p1 和 p2 是否一样相等,比较规则是比较对象的年龄(person 类的数据成员“age”)大小。那么,在设计 person 类的时候,就可以通过针对运算符" == " 进行重载,来使运算符“==”具有比较对象 p1 和 p2 的能力(实际上比较的内容是 person 类中的数据成员“age”)。
上面描述的对运算符“ == ”进行重载,之所以叫“重载”,是由于编译器在实现运算符“ == ”功能的时候,已经针对这个运算符提供了对于一些基本数据类型的操作支持,只不过现在该运算符所操作的内容变成了我们自定义的数据类型(如 class),而在默认情况下,该运算符是不能对我们自定义的数据类型进行操作的。因此,就需要我们通过对该运算符进行重载,给出该运算符操作我们自定义的数据类型的方法,从而达到使用该运算符对我们自定义的数据类型进行运算的目的。
实现运算符重载的方式通常有以下两种:
运算符重载实现为类的成员函数;
运算符重载实现为非类的成员函数(即全局函数)。
运算符重载实现为类的成员函数
在类体中声明(定义)需要重载的运算符,声明方式跟普通的成员函数一样,只不过运算符重载函数的名字是“operator紧跟一个 C++ 预定义的操作符”,示例用法如下(person 是我们定义的类):
bool operator==(const person& ps)
{
if (this->age == ps.age)
{
return true;
}
return false;
}
示例代码内容如下:
#include <iostream>
using namespace std;
class person
{
private:
int age;
public:
person(int nAge)
{
this->age = nAge;
}
bool operator==(const person& ps)
{
if (this->age == ps.age)
{
return true;
}
return false;
}
};
int main()
{
person p1(10);
person p2(10);
if (p1 == p2)
{
cout << "p1 is equal with p2." << endl;
}
else
{
cout << "p1 is not equal with p2." << endl;
}
return 0;
}
编译并运行上述代码,结果如下:

通过上述结果能够知道:因为运算符重载函数“operator==”是 person 类的一个成员函数,所以对象 p1、p2 都可以调用该函数。其中的 if (p1 == p2) 语句,相当于对象 p1 调用函数“operator==”,把对象 p2 作为一个参数传递给该函数,从而实现了两个对象的比较。
运算符重载实现为非类的成员函数(即全局函数)
对于全局重载运算符,代表左操作数的参数必须被显式指定。
示例代码如下:
#include <iostream>
using namespace std;
class person
{
public:
int age;
};
// 左操作数的类型必须被显式指定
// 此处指定的类型为person类
bool operator==(person const& p1 ,person const& p2)
{
if (p1.age == p2.age)
{
return true;
}
else
{
return false;
}
}
int main()
{
person p1;
person p2;
p1.age = 18;
p2.age = 18;
if (p1 == p2)
{
cout << "p1 is equal with p2." << endl;
}
else
{
cout << "p1 is NOT equal with p2." << endl;
}
return 0;
}
编译并运行上述代码,结果如下:

运算符重载的方式选择
可以根据以下因素,确定把一个运算符重载为类的成员函数还是全局函数:
如果一个重载运算符是类的成员函数,那么只有当与它一起使用的左操作数是该类的对象时,该运算符才会被调用;而如果该运算符的左操作数确定为其他的类型,则运算符必须被重载为全局函数;
C++ 要求’=‘、’[]‘、’()‘、’->'运算符必须被定义为类的成员函数,把这些运算符通过全局函数进行重载时会出现编译错误;
如果有一个操作数是类类型(如 string 类),那么对于对称操作符(比如操作符“==”),最好通过全局函数的方式进行重载。
运算符重载的限制
实现运算符重载时,需要注意以下几点:
重载后运算符的操作数至少有一个是用户定义的类型;
不能违反运算符原来的语法规则;
不能创建新的运算符;
有一些运算符是不能重载的,如“sizeof”;
=、()、[]、-> 操作符只能被类的成员函数重载。
=default和=delete
Defaulted Function
明确默认的函数声明式一种新的函数声明方式,在C++11发布时做出了更新。C++11允许添加“=default”说明符到函数声明的末尾,以将该函数声明为显示默认构造函数。这就使得编译器为显示默认函数生成了默认实现,它比手动编程函数更加有效。
例如,每当我们声明一个有参构造函数时,编译器就不会创建默认构造函数。在这种情况下,我们可以使用default说明符来创建默认说明符。以下代码演示了如何创建:
// use of defaulted functions
#include <iostream>
using namespace std;
class A {
public:
// A user-defined
A(int x){
cout << "This is a parameterized constructor";
}
// Using the default specifier to instruct
// the compiler to create the default implementation of the constructor.
A() = default;
};
int main(){
A a; //call A()
A x(1); //call A(int x)
cout<<endl;
return 0;
}

在上面的例子中,我们不必指定构造函数A()的主体,因为通过附加说明符’= default’,编译器将创建此函数的默认实现。
那么使用此“=default”符号有什么限制?
- 默认函数需要用于特殊的成员函数(默认构造函数,复制构造函数,析构函数等),或者没有默认参数。例如,以下代码解释了非特殊成员函数不能默认:
// non-special member functions can't be defaulted(非特殊成员函数不能使用default)
class B {
public:
// Error, func is not a special member function.
int func() = default;
// Error, constructor B(int, int) is not a special member function.
B(int, int) = default;
// Error, constructor B(int=0) has a default argument.
B(int = 0) = default;
};
int main() {
return 0;
}
运行结果:

当我们可以使用“{}”简单的空的实体时,使用’= default’有什么优点?
尽管两者可能表现相同,但使用default而不是使用{}仍然有一定的好处。以下几点做了一定的解释:
- 给用户定义的构造函数,即使它什么也不做,使得类型不是聚合,也不是微不足道的。如果您希望您的类是聚合类型或普通类型(或通过传递性,POD类型),那么需要使用’= default’。
- 使用’= default’也可以与复制构造函数和析构函数一起使用。例如,空拷贝构造函数与默认拷贝构造函数(将执行其成员的复制副本)不同。对每个特殊成员函数统一使用’= default’语法使代码更容易阅读。
Deleted Function
在C ++ 11之前,操作符delete 只有一个目的,即释放已动态分配的内存。而C ++ 11标准引入了此操作符的另一种用法,即:禁用成员函数的使用。这是通过附加= delete来完成的; 说明符到该函数声明的结尾。
使用’= delete’说明符禁用其使用的任何成员函数称为expicitly deleted函数。
虽然不限于它们,但这通常是针对隐式函数。以下示例展示了此功能派上用场的一些任务:
禁用拷贝构造函数:
// copy-constructor using delete operator
#include <iostream>
using namespace std;
class A {
public:
A(int x): m(x) { }
// Delete the copy constructor
A(const A&) = delete;
// Delete the copy assignment operator
A& operator=(const A&) = delete;
int m;
};
int main() {
A a1(1), a2(2), a3(3);
// Error, the usage of the copy assignment operator is disabled
a1 = a2;
// Error, the usage of the copy constructor is disabled
a3 = A(a2);
return 0;
}
禁用不需要的参数转换
// type conversion using delete operator
#include <iostream>
using namespace std;
class A {
public:
A(int) {}
// Declare the conversion constructor as a deleted function. Without this step,
// even though A(double) isn't defined, the A(int) would accept any double value
// for it's argumentand convert it to an int
A(double) = delete;
};
int main() {
A A1(1);
// Error, conversion from double to class A is disabled.
A A2(100.1);
return 0;
}
请注意,删除的函数是隐式内联的,这一点非常重要。删除的函数定义必须是函数的第一个声明。换句话说,以下方法是将函数声明为已删除的正确方法:
class C {
public:
C(C& a) = delete;
};
但是以下尝试声明删除函数的方法会产生错误:
// incorrect syntax of declaring a member function as deleted
class C {
public:
C();
};
// Error, the deleted definition of function C must be the first declaration of the function.
C::C() = delete;
最后,明确删除函数有什么好处?
删除特殊成员函数提供了一种更简洁的方法来防止编译器生成我们不想要的特殊成员函数。(如“禁用拷贝构造函数”示例中所示)。
删除正常成员函数或非成员函数可防止有问题的类型导致调用非预期函数(如“禁用不需要的参数转换”示例中所示)。
override
1、override关键字作用:
如果派生类在虚函数声明时使用了override描述符,那么该函数必须重载其基类中的同名函数,否则代码将无法通过编译。
2、举例子说明
class testoverride
{
public:
testoverride(void);
~testoverride(void);
virtual void show() const = 0;
virtual int infor() = 0;
virtual void test() = 0;
virtual int spell() = 0;
};
class B: public testoverride
{
public:
virtual void show(); //1
virtual void infor(); //2
virtual void vmendd(); //3
virtual void test(int x);//4
virtual void splle(); //5
};
上面的1-5个重载函数编译过程中,除了返回值不同的infor会报错以外,其他函数都不会有问题,但是在类实例化的时候会提示是抽象类,因为他们都没有真正实现重载
class C: public testoverride
{
public:
virtual void show() override;
virtual void infor() override;
virtual void vmendd() override;
virtual void test(int x) override;
virtual void splle() override;
};
添加了override以后,会在编译器override修饰符则可以保证编译器辅助地做一些检查,上面的情况无法通过编译
结论
如果派生类里面是像重载虚函数 就加上关键字override 这样编译器可以辅助检查是不是正确重载,如果没加这个关键字 也没什么严重的error 只是少了编译器检查的安全性
abs()和fabs()
两个函数都是取绝对值,使用时需调用
#include<cmath>
//或
#include<math.h>
两个函数的区别是:
- abs()是对整数求绝对值
- fabs()是对浮点数取绝对值:float、double型
nummeric_limits
搬运自:C++ limits头文件的用法(numeric_limits)
numeric_limits::max ()
是函数,返回编译器允许的 double 型数 最大值。
类似的 numeric_limits::max () 返回 编译器允许的 int 型数 最大值。
需包含头文件 #include
limits是STL提供的头文件(包含numeric_limits模板类),limit.h是C语言提供的头文件(包含一些宏定义)
例子:
#include
#include
using namespace std;
main(){
cout << std::numeric_limits::max () << endl;
cout << std::numeric_limits::max () << endl;
}
一般来说,数值类型的极值是一个与平台相关的特性。c++标准程序库通过template numeric_limits提供这些极值,取代传统C语言所采用的预处理常数。你仍然可以使用后者,其中整数常数定义于和<limits.h>,浮点常数定义于和<float.h>,新的极值概念有两个优点,一是提供了更好的类型安全性,二是程序员可借此写出一些template以核定这些极值。
下面是numeric_limits定义

下面是参数的解释:

参考文章
【1】OpenCV的Rect矩形类用法
【2】RECT类
【3】[C++] gtest入门教程
【4】C/C++中的数据类型转换()/static_cast/dynamic_cast/const_cast/reinterpret_cast
【5】Box2D入门教程(1.概述)
【6】Box2D:Overview
【7】C++11新特性:constexpr变量和constexpr函数
【8】size_t 数据类型
【9】C++中explicit的用法
【10】Abseil系列五:strings(字符串工具库)
【11】C++ 中的 inline 用法
【12】Google glog 使用
【13】C++中的resize()函数
【14】最详细的讲解C++中指针的使用方法(通俗易懂)
【15】C++的this指针【定义、用法、本质、特点】
【16】C++编程语言中重载运算符(operator)介绍
【17】C++中的 =default和=delete
【18】C++ override 关键字用法
【19】C++中的fabs()和abs()
【20】C++ limits头文件的用法(numeric_limits)














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









