






1. 总结脚本高级命令trap, install, mktemp, expect, 进程优先级命令:nice, renice, 进程管理工具: ps, pstree, prtstat, pgrep, pidof, uptime,mpstat,top,htop, free, pmap, vmstat, iostat, iotop, iftop, nload, nethogs, iptraf-ng, dstat, glances, cockpit, kill, job, 任务相关的命令: at, crontab, 命令,选项,示例。
1.1 脚本高级命令
trap
trap命令可以捕捉信号信息,修改信号原来的功能,实现自定义功能
#进程收到系统发出的指定信号后,将执行自定义指令,而不会执行原操作
trap '触发指令' 信号
#忽略信号的操作
trap '' 信号
#恢复原信号操作
trap '-' 信号
#列出自定义信号操作
trap -p
#当脚本退出时执行finish函数
trap finish EXIT
示例
#信号种类
[root@rocky87 ~]# kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
#当执行Ctrl+c or Ctrl+\时,打印一段话
[root@rocky87 ~]# trap "echo 'press Ctrl+c or Ctrl+\'" 2 3
[root@rocky87 ~]# trap -p
trap -- 'echo '\''press Ctrl+c or Ctrl+\'\''' SIGINT
trap -- 'echo '\''press Ctrl+c or Ctrl+\'\''' SIGQUIT
[root@rocky87 ~]# ^Cpress Ctrl+c or Ctrl+\
[root@rocky87 ~]#
install
install功能相当于cp,chmod,chown,chgrp,mkdir等工具的集合
Usage: install [OPTION]... [-T] SOURCE DEST
or: install [OPTION]... SOURCE... DIRECTORY
or: install [OPTION]... -t DIRECTORY SOURCE...
or: install [OPTION]... -d DIRECTORY...
OPTION:
-m MODE,默认755
-o OWNER
-g GROUP
-d DIRNAME 目录
示例
#复制文件
[root@rocky87 ~]# install -m 700 -o shichao -g shichao mysql_backup.sh mysql_backup
[root@rocky87 ~]# ll mysql_backup*
-rwx------ 1 shichao shichao 269 May 17 01:17 mysql_backup
-rwxr-xr-- 1 root root 269 May 6 21:08 mysql_backup.sh
#创建目录
[root@rocky87 ~]# install -m 700 -o shichao -g shichao -d test
mktemp
mktemp命令用于创建并显示临时文件,避免文件名冲突
格式:
mktemp [OPTION]... [TEMPLATE]
TEMPLATE:
filenameXXX,X至少出现三个
OPTION:
-d #创建临时目录
-p DIR或--tmpdir=DIR #指明临时文件所存放目录位置
示例
[root@rocky87 ~]# mktemp testXXXX
test9qkc
[root@rocky87 ~]# mktemp testXXXX
testC8gj
[root@rocky87 ~]# mktemp testXXXX
testE0C3
[root@rocky87 ~]# mktemp testXXXX -p /tmp/
/tmp/test9w7B
[root@rocky87 ~]# mktemp testXXXX -p /tmp/
/tmp/testM7vI
expect
expect是由Don Libes基于Tcl(Tool Command Language)语言开发的,主要用于自动化交互式操作的场景。
expect语法:
expect [ -dDhinNv ] [ -c cmds ] [ [ -[f|b] ] cmdfile ] [ args ]
#常用选项
-c:从命令执行expect脚本,默认expect是交互地执行
-d:可以调试信息
[root@rocky87 ~]# expect -c 'expect "\n" {send "press enter\n"}'
[root@rocky87 ~]# expect -d ssh.exp
expect 中相关命令
● spawn 启动新的进程
● expect 从进程接收字符串
● send 用于向进程发送字符串
● interact 允许用户交互
● exp_continue 匹配多个字符串在执行动作后加此命令
exp_continue的理解:只要是一个命令产生的多个提示就用exp_continue 依次往下判断,如果是每个命令只有一次标准输出就用expect匹配
expect变量
[root@rocky87 ~]# cat test.exp
#!/usr/bin/expext
set ip 10.0.0.3
set passwd root123
spawn scp shift.sh $ip:
expect {
"yes/no" {send "yes\n";exp_continue }
"password" { send "$passwd\n"}
}
expect eof
expect位置参数
[root@rocky87 ~]# cat test.exp
#!/usr/bin/expect
set ip [lindex $argv 0]
set passwd [lindex $argv 1]
spawn scp shift.sh $ip:
expect {
"yes/no" {send "yes\n";exp_continue }
"password" { send "$passwd\n"}
}
expect "#" { send "ls \n"}
expect eof
[root@rocky87 ~]# ./test.exp 10.0.0.3 root123
shell脚本中调用expect
[root@rocky87 ~]# cat test.exp
#!/bin/bash
ip=$1
passwd=$2
/usr/bin/expect <<EOF
spawn ssh root@$ip
expect {
"yes/no" {send "yes\n";exp_continue }
"password" { send "$passwd\n";exp_continue}
expect "#" { send "pwd \n"}
}
expect eof
EOF
1.2 进程优先级命令

系统优先级:0-139,数字越小优先级越高
实时优先级:99-0,数组越大优先级越高
nice值:-20到19
进程优先级调整
● 静态优先级:100-139
● 进程默认启动时的nice值为0,优先级为120
● 只有根用户才能降低nice值,即提高优先级
nice
用于指定优先级来启动进程
nice [OPTION] [COMMAND [ARG]...]
-n
renice
renice命令,调整正在执行中的进程优先级
renice [-n] priority pid...
[root@rocky87 ~]# nice -n 10 ping 127.0.0.1 > /dev/null &
[1] 2640
[root@rocky87 ~]# ps axo pid,comm,ni,pri| grep ping
2640 ping 10 9
[root@rocky87 ~]# ps axo pid,comm,ni,pri| grep ping
2640 ping 10 9
[root@rocky87 ~]# renice -n 20 2640
2640 (process ID) old priority 10, new priority 19
[root@rocky87 ~]# ps axo pid,comm,ni,pri| grep ping
2640 ping 19 0
[root@rocky87 ~]#
1.3 进程管理工具
ps
即 process state,查看进程当前状态的快照。Linux系统各进程的信息存放在/proc/PID/目录下
格式
ps [OPTION]...
支持三种风格选项:
UNIX选项 如 -A -e
GUN选项 --help
BSD选项 a
常用选项:
a 包括所有终端中的进程
x 包括不链接终端的进程
u 显示进程所有者信息
f 显示进程树
k|--sort 对属性排序,属性前加-表示倒序
o 属性,指定显示定制选项信息 pid cmd %cpu %mem
L 显示支持的属性列表
-L 显示线程
-e 显示所有进程,相当于-A
-f 显示完整格式的程序信息
-F 显示完整格式的进程信息
-p pid 显示指定pid进程
--ppid pid 显示属于pid的子进程
-t 指定tty
-u userlist 指定有效用户的ID或名称
-U userlist 指定真正用户的ID或名称
ps输出
C ps -ef显示列 C表示cpu利用率
VSZ virtual memory size,虚拟内存集,线性内存
RSS ReSident Size,常驻内存集
STAT 进程状态
R:running
S:interruptable sleeping
D:uninterruptable sleeping
T:stopped
Z:zombie
+:前台进程
l:多线程进程
L:内存分页并带锁
N:低优先级进程
<: 高优先级进程
s:sesion leader,会话(子进程)发起者
I:idler kernel thread
ni nice值
pri 优先级
rtprio 实时优先级
psr processor CPU编号
pstree
用于显示进程父子关系,以树形结构显示
pstree [OPTION] [PID|USER]
OPTION:
-p 显示PID
-T 不显示线程,默认显示线程,{}内的内容
-u 显示用户切换
-H pid 高亮显示指定进程及其前辈进程
prtstat
可显示进程信息,来自psmisc包
[shichao@rocky87 root]$ prtstat 911
Process: httpd State: S (sleeping)
CPU#: 0 TTY: 0:0 Threads: 1
Process, Group and Session IDs
Process ID: 911 Parent ID: 1
Group ID: 911 Session ID: 911
T Group ID: -1
Page Faults
This Process (minor major): 1598 55
Child Processes (minor major): 0 0
CPU Times
This Process (user system guest blkio): 0.11 0.20 0.00 0.13
Child processes (user system guest): 0.00 0.00 0.00
Memory
Vsize: 289 MB
RSS: 11 MB RSS Limit: 18446744073709 MB
Code Start: 0x1 Code Stop: 0x1
Stack Start: 0
Stack Pointer (ESP): 0 Inst Pointer (EIP): 0
Scheduling
Policy: normal
Nice: 0 RT Priority: 0 (non RT)
[shichao@rocky87 root]$ prtstat -r 911
pid: 911 comm: httpd
state: S ppid: 1
pgrp: 911 session: 911
tty_nr: 0 tpgid: -1
flags: 404100 minflt: 1598
cminflt: 0 majflt: 55
cmajflt: 0 utime: 12
stime: 20 cutime: 0
cstime: 0 priority: 20
nice: 0 num_threads: 1
itrealvalue: 0 starttime: 618
vsize: 289738752 rss: 2869
rsslim: 18446744073709551615 startcode: 1
endcode: 1 startstack: 0
kstkesp: 0 kstkeip: 0
wchan: 0 nswap: 0
cnswap: 0 exit_signal: 17
processor: 0 rt_priority: 0
policy: 0 delayaccr_blkio_ticks: 13
guest_time: 0 cguest_time: 0
pgrep
按预定义的模式搜索进程
pgrep [OPTION] pattern
-u uid: 生效者
-U uid:真正发起命令者
-t terminal: 指定终端
-l: 进程名
-a: 显示完成格式进程名,支持正则
-P pid: 显示指定进行的子进程
pidof
按进程或程序名查进程号
pidof [OPTION] [program ...]
-x 按脚本名称查找pid
#脚本中必须有shebang机制,否则查不到进程号
pidof -x ping.sh
uptime
负载查询
/proc/uptime 包括两个值,单位s
● 系统启动时长
● 空闲进程的总时长(按总CPU核数计算)
uptime和w显示内容
● 当前时间
● 系统已启动时间
● 当前上线人数
● 系统平均负载(1,5,15分钟的平均负载,一般不超过1,超过5建议报警)
系统平均负载:指在特定时间间隔内运行队列中的平均进程数,通常每个CPU内核的当前活动进程数不大3,如果每个CPU内核任务数大于5说明性能有严重问题。
如:Linux主机有1个双核CPU,当load average为6时,说明机器已充分使用
mpstat
显示CPU相关统计
top
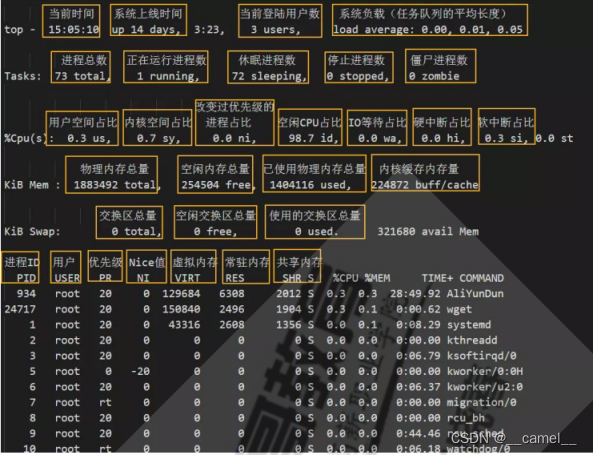
帮助:h或?,按q或esc退出帮助
排序:
P:以占用CPU百分比,%CPU
M:占据内存百分比,%MEM
T:累积占据CPU时长,TIME+
top选项
-d 指定刷新时间间隔,默认3s
-b 全部显示所有进程
-p 指定进程pid
-n 刷新多少次退出
-H 线程模式
free
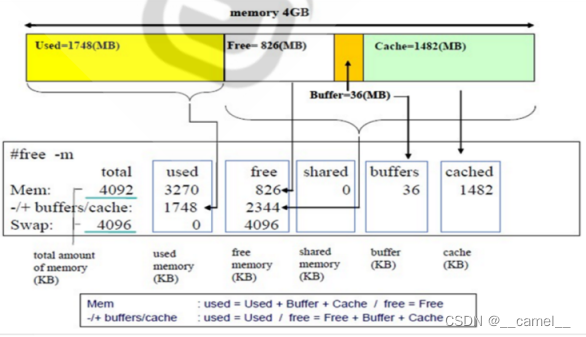
buffer和cache的区别
文件写入的时候先从用户空间的内存将文件放到内核空间的buffer,然后再由内核将buffer中的内容通过IO写入磁盘
当应用程序在读磁盘上的文件时,首先将文件加载进内核空间的cache,然后再由cache读入应用程序所在的用户空间供应用程序使用,当下次再访问同样的文件时可以直接读取内核空间的cache
格式
free [OPTION]
-b 以字节为单位
-m 以MB为单位
-g GB
-h 易读
-s n 刷新间隔n秒
-c b 刷新n次退出
向/proc/sys/vm/drop_caches中写入相应值会清理缓存。建议先执行 sync,将所有未写的系统缓存区写到磁盘。生产中要谨慎执行。
/proc/sys/vm/drop_caches (since Linux 2.6.16)
Writing to this file causes the kernel to drop clean caches, dentries, and inodes from memory, causing that memory to become free. This can be useful
for memory management testing and performing reproducible filesystem benchmarks. Because writing to this file causes the benefits of caching to be
lost, it can degrade overall system performance.
To free pagecache, use:
echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes, use:
echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes, use:
echo 3 > /proc/sys/vm/drop_caches
vmstat
虚拟内存信息
vmstat [OPTIONS] [delay [count]]
-s 查看内存统计数据
proc:
r:可运行(正运行和等待运行)进程的个数,和核心数有关
b:处于不可中断睡眠状态进程个数(被阻塞队列长度)
memory:
swpd:交换内存使用量
free:空闲物理内存总量
buffer:用于buffer的内存总量
cache:用于cache的内存总量
swap:
si:从磁盘交换进内存的数据速率(kb/s),in/out是对于内存来说的
so:从内存交换至磁盘的数据速率(kb/s)
io:
bi:从块设备读入数据到内存的数据速率(kb/s)
bo:从内存写入块设备数据速率(kb/s)
system:
in:interrupts 中断速率(包括时钟)
cs:context Switch 进程切换速率
cpu:
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
sy: Time spent running kernel code. (system time)
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
lsof
list of file,查看当前系统文件的工具。
-a 列出打开文件的进程
-c 进程名 列出指定进程所打开的文件
-g 列出gid号详情
-u 列出UID号详情
-d 文件号 列出占用该文件号的进程
+d 目录 列出目录下被打开的文件
+D 目录 递归列出目录下被打开的文件
-p pid 列出指定进程号所打开的文件
#列出所有打开的文件
[root@rocky87 ~]# lsof
#查看正在使用某文件的进程
[root@rocky87 ~]# lsof /var/log/messages
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rsyslogd 965 root 5w REG 253,0 9387247 99872 /var/log/messages
#查看某进程打开的文件
[root@rocky87 ~]# lsof -p 1717
#查看指定程序打开的文件
root@rocky87 ~]# lsof -c bash
#查看指定用户打开的文件
[root@rocky87 ~]# lsof -u root
#查看指定目录下被打开的文件,+D 递归列出所有打开的文件;+d 打开当前目录下被打开的文件
[root@rocky87 ~]# lsof +D /var/log
[root@rocky87 ~]# lsof +d /var/log
#查看所有网络连接,-i查看连接情况,包括连接的ip,端口等。也可以指定ip查看该ip的连接情况
[root@rocky87 ~]# lsof -i -n
[root@rocky87 ~]# lsof -i@127.0.0.1 -n
#指定端口查看连接情况
[root@rocky87 ~]# lsof -i:22 -n
#指定tcp协议查看连接情况
[root@rocky87 ~]# lsof -i TCP -n
kill
查看当前系统可用信号:
kill -l
trap -l
1)SIGHUP 无需关闭进程而让其重新读配置文件
2)SIGINT 中止正在运行的进程,相当于Ctrl+c
3)SIGQUIT 相当于Ctrl+\
9)SIGKILL 强制杀死正在运行进程,可能导致数据丢失
15)SIGTERM 中止正在运行进程
18)SIGCONT 继续运行
19)SIGSTOP 后台休眠
指定信号的方法:
● 信号的数字标识:1,2,9
● 信号完整名称:SIGHUP,sighup
● 信号简写:HUP ,hup
向进程发信号
#按pid
kill [-s sigspec| -n signum|-sigspec] pid
#按名称
killall [-SIGNAL]
#
job
查看当前所有作业
jobs
作业控制
fg [[%] JOB_NUM] 指定后台作业调回前台
bg [[%] JOB_NUM] 让送到后台的作业继续运行
kill [%JOB_NUM] 终止指定作业
1.4 任务相关的命令
at:实现一次性计划任务
cron:实现周期性计划任务
at
● 由包at提供
● 依赖atd服务,需要启动atd服务才能实现at任务
● at队列存放在/var/spool/at目录中,Ubuntu存放在/var/spool/cron/atjobs目录下
● 执行任务时PATH变量的值和当前定义任务的用户身份一致
格式
at [OPTION] TIME
-t time 时间格式
-l 列出指定队列中等待运行的作业
-d N 删除指定的N号作业
-c N 查看N号作业的具体任务
-f file 指定文件中读取任务
-m 当任务完成后,将给用户发送邮件,即使没有标准输出
TIME:定义出什么时候进行at这项任务的时间
HH:MM [YYYT-mm-dd] #如果时刻已过,则次日执行
noon,midnight,teatime(4pm),tomorrow
now + n {minutes,hours,days,weeks} #n分钟/小时/天/周之后
说明:
○ 作业执行命令的结果中的标准输出和错误以执行任务的用户身份发邮件给root
○ 默认centos8最小化安装没有安装邮件服务,需要自行安装
○ /etc/at.{allow,deny}控制用户是否能执行at任务,如果两个文件都不存在只有root能执行at命令
crontab
cron相关的程序包:
● cronie:主程序包,提供crond守护进程及相关辅助工具
● crontabs:包含centos提供的系统维护任务
● cronie-anacron:cronie的补充程序,用于监控cronie任务执行情况,如果cronie的任务在过去该运行时间点未能正常运行,则anacron会随后启动一次此任务
cron依赖crond服务,要确保crond守护正常运行
cron任务类型:
● 系统任务:系统维护作业,/etc/crontab主配置文件,/etc/cron.d子配置文件
● 用户任务:红帽系统保存在/var/spool/cron/USERNAME,Ubuntu系统存放在/var/spool/crontabs/USERNAME
计划任务日志:/var/log/cron
[root@rocky87 ~]# cat /etc/crontab
SHELL=/bin/bash #默认的shell类型
PATH=/sbin:/bin:/usr/sbin:/usr/bin #默认的PATH变量,任务中使用命令时需注意
MAILTO=root #默认标准输出和错误发送邮件给root,可以指向其他用户
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
[root@rocky87 ~]#
#每个月日期和星期的关系是或
Note: The day of a command's execution can be specified in the following two fields — 'day of
month', and 'day of week'. If both fields are restricted (i.e., do not contain the "*" character),
the command will be run when either field matches the current time. For example,
"30 4 1,15 * 5" would cause a command to be run at 4:30 am on the 1st and 15th of each month, plus
every Friday.
2. 总结索引数组和关联数组,字符串处理,高级变量使用及示例。
索引数组
声明数组
#普通数组可以不声明,直接使用
declare -a ARRAY_NAME
#关联数组必须先声明,后使用
declare -A ARRAY_NAME
#两种类型的数组不相互转换
数组赋值
#一次只赋值一个元素
ARRAY_NAME[INDEX]=VALUE
#一次赋值多个元素
ARRAY_NAME=("VAL1" "VAL2"...)
title=(ceo coo cto)
num=({1..10})
alpha=({a..z})
file=(*.txt)
#只赋值特定元素
ARRAY_NAME=([0]="VAL1" [3]="VAL2"...)
#交互式赋值
read -a ARRAY
显示当前shell定义的所有数组
declare -a
引用数组
#引用数组中某个元素
${ARRAY_NAME[INDEX]}
#如果省略[INDEX]表示引用下标为0的元素
#引用数组所有元素
${ARRAY_NAME[*]}
${ARRAY_NAME[@]}
#输出数组长度
${#ARRAY_NAME[*]}
${#ARRAY_NAME[@]}
#删除数组
unset ARRAY_NAME[INDEX] 删除数组中某个元素
unset ARRAY_NAME 删除整个数组
#数组切片
${ARRAY_NAME[@]:offset:number}
${ARRAY_NAME[*]:offset:number}
offset 要跳过的元素个数
number 要取出的元素个数
#取偏移后的所有元素
${ARRAY_NAME[@]:offset}
${ARRAY_NAME[*]:offset}
#最后number个元素,:和number之间有空格
${ARRAY_NAME[@]: -number}
${ARRAY_NAME[*]: -number}
[root@rocky87 ~]# echo ${array[@]: -2}
i7FS 2bNv
[root@rocky87 ~]# echo ${array[*]: -2}
i7FS 2bNv
关联数组
关联数组必须先声明,再调用
declare -A ARRAY_NAME
ARRAY_NAME=([idx_name1]='val1' [idx_name2]='val2'...)
ARRAY_NAME[idx_name3]='val3'
字符串处理
- 基于偏移量取字符串
返回字符串变量var的字符的长度,一个汉字/字母算一个字符
${#var}
[root@rocky87 ~]# str='jkdsfjgj'
[root@rocky87 ~]# echo $str
jkdsfjgj
[root@rocky87 ~]# echo ${#str}
8
返回字符串变量var中从第offset个字符后(不包括第offset个字符)的字符开始,到最后的部分。bash 4.2之后offset允许取负值
[root@rocky87 ~]# echo ${str:2}
dsfjgj
[root@rocky87 ~]# echo ${str: -2}
gj
#掐头去尾,掐掉左边连续offset个字符,去掉右边number个字符
${var:offset:-number}
- 基于模式取子串
从左往右,查找var变量所存储的字符串中,删除字符串开头到第一次出现word字符的部分(包含word字符串),即懒惰模式,即非贪婪模式
${var#*word}
与其对应的贪婪模式
${var##*word}
从var变量的字符串中删除以word开头的部分
${var#word} 与其对应的贪婪模式${var##word}
[root@rocky87 ~]# echo $var
qwer1234
[root@rocky87 ~]# echo ${var#qw}
er1234
[root@rocky87 ~]# echo ${var#w}
qwer1234
[root@rocky87 ~]#
从右往左,查找var变量所存储的字符串中,删除字符串从最后开始到第一次出现word字符的部分(包含word字符串),即懒惰模式,即非贪婪模式
${var%word*}
与其对应的贪婪模式
${var%%word*}
[root@rocky87 ~]# echo ${str}
abcdefg
[root@rocky87 ~]# echo ${str#*cd}
efg
[root@rocky87 ~]#
[root@rocky87 ~]# echo ${str%%cd*}
ab
[root@rocky87 ~]#
从var变量的字符串中删除以word结尾的部分
${var%word} 与其对应的贪婪模式${var%%word}
[root@rocky87 ~]# echo $var
qwer1234
[root@rocky87 ~]# echo ${var%34}
qwer12
[root@rocky87 ~]# echo ${var%3}
qwer1234
[root@rocky87 ~]#
高级变量
- 高级变量赋值
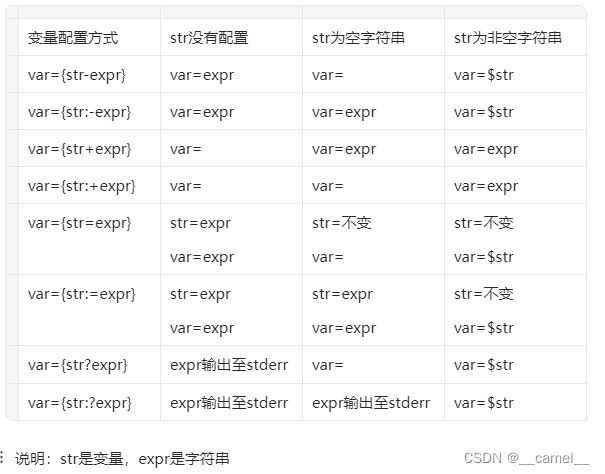
[root@rocky87 ~]# first_name=;last_name=${first_name-yu};echo $last_name
[root@rocky87 ~]# unset first_name;last_name=${first_name-yu};echo $last_name
yu
[root@rocky87 ~]# first_name=shichao;last_name=${first_name-yu};echo $last_name
shichao
[root@rocky87 ~]#
- 变量的间接引用
如果第一个变量的值是第二个变量的名字,从第一个变量引用第二个变量的值称为间接变量引用。
bash shell提供了2种实现变量间接引用的方法
val1=val2
val2="test"
#方法1
#赋值场景
var=\$$var1
#显示场景
eval echo \$$val1
eval echo '$'$val1
#方法2
#赋值场景
var=${!var1}
#显示场景
echo ${!var1}
eval命令:eval命令首先扫描命令行所有的置换,然后再指定该命令行。
[root@rocky87 ~]# cmd=whoami
[root@rocky87 ~]# eval $cmd
root
[root@rocky87 ~]# n=10;echo {1..$n}
{1..10}
[root@rocky87 ~]# n=10;eval echo {1..$n}
1 2 3 4 5 6 7 8 9 10
[root@rocky87 ~]#
3. 求10个随机数的最大值与最小值。
[root@rocky87 ~]# for i in {1..10};do num=$RANDOM;if [[ $i -eq 1 ]];then max=$num;min=$num;fi;echo -n $num ' ' ;if [[ $num -gt $max ]];then max=$num;elif [[ $num -lt $min ]];then min=$num ;fi;done;echo "中最大值为 $max ;最小值为 $min"
27542 2675 23932 13330 17504 17126 23983 11792 17026 11600 中最大值为 27542 ;最小值为 2675
[root@rocky87 ~]#
4. 使用递归调用,完成阶乘算法实现。
[root@rocky87 wordpress]# fact() { if [ $1 -eq 0 -o $1 -eq 1 ] ;then echo 1;else echo $[$1*$(fact $[$1-1])] ;fi };fact 8
40320
6. 总结OOM原理,及处理方法。
OOM,out of memory,内存用完。
原因:
● 给应用分配的内存太少:比如虚拟机本身可使用的内存太少
● 应用用的太多,并且用完没释放。
进程A想要分配物理内存(通常是当进程真正去读写一块内核已经“分配”给它的内存)->触发缺页异常->内核去分配物理内存->物理内存不够了,触发OOM
内核参数修改不允许内存申请过量(不推荐)
echo 2 > /proc/sys/vm/overcommit_memory
echo 80 > /proc/sys/vm/overcommit_ratio
echo 2 > /proc/sys/vm/panic_on_oom
linux默认允许memory overcommit,即只要进程申请,就分配内存,寄希望于进程实际上用不到那么多内存,如果用到了那么多,Linux会根据OOM killer机制挑选一个进程出来杀死,以腾出部分内存空间,如果还不够用就继续杀。也可以通过内核参数panic_on_oom使得发生OOM时自动重启系统。
7. 结合进程管理命令,说明进程各种状态。
进程状态
● 创建:进程在创建时需要申请一个空白的PCB,向其中填写控制和管理进程的信息,完成资源分配,如果创建无法完成,如资源不足,此时进程处于创建状态。
● 就绪:进程已准备好,已分配到所需资源,只要分配到CPU时间片就可立即执行
● 执行:进程处于就绪后被调用,进入执行状态
● 阻塞:正在执行的进程由于进行I/O请求而等待I/O的完成暂时无法继续运行,进入阻塞状态
● 终止:进程运行结束,或出现错误,或被系统终止
ps命令输出中进程的状态:
● 运行:running
● 就绪:ready
● 睡眠:分两种,可中断(interruptable)和不可中断(uninterruptable)
● 停止:stopped,暂停于内存,但不会被调度,除非手动启动
● 僵死:zombie,父进程结束前,子进程不关闭,杀死父进程可关闭僵死进程
STAT 进程状态
R:running
S:interruptable sleeping
D:uninterruptable sleeping
T:stopped
Z:zombie
+:前台进程
l:多线程进程
L:内存分页并带锁
N:低优先级进程
<: 高优先级进程
s:sesion leader,会话(子进程)发起者
I:idler kernel thread
# running 的进程
[[root@rocky87 wordpress]# ps aux --sort -stat | awk '{if ($8 ~ "R") print $0}' | head -n 3
root 3572 0.0 0.2 268896 4700 pts/0 R+ 15:55 0:00 ps aux --sort -stat
#sleeping进程
[root@rocky87 wordpress]# ps aux --sort -stat | awk '{if ($8 ~ "S") print $0}' | head -n 3
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.5 238044 10800 ? Ss 09:23 0:07 /usr/lib/systemd/systemd --switched-root --system --deserialize 16
root 2 0.0 0.0 0 0 ? S 09:23 0:00 [kthreadd]
8. 说明IPC通信和RPC通信实现的方式。
同一主机
● pipe 管道,单向传输
● socket 套接字文件,双工通信
● memory-mapped file 文件映射,将文件映射到内存,多个进程共享这块内存
● shm shared memory 共享内存
● signal 信号
● semaphore 信号量
不同主机
● RPC remote procedure call
● MQ
10. 总结Linux,前台和后台作业的区别,并说明如何在前台和后台中进行状态转换。
前台作业占用终端窗口,后台作业不占用窗口。
让作业运行在后台
● 前台运行中的作业:Ctrl+Z
● 准备运行的作业:COMMAND &
后台运行,同时退出终端作业不停止
● nohup COMMAND & &>/dev/null &
● screen ; COMMAND
● tmux ; COMMAND
查看当前终端所有作业
jobs
[root@rocky87 wordpress]# ping 127.0.0.1 > /dev/null &
[1] 3602
[root@rocky87 wordpress]# jobs
[1]+ Running ping 127.0.0.1 > /dev/null &
作业控制
fg [[%] JOB_NUM] 指定后台作业调回前台
bg [[%] JOB_NUM] 让送到后台的作业继续运行
kill [%JOB_NUM] 终止指定作业
[root@rocky87 wordpress]# fg 1
ping 127.0.0.1 > /dev/null
^Z
[1]+ Stopped ping 127.0.0.1 > /dev/null
[root@rocky87 wordpress]#
[root@rocky87 wordpress]# jobs
[1]+ Stopped ping 127.0.0.1 > /dev/null
[root@rocky87 wordpress]# bg 1
[1]+ ping 127.0.0.1 > /dev/null &
[root@rocky87 wordpress]#
11. 总结内核设计流派及特点。
● 宏内核(monolithic kernel):又称单内核和强内核,unix,Linux吧所有系统服务都放在内核里,所有功能集成于同一个程序,分层实现不同功能。其实Linux在单内核实现了模块化,也就相当于吸收了微内核的优点
● 微内核(micro kernel):windows,Solaris,HarmonyOS。简化内核功能,在内核之外的用户态尽可能多地实现系统服务,同时加入相互之间的安全保护,每种功能使用一个单独子系统实现,将内核功能移到用户空间,性能差。
12. 总结centos 6 启动流程,grub工作流程
- 加载BIOS的硬件信息,获取第一个启动设备
- 读取第一个启动设备的MBR引导加载程序(grub)的启动信息
- 加载核心操作系统的核心信息,核心开始解压缩,并尝试驱动所有的硬件设备
- 核心执行init程序,并获取默认的运行信息
- init程序执行/etc/rc.d/rc.sysinit文件,重新挂载根系统文件
- 启动核心的外挂模块
- init执行运行的各个批处理文件(scripts)
- init执行/etc/rc.d/rc.local
- 执行/bin/login程序,等待用户登录
- 登录后开始以shell控制主机
GRUB启动阶段
● primary boot loader
○ 1st stage:加载MBR的前446字节
○ 1.5 stage:MBR之后的扇区,让stage 1中的bootloader能识别stage 2所在的分区(/boot)上的文件系统(xfs)
● secondary boot loader
○ 2nd stage,分区文件/boot/grub
GRUB的作用是为了引导并加载kernel,要加载kernel首先得找到kernel所在的路径,因此首先就得有文件系统,要有文件系统首先要加载文件系统驱动,而文件系统驱动文件的大小远大于446字节(大约400+KB),而MBR之后的扇区可以存放一部分文件系统驱动,此时加载的文件系统驱动是grub2阶段所需文件(/boot下文件)需要的文件系统驱动,此时就可以使用/boot/grub/grub.conf,此配置文件中定义了kernel文件的位置,然后就可以加载kernel。
13. 手写chkconfig服务脚本,可以实现服务的开始,停止,重启。
[root@rocky87 ~]# cat /etc/init.d/test
# chkconfig: - 96 3
# description: test chkconfig service
start() {
echo "test service started"
}
stop() {
echo "test service stopted"
}
restart() {
echo "test service restarted"
}
case $1 in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
*)
echo "usage: service test start|stop|restart"
esac
[root@rocky87 ~]#
[root@rocky87 ~]# chkconfig --add test
[root@rocky87 ~]# chkconfig --list
Note: This output shows SysV services only and does not include native
systemd services. SysV configuration data might be overridden by native
systemd configuration.
If you want to list systemd services use 'systemctl list-unit-files'.
To see services enabled on particular target use
'systemctl list-dependencies [target]'.
test 0:off 1:off 2:off 3:off 4:off 5:off 6:off
[root@rocky87 ~]# service test restart
test service stopted
test service started
[root@rocky87 ~]# service test start
test service started
[root@rocky87 ~]# service test stop
test service stopted
[root@rocky87 ~]#
14. 总结systemd服务配置文件
/usr/lib/systemd/system #每个服务最主要的启动脚本,类似之前的/etc/init.d
/lib/systemd/system #ubuntu的对应目录,兼容centos7,8和Ubuntu
[root@centos79 ~]# ll /| grep lib
lrwxrwxrwx. 1 root root 7 Mar 13 23:40 lib -> usr/lib
/run/systemd/system #系统执行过程中产生的服务脚本,比上面目录优先运行
/etc/systemd/system #管理员建立的执行脚本,类似/etc/rcN.d/Sxx
unit类型
[root@rocky87 ~]# systemctl -t help
Available unit types:
service 文件扩展名为.service,用于定义系统服务
socket 文件扩展名为.socket,定义进程间通信用的socket文件,也可以在系统启动时延迟启动服务,实现按需启动
target 用于模拟实现运行级别
device 定义内核识别的设备
mount 定义文件系统挂载点
automount 文件系统的自动挂载点
swap 用于识别swap设备
timer
path 定义文件系统中的一个文件或目录使用,常用于当文件系统变化时延迟激活服务,如spool目录
slice
scope
unit格式说明
unit格式说明:
● #开头的行后面内容是注释
● 相关布尔值,1、yes、on、true都是开启;0、no、off、false都是关闭
● 时间单位默认是秒,其他单位要显式说明
service unit file通常由三部分组成:
● [Unit] 定义与Unit类型无关的通用选项;用于提供unit的描述信息,unit行为及依赖关系
○ Description:描述信息
○ After:定义unit的启动次序,表示当前unit应该晚于哪些unit启动,与Before相反
○ Requires:依赖到的其他units,强依赖,被依赖的units无法激活时,当前unit也无法激活
○ Wants:依赖到的其他units,弱依赖
○ Conflict:定义units间的冲突关系
● [Service] 与特性类型相关的专用选项
○ Type:定义影响ExecStart及相关参数的功能的unit进程启动类型
■ simple:默认值,这个daemon主要由ExecStart接的指令串来启动,启动后常驻内存
■ forking:由ExecStart启动的程序透过spawn延伸出其他子程序来作为此daemon的主要服务,原生父进程在启动结束后就会终止
■ oneshot:与simple类似,不过这个程序在工作完毕就结束了,不会常驻内存
■ dbus:与simple类似,但这个daemon必须要在取得一个D-bus的名称后才会继续运行。因此通常也要同时设定BusName=才行
■ notify:在启动完成后会发送一个通知消息,还需要配合NotifyAccess来让Systemd接收消息
■ idle:与simple类似,要执行这个daemon必须要所有的工作都顺序执行完毕后才会执行。这类的daemon通常是开机到最后才执行即可的服务
○ EnvirenmentFile:环境配置文件
○ ExecStart:指明启动unit需要运行命令或脚本的绝对路径
○ ExecStartPre:ExecStart前运行
○ ExecStartPost:ExecStart后运行
○ ExecStop:指明停止unit要运行的命令或脚本
○ Restart:当设定Restart=1时,则档次daemon服务意外终止后,会再次自动启动此服务
○ RestartSec:设置在重启服务前暂停多长时间,默认100ms
○ PrivateTmp:设定为yes时,会生成/tmp/systemd-private-UUID-NAME.service-XXXXX/tmp/ 目录
● [Install] 定义由“systemcrl enable”以及“systemctl disable”命令在实现服务启用或禁用时用到的一些选项
○ Alias:别名,可使用systemctl command Alias.service
○ RequiredBy:被哪些units所依赖,强依赖
○ WantedBy:被哪些units所依赖,弱依赖
○ Also:安装本服务的时候还要安装别的相关服务
15. 总结system启动流程
- UEFI或BIOS初始化,运行POST开机自检
- 选择启动设备
- 引导装载程序,centos7是grub2,加载装载程序的配置文件
a. /etc/grub.d/
b. /etc/default/grub
c. /boot/grub2/grub.cfg - 加载initramfs驱动模块,即通过/boot下的简化版linux加载操作系统根所需文件系统的驱动
- 加载内核选项
- 内核初始化,centos7使用systemd代替init
- 执行initrd.target所有单元,包括挂载/etc/fstab
- 从initramfs根文件系统切换至磁盘根目录
- systemd指定默认target配置,配置文件/etc/systemd/system/default.target
- systemd执行sysinit.target初始化系统及basic.target准备操作系统
- systemd启动muti-user.target下的本机与服务器服务
- systemd执行muti-user.target下的/etc/rc.d/rc.local
- systemd执行muti-user.target下的getty.target及登录服务
- systemd执行graphical需要的服务
16. 总结awk工作原理,awk命令,选项,示例。
awk先执行BEGIN语句块,
然后读入一行文本,执行pattern action语句块,这个过程一直重复到文本末尾
最后执行END语句块
命令语法
awk [options] 'program' var=value file...
awk [options] -f programfile var=value file...
-F 也支持正则表达式
program通常是被放在单引号中,并可以由三种部分组成
● BEGAIN语句块
● 模式匹配的通用语句块
● END语句块
pattern{action statements;...}
#pattern:决定动作何时触发以及触发事件,比如:BRGIN,END,正则表达式。pattern中!代表取反
#action:对数据进行处理
示例
#常见内置变量
FS
[root@centos79 ~]# df |awk -v FS=" +|%" '{ print $5}'
Use
0
0
2
0
9
14
0
[root@centos79 ~]#
OFS:输出字段分隔符,默认为空白字符
[root@centos79 ~]# df |awk -v FS=" +|%" -v OFS="|" '{ print $1,$5}'
Filesystem|Use
devtmpfs|0
tmpfs|0
tmpfs|2
tmpfs|0
/dev/mapper/centos-root|9
/dev/sda1|14
tmpfs|0
[root@centos79 ~]#
while循环在使用时需注意
while (condition){statement;...}
#注意condition如果为真则执行statement,如果为假则退出循环执行下一个record,然后再进行新一次while
The first thing the while statement does is test the condition. If the condition is true, it executes the statement body. After body has been executed, condition is tested again, and if it is still true, body executes again. This process repeats until the condition is no longer true. If the condition is initially false, the body of the loop never executes and awk continues with the statement following the loop.
17. 总结awk的数组,函数。
awk的数组为关联数组
[root@rocky87 ~]# awk -F: '{ arr[$1]++}END{for(i in arr){print i,arr[i]}}' /etc/passwd
www 1
tcpdump 1
sshd 1
postgres 1
systemd-resolve 1
shutdown 1
bin 1
redis 1
yu 1
chrony 1
tss 1
mail 1
halt 1
adm 1
nginx 1
shichao 1
apache 1
polkitd 1
dbus 1
named 1
operator 1
cockpit-wsinstance 1
systemd-coredump 1
nobody 1
ftp 1
sync 1
mysql 1
cockpit-ws 1
games 1
daemon 1
root 1
sssd 1
libstoragemgmt 1
lp 1
[root@rocky87 ~]#
多维数组
[root@rocky87 ~]# awk 'BEGIN{
> a[1][1]=11
> a[1][2]=12
> a[2][1]=21
> a[2][2]=22
> for(i in a){
> for(j in a[i]){
> print(a[i][i])
> }}}'
11
11
22
22
awk函数分为内置函数和自定义函数
内置函数
数值处理:
● rand():返回0到1之间的一个随机数
● srand():配合rand函数生成随机数的种子
● int():返回整数
字符处理函数:
● length():返回指定字符串的长度
● sub(r,s,t):对t字符串搜索r表示的模式匹配内容,并将第一个配置到的内容替换成s,即懒惰模式
● gsub(r,s,t):对t字符串搜索r表示的模式匹配内容,并将所有配置到的内容替换成s,即贪婪模式
● split(s,array,r):以r为分隔符,切割字符串s,并将切割后的结果保存到array数组中,数组的第一个元素索引值为1
awk中调用shell命令:
system("shell_cmd")
[root@rocky87 ~]# awk '{print $0;system("echo -------")}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
-------
bin:x:1:1:bin:/bin:/sbin/nologin
-------
daemon:x:2:2:daemon:/sbin:/sbin/nologin
-------
时间函数:
systime() #返回1970年1月1日到当前时间的秒数
strftime() #指定时间格式
[root@rocky87 ~]# awk 'BEGIN{ print systime()}'
1680229106
[root@rocky87 ~]# awk 'BEGIN{ print strftime("%Y-%m-%d %H:%M",systime()-3600)}'
2023-03-30 21:20
[root@rocky87 ~]#
自定义函数
第一步:定义函数
cat function.aw
function(){
…
}
第二步awk调用函数
awk -f function.awk
较高级使用较少
18. 总结ca管理相关的工具,根据使用场景总结示例。
关于加密解密的图示理解

私有CA实现证书颁发
- 创建私有CA
创建CA所需的文件
生成CA私钥
生成CA自签名证书
#生成证书索引数据库文件
touch /etc/pki/CA/index.txt
#指定第一个颁发证书的需要(16进制)
echo 01 > /etc/pki/CA/serial
#生成CA私钥
cd /etc/pki/CA
(umask 066; openssl genrsa -out private/cakey.pem 2048)
#生成CA自签名证书
openssl req -new -x509 -key /etc/pki/CA/private/cakey.pem -days 365 -out /etc/pki/CA/cacert.pem
-new:生成新证书签署请求
-x509:专用于CA生成自签名证书
-key:生成请求时用到的私钥文件
-days:证书的有效期
-out:自签证书的保存路径
- 证书申请及签署步骤:
- 生成证书申请请求
- RA核验
- CA签署
- 获取证书
#为需要使用证书的主机生成私钥
(umask 066;openssl genras -out /data/test.key 2048)
#为需要使用证书的主机生成证书申请文件
openssl req -new -key /data/test.key -out /data/test.csr
#在CA签署证书并将证书颁发给请求者
openssl ca -in /data/test.csr -out /etc/pki/CA/certs/test.crt -days 100
19. 总结openssh免密认证原理,及免认证实现过程。
- 客户端手动生成一对密钥(此处指账号密钥)
- 将客户端的公钥用ssh-copy-id拷贝的服务端
- 当客户端再次发送ssh连接请求时(包括ip/用户名)
- 服务器得到客户端的请求后,会到authorized_keys中查找,如果有相应的IP和用户,就会随机生成一个字符串,并用客户端拷贝过来的公钥对字符串加密发送给客户端
- 客户端用私钥解密,然后将解密后的随机字符串发给服务端
- 服务端比较字符串,一致则允许免密登录
实现基于密钥的登录方式
#在客户端生成密钥对
ssh-keygen -t rsa [ -P 'password'] [-f "~/.ssh/id_rsa"]
#将公钥文件传输至远程服务器对应用户的家目录
ssh-copy-id [-i [identify_file]] [user@]host
21.解析进程和线程的区别?
● 线程是程序执行的最小单位,而进程是操作系统分配和调度资源的最小单位。
● 一个进程由一个或多个线程组成
● 进程之间相互独立,但同一进程下的线程之间共享的进程内存空间(包括代码段,数据段。,堆等)及一些进程的资源(如打开的文件和信号),进程内的线程在其他进程不可见
● 线程上下文切换比进程切换要快的多
22 解析进程的结构。
内核把进程存放在叫做任务队列(task list)的双向循环链表中,链表中的每一项都是类型为task_struct,称为进程控制块(processing control block),PCB中包含一个具体进程的所有信息
● 进程id、用户id和组id
● 程序计数器
● 进程的状态(就绪,运行,阻塞)
● 进程切换时需要保存和恢复的CPU寄存器的值
● 描述虚拟地址空间的信息
● 描述控制终端的信息
● 当前工作目录
● 文件描述符,包含很多指向file结构体的指针
● 进程可以使用的资源上限(ulimit -a可查看)
● 输入输出状态:配置进程使用I/O设备















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









