






一.任务
PCA实战task:
1、基于iris_data.csv数据,建立KNN模型实现数据分类(n_neighbors=3)
2、对数据进行标准化处理,选取一个维度可视化处理后的效果
3、进行与原数据等维度PCA,查看各主成分的方差比例
4、保留合适的主成分,可视化降维后的数据
5、基于降维后数据建立KNN模型,与原数据表现进行对比
二.实战
#加载数据
import pandas as pd
import numpy as np
data = pd.read_csv('iris_data.csv')
data.head()

#定义X,y
X = data.drop(['target','label'],axis=1)#去掉最后两列
y = data.loc[:,'label']

// A code block
var foo = 'bar';
#建立模型
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors=3)#选用最近的三个点来预测新的点属于哪一类
KNN.fit(X,y)
y_predict = KNN.predict(X)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)

准确率达到了0.96,可以试着改变选用的点的个数来看看精度会怎么改变。
#将数据进行标准化处理
from sklearn.preprocessing import StandardScaler
X_norm = StandardScaler().fit_transform(X)
print(X_norm)

这样我们看不出来现在的数据和原来有什么区别,所以下一步进行可视化数据,分别将现在的数据和原来的数据可视化出来做一个对比
#数据可视化
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(20,5))
plt.subplot(121)
plt.hist(X.loc[:,'sepal length'],bins=100)#这里只取sepal length这一个维度
plt.subplot(122)
plt.hist(X_norm[:,0],bins=100)#将标准化处理后的数据可视化
plt.show()

这里我们可以看到原来的均值大概是6左右,而标准化处理后的均值大概是0左右。但到底是不是这样呢?我们可以计算一下
#计算均值和标准差
x1_mean = X.loc[:,'sepal length'].mean()#原数据的均值
x1_norm_mean = X_norm[:,0].mean()#处理后数据的均值
x1_sigma = X.loc[:,'sepal length'].std()#原数据的标准差
x1_norm_sigma = X_norm[:,0].std()#处理后数据的标准差
print(x1_mean,x1_sigma,x1_norm_mean,x1_norm_sigma)
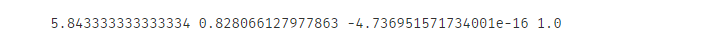
我们可以看到处理后的数据的均值很小,后面都是一个10的负16次方了,接近于0,它的标准差为1.0,符合我们数据预处理希望的结果。
#看一下原数据的维度,下面要用
print(X.shape)

这里的维度是4,我们的目标是把它降为2。下面就开始进行任务的第3步。
# pca analysis
from sklearn.decomposition import PCA
pca = PCA(n_components=4)#原数据是维度是4,要进行同等维度的PCA处理,故n_components=4
X_pca = pca.fit_transform(X_norm)#这里已经是经过PCA处理的主成分了
#计算各维度下的主成分的方差比例
var_ratio = pca.explained_variance_ratio_
print(var_ratio)
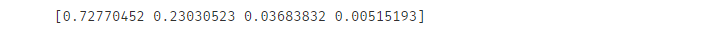
可以看到前两个的方差比例是比较大的,这说明相关性就比较小,所以我们保留前两个主成分
#可视化数据
fig2 = plt.figure(figsize=(20,5))
plt.bar([1,2,3,4],var_ratio)#有4个维度,所以这里是1,2,3,4
plt.xticks([1,2,3,4],['PC1','PC2','PC3','PC4'])#给每维度的主成分的方差比例图加上名称
plt.ylabel('variance ratio of each PC')#给y轴加上名称
plt.show()

最后两项的方差比例是比较小的,数据间的相关性较高,很多信息是重复的,所以舍弃掉而选择前面两项。到这里任务第3步就完成了,下面开始任务第四步。
pca = PCA(n_components=2) #因为我们要把数据维度降为2,所以这里n_components=2
X_pca = pca.fit_transform(X_norm)
X_pca.shape #看一下维度,这里已经为2了

type(X_pca)#看一下类型

#可视化数据
fig3 = plt.figure(figsize=(10,6))
setosa = plt.scatter(X_pca[:,0][y==0],X_pca[:,1][y==0])#标签为0的
versicolor = plt.scatter(X_pca[:,0][y==1],X_pca[:,1][y==1])#标签为1的
virginica = plt.scatter(X_pca[:,0][y==2],X_pca[:,1][y==2])#标签为2的
plt.legend((setosa,versicolor,virginica),('setosa','versicolor','virginica'))
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()

至此,第4步已经完成,下面进行最后一步
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X_pca,y)
y_predict = KNN.predict(X_pca)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)

我们可以看到数据降到2维后,准确率只下降了一点点,说明还是不错的。至此我们的实战就告一段落了。
三.总结
PCA实战summary:
1、通过计算数据对应的主成分(principle components),可在减少数据维度同时尽可能保留主要信息;
2、为确定合适的主成分维度,可先对数据进行与原数据相同维度的PCA处理,再根据根据各个成分的数据方差确认主成分维度;
3、核心算法参考链接:https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html?highlight=pca#sklearn.decomposition.PCA
本次分享就到这里啦,thanks~~
数据集.
提取码:6i01














 72
72











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









