







一、背景
首先明确下,拿Clickhouse这种OLAP来跟关系型数据库Oracle、内存MapReduce Spark、磁盘MapReduce Hive对比比性能,的确有点欺负人的感觉,但没办法,业务需求,为了说服IT部门给部署Clickhouse集群,千万级的数据量,他们动不动就上Hadoop体系,我实在看不下去了,撸起袖子自己来吧。
定性结论:
1、Clickhouse作为OLAP中的特立独行者,做数据分析真的是再合适不过了,丰富的分析函数可以节省大量时间,同时,性能在4个平台中,呈现碾压趋势。函数方面,举个例子:要实现Excel中的sumif函数功能,CH中直接有sumIf函数与之对应,Oracle、Spark、Hive都要借助sum(Case when...else...end)来实现,极其繁琐;类似的还有Mutiif、toDate、toYear等,简直不要太方便。
2、Oracle我一直以为是收费的,结果去官网一查,软件使用竟然是免费的,当然仅供学习和科研,商业还是要收费的,MySQL也被Oracle收购了,PG号称最好的关系型数据库,但明显干不过Oracle,关键原因在于Oracle后面有强大的团队支撑,保障数据不丢失,这一点,对于支撑事务的关系型数据库来说是至关重要的。Oracle的性能在千万级别下,中规中矩,跑点简单规则和指标加工还行。
3、Spark和Hive我放到一起说,我的建议,100亿级一下数据量,建议别上Hadoop体系,有那个资源上一套分布式Clickhouse集群,分分钟完成原来需要个把小时的计算任务,除非你要用Pyspark跑一些复杂模型,但现实告诉我,实际业务中复杂模型几乎没有用途,后面我会专门写一篇算法介绍的文章,其根本原因在于业务需要清晰的解释性,如果你的模型结果不能很好解释出因果关系,连搭上业务的机会都没有,当你研究出牛逼的模型的时候,先问问自己业务人员能听懂不?我自己能用清晰的逻辑解释清楚我的模型不?如果不能,想办法变成能吧,否则就只能躺在模型库里,发挥不出任何价值。扯远了。。。。 回归正题,Spark和Hive应对千万级数据,效率太低了,不建议采用,具体看测试报告。
二、测试环境
内存:64G
硬盘:2T机械
Cpu: 24 QEMU Virtual CPU
Cpu: 2095.072 MHz
Cache size : 16384 KB
操作系统:CentOS Linux 7.8.2003 Core
资源类型:KVM云主机 虚拟机
Oracle版本:19c(19.3.0.0.0)容器方式部署 单机
Clickhouse版本:21.8.10.19 容器方式部署 单机
Spark版本:2.4.0 容器方式部署 1master+2worker
Hive版本:2.3.7 容器方式部署
Hadoop版本:2.7.3 容器方式部署 1master+2slave
以上环境同时开启。
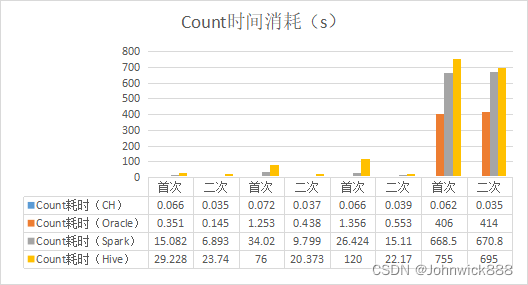
三、数据存储、Count对比测试:
为节省时间,仅测试了部分有代表性的表。CH的LZ4压缩比大概在8倍左右,另外,我发现Spark在生成RDD的时候也用了LZ4压缩算法,这个LZ4有时间真要好好研究下。
| 数据量(条) | Oracle存储(MB) | CH存储(MB) | HDFS存储(MB) | Count耗时(CH) | Count耗时(Oracle) | Count耗时(Spark) | Count耗时(Hive) |
| 2,224,594 | 464 | 64 | 495.03 | 0.066 0.035 | 0.351 0.145 | 15.082 6.893 | 29.228 23.740 |
| 155,624 | 38 | 6.8 | 41.06 | ||||
| 5,317,136 | 1800 | 392 | 2130 | 0.072 0.037 | 1.253 0.438 | 34.020 9.799 | 76 20.373 |
| 123,768 | 104 | 29 | 99.82 | ||||
| 733,737 | 168 | 22 | 179.59 | ||||
| 5,504,293 | 2200 | 445 | 2390 | 0.066 0.039 | 1.356 0.553 | 26.424 15.110 | 120 22.170 |
| 45,254,157 | 21000 | 2600 | 22860 | 0.062 0.035 | 406 414 | 668.5 670.8 | 755 695 |
| 924,963 | 112 | 18 | 120 | 0.068 | 0.126 | 7.545 | 22.290 |
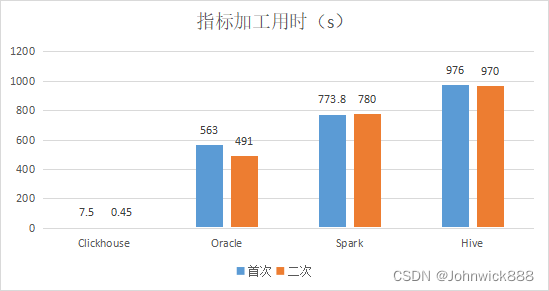
四、复杂指标加工测试:
数据量4500W+
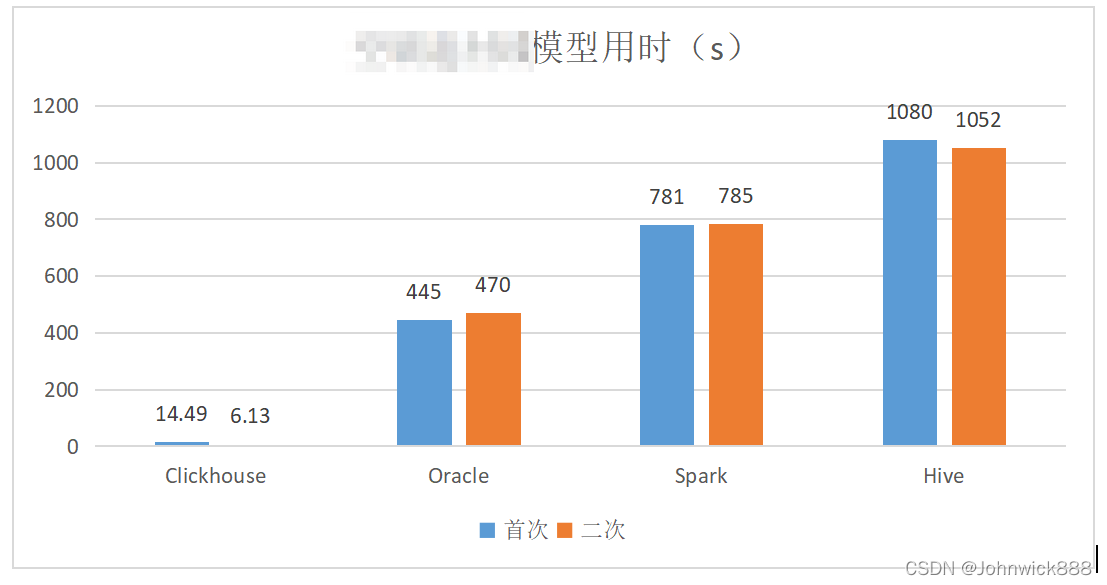
五、复杂规则型模型测试:
数据量4500W+ 、550W+ 有join操作
六、几点结论
- 无论是简单的Count查询,复杂指标加工查询,还是带有join操作的复杂规则模型查询,Clickhouse这种OLAP平台都有压倒性优势;
- 无论从计算效率和存储效率来看,排名都是Clickhouse>Oracle>Spark>Hive;
- 从Count效率来看,当数据量在550W左右的时候,CH、Oracle、Spark的计算时间都在可接受范围内,首次查询能在30s内完成;但当数据量来到4500W+的时候,除CH外,其他平台效率均过低,此时,CH的首次查询效率是Oracle的6550倍,二次查询效率约为12000倍;
- 从指标加工效率来看,除CH外,其他平台用时均在500s以上,即8分钟以上,而CH首次可在8s内给出结果,此时,CH首次查询效率为Oracle的75倍,二次效率为1091倍;
- 从复杂规则模型来看,首次查询CH可以在15s内完成,其他平台均在400s以上,此时,CH首次查询效率为Oracle的31倍,二次效率为77倍;
- 同时,对比指标加工和模型用时,可以看出Oracle的指标加工效率要低于条件过滤效率,在各平台用时普遍增加的情况下,Oracle两种情景下用时不增反降;CH的指标加工效率较条件过滤更高。
- 关于Oracle容器部署请参考这位老兄的,docker安装oracle19c_逝水无痕博客-CSDN博客_docker安装oracle19c,提醒一点,记得带上自动重启参数和网络参数,否则容易容器之间无法访问。我的启动命令如下,shadownet是我建Hadoop集群时候设置的影子网络,搜索docker network 命令就能查询到怎么用,这里不赘述。
-
docker run --restart=always --net shadownet --ip 172.18.0.96 --hostname oracle \ -p 1521:1521 -p 5500:5500 \ -e ORACLE_SID=orcl \ -e ORACLE_PDB=orclpdb1 \ -e ORACLE_PWD=123456 \ -e ORACLE_CHARACTERSET=zhs16gbk \ -e ORACLE_BASE=/opt/oracle \ -e ORACLE_HOME=/opt/oracle/product/19c/dbhome_1 \ -e PATH=/opt/oracle/product/19c/dbhome_1/bin:/opt/oracle/product/19c/dbhome_1/OPatch/:/usr/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin \ -v /data/oradata:/opt/oracle/oradata \ --name myoracle \ registry.cn/oracle:19c - 关于CH集群的部署,下周我会写一遍出来,目前我动手实现了基于Zookeeper的高可用集群,和丢弃Zookeeper,仅用两个节点实现的Clickhouse集群,两种方案在参数设置上略有不同,在后面的文章中我会详细阐述。这应该是新年前最后一篇博文了,祝各位技术大拿新年快乐,虎虎生威。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









