







文章目录
Q8:关系抽取的三类常用方法及其优缺点
关系抽取就是从文本中判定实体对之间存在的特定的关系。
基于模版、规则的方法(触发词)
通常是找关键词。
依存句法分析
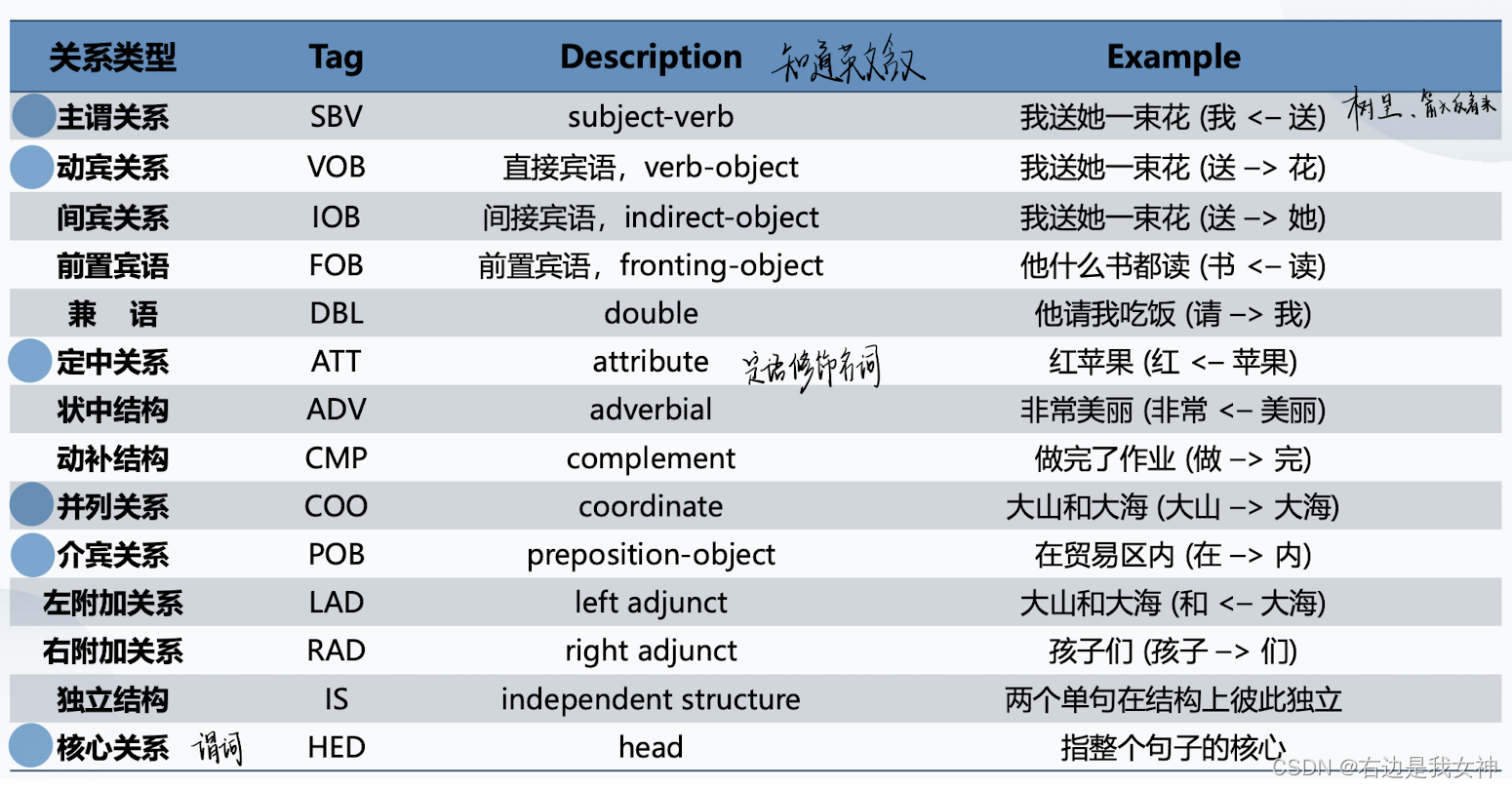
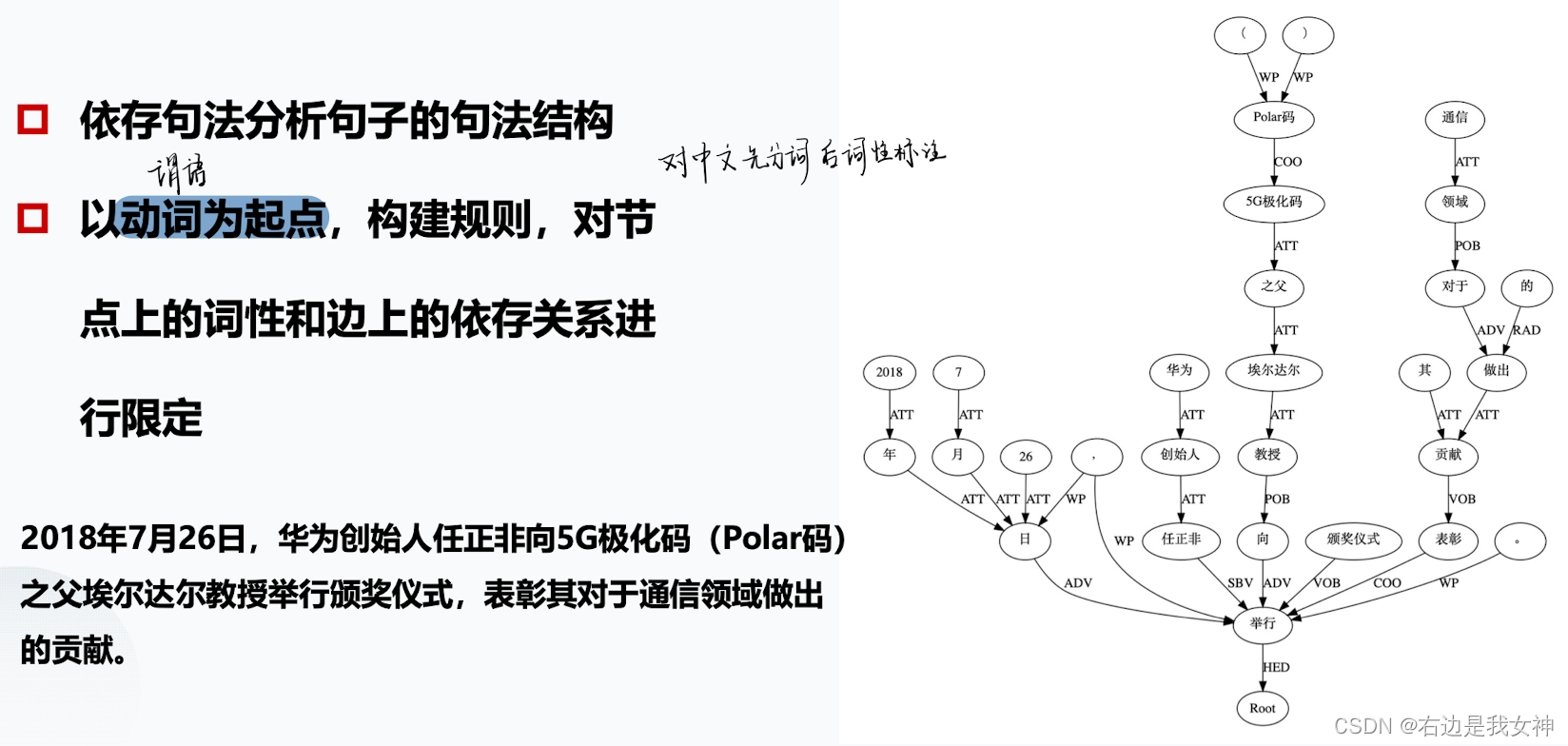
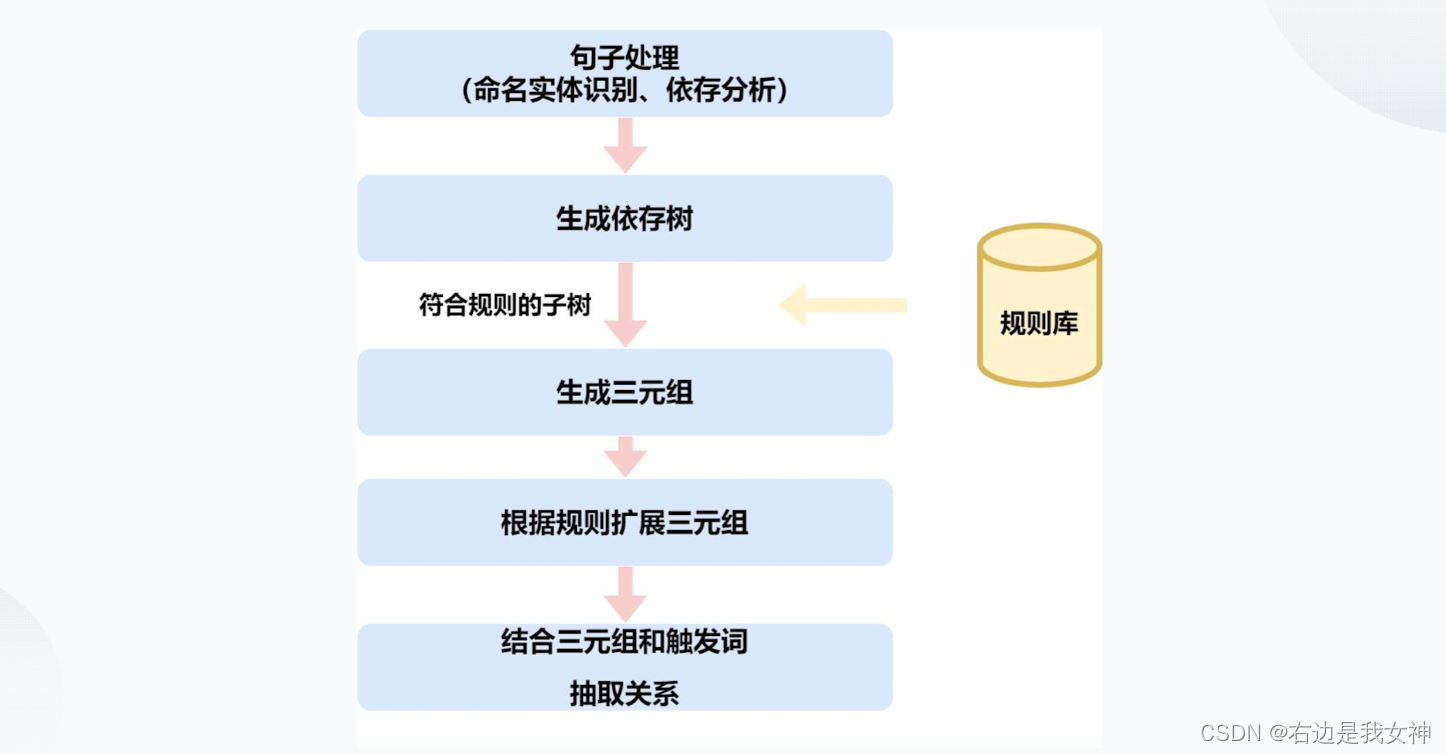
根据句子依存语法树结构上匹配规则,每匹配一条规则就生成一个三元组。
所谓扩展三元组可以理解为知道(小王,在,图书馆),可以同理推出(小张,身处,食堂)。
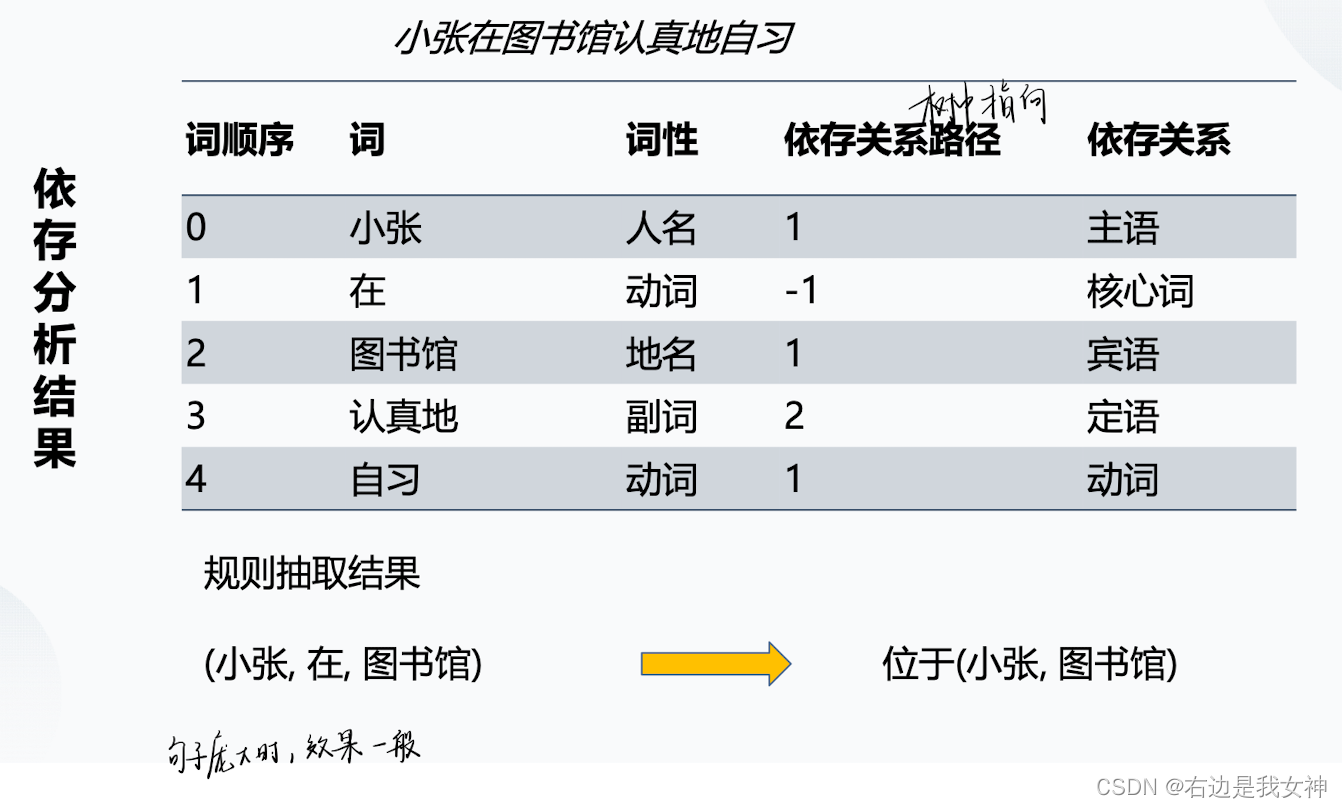
比如根据主谓宾关系抽取三元组,然后依据规则或者触发词从中抽取出关系。
| 优点 | 缺点 |
|---|---|
| 在小规模数据集上容易实现 | 特定领域的模板需要专家构建 |
| 构建简单 | 难以维护 |
| - | 可移植性差 |
| - | 规则集合小的时候,召回率很低 |
基于传统机器学习的方法
分为学习过程和预测过程。在学习过程中,通过支持向量机等传统机器学习方法对有量数据的训练语料库进行训练,得到分类模型。在预测过程中,实体对送入训练好的关系抽取模型中进行对这些候选实例的分类。
基于特征向量的关系抽取方法
核心思想:通过从句子上下文中提取出句法和语法等特征信息去构造特征向量,进而利用特征向量的相似度训练实体关系识别模型,如最大熵。
关键:如何获取各种有效的词法、句法、语义等特征,并把它们有效地集成起来,从而产生描述实体语义关系的各种局部特征(词级)和简单全局特征(句级),不同特征对最终系统的性能有不同影响。
基于核函数的关系抽取方法
核心思想:通过核函数将输入空间的数据嵌入到合适的高维特征空间,通过线性分类器在新的特征空间进行关系抽取。本质就是通过核函数计算两个实体之间的相似度。
关键:设计出计算两个关系实例相似度的核函数。
两个方法之间的比较
| 方法 | 优势 | 局限性 |
|---|---|---|
| 基于特征向量的方法 | 可解释性好 | 特征选择和设置上更多依靠构建者的直觉和经验;特征项的选择组合是有限的,无法表示指定语义关系 |
| 基于核函数的方法 | 处理高维特征空间问题计算代价低;求解的是凸优化问题;核矩阵展现输入在特征空间中相对位置的信息 | 随着性能要求的提升,核函数的复合更为复杂,导致训练预料过慢,对于大规模数据处理能力差 |
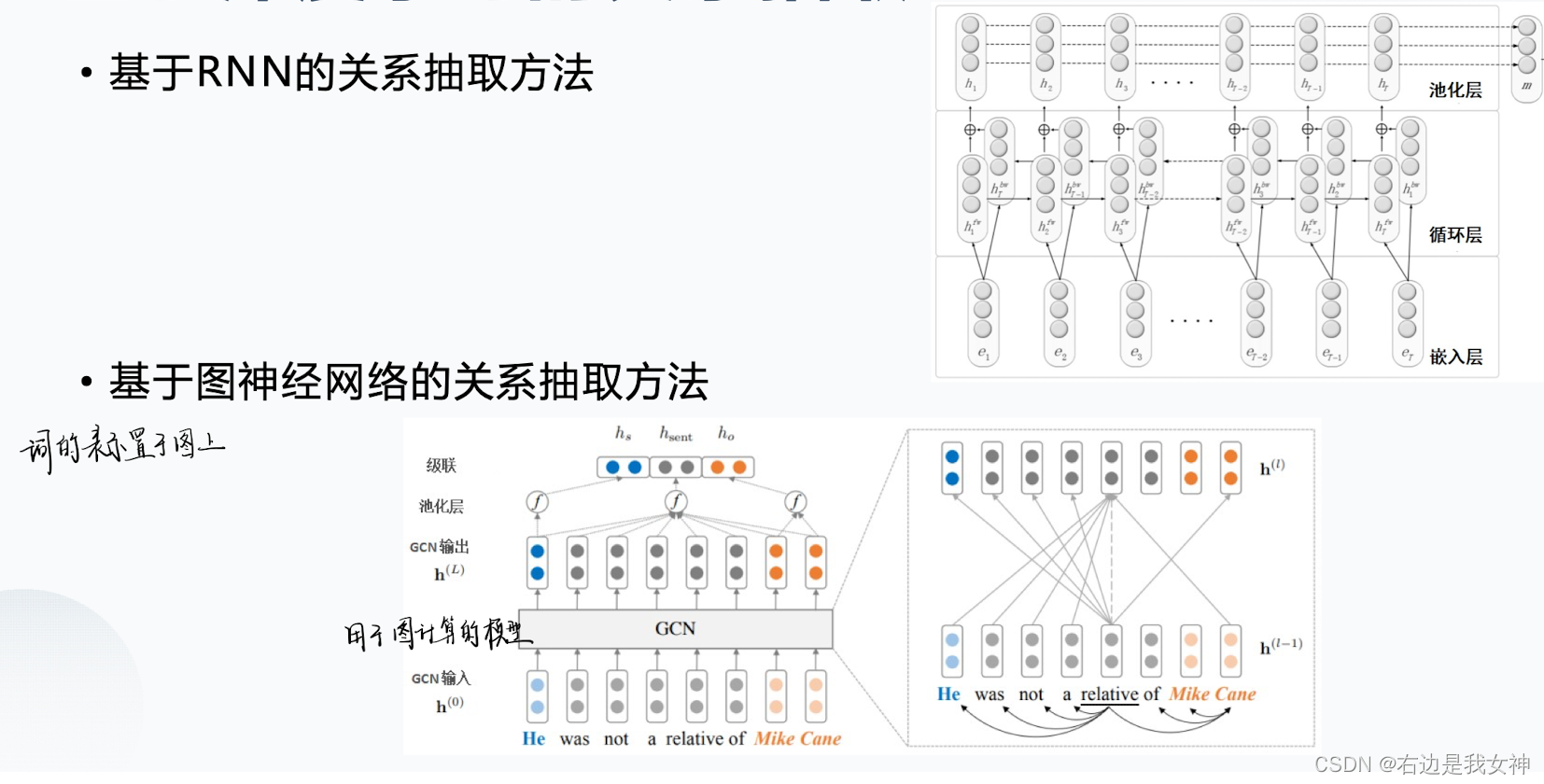
基于深度学习的方法
基于CNN的方法
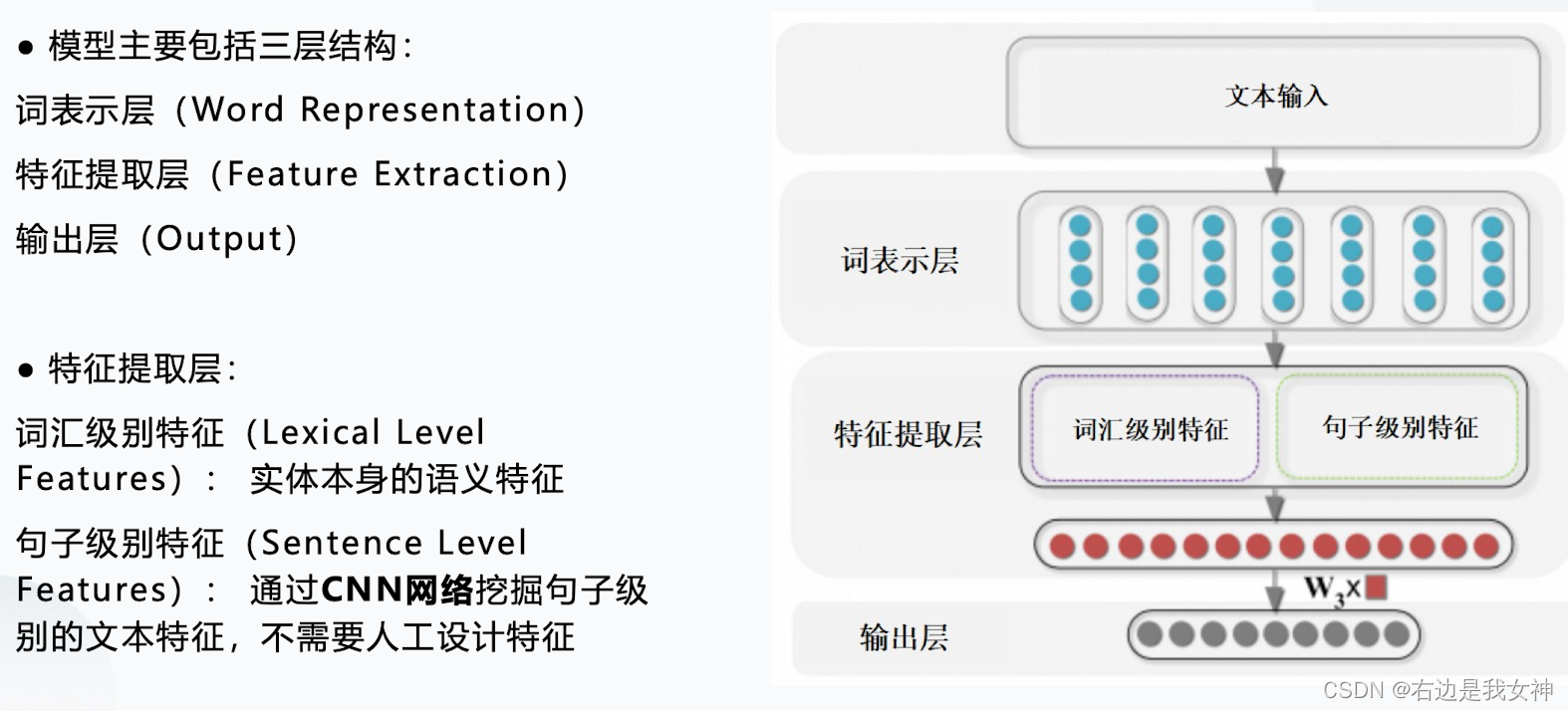

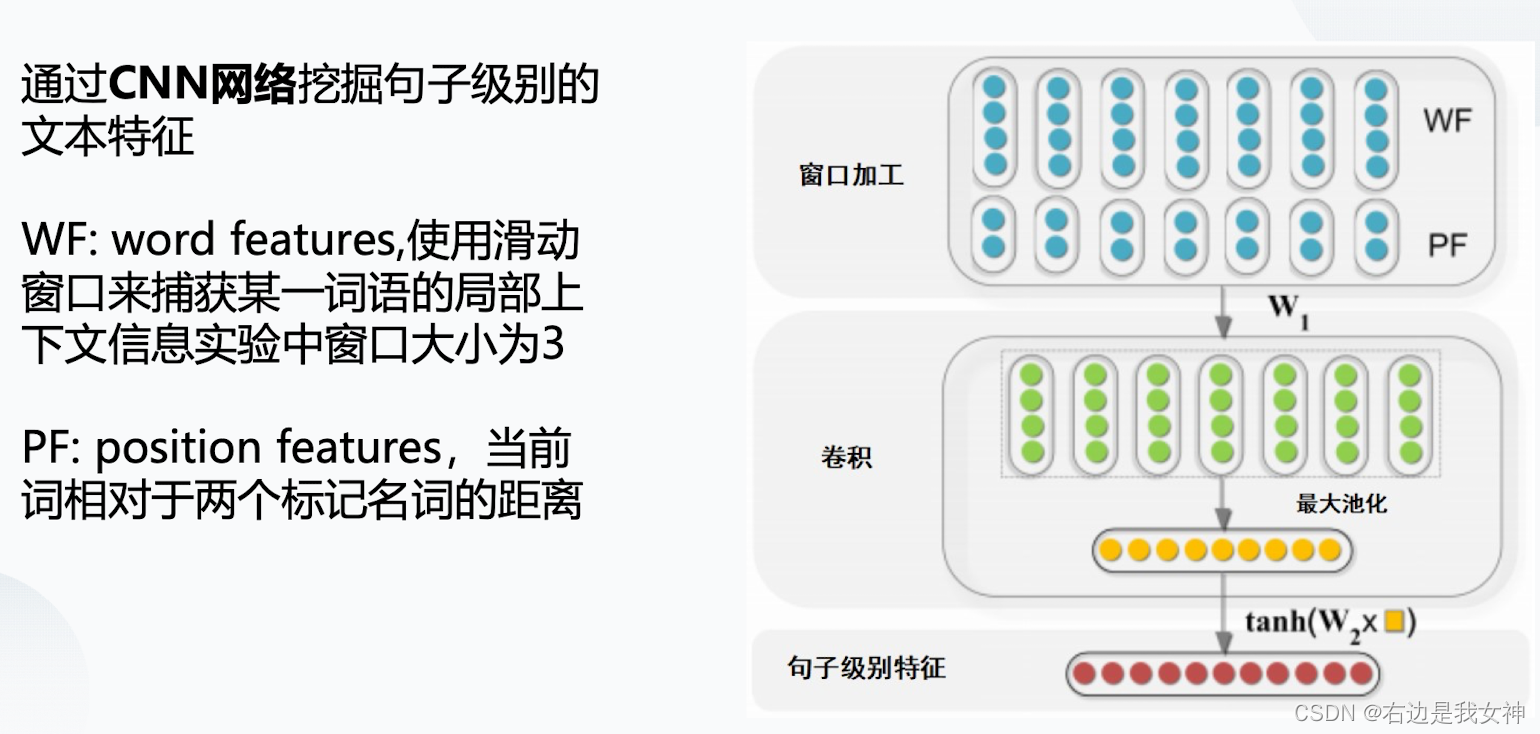
与机器学习任务相比
| 机器学习的缺陷 | 深度学习的优势 |
|---|---|
| 特征工程是一个很要的组成部分,基于特征向量的方法需要人工选取特征,基于核函数的方法可以自动抽取但是没有从语义层面计算特征。同时在进行特征抽取之前还要进行分词、词性标注、句法分析等工作,这是典型的pipeline做法,其中存在的错误会逐渐累积。 | 深度学习技术通过端到端的抽取方法能大幅度减少特征工程,减少对预处理模块的依赖,使得特征表示更具有深度。 |
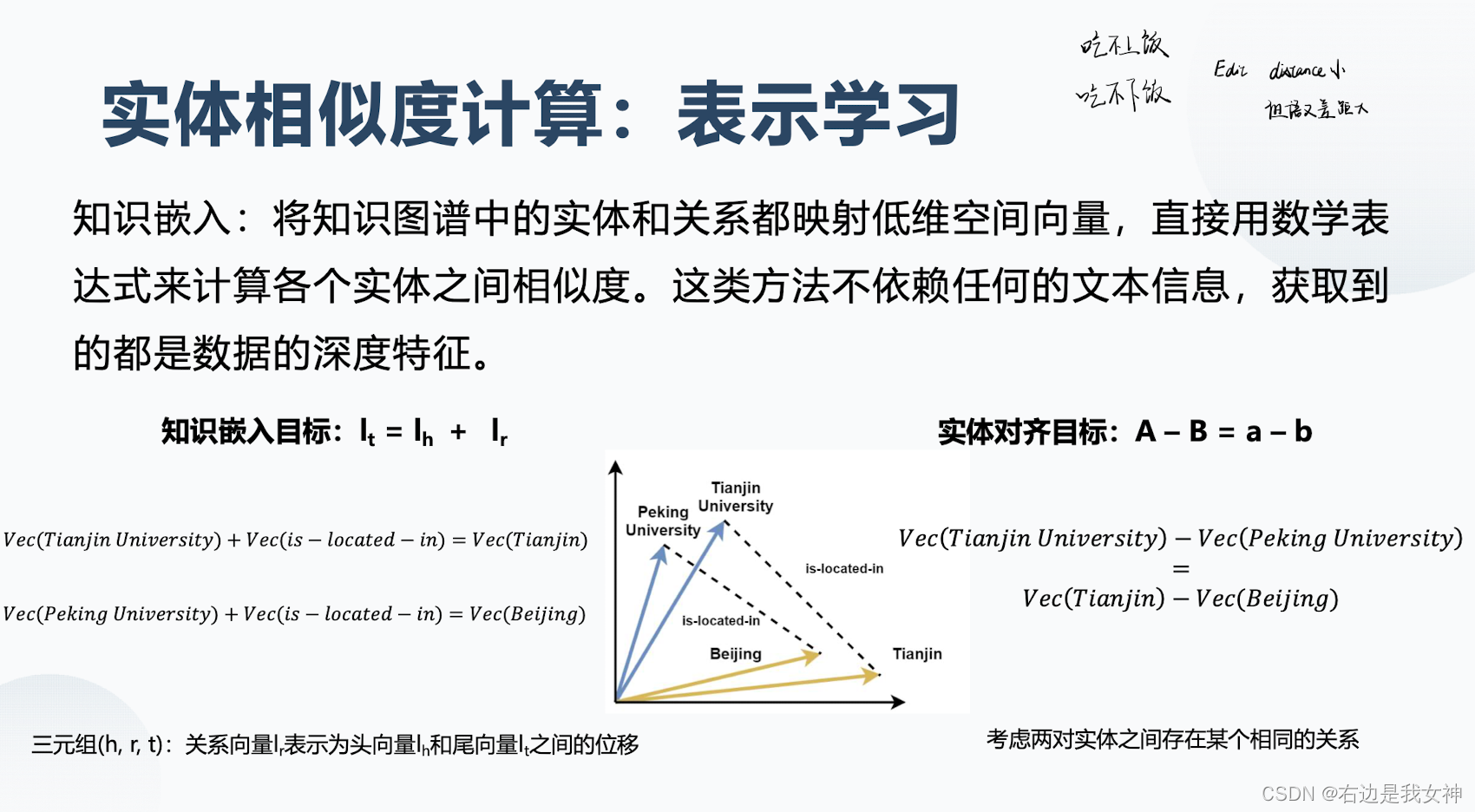
Q9:知识融合的两种方式&常用工具&实体对齐的常用方法
引言
知识图谱之间存在异构问题:
语言异构:语法(JSON、XML、RDF、OWL);逻辑;表达能力;
概念异构:概念化不匹配(动物有的划分为哺乳动物和鸟,有的划分为食肉动物和食草动物);解释不匹配。
知识融合是研究如何融合来源于多个数据集的关于同一实体或概念的描述信息。
比如depedia.org中的Rome和geoname.org中的roma是同一个实体。通过两个sameAs链接。这一工作称为知识融合。主要也是针对知识图谱进行的。
具体而言是两个层面的匹配关系:
- 本体层匹配(等价类、子类、等价属性、子属性这些抽象的关系)
- 实例层匹配(实例等价这些具体的关系)
常见的方法也有两个:
- 本体匹配:发现等价类、相似的类、属性或关系;
- 实体对齐:发现指向相同真实对象的不同实例。
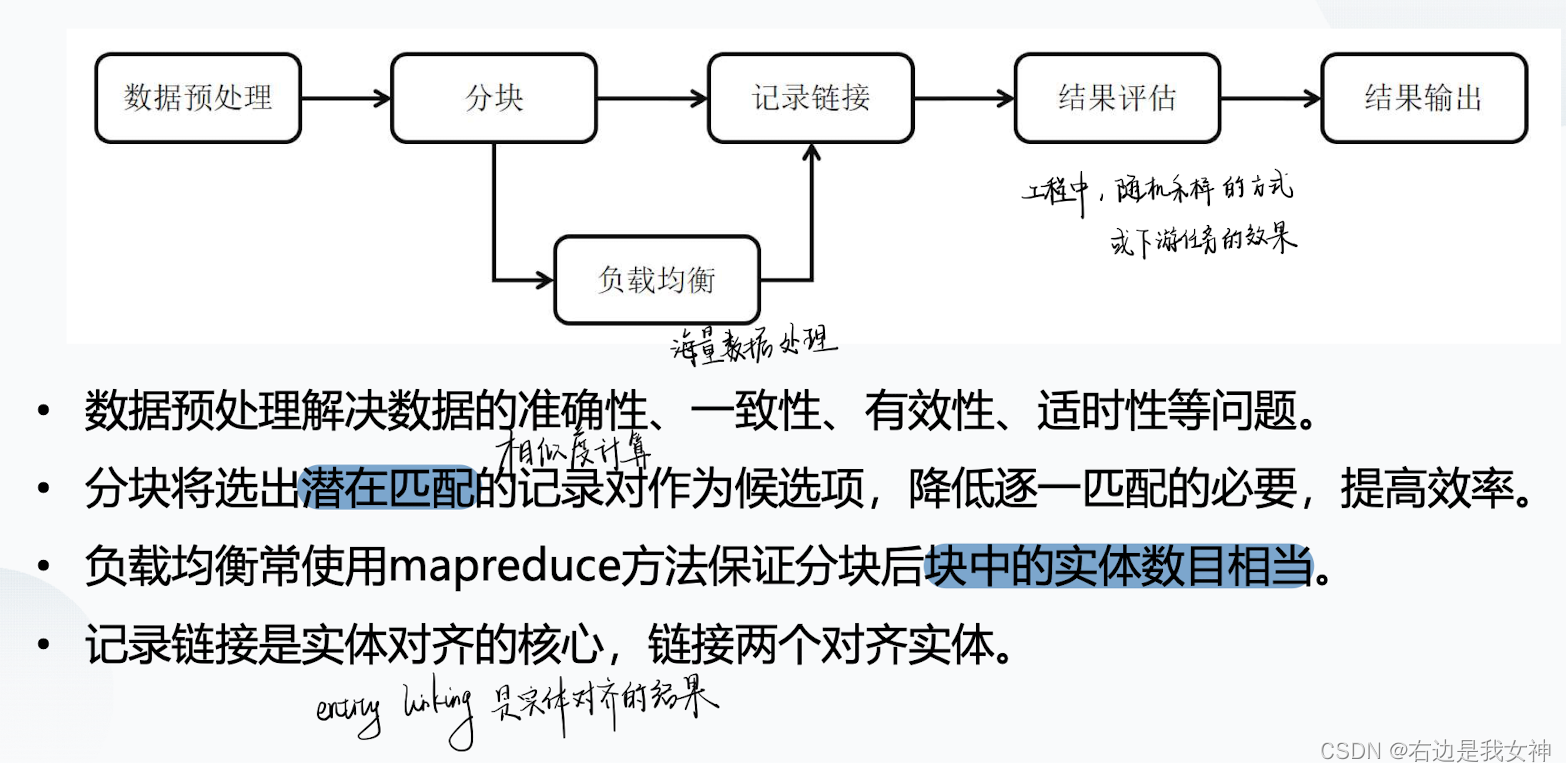
一般流程
本体匹配
本体指的是一个概念体系的显式的形式化规范。形式化地刻画了一个领域。一个典型的本体由有限个术语(给定论域中的概念)以及他们之间的关系组成。

本体匹配是指计算两个不同本体之间的相似度的过程,通过相似度的值来判断本体中实体之间的语义关系,实现语义之间的映射。


本体匹配工具:Falcon-AO
Falcon-AO是一个自动的本体匹配系统,已经成为RDF(S)和OWL所表达的Web本体相匹配的一种实用和流行的选择。编程语言为Java。作者为胡伟。
实体对齐
实体对齐是在实例层的融合,目的是融合相同现实对象的不同实例。这个所谓的实例在不同领域的称呼不一样(知识工程(实例),数据库(记录),自然语言处理(实体))。
实体对齐(实体匹配)的常用方法
基于快速相似度计算的实例匹配方法
通过计算实体之间的相似度来判断实体之间的匹配关系。

基于规则的实例匹配方法
通过匹配规则来实现实体之间的匹配。
由于数据源的异构性,处理不同的数据源需要不同的匹配规则,往往需要人类手工构建规则来保证结果质量。
基于分治的实例匹配方法
分治处理方法的思想是降低相似度计算的总的时间复杂度。采用分治策略,将大规模知识图谱划分为k个小规模的知识图谱匹配后,计算这些小知识图谱见的匹配。
基于学习的实例匹配方法
可视为机器学习的二分类问题,利用知识图谱中丰富的网络结构信息和实例相关的信息来训练一个分类模型,从而实现实例匹配。因为实例的规模较大,所以分类之前需要对实例进行分块。通常采用基于属性的规则来进行分块处理。
实体对齐工具
| 名称 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| Dedupe | 实用机器学习对结构化数据快速执行模糊匹配,重复数据删除和实体对齐的python库 | 主动学习:主动学习训练正负样本,降低用户标注 | 属性数量有限制,要求输入数据集中记录的属性数量很少,通常为10-20个 |
| Silk系统 | 是一个用于集成异构数据源的开源框架,用途有:生成不同关联数据源中相关数据项的链接;关联数据发布者可以使用Silk将RDF链接从其数据源设置为Web上的其他数据源;将数据转换应用于结构化数据源 | 提供了专门的Silk-LSL语言进行具体的处理;提供图形化界面Silk Workbench方便用户记录链接 | - |
Q10:两种关系型数据库的存储方式&基本原理&优缺点
基本知识储备
知识存储
知识存储是指将知识放在磁盘中。知识存储主要包括两种存储方式:集中式存储和分布式存储。
| 类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 集中式系统 | 由一台或多台主计算机组成中心节点:数据集中存储在这个中心节点上,整个系统的业务单元集中在这个中心节点上,系统的所有功能均由其集中处理 | - | 大型主机的人才培养成本非常高;大型主机很昂贵;有明显的单点问题(某一部分奔溃,全部奔溃) |
| 分布式系统 | 将知识分散存储在多台独立的设备上;其要素有一致性(多台服务器共同存储数据,服务器数量增加,出故障的概率也在增加);可用性(需要多台服务器同时工作);分区容错性(通过网络进行连接) | 提高了系统的可靠性、可用性和存储效率还易于扩展 | - |
关系型数据库介绍
概念模型
概念模型用于信息世界的建模,是现实世界到信息世界的第一层抽象。为了把现实世界中的具体事物抽象、组织为某一数据库管理系统支持的数据模型,人们常常首先将现实世界抽象为信息世界(然后将信息世界转化为机器世界)。所谓信息世界是一种信息结构,不依赖于计算机系统,是概念级别的模型,称为概念模型。
| 信息世界中的基本概念 | 描述 |
|---|---|
| 实体 | 客观存在并且可相互区别的事物,可以是具体的人、事、物或者抽象的概念 |
| 属性 | 实体所具有的某一特性,一个实体可以由若干个属性来刻画 |
| 码 | 唯一标识实体的属性集 |
| 域 | 属性的取值范围 |
| 实体型 | 用实体名及其属性名的结合来抽象和刻画同类实体 |
| 实体集 | 同一类型的实体的集合 |
| 联系 | 实现世界中事物内部以及事物之间的联系在信息世界中反映为实体内部的联系和实体之间的联系 |
两个实体之间的联系



两个以上实体型之间的联系


对于供应商中的每一实体,项目中有n个实体与之联系。这是n的含义。
E-R图
E-R模型是描述现实世界的概念模型。矩形表示实体型、椭圆形表示属性、菱形表示联系,同时无向边写上关系类型。

关系模型
用二维表形式表示实体和实体之间联系的数据模型。属于机器世界的模型表示。
关系型数据库系统采用关系模型作为数据的组织方式。
| 关系模型的数据结构 | 描述 | 对应的表格术语 |
|---|---|---|
| 关系 | 一个关系对应通常说的一张表 | 一张二维表 |
| 元组 | 表中的一行即为一个元组 | 行/记录 |
| 属性 | 表中的一列即为一个属性,给每个属性起一个名称即为属性名 | 列 |
| 主码 | 表中的每个属性组,它可以唯一确定一个元组 | - |
| 域 | 属性的取值范围 | - |
| 分量 | 元组中的一个属性值 | 一条记录中的一个列值 |
| 关系模式 | 对关系的描述:学生(学号、姓名、年龄、性别、系、年级) | 表头(表格的描述) |
关系的完整性
| 关系的三类完整性约束 | 描述 |
|---|---|
| 实体完整性 | 若属性A是基本关系R的主属性,则属性A不能取空值 |
| 参照完整性 | 关系间的引用:在关系模型中实体及实体间的联系都是用关系来描述的,因此可能存在着关系与关系间的引用;外码:设F是基本关系R的一个或一组属性,但不是关系R的码,如果F与基本关系R的主码K相对应,则称F是基本关系R的外码;参照完整性规则:若属性F是基本关系R的外码,它与基本关系S的主码K相对应,则对R中每个元组在F上的取值必须为:F的属性值为空或者等于S中某个元组的主码值 |
| 用户定义的完整性 | 针对某一具体关系数据库的约束条件,反映某一具体应用所涉及的数据必须满足语义要求 |
RDF的关系存储(两类存储方式)
RDF一般描述一个三元组(主语、宾语、谓语)。
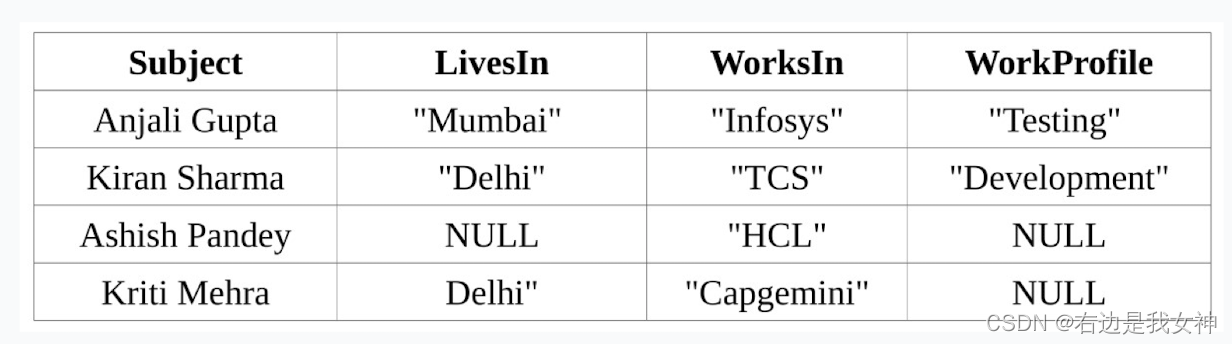
RDF属性表&水平划分
RDF属性表相当于水平表的划分,不同类型的实体存入不同的表中。不能存储多值属性和一对多联系。
原理
使用一张N+1列数据表存储RDF数据集(N为数据集中不同谓词数目)。
基于主语对RDF数据集进行划分,数据表中每行记录存储知识图谱中一个主语的所有谓语和宾语,不存在对应宾语时使用空值填充。
优缺点
| 优点 | 缺点 |
|---|---|
| 将同一主语的所有数据存储在同一行,有利于星型SAPRQL查询处理 | 数据表中可能存在大量空值,引入存储和查询额外空值的开销 |
| Join(将表连在一起查询输出)减少了,接近于关系型数据库,可重用RDBMS(关系型数据库)功能 | 数据表所需列数目等于RDF数据集中不同谓语数量,该数量可能超过关系数据库所允许的表中列数目上限 |
| - | 不能存储多值或一对多的关系 |
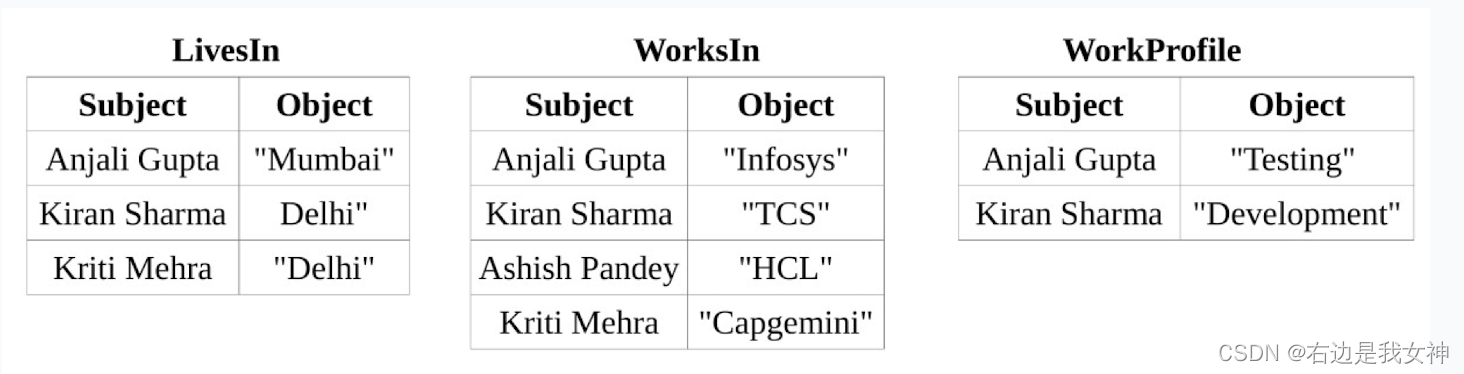
RDF二元关系表&垂直划分
相当于三元组按谓词进行划分,有名垂直划分表。
为每一个谓词创建一个两列表,共N个2列表(N:属性数量);
多个谓词的查询会导致多表链接问题(谓词多则表多)。
原理
垂直划分的方法使用N张两列表存储RDF数据集(N为数据集中不同谓词个数);
基于谓词对数据集进行划分,为每种谓词构建一张两列表,表名即为该谓词,表中每行数据是由该谓词连接的一对主语和宾语。
优缺点
| 优点 | 缺点 |
|---|---|
| 仅存储出现在RDF数据集中的三元组,不存储空值 | 创建两列表数目与数据集中不同谓语个数相等,数量较大时难以维护 |
| 将多值属性存储为连续的行,解决了多值问题 | 对于具有n条边的SPARQL查询,垂直划分方法需要读取n张数据表,并执行n-1次Join |
| 基于主语列对数据表进行排序,能够使用归并排序连接快速执行Join操作 | 存在多表链接问题 |
Q11:基于图模型的存储的优点&属性图模型存储数据的原理&典型的系统
引入
关系型数据库的局限性:
- 关系模型将语义关系隐藏在外键结构中,无显式表达,并带来关联查询与计算的复杂性;
- 知识图谱需要更加丰富的关系语义表达和关联推理能力;
- 关系型数据库处理关联查询通过join,百万级别数据数小时才能完成,在图数据库上进行图查询可以在秒内完成计算。
关系模型背离了接近自然语言的方式来描述客观世界的原则,这使得概念化、高度关联的世界模型与数据的物理存储之间出现了失配。
优点
| 优点 | 描述 |
|---|---|
| 自然表达 | 使用图的方式来表达现实世界的关系很直接、自然、易于建模 |
| 便于扩展 | 图数据库可以很高效地插入大量数据。关系型数据库如MySQL需进行分库分表,图模型数据库可以轻松胜任亿级以上的数据 |
| 关联查询高效 | 图模型数据库可以很高效地查询关联数据。传统关系型数据库需要做表的连接,涉及大量的IO操作以及内存消耗 |
| 多跳优化 | 在处理多跳查询上,图模型有性能优势 |
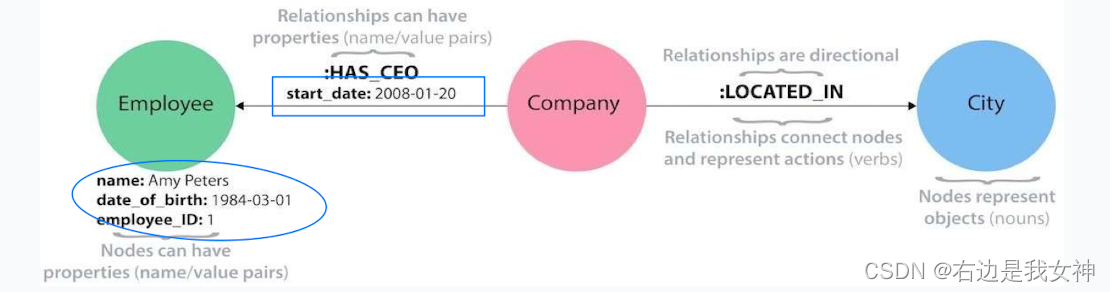
原理
属性图是图数据模型,由顶点集和边集组成;
节点可以由一个或多个标签;
节点具有一组属性,每个属性是一个键值对;
边有一个类型和方向;
边也可以具有属性。
典型的图数据库管理系统
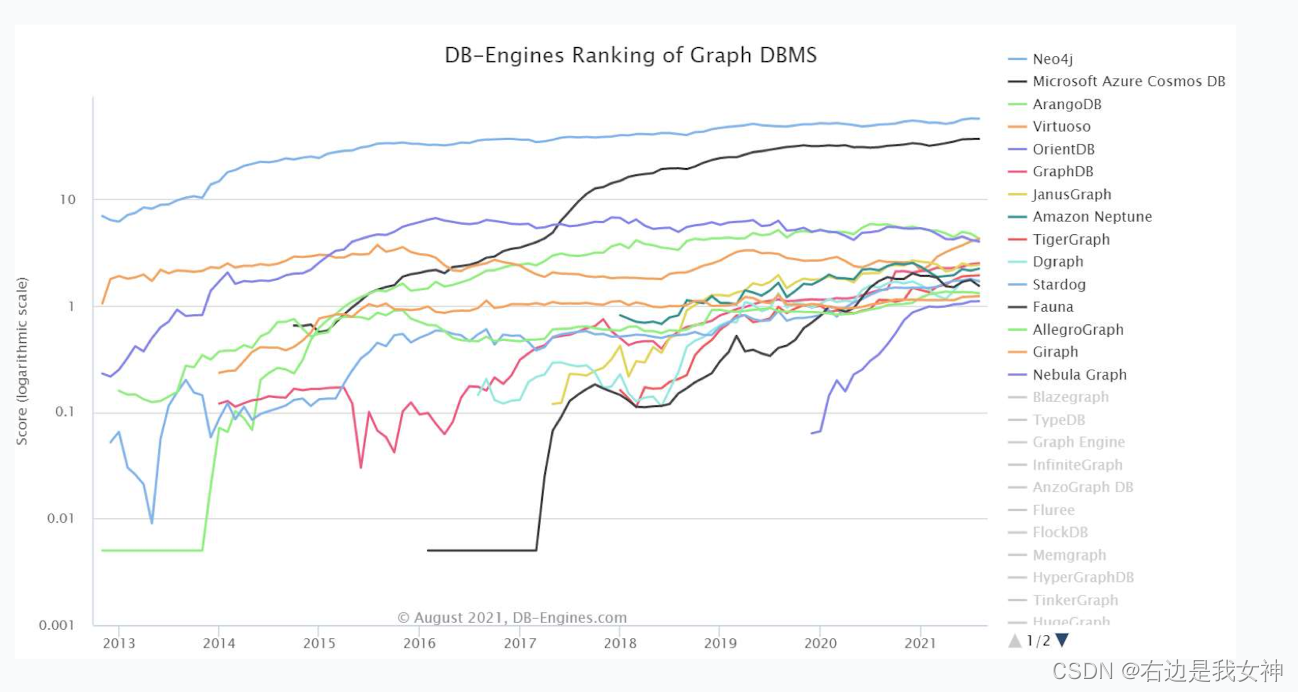
Q12:SQL、SPARQL、Cypher查询语句
SQL查询语句
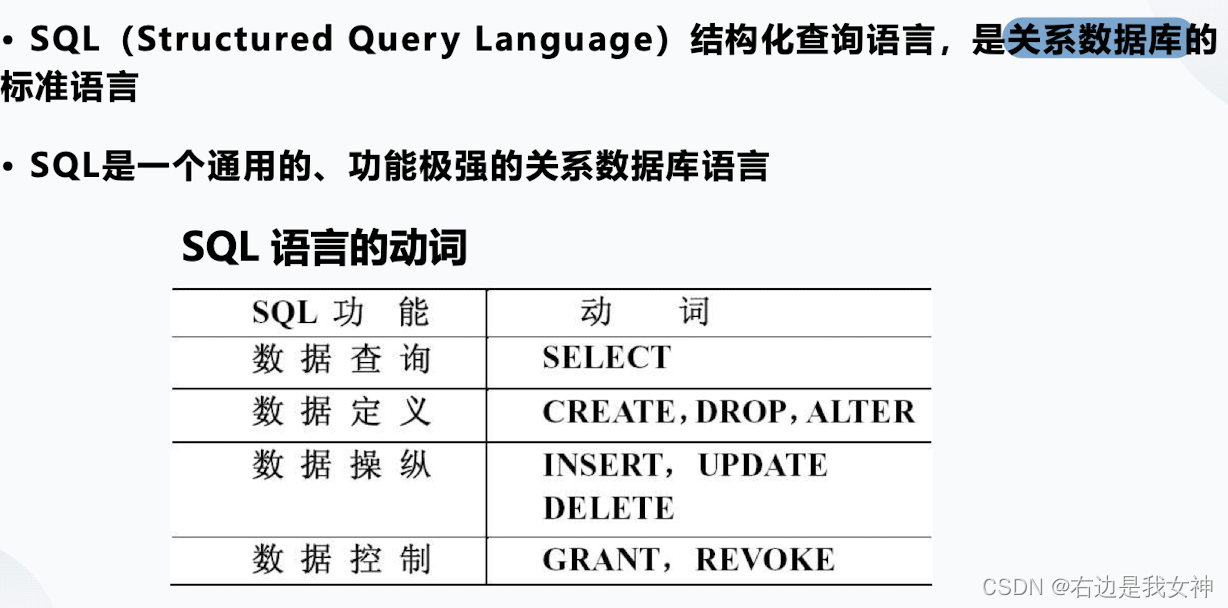
以学生-课程数据库为例
| 表名 | 描述 |
|---|---|
| 学生表 | Student(Son,Sname,Ssex,Sage,Sdept) |
| 课程表 | Course(Con,Cname,Cpno,Ccredit) |
| 学生选课表 | SC(Sno,Cno,Grade) |
其结果如下
CREATE
描述:建立一个学生表Student,包含学号、姓名、性别、年龄、所在系五个属性。要求学号为主码,姓名取值唯一。SQL的常见数据类型参见这篇文章。
CREATE TABLE Student(
Sno CHAR(9) PRIMARY KEY,
Sname CHAR(20) UNIQUE,
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
同理课程表的定义为:

关注主码、唯一标识符、外码的写法。
SELECT
查询指定列
SELECT Sno,Sname
FROM Student;
选出所有列
SELECT *
FROM Student;
查询经过计算的值
简单的计算
SELECT Sname,2004-Sage
FROM Student;

比较大小
查询所有年龄在20岁以下的学生姓名及其年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage<20
查询考试成绩有不及格学生的学号
SELECT DISTINCT Sno
FROM SC
WHERE Grade<60
单表的唯一查询:DISTINCT,比如(200101,1,59),(200101,2,58),这样就有两门课不及格,会返回两次200101。
确定范围
查询年龄在20~23岁之间(包括20和23)的学生的姓名、系别和年龄
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
查询年龄不在20~23岁之间(包括20和23)的学生的姓名、系别和年龄
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage NOT BETWEEN 20 AND 23;
字符匹配
1.匹配固定的字符串
查询学号为200215121的学生的详细情况
SELECT *
FROM Student
WHERE Sno LIKE ‘200215121’;
或者 WHERE Sno = ‘200215121’;
2.匹配串为含通配符的字符串
查询所有姓刘学生的姓名、学号和性别
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname LIKE ‘刘%’;
查询姓欧阳且全名为三个汉字的学生的姓名
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳__';
查询名字中第2个字为“阳”的学生的姓名和学号
SELECT Sname,Sno
FROM Student
WHERE Sname LIKE '__阳%';
查询所有不姓刘的学生姓名
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname NOT LIKE ‘刘%’;
数据更新
INSERT
将新的元素插入指定表中
INSERT
INTO <表名>[(<属性列1>[,<属性列2>,...])]
VALUES (<常量1>[,<常量2>...])
INTO子句:属性列的顺序可与表定义中的顺序不一致;没有指定属性列;指定部分属性列;
VALUES子句:提供的值必须与INTO子句匹配:值的类型及值的个数。


不写属性就要全部赋值,没写的属性赋为空值。
UPDATE
修改指定表中满足WHERE子句条件的元组的指定列值。
UPDATE <表名>
SET <列名>=<表达式> [,<列名>=<表达式>]...
[WHERE <条件>];
SET子句:指定修改方式;要修改的列;修改后的取值;
WHERE子句:指定要修改的元组;缺省表示要修改表中的所有元组。

例6(相关子查询,里层要用到外层,如果里层不用到外层就是不相关子查询)
每次从SC里面取一个元组放到括号中,然后从Student表中找到有这个学号的学生的元组,从里面把专业取出来,如果等于CS的话,就把这个SC的元组给置零。
不相关子查询,更显而易见的写法。
UPDATE SC
SET Grade=0
WHERE Sno IN
(SELECT Sno
FROM Student
WHERE Sdept='CS');
分别对应着:修改某一元组的值;修改多个元组的值;带子查询的修改语句;
DELETE
删除指定表中满足WHERE子句条件的元组
DELETE
FROM <表名>
[WHERE <条件>]
WHERE子句:指定要删除的元组;缺省表示要删除表中的全部元组。

分别对应着:删除某一元组的值;删除多个元组的值;带子查询的删除语句。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











