






CLIP 改进工作串讲(上)【论文精读·42】
截止2022年9月.
分割
Language-driven semantic segmentation - ICLR2022
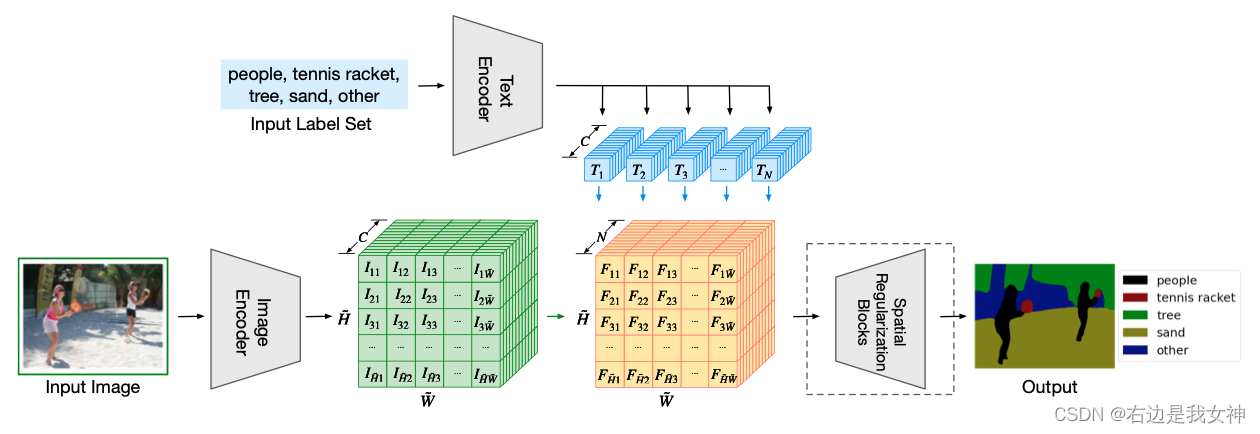
文本编码器采用CLIP的文本编码器, 原因是数据集规模小(10万,20万), 微调的话, 可能会把参数带偏.
视觉编码器采用DPT, 是作者之前的工作.
文本编码器得到 N × C N\times C N×C的特征, 视觉编码器得到 H ~ × W ~ × C \tilde{H}\times\tilde{W}\times C H~×W~×C的特征. 相乘后得到 H ~ × W ~ × N \tilde{H}\times\tilde{W}\times N H~×W~×N的特征.
本文的意义在于将文本分支加入进来, 使分割效果可以通过文本进行控制.
Spatial Regularization Blocks : 可忽略.
Failure cases : 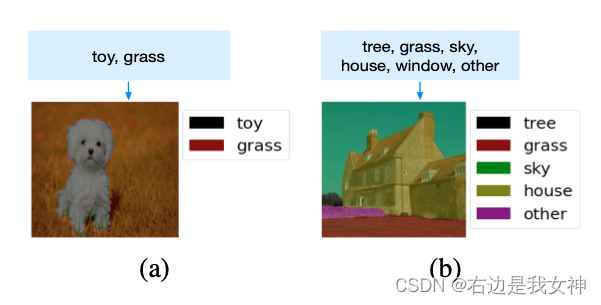
实际上, CLIP这一模型算的是图文之间的相似度, 所以选择相似的, 而不是准确的.
GroupViT: Semantic Segmentation Emerges from Text Supervision
监督信号来自文本, 和CLIP一样, 利用图像文本对进行训练.
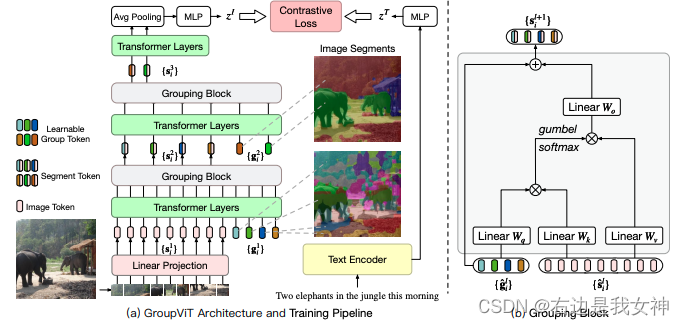
group: 有几个初始的中心点, 逐渐向外发散, 和与自己相近的点构成一个group, 形成最终的mask. 是一种自下而上的方式.
提出计算单元grouping block和一些可学习的tokens(贡献). 在学习的过程中能够把相邻相似的点给group
起来.
group tokens : 聚类中心, 初始设定为 64 × 384 64\times 384 64×384, 可以理解为cls token, 因为每一个类别/小块都有一个token去表示他.
grouping block : 将input token assign 到group token, 最终输出 g r o u p t o k e n s s i z e × 384 group tokens size \times 384 grouptokenssize×384.
如何训练呢?
把group tokens的特征做了pooling, 得到一个特征.
如何推理呢?

group embedding和text embedding计算相似度, 即可得到类别信息.
GroupViT分割做的很好, 但是分类效果不好. 这是因为CLIP只能学到语义信息很明确的东西.
目标检测
ViLD : Open-vocabulary object detection via vision and language knowledge distillation
引言非常好(越早知道想做什么越好).
现有数据集的标注信息有限. 本文希望在现有标注情况下, 做到识别更细粒度的,更深层次的标签.


Baseline是Mask RCNN.
ViLD-text也是在基础类上做有监督的训练, 目的是将视觉和文本编码关联起来. 其尚未具备open-vocabulary的能力.

如何拓展ViLD-text在CN(新的类别)上的性能?如何引入CLIP?
ViLD-image
对于候选框, 原网络抽取的特征和CLIP抽取的特征尽可能地接近, 即做蒸馏即可. 此时, 这是一个无监督的训练, 监督信号从CLIP来.
为了加快训练过程, 这里的proposals都已经抽取完全.
对于最终的ViLD, Splitting出的分支之用于训练.

有了图文编码即可计算交叉熵损失, 做无监督的训练.
回顾ViLD和GroupViT, 两者的共性在于:
- 在推理中, 图文编码的相似度用于反馈类别标签, 图像编码本身可以实现分割或检测.
两者的差异性在于: - ViLD用CLIP蒸馏, 目的是获取捕捉更多新类的能力;
- GroupViT则迁移了Grouping的思想, 其侧重点在于无监督训练.

LVIS数据集(长尾数据集), 分为三类, 下标f表示常见类, 下标c表示一般类, 下标r表示罕见类. 重点观察罕见类的结果. 效果好也是利用了LVIS的特性(少见数据不如不训).

视觉定位
目标检测: 给一张图像, 输出目标框;
视觉定位: 给一张图像, 一段文本, 输出目标框.
GLIP:Grounded Language-Image Pre-training
如何把图像文本对用上.
把detection和visual grounding结合起来, 把大规模图像文本对用上做预训练.


Visual Grounding的范式和ViLD-text的分类头是类似的.

统一后的detection和visual grounding任务对样本的要求是图像, 文本以及目标框. 为了扩大数据集, 作者额外引入了caption的数据, 然后通过tiny模型预测他们的目标框(伪标签).
每个框的编码和一句话中每个单词的编码计算相似度矩阵.

文本编码和图像编码直接得到后和L-Seg一样, 是可以直接计算相似度矩阵的. 但是图文之间的joint embedding 还不是学的很好, 因此需要一些Fusion模块优化两个编码的表示.
本文采用Cross Attention把两部分特征交互一下(DeepFusion技术).
上述Alignment Loss就是ViLD-text.

GLIP能够对概念做一些理解, 图上海绿色也能被框出.
对比ViLD和GLIP:
- 同样是需要预测框, 对于框的取舍, 都采用与文本的相似度计算;
- 对于框的定位, 这是固定不变的.
图像生成
CLIPasso: Semantically-Aware Object Skecthing
保持语义信息的物体素描.
把真实物体变成简单形象, 且保持简单形象的语义信息. 简而言之, 给一张真实照片, 反馈一张简笔画.
以往的方法收集素描数据集来训练模型, 这带来两个问题: 生成的风格受限, 生成的种类受限.

CLIP能够不管图像的风格, 都能够把图像的特征编码得特别好.

简笔画生成的特征和简笔画生成的特征尽可能接近, 即 L s L_s Ls, 语义损失.
除了在语义上的限制, 还需要在几何上进行限制, 即 L g L_g Lg. 把ResNet50浅层的特征去算loss, 因为其中保持一些几何信息.
此时, 已经可以通过贝兹曲线生成各种各样的简笔画了, 即简笔画的生成方式是前人的工作.
但是作者发现, 控制贝兹曲线的点的位置放置很有讲究. 于是提出了基于saliency的方法, 不过多赘述.
综上, 这里也是采用蒸馏的方式.
最后, 在生成简笔画的过程中, 得到了多幅, 最后选择与原图损失最小的, 这一思想在DALL-E中也被运用.

上图体现CLIPasso生成罕见图像的简笔画

上图体现CLIPasso生成不同难度的简笔画.
视频
略
多模态
How Much Can CLIP Benefit Vision-and-Language Tasks?
empirical study.
使用预训练好的CLIP模型当做视觉编码器的初始化参数, 然后在下游任务上微调并查看性能.
结论是效果很好!
深度估计
Can Language Understand Depth?
把深度估计看做分类问题.
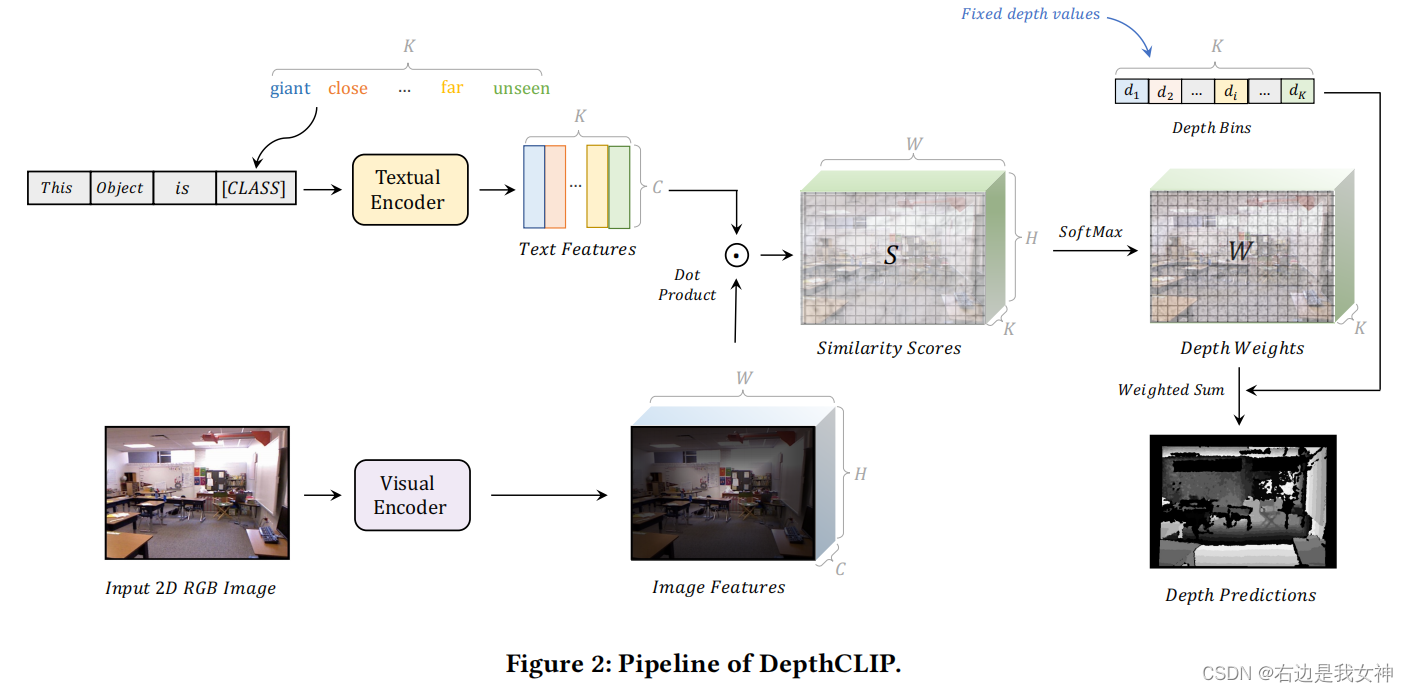
pipeline与L-seg高度相似.
总结
- 把图像和文本通过CLIP得到特征, 和原来的特征做拼接或点乘(L-Seg, ViLD);
- 把CLIP作为Teacher来蒸馏预训练好的知识(CLIPasso);
- 借鉴对比学习的思想, 定义自己的正负样本对并计算Loss(GroupViT).



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











