







Structured Streaming
Structured Streaming简介
• Structured Streaming是构建在Spark SQL引擎上的流式数据处理引擎,使用Scala编写,具有容错功能。
• sparkstreaming官方已经停止了维护,从spark2.2开始全力打造Structured Streaming
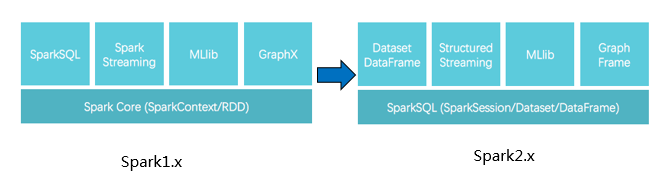
• Spark 1.x 时代里,以 SparkContext(及 RDD API)为基础,在 structured data 场景衍生出了 SQLContext, HiveContext,在 streaming 场景衍生出了 StreamingContext,很是琳琅满目。
• Spark 2.x 则精简到只保留一个 SparkSession 作为主程序入口,以 Dataset/DataFrame 为主要的用户 API,同时满足 structured data, streaming data, machine learning, graph 等应用场景,大大减少使用者需要学习的内容,爽爽地又重新实现了一把当年的 “one stack to rule them all” 的理想。
RDD、Dataset与DataFrame
• Spark 1.x的RDD更多意义上是一个一维、只有行概念的数据集,比如RDD[Person],那么一行就是一个Person,存在内存里也是把Person作为一个整体。
• Spark2.x里,一个Person的Dataset或DataFrame,是二维行+列的数据集,比如一行一个 Person,有name:String, age:Int, height
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









