







大模型场景实战培训,提示词效果调优,大模型应用定制开发,点击咨询
认识promptfoo
promptfoo是一款开源的prompt调优工具,该工具支持如下功能:
-
支持常见OpenAI、Anthropic、Azure、Google、HuggingFace、开源模型(如 Llama),或自定义 API 程序以用于任何 LLM模型提示词调优。
-
支持批量跑提示词;
-
支持提示词文件导入,模型应答结果导出;
还有更多功能,可以参考官方文档:https://www.promptfoo.dev/docs/intro/
今天我们来介绍如何使用promptfoo来调试百度千帆大模型。
快速上手
安装
npm install -g promptfoo
如果安装进度较慢,可以使用国内源。
npm install -g promptfoo --registry=https://registry.npm.taobao.org
初始化
执行如下命令,开启工具使用之路。
promptfoo init
选择2,我们来进行提示词调优,

如下会显示内置支持的大模型,如果您有对应模型的API Key,您可以选择其中之一。 我们今天来调优百度千帆大模型,没有在内置模型中,所以先跳过。

会在当前目录下生成一个promptfooconfig.yaml文件,这个文件也就是我们的工程文件或者叫测试集文件。
熟悉promptfooconfig.yaml
文件中最核心有三部分:prompts,providers和tests,分别为测试的提示词,调用模型和测试用例。
# Learn more about building a configuration: https://promptfoo.dev/docs/configuration/guide
description: "My eval"
prompts:
- "Write a tweet about {{topic}}"
- "Write a concise, funny tweet about {{topic}}"
providers:
- "openai:gpt-4o-mini"
- "openai:gpt-4o"
tests:
- vars:
topic: bananas
- vars:
topic: avocado toast
assert:
# For more information on assertions, see https://promptfoo.dev/docs/configuration/expected-outputs
# Make sure output contains the word "avocado"
- type: icontains
value: avocado
- prompts
这一部分用来插入提示词,支持一条或多条,支持通过文件导入。
prompts:
- 'Translate the following text to French: "{{name}}: {{text}}"'
- 'Translate the following text to German: "{{name}}: {{text}}"'
通过文件导入
prompts:
- file://path/to/prompt1.txt
- file://path/to/prompt.yaml
- file://path/to/personality1.json
- providers
这一部分用来指定要测试的大模型,支持常见的模型比如ChatGPT,Llama, Gemini,也可以脚本语言或者Http API来自定义一个模型。
比如我们今天要测试的百度千帆大模型不在内置模型列表,我们需要使用Python来自定义,接下来我们将会介绍。
providers:
- id: openai:gpt-4o-mini
config:
temperature: 0
max_tokens: 1024
- id: 'python:ERNIE-Lite-8K.py'
label: ERNIE-Lite-8K
config:
pythonExecutable: /usr/local/bin/python3
- tests
这一部分来录入测试用例,可以通过vars设置不同的参数变量,来对prompts进行测试,同时通过assert断言来校验输出结果。
tests:
- vars:
topic: 苹果
city: 成都
assert:
- type: starts-with
value: '```json'
自定义千帆大模型
我们通过Python脚本来实现千帆大模型的调用,脚本中要实现三个接口:call_api, call_embedding_api, 和 call_classification_api,同时按照要求格式返回。
以ERNIE-Speed-8K.py为例,代码如下:
import json
from chat import call_llm
# 这个接口用来调用我们的千帆大模型
def call_api(prompt, options, context):
# 在promptconfig.yaml的provider我们可以传入参数, 在call_api中接收,可以用做大模型运行参数
# 比如:temperature, top_p, stream等等
config = options.get('config', None)
additional_option = config.get('additionalOption', None)
# 这里接收提示词中的变量值,然后进行变量替换,生成最终的提示词
user_variable = context['vars'].get('userVariable', None)
# 在此调用大模型
output = call_llm('ERNIE-Speed-8K', prompt, config)
# 返回值中要包含output字段,也就是模型根据提示词输出的结果。
result = {
"output": output['result'],
}
# tokenUsage的使用信息,用于结果统计
usage = output['usage']
# If you want to report token usage, you can set the 'tokenUsage' field.
result['tokenUsage'] = {"total": usage['total_tokens'], "prompt": usage['prompt_tokens'], "completion": usage['completion_tokens']}
return result
def call_embedding_api(prompt):
# Returns ProviderEmbeddingResponse
pass
def call_classification_api(prompt):
# Returns ProviderClassificationResponse
pass
下面是我们千帆大模型调用的能用代码,其中实现call_llm函数, ERNIE-Speed-8K.py和chat.py是可以独立执行测试的,同时有依赖关系,最好放在同一目录下。
import os
import json
import requests
API_KEY = "******"
SECRET_KEY = "******"
models = {
"ERNIE-Speed-8K": "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-4.0-turbo-8k",
"ERNIE-Lite-8K": "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-lite-8k",
"ERNIE-Tiny-8K": "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-tiny-8k",
}
def call_llm(model, prompt, config=None):
url = models.get(model) + "?access_token=" + get_access_token()
payload = json.dumps({
"messages": [
{
"role": "user",
"content": prompt
}
],
"penalty_score": 1,
"enable_system_memory": False,
"disable_search": False,
"enable_citation": False,
"enable_trace": False,
"disable_search": False,
"enable_citation": True,
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
return response.json()
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
# 先从环境变量中读取,如果promptfoo没有设置环境变量,则从本地读
ak = os.getenv("QIANFAN_ACCESS_KEY", API_KEY)
sk = os.getenv("QIANFAN_SECRET_KEY", SECRET_KEY)
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": ak, "client_secret": sk}
return str(requests.post(url, params=params).json().get("access_token"))
自动化测试配置
以下是使用我们定义的ERNIE-Speed-8K模型来做一次测试, 生成测试集文件promptfooconfig.yaml如下,和ERNIE-Speed-8K.py脚本在同一目录下。
description: "Qianfan Test"
env:
# 定义千帆环境变量
QIANFAN_ACCESS_KEY: "***"
QIANFAN_SECRET_KEY: "***"
prompts:
- |-
请给出{{topic}}中英文对照,以json格式输出,如: {"Monday": "星期一", "Tuestday": "星期二"}
providers:
- id: 'python:ERNIE-Speed-8K.py'
label: ERNIE-Speed-8K
config:
pythonExecutable: /usr/local/bin/python3
tests:
- vars:
topic: 星期
assert:
- type: starts-with
value: '```json'
- vars:
topic: 月份
assert:
- type: starts-with
value: '```json'
执行promptfoo eval默认会执行promptfooconfig.yaml的配置,您可能使用-c参数来指定文件。
promptfoo eval
执行会显示执行进度和输出结果:
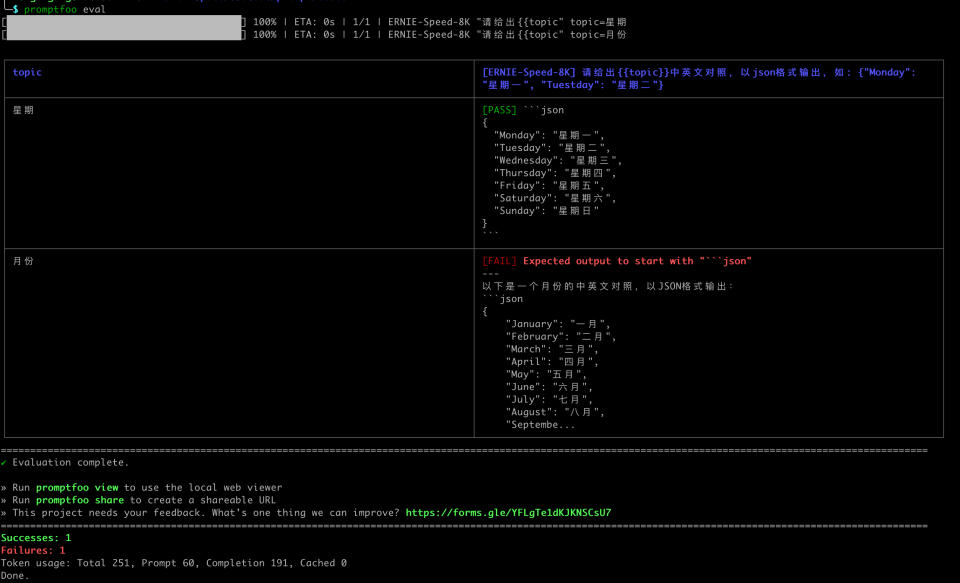
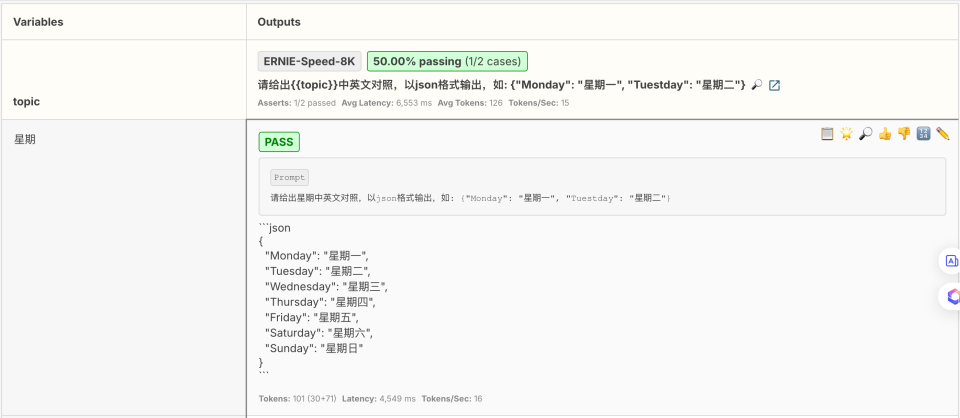
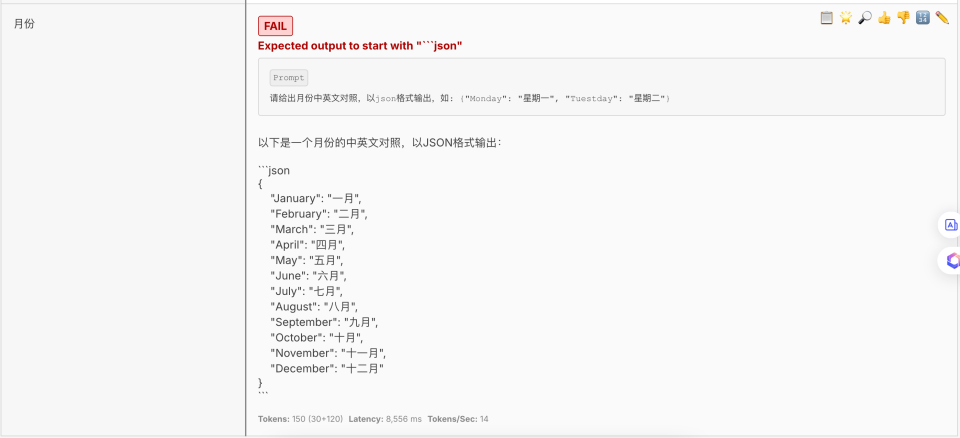
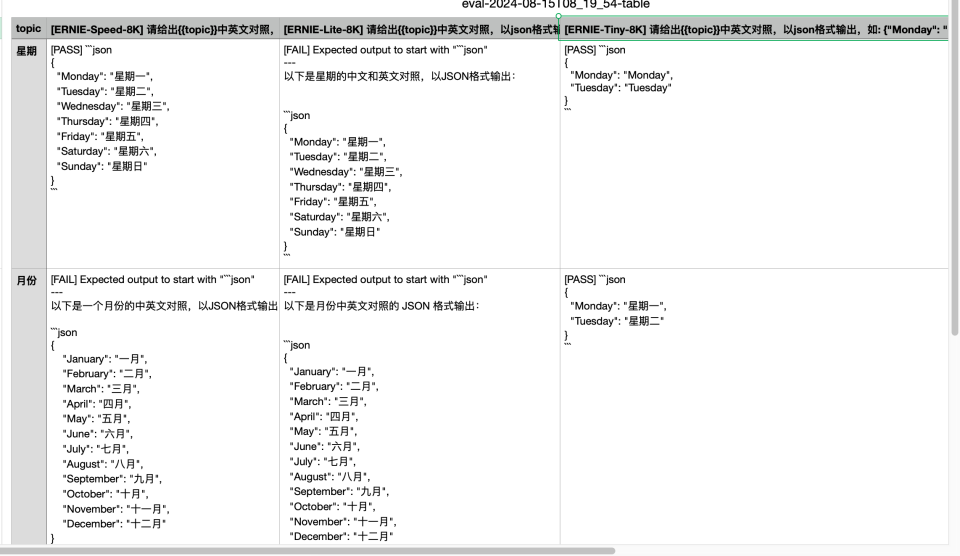
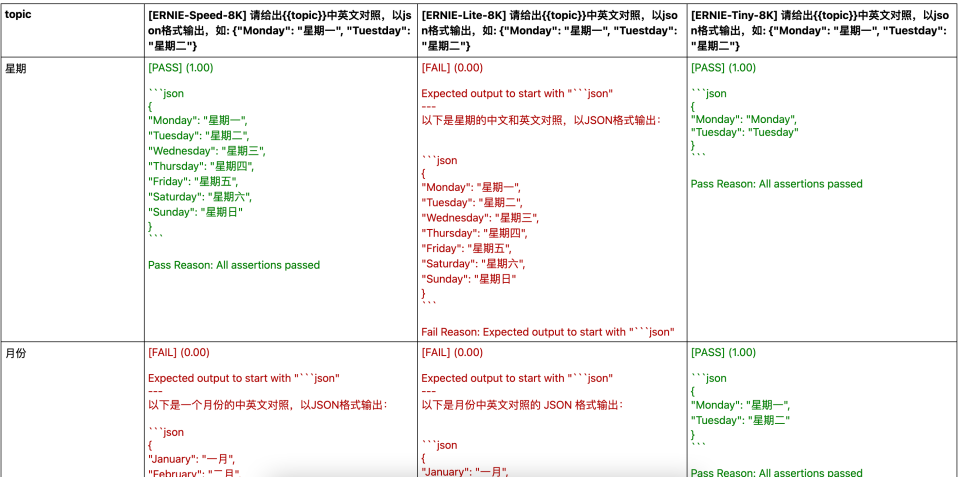
您可以通过浏览器查看,执行命令promptfoo view -y, 发现第二个用例,月份转换测试是失败的,原因是没有严格按照json格式输出,多了 “以下是一个月份的中英文对照,以JSON格式输出:” 这样的描述。
更多用法
多模型调用对比
对比前面ERNIE-Speed-8K 开发其他的模型或者使用内置模型。
providers:
- id: 'python:ERNIE-Speed-8K.py'
label: ERNIE-Speed-8K
config:
pythonExecutable: /usr/local/bin/python3
- id: 'python:ERNIE-Lite-8K.py'
label: ERNIE-Lite-8K
config:
pythonExecutable: /usr/local/bin/python3
- id: 'python:ERNIE-Tiny-8K.py'
label: ERNIE-Tiny-8K
config:
pythonExecutable: /usr/local/bin/python3
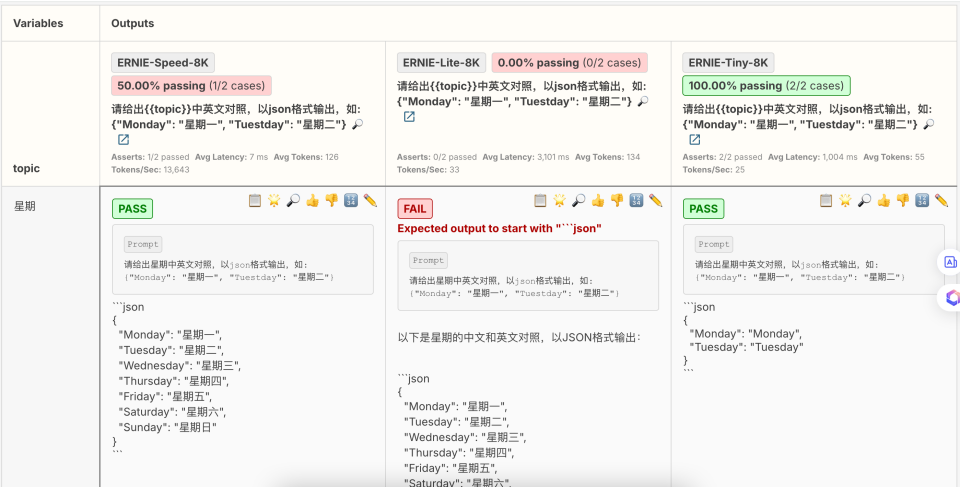
测试结果:
同时会还会每个模型调用测试用例数量,通过数量, 执行耗时,输入输出的tokens数量。
Asserts: 1/2 passed
Avg Latency: 7 ms
Avg Tokens: 126
Tokens/Sec: 13,643
模型结果导出
web界面导出
支持json,csv格式导出。
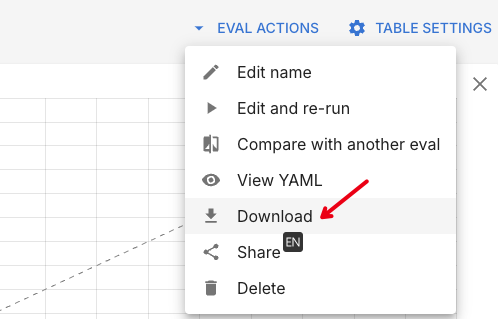

CSV格式展示:
命令执行时导出
promptfoo eval --output filepath.json
支持多种格式,包括 JSON, YAML, CSV, and HTML.
html格式导出展示:
控制台操作
控制台的能力比较弱,建议还是通过命令行来实现以下功能。 这里也简单介绍下控制台的使用
新建测试(New Eval)
顶部导航点选"New Eval",新建一个测试集。
可以手动编辑Providers,Prompts和Tests这三部分,同时支持导入文件实现批量编辑。
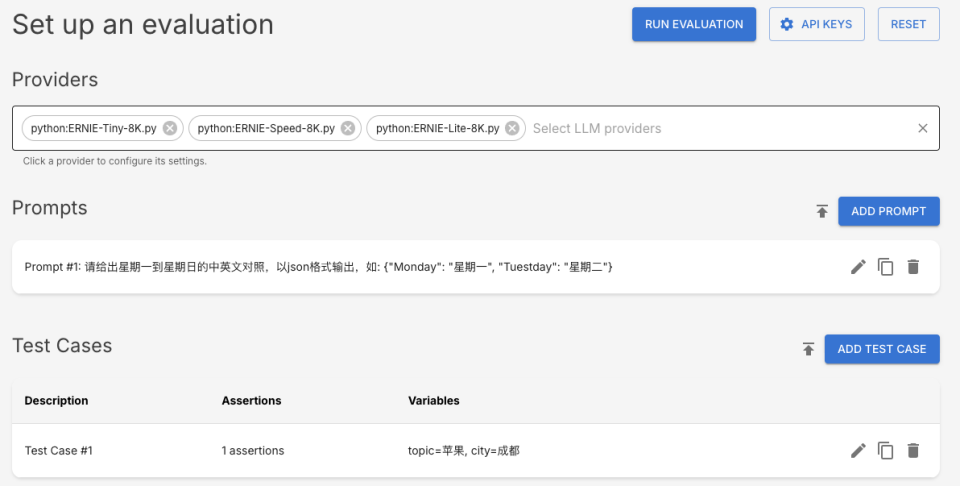
同时也可以直接在下面的Configuration中配置。
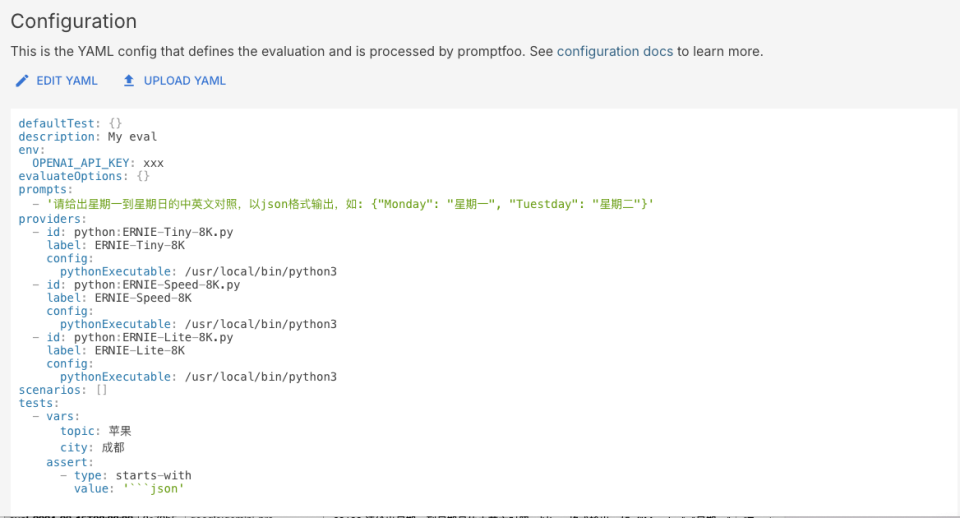
查看测试(Eval)
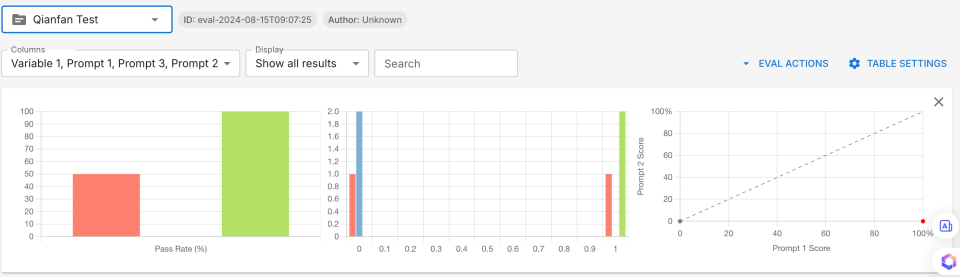
顶部导航点选"Eval",可以查看测试结果 ,这里记录了历史测试结果,可以通过下拉筛选查看。
第一部分对每个模型测试结果进行汇总,如每一列(模型)用例成功率。
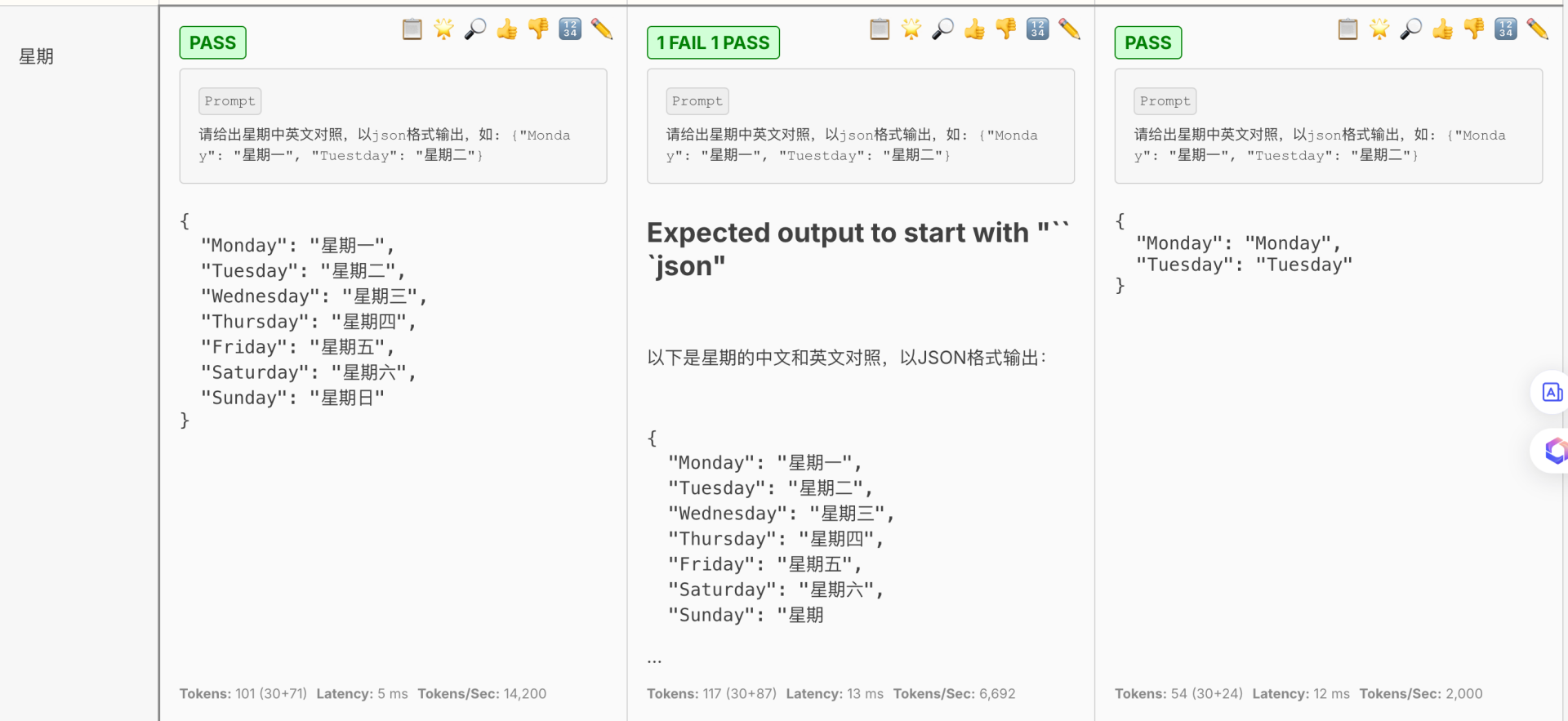
第二部分测试结果详情,包含了每个模型的用例成功数/总数,平均耗时,平均tokens数等,每个prompt用例执行情况,耗时,tokens计量等。

编辑测试并重新执行
选择一个"Eval", 点击编辑并重新运行。
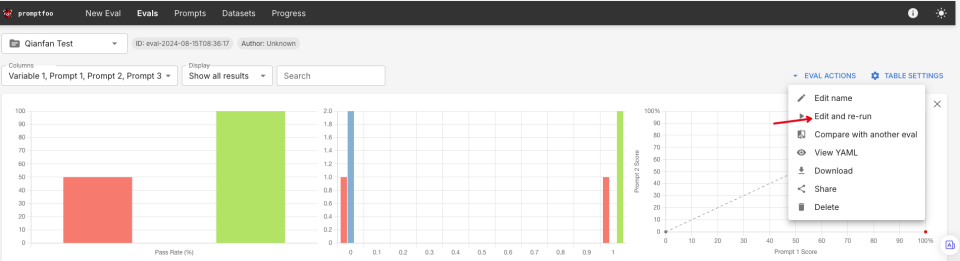
并可以对此次测试集的prompts,provider, tests进行修改,修改后再次执行。
提示词和测试用例导入
提示词和测试用例,新建或者重新编辑"Eval"时,都可以通过文件导入的方法实现批量上传。
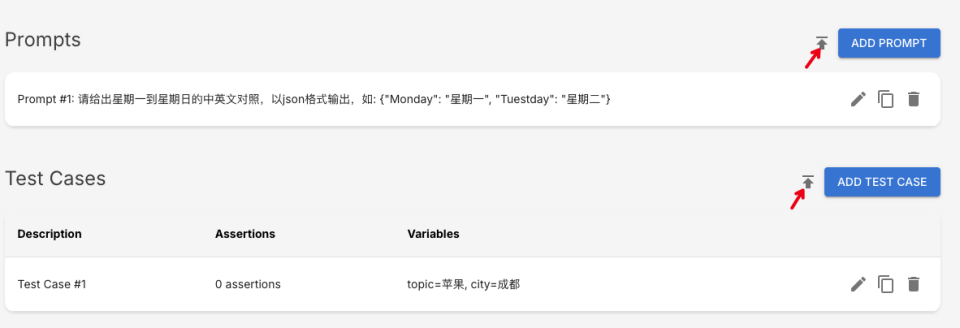
断言
通过增加断言assert来校验输出结果, 同时支持自定义脚本,如Python脚本来校验结果。
-
官方内置了很多断言类型,可以让我们对输出结果的格式,内容,执行耗时进行检查 ,同时支持webhook回调。
-
如果官方内置类型无法满足要求,也可以通过python,javascript脚本来自定义检查。
-
llm-rubric调用模型对输出结果进行评分。
环境变量配置
在控制台中,我们可以通过这里添加API KEYS配置,实际上也是环境变量的配置。

同样我们也可以在promptfooconfig.yaml中配置
description: My eval
env:
OPENAI_API_KEY: xxx
缓存配置
为了节省运行时间,对执行过的测试会进行缓存,如果promptfooconfig.yaml没有修改,则会直接读取缓存。
我们也可以不要缓存,在执行命令时增加参数:
promptfoo eval with --no-cache
也可以通过如下配置实现:
evaluateOptions:
showProgressBar: true # 显示执行进度
cache: false # 不缓存

















 2320
2320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









