







1.如有报错,大概率是Excel.Application的问题,Win+R查找dcomcnfg,如下

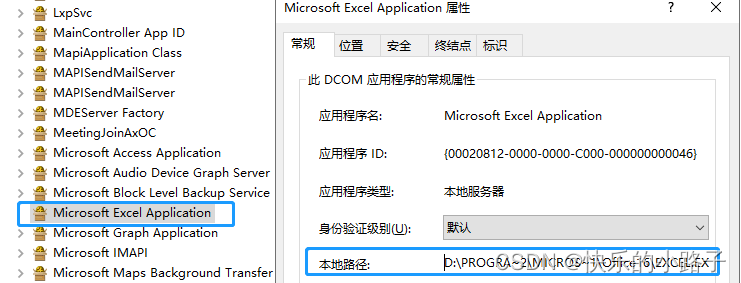
检查EXCEL.exe路径是否正确,如路径不对,此处不能修改路径,要去编辑注册表win+r输入regedit命令修改路径。修改方法:CTRL+F查找目标,修改为应用程序所在路径+\EXCEL.EXE /automation,再回到dcomcnfg查找路径正确即可。如仍不正确,本地可能安装多版本excel,路径需一致。如找不到Microsoft Excel Application,检查是否正确安装了office。
2.完整代码如下:
import os
import pandas as pd
import win32com.client
import openpyxl
import xlsxwriter
import datetime
from 转换pdf import PDFConverter
nowday = datetime.datetime.now().strftime("%m-%d")
def fenzu():
filename = "原表.xlsx" # 取用要拆分的表
filepath = "D:\\python代码\\批量插图\\" + filename # 源文件
file = pd.read_excel(filepath, sheet_name='2022') # 取用要拆分表格中的目标sheet
i = 1
for name, group in file.groupby("子类"): # 分组2
print(i, name, group['大类'].iloc[0]) # 分组1
i=i+1
namefile = group['大类'].iloc[0] + '-' + name + '-' + '款销售情况' # 以分组1命名文件
group['图片'] = '' # 增加想要添加的列(本文以执行插图宏文件为例子)
data = group[['排名', '子类', '供应商', '吊牌价', '买手', '款销量', '款式编号', '图片', '色名', '尺码', '订货', '销量', '余量']] # 选取要展示的字段
filename = "D:\\python代码\\批量插图\\拆分\\" + namefile + ".xlsx" # 命名分组后的excel表群
# 如不存在路径可创建
if not os.path.exists("D:\\python代码\\批量插图\\拆分\\"):
os.makedirs("D:\\python代码\\批量插图\\拆分\\")
# 以下为修改分组后的表群格式代码
writer = pd.ExcelWriter(filename, engine='xlsxwriter')
data.to_excel(writer, sheet_name='Sheet1', index=False) # 导入writer
workbook = writer.book # 提取workbook对象
worksheet = writer.sheets['Sheet1'] # 添加工作表
worksheet.set_default_row(73) # 设置所有行高
header_format = workbook.add_format({
'text_wrap': True, # 是否自动换行
'valign': 'vcenter', # 垂直对齐方式
'align': 'center', # 水平对齐方式
'border': 1,
# 'bold': True, # 字体加粗
# 'fg_color': '#D7E4BC', # 单元格背景颜色
}) # 设置格式1
head_format = workbook.add_format({
'text_wrap': True, # 是否自动换行
'valign': 'vcenter', # 垂直对齐方式
'align': 'center', # 水平对齐方式
'bold': True, # 字体加粗
'fg_color': '#D7E4BC', # 单元格背景颜色
'border': 1,
}) # 设置格式2
worksheet.set_row(0, 20, cell_format=header_format) # 设置第一行表头行高
worksheet.set_column("A:M", 3, header_format) # 设置所有列宽
worksheet.set_column("A:A", 3, header_format) # 设置特殊列列宽
worksheet.set_column("B:B", 6, header_format) # 设置特殊列列宽
worksheet.set_column("C:C", 6, header_format) # 设置特殊列列宽
worksheet.set_column("D:D", 6, header_format) # 设置特殊列列宽
worksheet.set_column("E:E", 5, header_format) # 设置特殊列列宽
worksheet.set_column("F:F", 6, header_format) # 设置特殊列列宽
worksheet.set_column("G:G", 10, header_format) # 设置特殊列列宽
worksheet.set_column("H:H", 10, header_format) # 设置特殊列列宽
worksheet.set_column("I:I", 5, header_format) # 设置特殊列列宽
worksheet.set_column("J:J", 5, header_format) # 设置特殊列列宽
worksheet.set_column("K:K", 5, header_format) # 设置特殊列列宽
worksheet.set_column("L:L", 5, header_format) # 设置特殊列列宽
worksheet.set_column("M:M", 5, header_format) # 设置特殊列列宽
writer.save()
writer.close()
# break
def useVBA(file_name):
xlApp = win32com.client.DispatchEx("Excel.Application")
xlApp.Visible = True
xlApp.DisplayAlerts = 0
file_path = file_name
xlBook = xlApp.Workbooks.Open(os.path.abspath(file_path), False)
xlBook.Application.Run("'D:\\python代码\\批量插图\\插入图片.xlsm'!CreateNewMacros.插入图片") # 执行宏文件插入图片
xlBook.Close(True)
xlApp.Quit()
def get_all_excel(dir):
file_list = []
for root_dir, sub_dir, files in os.walk(r'' + dir):
# 对文件列表中的每一个文件进行处理,如果文件名字是以‘xlxs’结尾就认定为是一个excel文件,当然这里还可以用其他手段判断,比如你的excel文件名中均包含'res',那么if条件可以改写为
for file in files:
# if file.endswith('.xlsx') and 'res' in file:
if file.endswith('.xlsx'):
# 要获取文件路径,如要把D:/myExcel 和res.xlsx拼接为D:/myExcel/res.xlsx
file_name = os.path.join(root_dir, file)
useVBA(file_name)
pdfConverter = PDFConverter(file_name) # 也支持单个文件的转换
pdfConverter.run_conver()
file_list.append(file_name) # 把拼接好的文件目录信息添加到列表中
# break
# return file_list
if __name__ == '__main__':
fenzu()
dirpath = "D:\\python代码\\批量插图\\拆分\\" # 存放拆分后的excel表群
get_all_excel(dirpath)
print("输出成功!")














 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









