






用完这个工具,你会发现,根本不用像python一样模拟登陆,敲一大堆代码,平均获取一页数据在1.5秒左右,简单轻松上手。
第一步 安装Web Scraper、注册Web Scraper账号和Dropbox账号
Web Scraper是一个chrome插件,网上自行下载,csdn人都会,安装完会跳转页面,顺着页面注册账号即可,然后想要导出的话得链接Dropbox账号,up主5分钟就搞定了,这里就不多赘述咯
第二步 打开想要爬取的微博网站,直接开爬
这里有个小细节,如果你是在网页打开电脑端的微博如Sina Visitor Systemhttps://weibo.com/,网页内容极其复杂,估计很难爬,但是如果你打开的是移动版的网页如微博,一切就变得简单了。
1. 找到想爬取评论的网站后,打开F12调试器,点击Web Scraper —— Create new sitemap ——Create Sitemap
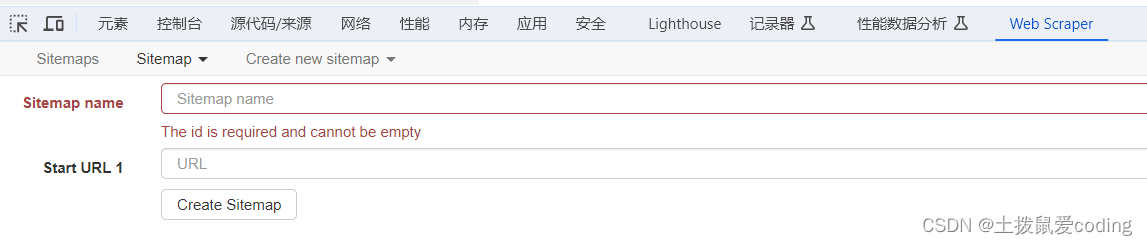
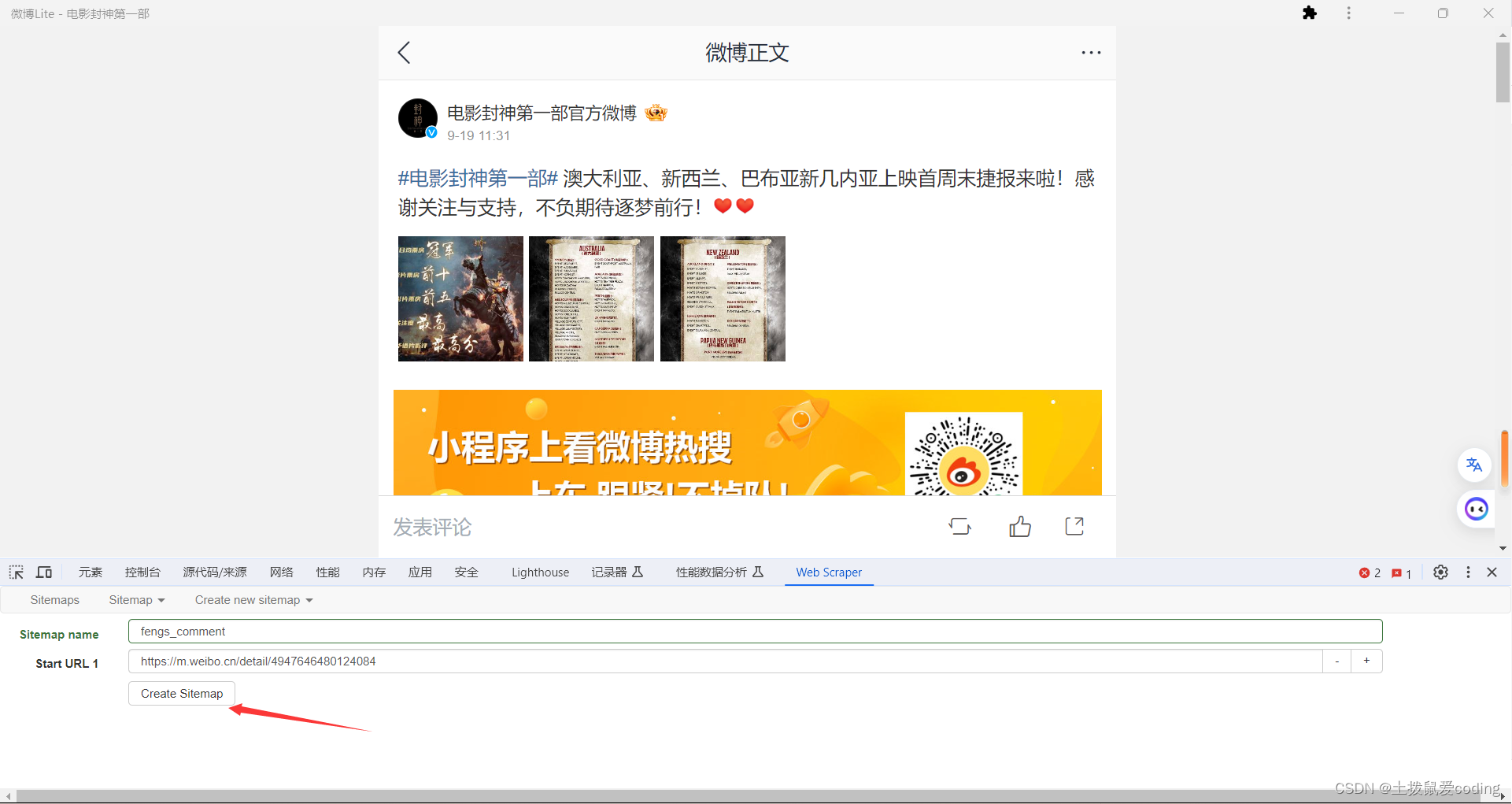
其中,Sitemap name名称是项目名称,英文随意取,Start URL就是想要爬取的网站的URL,输入完点击Create Sitemap
2. 点击Add new selector
其中Id是你想给该行为取的名称或者所爬取的内容的名称,也是英文,Type的话选择Element Scroll down(也就是向下滚动,如果没有该动作,你只能爬取少量几个数据,加了该动作,它会自动往下滚动到底部才会停止,然后同时爬取所有加载的你选中的内容。)
必须勾选Multiple,因为字样才会批量爬取,一切就绪后点击select进行内容的勾选。
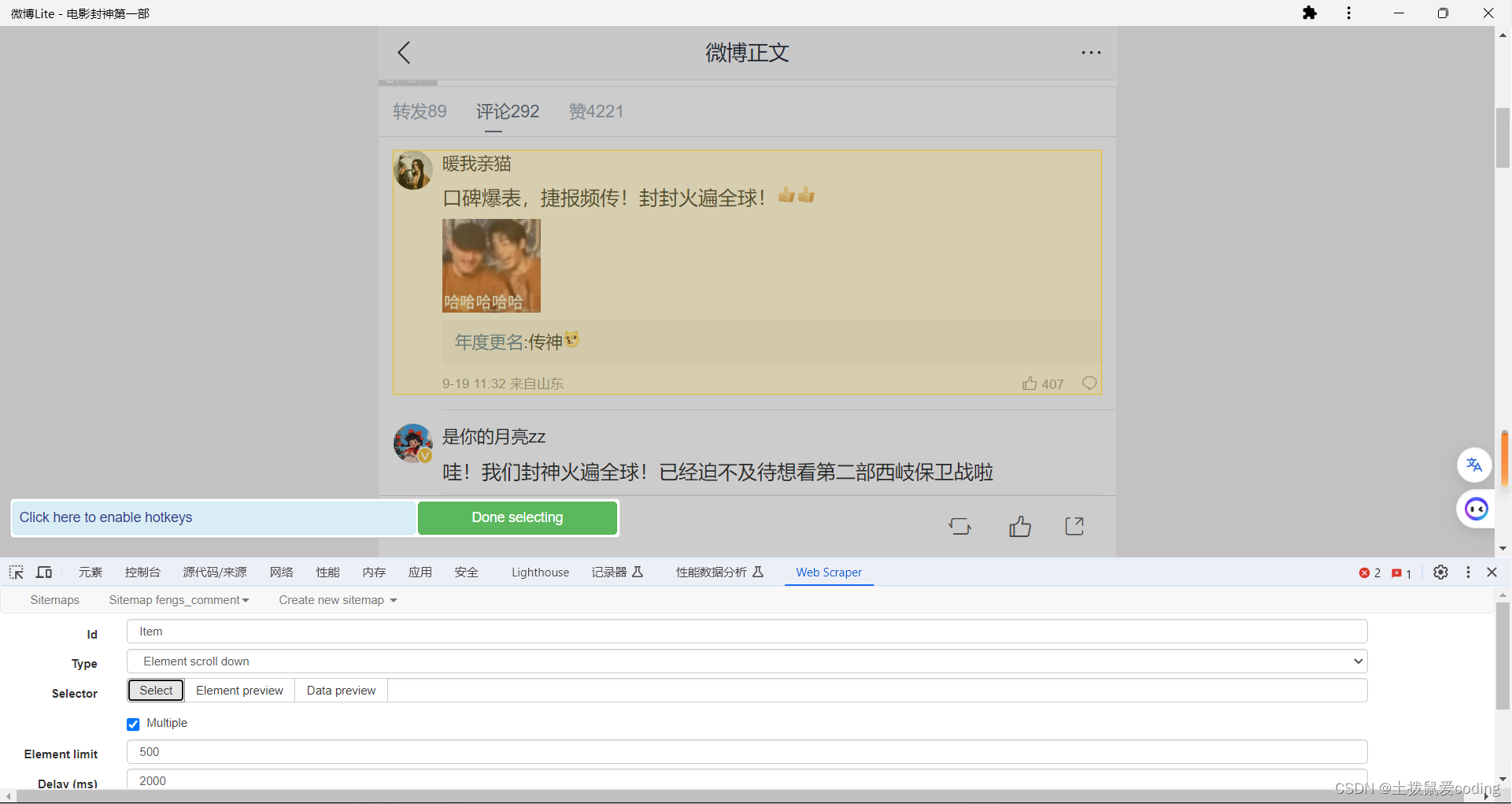
像我这样选中整个评论的框,点击它,然后再点下一个,你会发现匹配上了,然后点绿色的Done selecting
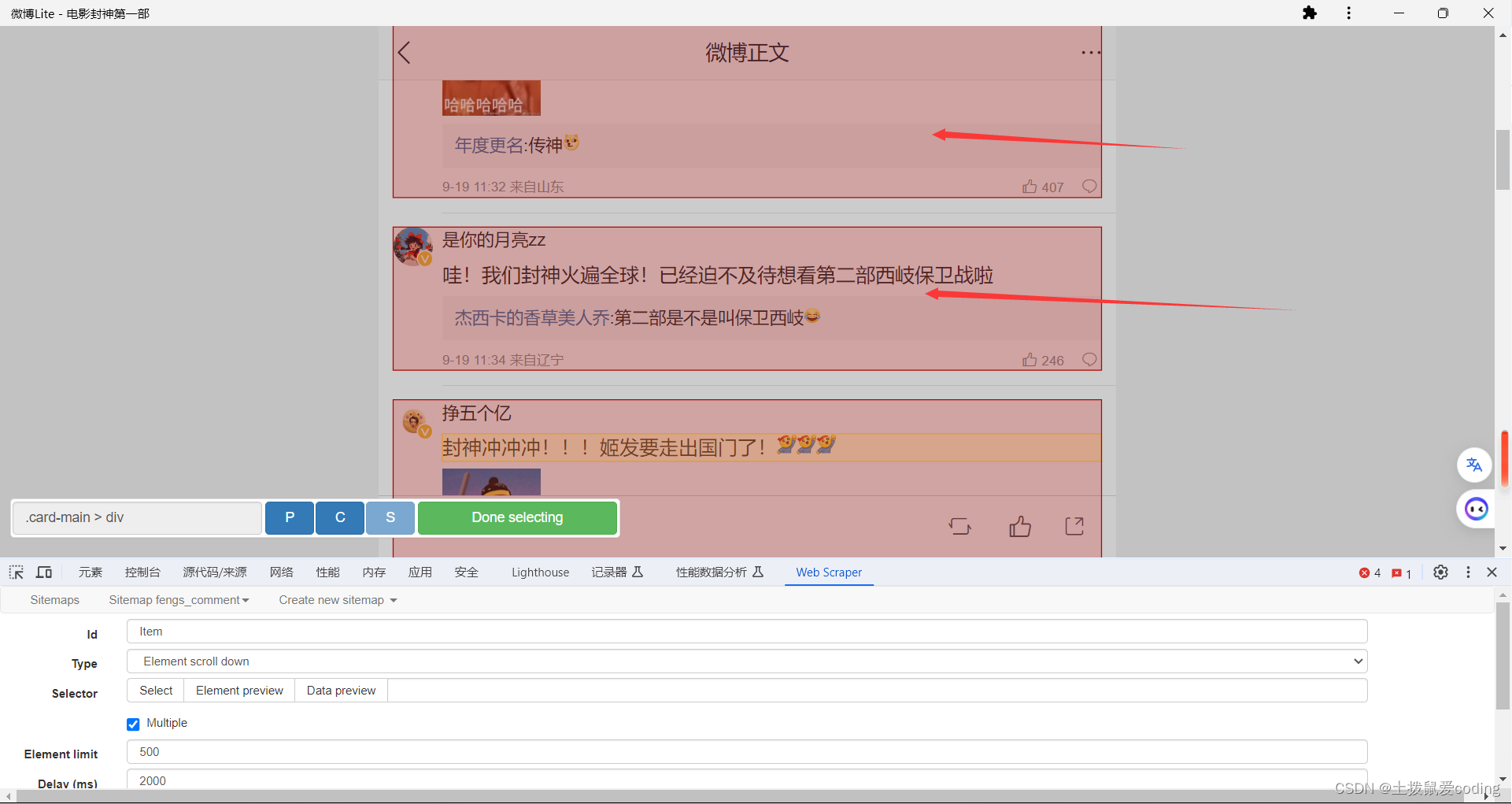
然后点保存
3. 点进我们的这个选择器,现在开始给数据分类了,例如名称,评论内容,评论时间等。
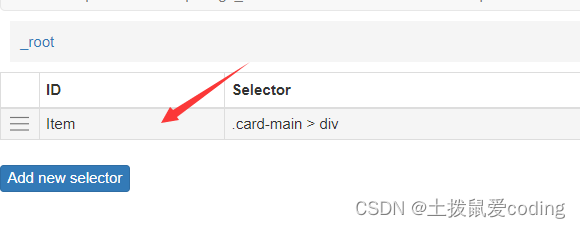
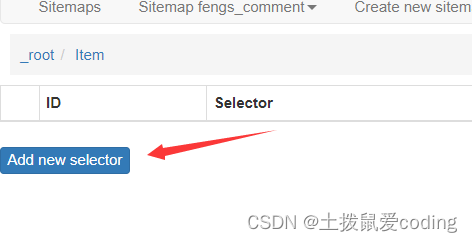
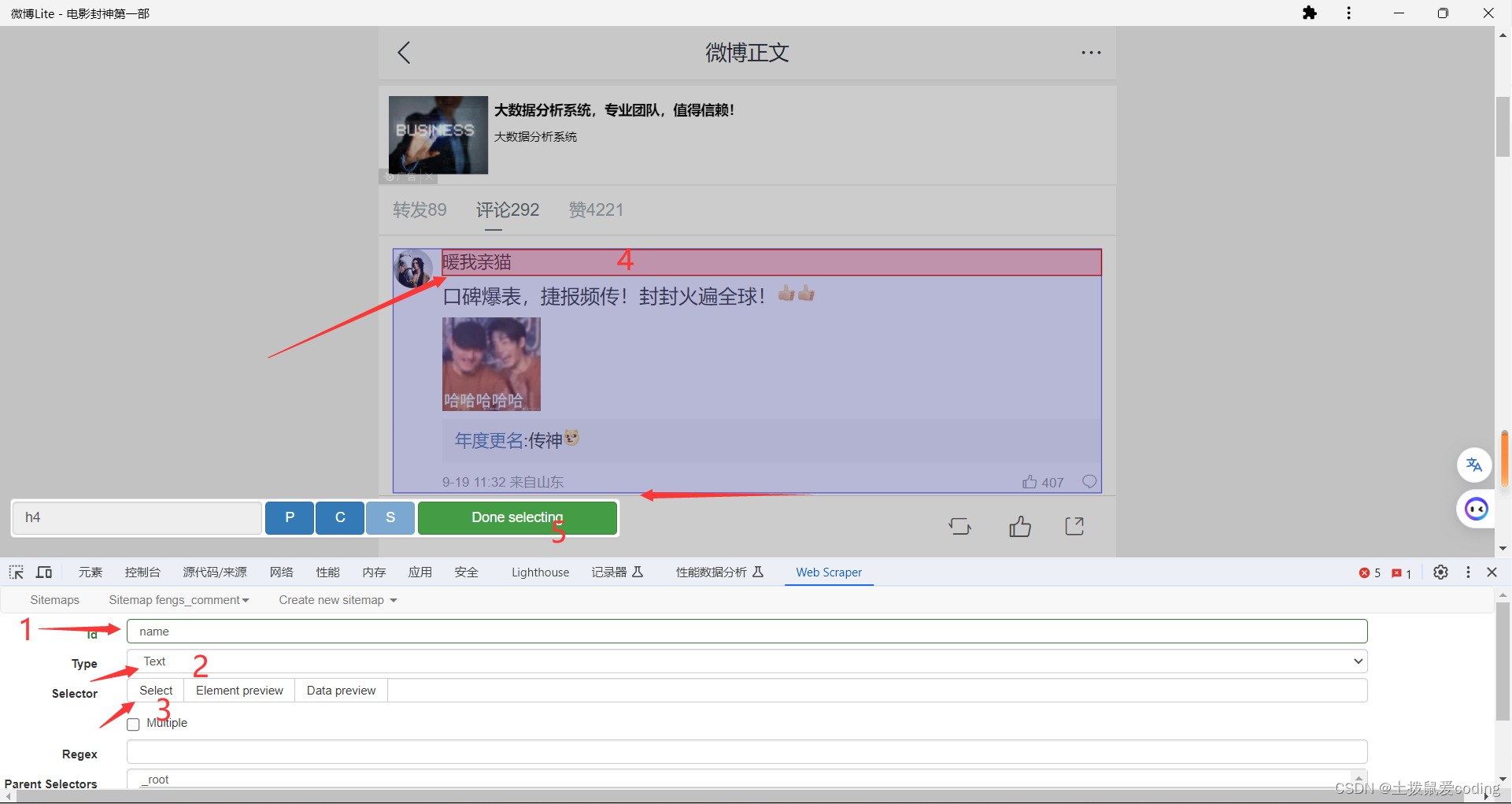
记得父级Item,默认的是对的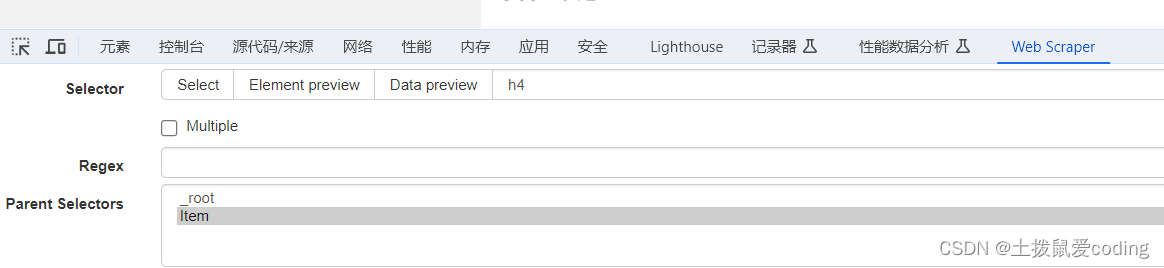
同样保存,这个数据就归类好了,接下来文本哪,时间哪也都是这个操作。
做完如图:可以点击Data view看一下数据对不(强烈建议全部做完再点,因为这样它会开始爬取)
4. 回到根目录开始爬取,点Start scraping就可以开始爬取了,建议爬大型网站时不赶时间的话改为5000毫秒 ,防拉黑
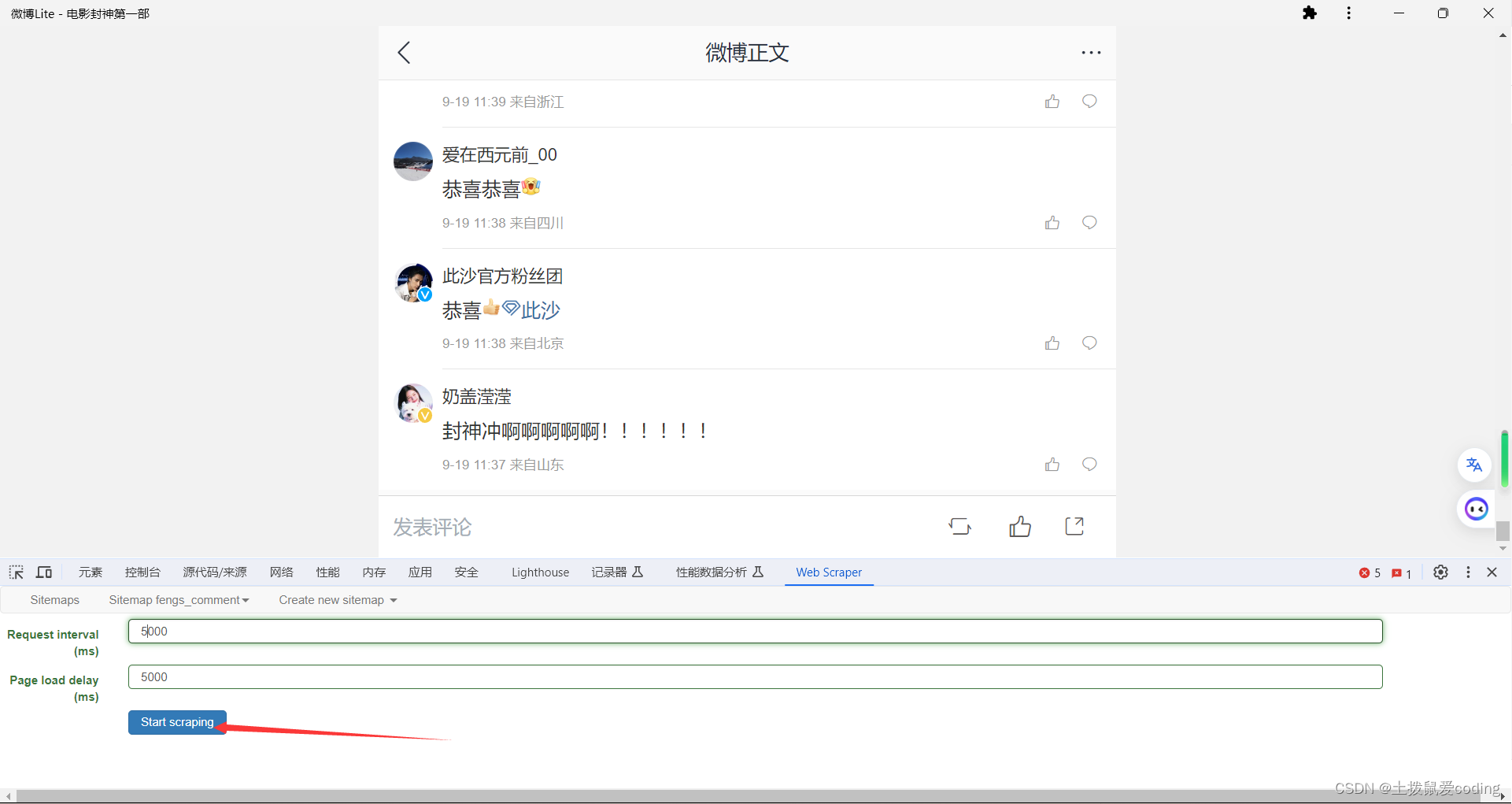
爬取完成后点refresh就可以看了


5. 导出


效果如图: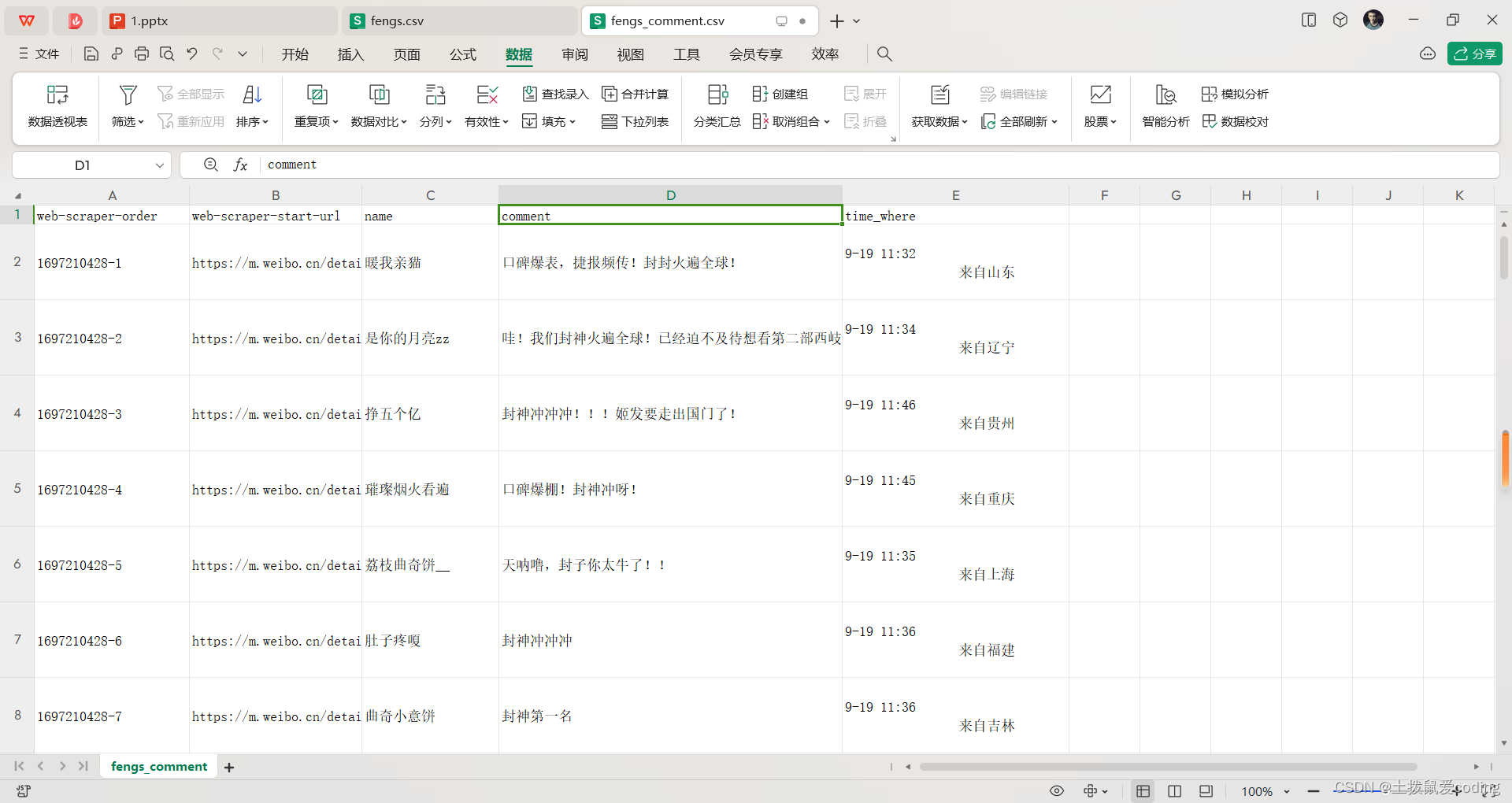
好了,以上就是全部内容了,感谢观看!!!

















 1837
1837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









