






使用jetson nano 4G 版本安装ollama,GPU版本的Qwen3教程
- 由于jtson nano 4g版本不能够使用官方的ollama进行GPU推理,会使用cpu,太慢了
- 使用别人编译好的llama.cpp运行,不用安装任何的环境!!! 先上结果
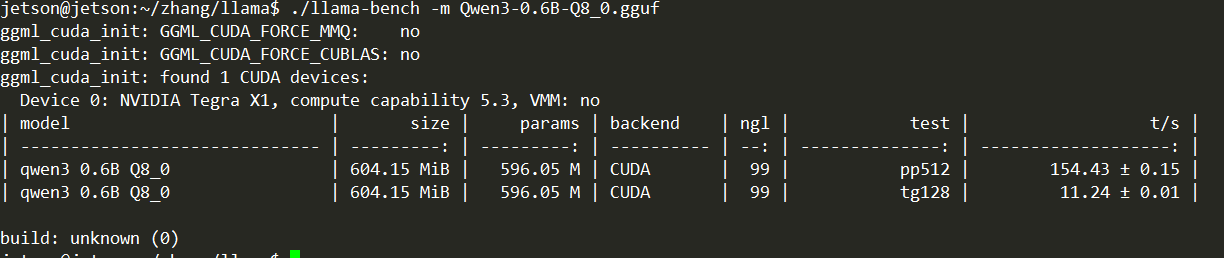
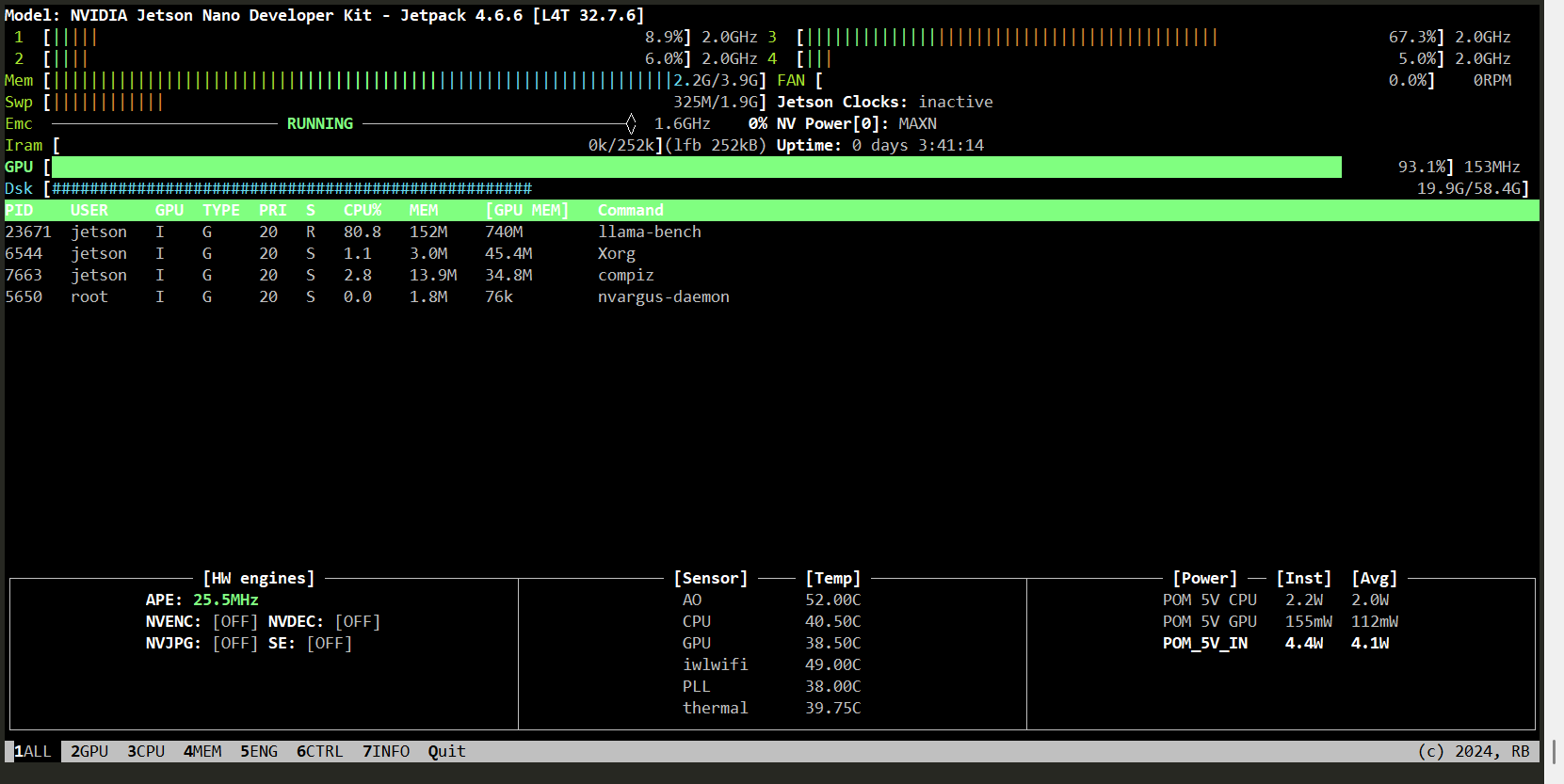
可以看到GPU的利用率非常高,速度也还可以,系统是超频之后的,应该有一点的关系
历史分界线,下面是比较折腾的方法,感兴趣的可以看看
- 使用docker 可以安装其他镜像进行推理,流程如何
安装jetson-containers
- 命令
cd /opt/
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
装完之后目前还是无法使用gpu版本的ollama
需要安装一个镜像
cd jetson-containers
sudo ./run.sh dustynv/ros:humble-desktop-l4t-r35.3.1
# 这个是安装完成之后的样子,会进入一个容器之中,可能需要科学上网
# Digest: sha256:08eafdabc4d3d9ed6395bef3fd9b12636b10258a6c2968a68eb1e611acddde5b
# Status: Downloaded newer image for dustynv/ros:humble-desktop-l4t-r35.3.1
# sourcing /opt/ros/humble/install/setup.bash
# ROS_DISTRO humble
# ROS_ROOT /opt/ros/humble
然后就会进行一个容器之中,
安装ollama
curl -fsSL https://ollama.com/install.sh | sh
# 后台运行ollama
nohup ollama serve &
ollama run llama3.2:1b

ollama run --verbose deepseek-r1:1.5b
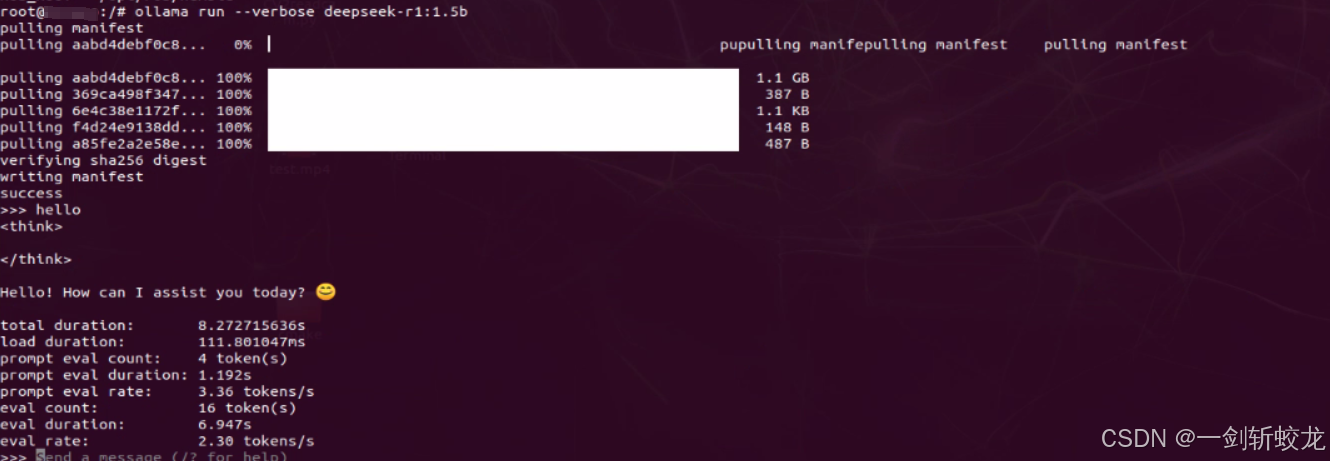
- 在jtop中可以看到gpu已经在使用了,但是速度比较慢,只能运行小模型


















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









