







排序和查找算法
2、排序+查找算法
//常见的排序算法(快排、冒泡、选择、插入等)的实现思路
//手写冒泡、快排的代码
//了解各个排序算法的特性,比如时间复杂度、是否稳定
2.1 二分查找
前提条件:有序的折半查找
-
有序
-
求numbs的中间值
-
比较它和target的大小,来确定查询范围
-
以此循环
1.编写二分查找的代码 1.前提条件:有已排好序的数组A 2.定义左边界Left,有边界Right,确定搜索的范围,循环执行3,4两步 3.获取中间索引的m=Floor(Left+Right)/2 4.中间索引的值A[m]与待搜索的target进行比较 a.A[m]==target,返回中间索引 b.A[m]>target,中间值得右侧都大于target,无需比较,中间索引左边去找,将m-1设置为右边界 c.A[m]<target,中间值的左侧都小于target,无需比较,中间的索引的右边去找,将m+1设置为左边界,重新查找 5.当left>right的时候,表示没有找到,应结束循环 return -1; 6.如果m整数过大 会存在整数溢出的问题
2.2 冒泡排序
//冒泡排序的原理
//内循环:使用相邻的指针,j、j+1,从左至右遍历,依次比较相邻元素的大小,若左元素大于右元素则将它们交换;遍历完成的时候,最大的元素会被交换至数组的最右边。
//外循环:不断重复内循环,每轮将最大元素交换至 剩余未排序数组最右边 直至所有元素都被交换至正确的时结束。
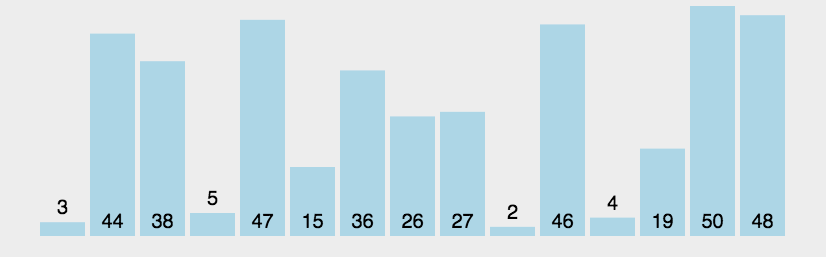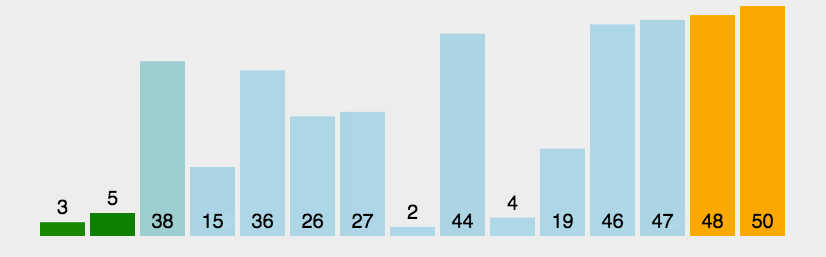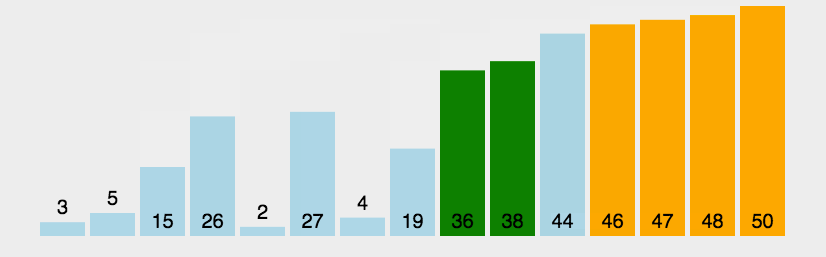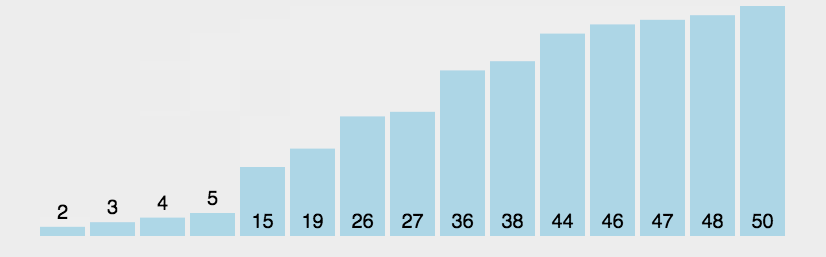
//冒泡排序
package com.uin.sort;
import java.util.Arrays;
/**
* @author wanglufei
* @description: TODO
* @date 2021/11/24/4:30 下午
*/
public class BubbleSort {
public static void main(String[] args) {
int[] a = {5, 9, 7, 4, 1, 3, 2, 8};
// int[] a = {1, 2, 3, 4, 5, 7, 8, 9};
// bubble(a);
bubble_2(a);
}
//优化方式:每轮冒泡排序,记录最后一次交换索引可以作为下一轮冒泡的比较次数,如果这个值为零,表示整个数组有序,直接退出
//外层循环即可。
public static void bubble_v2(int[] a) {
int n = a.length - 1;//交换的次数
while (true) {
int last = 0;//最后一次交换的索引
for (int i = 0; i < n; i++) {
System.out.println("比较次数" + i);
if (a[i] > a[i + 1]) {
swap(a, i, i + 1);
last = i;
}
}
n = last;
System.out.println("排序" + Arrays.toString(a));
if (n == 0) {
break;
}
}
}
public static void bubble(int[] a) {
for (int j = 0; j < a.length - 1; j++) {
// for (int i = 0; i < a.length - 1; i++) {
/**
* 改进冒泡的次数
*/
boolean swapped = false;//是否发生了交换
for (int i = 0; i < a.length - 1 - j; i++) {//减少内存循环的次数
System.out.println("比较次数" + i);
if (a[i] > a[i + 1]) {
swap(a, i, i + 1);
swapped = true;
}
}
System.out.println("第" + j + "轮冒泡" + Arrays.toString(a));
if (!swapped) {
break;
}
}
}
public static void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
//实现二
package com.uin.sort;
import java.util.Arrays;
/**
* @author wanglufei
* 冒泡排序的第二种理解
* @description: TODO
* @date 2021/12/5/2:30 PM
*/
public class bubbsort {
public void bubblesort(int[] array) {
//3.控制循环的轮次
for (int i = 0; i < array.length - 1 - 1; i++) {//比较的轮次是m个元素比较m-1次
//2.控制j向前移动
for (int j = 0; j + 1 <= array.length - 1 - i; j++) {//减去i是为了减少最后面已经排好序的元素的比较次数
//1.交换相邻元素
if (array[j] > array[j + 1]) {
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
}
public static void main(String[] args) {
int[] array = new int[]{7, 0, 1, 9, 2, 6, 3, 8, 5, 4};
bubbsort bs = new bubbsort();
bs.bubblesort(array);
System.out.println(Arrays.toString(array));
}
}
平均时间复杂度:O(n²)
空间复杂度:O(1)
算法稳定性:稳定
2.3 选择排序
选择排序的原理与冒泡排序相比更加容易理解:选定一个标准位,将待排序序列中的元素与标准位元素逐一比较,反序则互换。其中所谓的标准位实际上是数组中的一个下标位,在选定了这个下标位之后,在一轮排序中这个标准位将不再移动。
然后将待排序序列–也就是这个标准位之后的所有元素组成的序列----中的元素逐个和标准位进行比较
如果某一个待排序序列上的值比标准位上的值更小(升序排序)或者更大(降序排序),那么就将这个元素和标准位上的元素进行互换。
文字描述:
1.将数组分为两个子集,排序的和未排序的,每一轮从未排序的子集中选出最小的元素,放入排序子集。
2.重复以上步骤,知道整个数组有序。
//{5, 3, 7, 2, 1, 9, 8, 4}
i j
//3,5,7,2,1,9,8,4
//3,5,7,2,1,9,8,4
//3,5,2,7,1,9,8,4
//3,5,2,1,7,9,8,4
//3,5,1,7,8,9,4
//3,5,1,7,8,4,9
//.....
//
package com.uin.sort;
import java.util.Arrays;
/**
* @author wanglufei
* 选择排序
* @description: TODO
* @date 2021/11/24/6:40 下午
*/
public class SelectionSort {
public static void main(String[] args) {
int[] a = {5, 3, 7, 2, 1, 9, 8, 4};
selection(a);
}
public static void selection(int[] a) {
//优化方式:为减少交换次数,每一轮可以先找到最小的索引,在每轮最后在交换元素
for (int i = 0; i < a.length - 1; i++) {//i 代表每轮选择最小元素要交换的最小索引
int s = i;//代表最小元素的索引 初始值 索引为0的值
for (int j = s + 1; j < a.length; j++) {
if (a[s] > a[j]) {
s = j;
}
}
if (s != i) {
swap(a, s, i);
}
System.out.println(Arrays.toString(a));
}
}
public static void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
//选择排序的第二种实现
第0轮排序
3 1 9 2 8 a[i]<a[j] 不换 a[i]>a[j] 换
i j
3 1 9 2 8
i j
2 1 9 3 8
i j
2 1 9 3 8
i j
1 2 9 3 8
ij 当ij相遇的时候一轮选择排序就已经结束
第1轮排序
1 2 9 3 8
i j
1 2 9 3 8
i j
1 2 9 3 8
i j
1 2 9 3 8
ij 当ij相遇的时候一轮选择排序就已经结束
第2轮排序
1 2 9 3 8 a[i]>a[j] 换
i j
1 2 8 3 9
i j
1 2 8 3 9 a[i]>a[j] 换
i j
1 2 3 8 9
ij 当ij相遇的时候一轮选择排序就已经结束
第3轮选择排序
1 2 3 8 9 //当剩余一个元素的时候 记住一句话 元素自己和自己排序 永远都是自己有序的
i j
//代码实现
package com.uin.sort.选择排序;
import com.uin.sort.冒泡.bubbsort;
import java.util.Arrays;
/**
* @author wanglufei
* 选择排序的第二种实现
* @description: TODO
* @date 2021/12/5/3:21 PM
*/
public class selectsort {
public void selesort(int[] array) {
//3.来控制标准位下标i的移动 i最远移动到数组下标的倒数第二位
for (int i = 0; i < array.length - 1 - 1; i++) {
//2.创建一个循环,来控制下标j对应的元素的移动
for (int j = array.length - 1; j > i; j--) {
//1.将标准位的元素与小标为j对应的元素进行比较,反序则互换
if (array[i] < array[j]) {//将序排序 要升的话 改符号
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
}
}
}
public static void main(String[] args) {
int[] array = new int[]{7, 0, 1, 9, 2, 6, 3, 8, 5, 4};
selectsort ss = new selectsort();
ss.selesort(array);
System.out.println(Arrays.toString(array));
}
}
2.4 冒泡排序和选择排序的比较
//1.二者平均时间复杂度都是O(n*2)
//2.选择排序一般要快于冒泡,因为其交换次数少
//3.但如果集合有序度高,冒泡优于选择
//4.冒泡属于稳定排序算法,而选择属于不稳定排序
面试题10.01 合并排序的数组
//给定两个排序后的数组 A 和 B,其中 A 的末端有足够的缓冲空间容纳 B。 编写一个方法,将 B 合并入 A 并排序。
//
// 初始化 A 和 B 的元素数量分别为 m 和 n。
//
// 示例:
//
// 输入:
//A = [1,2,3,0,0,0], m = 3
//B = [2,5,6], n = 3
//
//输出: [1,2,2,3,5,6]
//
// 说明:
//
//
// A.length == n + m
//
// Related Topics 数组 双指针 排序 👍 122 👎 0
package com.uin.sort;
import java.util.Arrays;
/**
* @author wanglufei
* @description: TODO
* @date 2021/11/24/10:00 下午
*/
public class SortedArrayMerge {
public static void main(String[] args) {
int[] a = new int[]{1,3,4,5,7};
int[] b = new int[]{0,1,5,7,7,8,9};
SortedArrayMerge sam = new SortedArrayMerge();
int[] result=sam.sortedArrayMerge(a,b);
System.out.println(Arrays.toString(result));
}
public int[] sortedArrayMerge(int[] a, int[] b) {
//创建一个结果数组,结果数组的长度为两个有序数组的长度之和
int m=a.length;
int n=b.length;
int[] meragee = new int[m + n];
//创建指针i,j。分别用来遍历A和B
int i = 0;
int j = 0;
//创建指针k,用来控制结果数组的元素的下标
int k = 0;
//创建循环变量实现有序数组的合并的操作,在合并的过程中,比较A[i]和B[j]的大小,谁更小,谁就落在结数组
//中,并且,哪一个数组的元素的落在结果数组中之后,控制这个数组的指针就加+1
while (i < m && j < n) {
if (a[i] <= b[j]) {
meragee[k] = a[i];
i++;
} else {
meragee[k] =b[j];
j++;
}
k++;
}
//判断哪一个数组当中还有剩余的元素,就将这些剩余的元素直接 copy到结果数组当中
if (i < m) {
while (i < m) {
meragee[k] = a[i];
i++;
k++;
}
}
if (j < n) {
while (j < n) {
meragee[k] = b[j];
j++;
k++;
}
}
return meragee;
}
}
2.5 插入排序
一、文字描述:
1.将数组分为两个区域,排序区域和未排序区域,每一轮从未排序区域中取出第一个元素,插入到排序区域(需保证顺序)
2.重复以上步骤,直到整个数组有序
二、与选择排序的比较
1.二者的时间复杂度都是O(n^2)
2.大部分的情况下,插入都略于优于选择
3.有序集合插入的时间的复杂度为O(n)
4.插入属于稳定的排序的算法,二选择不属于稳定的排序
//插入
//2 3 4 1===>1 2 3 4
//插入的情况:t=1 为待插入的元素 1和4比较 发现4大 将4向后移一位 2 3 * 4
//j-- 继续比较 2 * 3 4
//继续比较 * 2 3 4
//将t插入
package com.uin.sort;
import java.util.Arrays;
/**
* @author wanglufei
* 插入排序的实现
* @description: TODO
* @date 2021/11/25/8:24 上午
*/
public class InsertSort {
public static void main(String[] args) {
int[] a = {9, 3, 7, 2, 5, 8, 1, 4};
insert(a);
}
public static void insert(int[] a) {
//i取1 是因为插入排序 假设是将数组分为待排序和已排序的两个部分
//索引为0 是默认已排序的元素
//实现插入的话 就要比较a[i]和a[i-1]的大小情况。
//那么i就代表待插入元素的索引
for (int i = 1; i < a.length; ++i) {
//用临时变量 来存储a[i]的值
int t = a[i];//代表待插入的元素的值
//代表a[i-1]的元素 比如a[i=1] 那么a[i-1=0]
//也就是比较a[1]和a[0]的大小 如果a[1]<a[0]
//就将a[1]插入到a[0]的前面(只移动a[j] 向前移还是向后1移)
//======前面的a[i-1]也就是a[j]=======
int j = i - 1;//代表已排序的元素索引
//比较大小的边界 就是a[0] 数组的头 就跳出循环
while (j >= 0) {
//如果a[j]大于t,说明要将a[j]向后移一位 一次循环 知道数组的头部 也就是j=0
if (t < a[j]) {
a[j + 1] = a[j];
//如果待插入的值大于已排序的值 那么就代表已经找到待插入元素的位置
} else {
//优化方式
//待插入元素进行比较,遇到比自己较小的元素,就代表找到了插入位置,无需进行后续的比较
//插入时可以直接移动元素,而不是交换元素
break;//减少循环,减少不必要比较的次数 优化
}
j--;
}
//将待插入的值 插入空位
a[j + 1] = t;
System.out.println(Arrays.toString(a));
}
}
}
第二种实现
第1轮排序
5 1 9 2 7 和第一个比较
i
1 5 9 2 7
第2轮排序
1 5 9 2 7 和前面的元素继续比较比较 发现9 比5大 就不用先后比较了
i
第3轮排序
1 5 9 2 7
i
1 5 2 9 7
1 2 5 9 7
第4轮排序
1 2 5 9 7
i
1 2 5 7 9
//代码实现
package com.uin.sort.插入排序;
import java.util.Arrays;
/**
* @author wanglufei
* @description: TODO
* @date 2021/12/5/3:41 PM
*/
public class inssort {
public void insertsort(int[] array) {
//1.创建一个循环用来控制抽牌的数量
for (int i = 1; i <= array.length - 1; i++) {
//2.创建循环,用来控制抽到的牌和之前的牌比较和交换
for (int j = i; j - 1 >= 0 && array[j] < array[j - 1]; j--) {
//3.执行交换的操作
int tmp = array[j];
array[j] = array[j - 1];
array[j - 1] = tmp;
}
}
}
public static void main(String[] args) {
int[] array = new int[]{7, 0, 1, 9, 2, 6, 3, 8, 5, 4};
inssort is = new inssort();
is.insertsort(array);
System.out.println(Arrays.toString(array));
}
}
2.6 希尔排序
是排序算法中第一个时间复杂度突破On^2的排序算法。
希尔排序的实际上是一种变形的插值排序算法。它将整个序列按照规定的步长(step)进行分部分取值,并将这些值进行插值排序
在一轮排序之后,再将步长折半,一次类推,当步长取值为1的时候,整个希尔排序也就退化成了一个单纯的插值排序。
在插入排序中,如果最大的元素在头部,那么就会增加移动次数,针对这种情况,希尔排序,对插入排序进行了改进。
间隙队列的选择
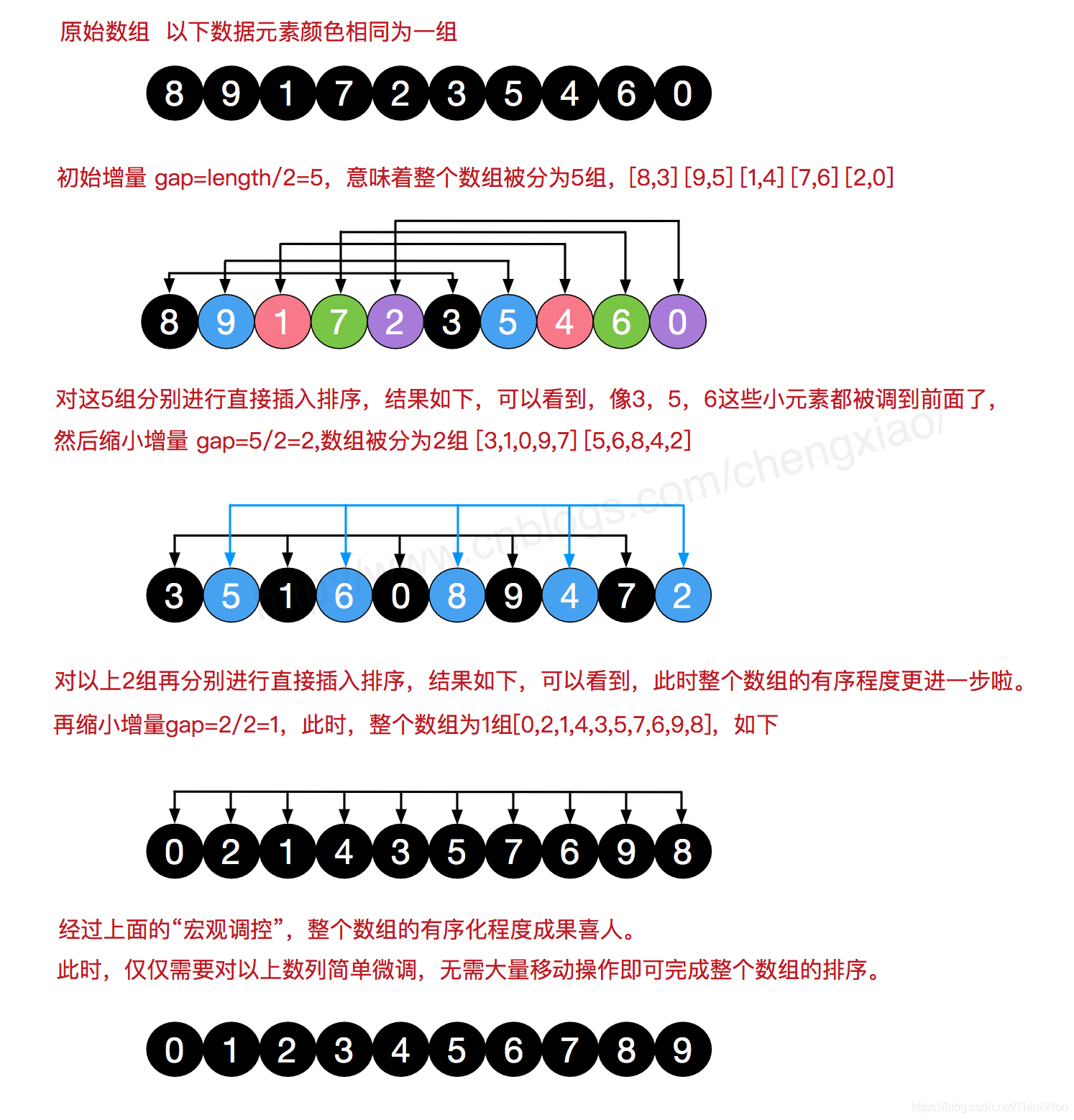
间隙相同的化为一组

public class ShellSort extends BaseSort {
public static void main(String[] args) {
ShellSort sort = new ShellSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
int length = nums.length;
int temp;
//步长
int gap = length / 2;
while (gap > 0) {
for (int i = gap; i < length; i++) {
temp = nums[i];
int preIndex = i - gap;
while (preIndex >= 0 && nums[preIndex] > temp) {
nums[preIndex + gap] = nums[preIndex];
preIndex -= gap;
}
nums[preIndex + gap] = temp;
}
gap /= 2;
}
}
}
//10万个数的数组,耗时:261毫秒
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OnaJweqO-1648693028237)(%E5%B8%8C%E5%B0%94%E6%8E%92%E5%BA%8F%E7%9A%84%E5%8E%9F%E7%90%86.png)]
//代码实现
package com.uin.sort.希尔排序;
import java.util.Arrays;
/**
* @author wanglufei
* @description: TODO
* @date 2021/12/5/8:04 PM
*/
public class shell {
//希尔排序内部使用的差值方法
private void insertsort(int[] a, int step, int start) {
//1.创建一个循环用来控制抽牌的数量
for (int i = start + step; i <= a.length - 1; i += step) {
//2.创建循环,用来控制抽到的牌和之前的牌比较和交换
for (int j = i; j - step >= 0 && a[j] < a[j - step]; j = j - step) {
//3.执行交换的操作
int tmp = a[j];
a[j] = a[j - step];
a[j - step] = tmp;
}
}
}
public void shellsort(int[] a) {
int step = a.length / 2;
//1.创建一个循环用来控制希尔排序中使用步长的变化
while (step >= 1) {//使用这个循环控制希尔排序的轮次
//2.创建一个循环,用来控制参与内部差值的元素的起点下标
for (int start = 0; start < step; start++) {
insertsort(a, step, start);
}
step = step / 2;
}
}
public static void main(String[] args) {
int[] a = new int[]{7, 0, 1, 9, 3, 8, 5, 4};
shell shell = new shell();
shell.shellsort(a);
System.out.println(Arrays.toString(a));
}
}
2.7 快速排序(DNC思想 分而治之思想)
文字描述:
1.每一轮排序选择一个基准点(pivot)进行分区(也就是在数组中选出一个元素,小于基准点放左边,大于的放右边)
1.让小于基准点的元素的进入一个分区,大于基准点的元素的进入另一个分区
2.当分区完成时,基准点元素的位置就是最终位置
2.在子分区内重复以上过程,直至**子分区的元素个数少于等于1**,这体现的是分而治之的思想(divide-and-conquer)
3.**发现基准点的位置就是它最终的位置**
4.在对基准点的左右边进行再分区 重复以上的过程 递归
分类:
1.单边循环快排(lomuto 洛穆托分区方案)
1.选择最右元素作为基准点的元素
2.j指针负责找到比基准点小的元素,一旦找到则与i进行交换
3.i指针维护小于基准点元素的边界,也是每次交换的目标索引
4.最后基准点与i交换,i即为分区位置
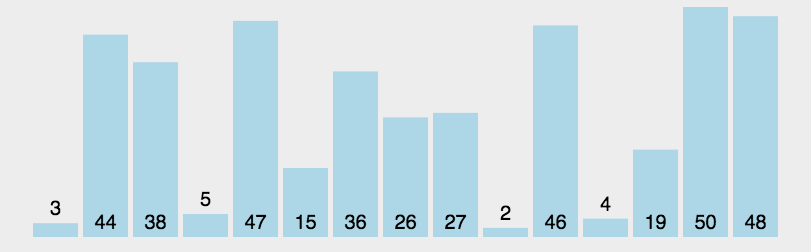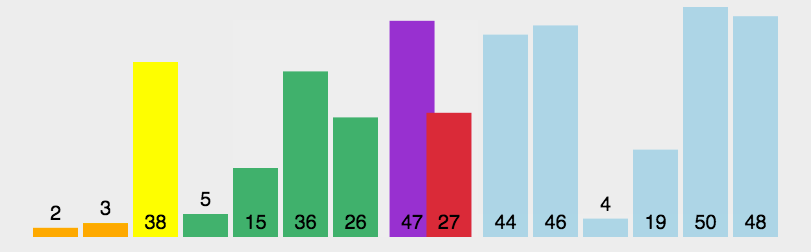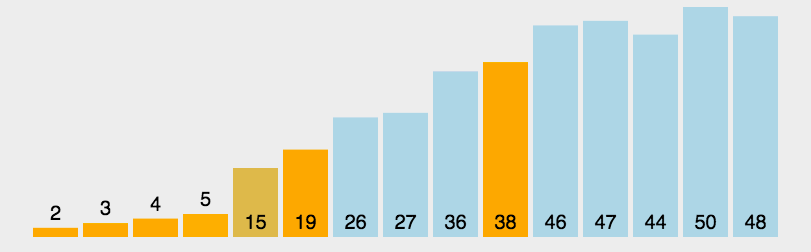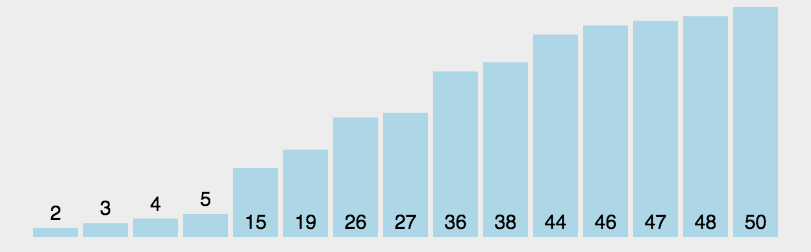
package com.uin.sort;
import java.util.Arrays;
import static com.sun.tools.javac.jvm.ByteCodes.swap;
import static com.uin.sort.SelectionSort.swap;
/**
* @author wanglufei
* 单边循环快排
* @description: TODO
* @date 2021/11/25/10:46 上午
*/
public class QuickSort_lomuto {
public static void main(String[] args) {
int[] a = {5, 3, 7, 2, 9, 8, 1, 4};
//l 上边界是0
//h 下边界 length-1 基准点元素
// partition(a, 0, a.length - 1);
//返回的基准点索引为3(int)就可以确定下一次 分区的边界
// {3 2 1 4 9 8 7 5}
quick(a, 0, a.length - 1);
}
//递归实现
public static void quick(int[] a, int l, int h) {
//当分区元素的个数小于1
if (l >= h) {
return;
}
int resultPvIndex = partition(a, l, h);//返回第一次基准点的索引值
//{3 2 1}
quick(a, l, resultPvIndex - 1);//左边的分区确定
//{9 8 7 5}
quick(a, resultPvIndex + 1, h);//右边的分区确定
}
public static int partition(int[] a, int l, int h) {
//基准点的元素 用来比较大小
int pv = a[h];
int i = l;
for (int j = l; j < h; j++) {
if (a[j] < pv) {
if (i!=j){
swap(a, i, j);
}
i++;
}
}
//基准点和i对应的元素交换
if (i!=h){
swap(a, h, i);
}
System.out.println(Arrays.toString(a) + "i:" + i);
//返回的结果代表了基准点的索引,来确定下一次分区的边界
return i;
//确定下一次分区的基准点
}
}
2.双边循环快排(并不会等价于hoare霍尔区方案)
1.选择最左元素作为基准点元素
2.j指针负责从右到左找比基准点小的元素,i指针负责从左到右找比基准点大的元素,一旦找到二者交换,直至i和j相交
3.左后基准点i(此时i和j相等)交换,i即为分区的位置
package com.uin.sort;
import java.lang.reflect.Array;
import java.util.Arrays;
import static com.uin.sort.SelectionSort.swap;
/**
* @author wanglufei
* 双边循环快排
* @description: TODO
* @date 2021/11/25/11:59 上午
*/
public class Quick_Double {
public static void main(String[] args) {
int[] a = {5, 3, 7, 2, 9, 8, 1, 4};
System.out.println(Arrays.toString(a));
quick(a, 0, a.length - 1);
}
private static void quick(int[] a, int l, int h) {
if (l >= h) {
return;
}
int resultPvIndex = partition(a, l, h);
quick(a, l, resultPvIndex - 1);
quick(a, resultPvIndex + 1, h);
}
private static int partition(int[] a, int l, int h) {
int pv = a[l];
int i = l;
int j = h;
while (i < j) {
//j 从右向左 找比基准点小的
while (i < j && a[j] > pv) {
j--;
}
//i 从左向右 找比基准点大的
while (i < j && a[i] <= pv) {
i++;
}
swap(a, i, j);
}
swap(a, l, j);
System.out.println(Arrays.toString(a)+" j="+j);
return j;
}
}
3.快速排序的特点
1.平均时间复杂度O(n*l**o**g*2*n*),最坏时间复杂度0(n^2)
2.数据量大的时候,优势非常明显
3.属于不稳定的排序
快排的第二种实现
快速排序算法的思想是这样的:首先我们使用两个下标变量i和j,分别指向待排序序列的起点(i)和终点(j);然后,我们使用j变量逐步向前移动,并在移动过程中找到第一个比i下标指向元素取值更小的元素,此时j变量停下脚步,i位置上的元素和j位置上的元素进行互换。互换完毕后,换i变量向后移动,同时在移动过程中找到第一个比j变量指向元素更大的值,当找到这个值得时候,i变量停下脚步,i位置上的元素和j位置上的元素进行互换。
之后重复上面的两个步骤,变量i和j交互相对移动,直到ij碰面为止。然后以ij碰面的位置为中间点,将待排序序列一分为二,重复执行上面的步骤。
相信各位同学在听了上面的说明应该已经一脸蒙圈状了(请原谅我的词穷|||Orz),下面我们直接通过一张图片演示的快速排序算法的流程来进行观察,并总结出相关的规律:

package com.uin.sort.快速排序;
import java.util.Arrays;
/**
* @author wanglufei
* @description: TODO
* @date 2021/12/7/10:45 AM
*/
public class Quick {
public void quiicksort(int[] a, int start, int end) {
if (end - start >= 1) {
int i = start;
int j = end;
int tmp = 0;
while (i < j) {
//如果a[i]<a[j] 控制j向前
while (i < j && a[j] >= a[i]) {
j--;
}
//来判断是ij相遇了 还是 a[i]>a[j]
//a[i]>a[j]
if (i < j) {
tmp = a[j];
a[j] = a[i];
a[i] = tmp;
}
//让i向后走
while (i < j && a[i] <= a[j]) {
i++;
}
if (i < j) {
tmp = a[j];
a[j] = a[i];
a[i] = tmp;
}
}
//此时i==j ij相遇了
//递归实现 对左右数组元素快速排序
quiicksort(a, start, i - 1);
quiicksort(a, i + 1, end);
} else {
return;
}
}
public static void main(String[] args) {
int[] a = new int[]{7, 0, 1, 9, 2, 3, 8, 5, 4};
Quick quick = new Quick();
quick.quiicksort(a, 0, a.length - 1);
System.out.println(Arrays.toString(a));
}
}
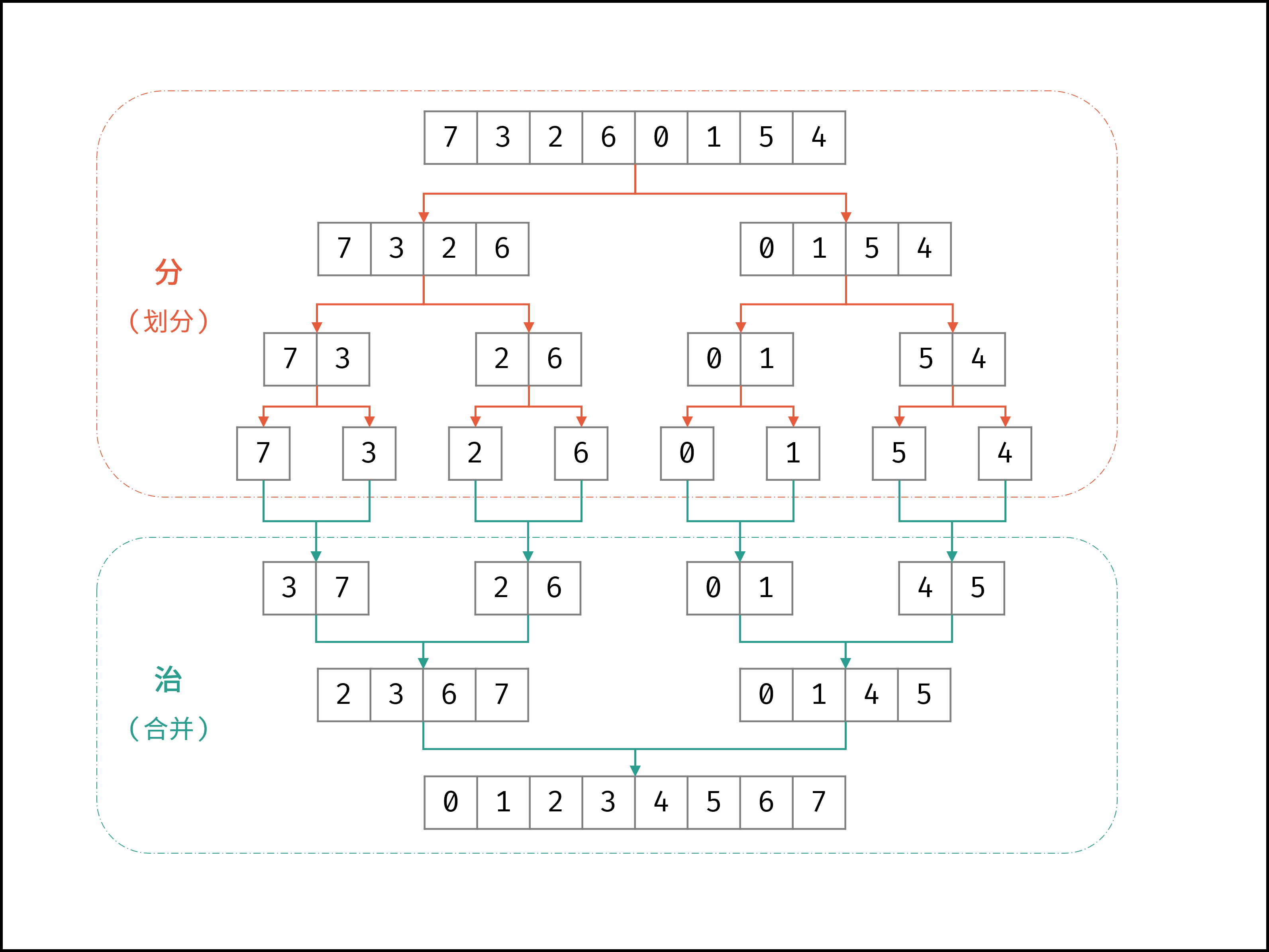
2.8 归并排序
归并排序(Merage-Sort)是建立在归并的操作上的一种有效的排序算法,该算法采用分治法的一个典型应用。将已有的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并排序是采用分治法的典型应用,而且是一种稳定的排序方式,不过需要使用到额外的空间。
合久必分分久必合。
文字描述:
1.将序列中待排序数字分为若干组,每个数字分为一组
2.将若干个组两两合并,保证合并后的数组是有序的
3.重复第二步操作知道剩下一组,排序完成
归并排序的优点在于最好情况和最坏的情况的时间复杂度都是O(nlogn),所以是比较稳定的排序方式。
package com.uin.sort;
/**
* @author wanglufei
* @description: TODO
* @date 2021/11/25/3:01 下午
*/
public class MergingSort {
public static void main(String[] args) {
int[] a = {9, 2, 6, 3, 5, 7, 10, 11};
merSort(a, 0, a.length - 1);
for (int i = 0; i < a.length; i++) {
System.out.println(a[i]+"");
}
}
public static void merSort(int[] a, int left, int right) {
if (left < right) {
int mid = (left + right) / 2;
merSort(a, left, mid);//左边归并排序,是的左子序列有序
merSort(a, mid + 1, right);//右边归并排序,是的右子序列有序
merge(a, left, mid, right);
}
}
private static void merge(int[] a, int left, int mid, int right) {
//合并a数组中下标为left和right到mid 和下标mid+1到right部分
//
int[] temp = new int[right - left + 1];
int i = left;
int j = mid + 1;
int k = 0;
while (i <= mid && j <= right) {
//左子序列
if (a[i] < a[j]) {
temp[k++] = a[i++];
} else {//a[i]>=a[j]
temp[k++] = a[j++];
}
}
while (i <= mid) {
//将左边的剩余元素填充到temp
temp[k++] = a[i++];
}
while (j <= right) {
//将右边的剩余元素填充到temp
temp[k++] = a[j++];
}
//
for (int k2 = 0; k2 < temp.length; k2++) {
a[k2+left]=temp[k2];
}
}
}
第二种实现:
//二分
//有序数组的合并
package com.uin.sort.归并排序;
import java.util.Arrays;
/**
* @author wanglufei
* 实现二
* @description: TODO
* @date 2021/12/6/9:29 PM
*/
public class mersort {
/**
* 用户调用的归并排序算法方法
* 在其内部创建一个与待排序数组a等长的辅助空间数组tmp
* 并在内部调用mergeSortInner()方法的时候传递这个辅助数组到该方法中
* 该方法相当于归并排序算法的外壳方法
*/
public void mergesort(int[] a) {
//1.在外壳方法当中,首先创建一个与待排序数组等长的临时空间数组
int[] tmp = new int[a.length];
mergeSortInner(a, 0, a.length - 1, tmp);
}
/**
* 真正实现归并排序算法的内部方法
* 该方法使用递归结构实现
* 通过外部传入临时数组的方方式创建与原始数组登场的辅助空间数组
*/
public void mergeSortInner(int[] a, int start, int end, int[] tmp) {
//1.如果待排序数组剩余的空间的长度是大于1的,那么就继续执行e二分
if (end - start >0) {
//3.执行递归调用,将数组a分为左右两部分,分别递归排序,保证左右两部分数组有序
int m = (start + end) / 2;
//左的递归调用
mergeSortInner(a, start, m, tmp);
//右的递归调用
mergeSortInner(a, m + 1, end, tmp);
//4.在保证左右连两个数组的元素有序,在对左右两部分区间的元素进行数组合并
//4.1 将a当中指定空间范围内,左右两部分元素对应的拷贝到临时数组tep当中
for (int i = start; i <= m; i++) {//左
tmp[i] = a[i];
}
for (int i = m + 1; i <= end; i++) {//右
tmp[i] = a[i];
}
//4.2 执行有序数组的合并的过程
int left = start;
int right = m + 1;
int result = start;
while (left <= m && right <= end) {
if (tmp[left] <= tmp[right]) {
a[result] = tmp[left];
left++;
} else {//tmp[left] > tmp[right]
a[result] = tmp[right];
right++;
}
result++;
}
//4.3有一部分肯定会先完成合并,而剩余元素的肯定要比已经合并的元素要大,直接续上
if (left <= m) {
while (left <= m) {
a[result++] = tmp[left++];
}
}
if (right <= end) {
while (right <= end) {
a[result++] = tmp[right++];
}
}
} else {
//2.递归出口 end - start == 0 ,当前操作范围内只有一个元素,天然有序
//此时我们就直接结束递归
return;
}
}
public static void main(String[] args) {
int[] a = new int[]{7, 0, 1, 9, 2, 6, 3, 8, 5, 4};
mersort mersort = new mersort();
mersort.mergesort(a);
System.out.println(Arrays.toString(a));
}
}
2.9 递归和查找
2.9.1 二分查找
1. 有序
2. 求numbs的中间值
3. 比较它和target的大小,来确定查询范围
4. 以此循环
5. 返回target元素的下标
1.编写二分查找的代码
1.前提条件:有已排好序的数组A
2.定义左边界Left,有边界Right,确定搜索的范围,循环执行3,4两步
3.获取中间索引的m=Floor(Left+Right)/2
4.中间索引的值A[m]与待搜索的target进行比较
a.A[m]==target,返回中间索引
b.A[m]>target,中间值得右侧都大于target,无需比较,中间索引左边去找,将m-1设置为右边界
c.A[m]<target,中间值的左侧都小于target,无需比较,中间的索引的右边去找,将m+1设置为左边界,重新查找
5.当left>right的时候,表示没有找到,应结束循环 return -1;
6.如果m整数过大 会存在整数溢出的问题
//代码格式
package com.uin;
/**
* @author wanglufei
* 二分查找的模版
* @description: TODO
* @date 2021/11/24/3:21 下午
*/
public class BinarySearch {
public static void main(String[] args) {
//奇数取中间
//偶数二分取中间靠左
int[] array = {1, 5, 8, 11, 19, 22, 31, 35, 40, 45, 48, 49, 50};
int target = 48;
int idx = binarySearch(array, target);
System.out.println(idx);
}
public static int binarySearch(int[] a, int t) {
int left = 0, right = a.length - 1, m;
while (left <= right) {
/*
* 如果整数很大 那么会存在整数溢出的问题
* l+(r-l)/2
* l/2+r/2
* =========
* 无符号的右移运算
* (l+r)>>>1
*/
m = (left + right) / 2;
if (a[m] == t) {
return m;
} else if (a[m] < t) {//35<48
//35, 40, 45, 48, 49, 50
left = m + 1;
} else {//a[m]>target
right = m - 1;
}
}
return -1;
}
}
//以递归的方式实现
package com.uin.search;
/**
* @author wanglufei
* 递归方式实现
* @description: TODO
* @date 2021/12/6/6:47 PM
*/
public class recursionBinarySerarch {
/**
* @desc 递归调用:[start,end]
* target<a[m] binarySearch(a,target,start,m-1)
* target>a[m] binarySearch(a,target,m+1,end)
* 递归出口:
* 1.target == a[m] 此时表示目标元素在搜索序列中的下标已经找到,直接返回m取值即可
* 2.s > e:此时表示待搜索序列当中不包含目标元素,此时直接返回-1即可
* @Return: int
* @author: wanglufei
* @date: 2021/12/6 6:53 PM
* @Version V1.1.0
*/
public int binarySearch(int[] a, int target, int start, int end) {
if (start > end) {
return -1;
}
int m = (start + end) / 2;
if (a[m] < target) {
return binarySearch(a, target, m + 1, end);
}
if (a[m] > target) {
return binarySearch(a, target, start, m - 1);
}
if (a[m] == target) {
return m;
}
return -1;
}
public static void main(String[] args) {
int[] a = new int[]{12, 24, 35, 47, 56, 66, 78, 81, 89, 90};
recursionBinarySerarch serarch = new recursionBinarySerarch();
int target = 12;
System.out.println(serarch.binarySearch(a, target, 0, a.length - 1));
}
}
2.9.2 递归
实际上从变成的角度来看,递归并不像我们在Java中常见的ArrayList、HashMap那样,是一种具体的代码,递归更多的是一种代码结构。通过这种的代码结构,我们能够更加简单的解决同一类问题,而这一类问题有一个统一的名字:分治算法的问题。
1.每个小问题的解决过程和前一个大问题的解决过程是一致的,只是每一次的临界条件不太相同
2.并且每一次的问题规模都在缩小
//递归的简答案例
//1-10相加
//递推公式:add(n)=n+add(n-1)
//三个明确
1.什么时候将问题过程继续拆分
只要不是自己加到自己的本身 也就不是1+1的时候
2.拆到什么时候是头,也就是什么时候能够得到小问题的明确答案
只有在计算到从1加到1的时候,才不需要继续拆分,这个问题才有明确的解
3.大问题的解和小问题解之间具有什么样的关系
每一个大问题的答案,都时有小问题的答案堆起来的,比如从1加到10的和,就是10加上从1到9的和计算出来的
//伪代码实现
如果n>1
从1加到n的和=n+从1加到n-1的和
如果n==1
这个问题有直接的解,直接返回1
package com.uin.recursion;
/**
* @author wanglufei
* @description: TODO
* @date 2021/12/6/3:12 PM
*/
public class Add {
public int add(int n) {
if (n > 1) {
return n + add(n - 1);//递归代码级别的实现
} else {
return 1;
}
}
public static void main(String[] args) {
Add add = new Add();
int add1 = add.add(10);
System.out.println(add1);
}
}
1.递归算法的标准结构
如果你已经能理解上面的代码,那么说明说明你已经能够在读懂的基础上,能够使用递归算法的基础上解决一些简单的为题了。
//1.递归的简单的调用
递归调用指的就是在同一个方法内部再次调用自己的过程
递归调用作用实际上就是在将一个大问题进行解剖,将其划分为诸多小问题,并将这些小问题一一解决
并且最终使用小的问题的解,计算得到大问题的解。
所以我们可以得到这样的一条结论:在执行递归调用的时候,我们传递的参数范围,规模等等。都比原来的问题的范围小、规模小。
package com.uin.recursion;
/**
* @author wanglufei
* @description: TODO
* @date 2021/12/6/6:08 PM
*/
public class RecursionCases {
/**
* @param n
* @desc n的阶乘
* @Return: int
* @author: wanglufei
* @date: 2021/12/6 6:10 PM
* @Version V1.1.0
*/
public int factorial(int n) {
if (n > 1) {
return n * factorial(n - 1);
} else {
return 1;
}
}
/**
* @param
* @desc 斐波那契数列
* @Return: int
* f(n)=f(n-1)+f(n-2)
* @author: wanglufei
* @date: 2021/12/6 6:15 PM
* @Version V1.1.0
*/
public int fibonacci(int n) {
if (n > 2) {
return fibonacci(n - 1) + fibonacci(n - 2);
} else {
return 1;
}
}
public static void main(String[] args) {
RecursionCases cases = new RecursionCases();
System.out.println(cases.factorial(10));
System.out.println(cases.fibonacci(3));
}
}
2.10 分治算法与递归
1.大事化小小事化了:什么是分治算法
分治算法所解决的问题,都有相同的特征:整个大问题的解是通过分别计算多个小问题的解,并通过将这些小问题的解进行合并而得到的。
举个例子:菜市场做活动打折,拉哥要去把这一个月的要吃的菜都买回来,那么我就需要知道我这个月都要吃什么;
我想要知道这个月吃什么,那么就要知道这个月的每个星期我想要吃什么;
我想要知道这个月的每个星期吃什么,我就要知道每一个星期的每一天吃什么;
我想要知道每个星期的每一天吃什么,我就要知道每天的三顿饭分别吃什么;
每天的每一餐就已经是最小单位了,不能再拆分了,所以我只要能够确定每一餐吃什么,我就能够不断向上递推,得到每一天、每一个星期、进而这个月我都要吃什么。
所以:分治算法就是一种大事化小,小事化了的算法——用小问题的解递推合并计算出大问题的解。
2.分治算法的经典步骤:分、治、合
分治算法也有其规范的实现步骤,按照这个步骤,我们可以得到如下图所示的流程:

分治算法拆分流程图
通过上图,我们能够看到,分治算法的经典解题步骤就是:分、治、合。所谓分治合,解释如下:
分:将大问题逐渐拆分成为小问题的过程;只要一个小问题没有小到能够直接求解的程度,就要继续分解,这个过程称之为分;
治:当一个问题被拆分的足够小的时候,这个小问题的解能够直接计算得到,那么计算最小问题解的过程,称之为治;
合:求取最小问题解并不是我们的最终目标,我们的最终目标是要通过最小问题的解,逐渐合并并推导出整个大问题的解,这个过程称之为合。
实际上,我们后面所学的归并排序、快速排序等等算法,都会用到这个思路,所以他们也都属于分治算法的实现。
3.分治算法和递归的关系
递归结构是解决分治算法问题的常用工具,实际上几乎所有的分治算法问题都可以套用递归结构来实现。其中:
分治算法分的阶段,可以使用递归结构中的递归调用来实现,每一次的递归调用,都在将问题的规模不断变小;
分治算法治的阶段,可以看做是递归结构中递归出口,递归出口的取值就是最小问题的直接解;
分治算法合的阶段,需要在递归中使用各个递归调用结果值之间的关系来表示,因为递归方法的回退在内存中时自动的。
所以我们只要表示清楚小问题的解之间,是如何递推出大问题的解的关系即可。
所以综上所述:递归结构是实现分治算法问题的有力工具,绝大部分分治算法问题都可以使用递归结构进行实现。 作者:写Bug的拉哥 https://www.bilibili.com/read/cv8503499 出处:bilibili
2.11 桶排序–又快又麻烦的排序
桶排序算法是一种具有一些特殊条件约束的排序算法。但是在这些特殊条件的约束之下,桶排序算法的时间复杂度非常低,甚至可以说,在我们目前接触的8种排序算法中,桶排序算法的时间复杂度是最低的。
桶排序算法的排序流程可以做如下总结:
步骤1:遍历整个待排序序列,并找到这个序列中的最大值;
步骤2:使用待排序序列的最大值,作为一个辅助序列下标的最大值,创建一个辅助序列,我们称这个序列为桶序列(或者说直白一些就是桶数组);
步骤3:再次遍历整个待排序序列,在遍历过程中,如果遇见取值为m的元素,那么就在桶序列下标为m的位置上+1;
步骤4:遍历整个桶序列,在遍历过程中,如果下标为m的位置上的取值是k,那么就将这个下标m输出k次到原始数组中,排序完成。
听了上面的步骤,可能各位同学会觉得一言难尽……总觉得有些云里雾里……
桶排序没有复杂的步骤,没有高深的结构,但是却能够通过简单的3次遍历完成对序列的排序,这到底是是怎么实现的呢?

2.12 堆排序–枪打出头鸟
堆,是一种类似于二叉树的结构
也就是说,在堆中,每一个待排序序列的元素都可以看作是一个堆的节点
而堆的每一个节点,又有两个子节点,堆的结构如下图:

我们称图中任何一个节点下方的左右两个分支节点为其左右孩子节点,这个节点本身称之为其左右孩子节点的父节点。我们通过不断调整堆的结构,能够得到大根堆(用于升序排序)或者小根堆(用于降序排序)。也就是说:
大根堆:堆顶元素是整个堆中取值最大的元素;
小根堆:堆顶元素是整个堆中取值最小的元素。
然后我们通过将堆顶元素与堆中最后的元素进行互换,完成对整个堆的排序操作。
有的同学可能会说:我并不会操作二叉树,那么我能够写出来堆排序吗?
答案是肯定能啊!因为我们使用Java代码实现的堆排序算法并没有真的用到二叉树结构,而是使用一组下标关系公式来模拟二叉树结构。所以只要掌握了这几个公式,就能够完成通过一个序列(比如说数组)实现的“虚拟堆”的操作。
下面我们将堆排序算法的步骤进行分解,来演示一组堆排序的操作流程:
步骤1:构建堆。也就是将待排序序列中的元素,逐一加入堆结构中,这个过程相当于广度优先创建一个二叉树的过程:

步骤2:从最后一个根节点开始,从这个根节点的左右两个孩子节点中找到一个比较大的,然后和父节点进行比较:如果这个孩子比父节点取值更大,那么这个孩子和父节点进行互换,否则不动;重复上述过程,直到最后一个根节点为止。实际上堆顶元素就是最后一个根节点,当对最后一个根节点(堆顶元素)完成上述操作之后,堆顶元素就是整个堆结构中取值最大的元素。此时我们称这个堆成为了一个大根堆:

步骤3:将堆顶元素和堆中的最后一个元素互换,并断开互换后最后一个元素和堆的链接,此时我们就完成了对待排序序列中最大元素的排序,此时,一个元素就这样有序了:

然后不断重复步骤2与步骤3,直到堆中仅剩余一个元素为止,堆排序完成。
上面我们演示了一轮堆排序算法的流程,下面我们通过这个流程,总结出一些堆排序的规律。尤其重要的是,我们要通过上面演示的流程,总结出在序列(比如数组结构)中,用来描述堆结构的两个公式:
1.在堆排序过程中,创建堆结构的流程我们仅执行一次,如果我们使用一个线性存储结构用来描述堆结构。那么这个过程实际上是不需要通过代码实现的,也就是说,这个流程本身只是存在于思想结构和理论过程中的;
2.构建大根堆的流程,每执行一次,都能够将当前堆结构中的最大元素升至堆顶,也就是说,每构建一次大根堆,就能够使得一个元素有序。所以,如果一个序列中存在n个元素,那么我们只要执行n-1次构建大根堆的过程就可以了;
3.在堆结构中,一个中间节点,要么同时存在左右两个孩子,要么只有一个左孩子,不可能左右孩子同时不存在。因为如果一个节点左右孩子都不存在,那么这个节点就不能够称之为中间节点了,只能够称之为叶子结点;
4.我们在创建堆的过程中,实际上就相当于遍历了整个序列,然后将序列中的元素逐个放入堆结构中,所以实际上堆结构中的元素,按照从上到下,从左到右的顺序,就是序列中元素的顺序;
5.根据上面一条规律,我们能够直接推断出来,在堆结构中,具有所有中间节点(即具有左右孩子的节点,包括堆的根节点)所在下标的规律:中间节点在长度为n的序列中下标的最大值是:n / 2 -1,并且对这个值向下取整;
6.因为在堆中,每一个中间节点最多能够具有两个孩子节点,所以如果某一个中间节点如果在序列中的下标为k,那么其左右孩子节点与这个父节点的下标关系为:
左孩子节点下标 = 2k + 1;
右孩子节点下标 = 2k + 2;
7.通过上面总结的中间节点最大下标和父节点与两个孩子节点的下标关系,我们可以推理出如何判断一个节点是否具有右孩子,即:只要右孩子下标:2k + 2 <= n / 2 + 1,那么说明这个下标为k的父节点是具有右孩子的;
8.根据规律4我们可以知道,在堆结构中,按照从上到下、从左到右的顺序,堆结构中的节点的顺序就是序列中节点的顺序。所以,在构建一个大根堆之后,我们在将堆顶元素和堆中最后一个元素进行互换的时候,就是将序列中下标为0的元素和待排序序列中的最后一个元素的互换过程,即序列中下标为0的元素和下标为n / 2 - 1的元素之间的互换过程;
9.当序列中的一个元素有序之后,我们只要将待排序序列的最大下标,即n / 2 - 1向前提一位,即-1操作,就可以保证在这个序列中最后的元素,不会再参与到对排序之中。
package com.uin.sort.堆排序;
import java.util.Arrays;
/**
* @author wanglufei
* @description: TODO
* @date 2021/12/7/2:41 PM
*/
public class HeapSort {
public void heapSort(int[] a) {
//1.先将数组转换成堆结构
//数组的初始状态就对应了堆的初始状态,不需要用代码进行转换
//4。实现一个循环,每一次都表示一个循环有序,每一次都将参与堆排序的数组的最大下标向前题一格
for (int end = a.length - 1; end > 0; end--) {
//2.将堆结构不断的调整成为大根堆
maxHeap(a, end);
//3.将堆顶元素(此时表示的是堆中的最大的元素)和堆的最后一个叶子节点进行交换,表示这个元素已经有序
int tmp = a[0];
a[0] = a[end];
a[end] = tmp;
}
}
/**
* @param a 构建大根堆的数组
* @param end 参与构建大根堆数组元素的最大下标
* 相当于堆中的最后一个节点(叶子节点)在数组a中的对应下标
* @desc 构建大根堆的方法
* @Return: void
* @author: wanglufei
* @date: 2021/12/7 2:50 PM
* @Version V1.1.0
*/
public void maxHeap(int[] a, int end) {
//1.根据公式计算出堆的结构中最后一个父节点的下标
//公式:lastFather = [(start+end)/2👆取整]-1
int lastFather = (0 + end) % 2 != 0 ? (0 + end) / 2 : (0 + end) / 2 - 1;
//5.从最后一个父节点开始向前不断-1,使得每一个节点都能够实现左右的pk,以上犯上的步骤
for (int father = lastFather; father >= 0; father--) {
//2.根据父节点的下标推算出左右孩子的数组下标
//左孩子:2n+1
//右孩子:2n+2
int left = father * 2 + 1;
int right = father * 2 + 2;
//3.在保证右孩子下标没有越界的情况下,使用右孩子和父节点进行比较
//如果右孩子 > 父节点 进行交换
if (right <= end && a[right] > a[father]) {
int tmp = a[right];
a[right] = a[father];
a[father] = tmp;
}
//4.使用左孩子和父节点进行比较,如果左孩子 > 父节点 ,进行交换
//步骤4相当于间接的进行了左右孩子的大小比较
if (a[left] > a[father]) {
int tmp = a[left];
a[left] = a[father];
a[father] = tmp;
}
}
}
public static void main(String[] args) {
int[] a = new int[]{7, 0, 1, 9, 2, 6, 3, 8, 5, 4};
HeapSort heapSort = new HeapSort();
heapSort.heapSort(a);
System.out.println(Arrays.toString(a));
}
}
Top-N分析问题
对于经典TopK问题,本文给出 4 种通用解决方案。
解题思路:
一、用快排最最最高效解决 TopK 问题:
二、大根堆(前 K 小) / 小根堆(前 K 大),Java中有现成的 PriorityQueue,实现起来最简单:
三、二叉搜索树也可以 解决 TopK 问题哦
四、数据范围有限时直接计数排序就行了:
剑指 Offer 40. 最小的k个数
//大根堆
//输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
//
//
//
// 示例 1:
//
// 输入:arr = [3,2,1], k = 2
//输出:[1,2] 或者 [2,1]
//
//
// 示例 2:
//
// 输入:arr = [0,1,2,1], k = 1
//输出:[0]
//
//
//
// 限制:
//
//
// 0 <= k <= arr.length <= 10000
// 0 <= arr[i] <= 10000
//
// Related Topics 数组 分治 快速选择 排序 堆(优先队列) 👍 332 👎 0
import java.util.PriorityQueue;
import java.util.Queue;
//leetcode submit region begin(Prohibit modification and deletion)
class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
//保持堆的大小为k,然后遍历数组中的个数,遍历的时候做如下判断:
//1.若目前堆的大小小于k,将当前数字放入堆中
//2.否则判断当前数字与大根堆堆定元素的大小关系,如果当前数字比大根堆堆顶还大,这个数就直接跳过;
//反之如果当前数字比大根堆堆顶小,先poll掉堆顶,在将该数字放入堆中
if (k == 0 || arr.length == 0) {
return new int[0];
}
//默认是小根堆,实现大根堆需要重写一下比较器
Queue<Integer> pq = new PriorityQueue<>((v1, v2) -> v2 - v1);
for (int num : arr) {
if (pq.size() < k) {
pq.offer(num);
} else if (num < pq.peek()) {
pq.poll();
pq.offer(num);
}
}
//返回堆中的元素
int[] res = new int[pq.size()];
int idx = 0;
for (int num : pq) {
res[idx++] = num;
}
return res;
}
}
//leetcode submit region end(Prohibit modification and deletion)















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









