






文章目录
Shell常见的排序和查找算法
一、排序算法
1、冒泡排序
1.1 基本思想
所谓冒泡排序,就是如同水里的泡泡一样,将合适的值一次次往上冒,直到所有数据全部处理完成。
在数据中的解释就是:从第一个数开始,每次都将前一个数与后一个数作比较,如果前一个数大于后一个数,则将两者交换位置(否则不交换),此时,后一个数值已变化,然后再将后一个数与后后一个数作比较,重复操作,直到所有的数都比较完成。
1.2 算法过程
先定义一个外循环,控制整个排序次数(排序次数为数据的个数),然后再内嵌一个内循环,在内循环中进行每次排序的比较,内循环的比较次数为:数据个数-当前排序次数,因为,比如说,在第一次比较时,比较得出的结果一定是数据中的最大值,并排在最后,此时,最大值已知,不用再进行比较了,以此类推,每次都会减少一次比较。

1.3 时间复杂度
第一次循环n,第二次循环n,综合为O(n^2)。
1.4 shell实现
#!/bin/bash
a=(10 20 30 80 40 60 )
echo ${a[*] }
n=${#a[*]} //提取数组长度
for (( i=1 ; i<n; i++ ))
do
for ((j=0;j<n-i;j++)) //确定比较元素的位置,比较相邻两个元素,较大的数往后放,比较次数随比较轮数而减少
do
if [ ${a[$j]} -gt ${a[$j+1]} ] ; then
c=${a[$j+1]} ; a[$j+1]=${a[$j]} ; a[$j]=$c; //元素交互
fi
done
done
echo ${a[*]}

2、插入排序
2.1 基本思想
所谓插入排序,就是将后面的数与前面的数比较,如果后面的数小于前面的数,就将后面的数插入到前面的数的前面。
2.2 算法过程
所谓插入排序,就是从第二个数开始,依次向前比较,如果前面一个数小于这个数,那么就将前面一个数右移,将前面一个数的位置赋空(看了代码就明白),然后再比较这个数与前前一个数,如果前前一个数大于这个数,则将这个前前的数赋给这个空位置,前前一个数的原位置则就代表了空,重复以上操作,最后将空位置补上当前操作的数即可,直到全部比较完成。
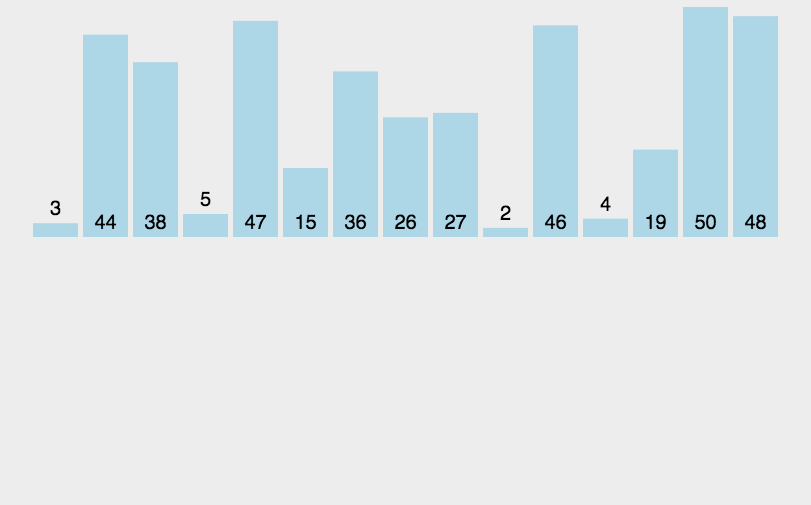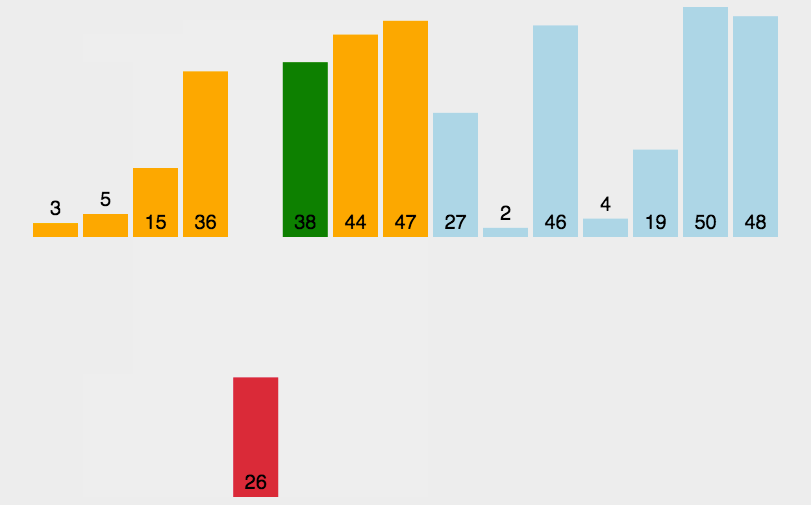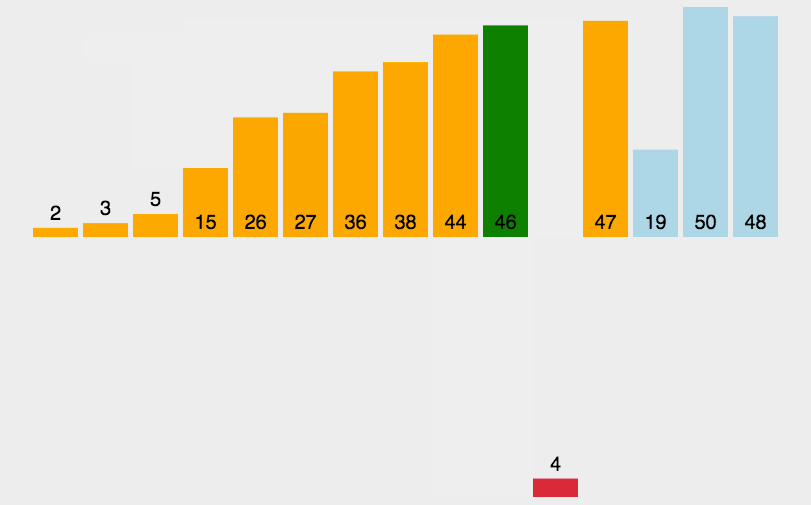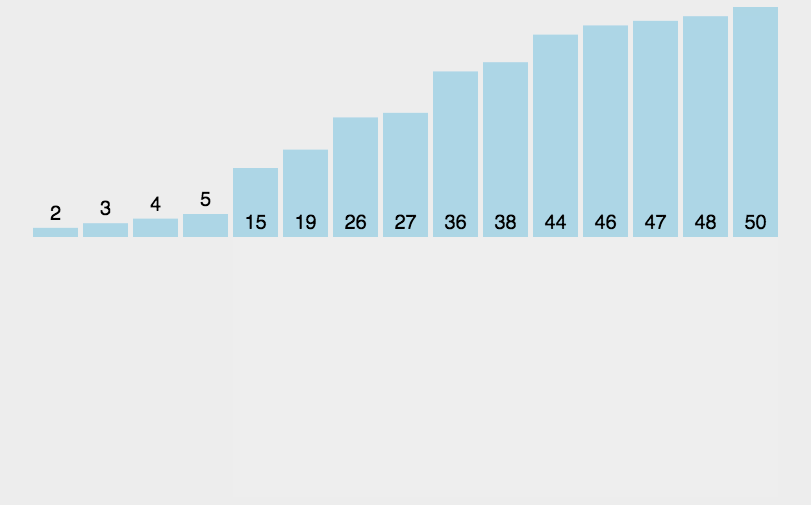
2.3 时间复杂度:
第一次循环n,第二次循环n,综合为O(n^2)。
2.4 Shell实现
#!/bin/bash
a=(1 4 3 2 9 7 6 8 5)
n=${#a[*]}
for (( i=1 ; i<n ; i++))
do
cmp=${a[$i]}
for (( j=i-1 ; j>=0 && a[j]>cmp; j-- )) //将比较的元素钱
do
a[j+1]=${a[j]}
done
a[$j+1]=$cmp
done
echo ${a[*]}

3、选择排序
3.1 基本思想
所谓选择排序,就是每次选择出当前比较数据的最小值,然后将其传递到数据的前面。
3.2 算法过程:
第一步:定义一个外层循环,控制排序次数,循环次数为数据个数-1。
第二步:定义一个变量k,这个变量等于外层循环的次数的起始值 i ,目的是存放当前需要操作的数据的第一个数,以便与后面的数比较。
第三步:定义一个内层循环,这个内层循环代表着当前需要比较的次数,起始值为k+1,因为k是当前数据的第一个位置,不需要让自己比自己,结束位置为数据末端,即数据的长度。
第四步:将k位置的数与数据比较,如果比较的数小于k位置的数,则将这个索引赋给k,以此类推,最后每次比较结束都会找到当前数据的最小值。
第五步,将第i的位置的数据与k的数据交换,即将最小值放到前面。
第六步:再次操作以上步骤,直到数据全部完成。
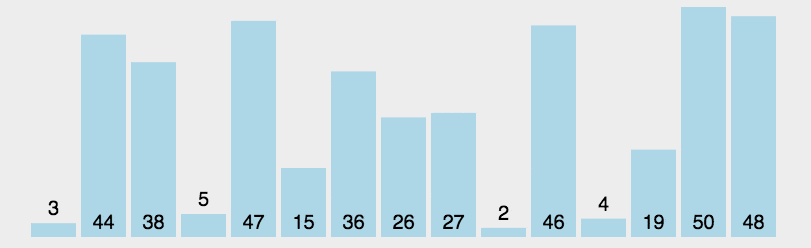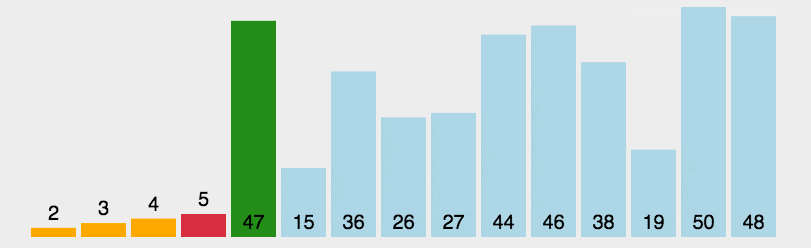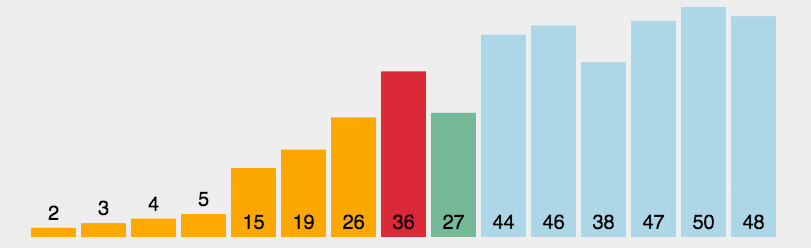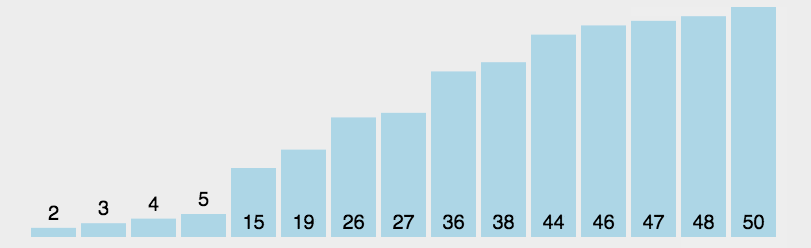
3.3 时间复杂度:
第一次循环n,第二次循环n,综合为O(n^2)。
3.4 Shell实现
还有两种方式,一种直接交互,一种是记下下标,最后交互。
方式一:
#!/bin/bash
a=(10 20 30 80 40 60 )
echo ${a[*] }
n=${#a[*]}
for (( i=0 ; i<n; i++ ))
do
for ((j=i+1;j<n;j++))
do
if [ ${a[$i]} -gt ${a[$j]} ] ; then
c=${a[$j]} ; a[$j]=${a[$i]} ; a[$i]=$c; //比较成立的就交换,确保每次都是找出最小或最大值
fi
done
done
echo ${a[*]}


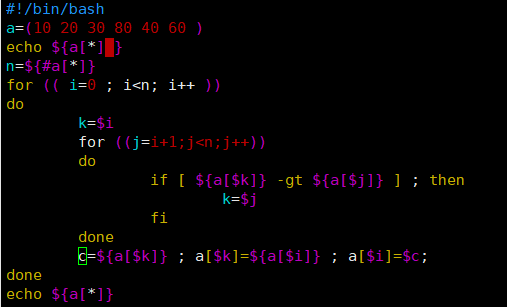
方式二:
#!/bin/bash
a=(10 20 30 80 40 60 )
echo ${a[*] }
n=${#a[*]}
for (( i=0 ; i<n; i++ ))
do
k=$i
for ((j=i+1;j<n;j++))
do
if [ ${a[$k]} -gt ${a[$j]} ] ; then
k=$i; //比较成立不立即交互,记下下标,确保每次都是找出最小或最大值的下标
fi
done
c=${a[$i]} ; a[$i]=${a[$k]} ; a[$k]=$c;
done
echo ${a[*]}

二、查找算法
1、顺序查找
1.1 基本思想
对于任意一个序列以及一个给定的元素,将给定元素与序列中元素依次比较,直到找出与给定关键字相同的元素,或者将序列中的元素与其都比较完为止。
1.2 时间复杂度
只有一次循环n次,所以为综合为O(n)。
1.3 Shell实现
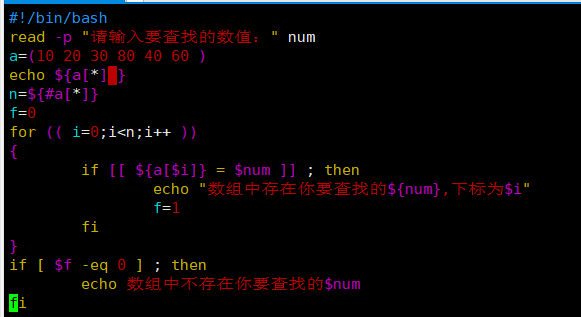
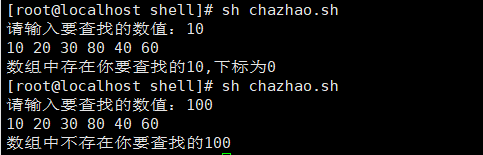
#!/bin/bash
read -p "请输入要查找的数值:" num
a=(10 20 30 80 40 60 )
echo ${a[*] }
n=${#a[*]}
f=0 //判断是否找到的标志位
for (( i=0;i<n;i++ ))
{
if [[ ${a[$i]} = $num ]] ; then
echo "数组中存在你要查找的${num},下标为$i"
f=1
fi
}
if [ $f -eq 0 ] ; then
echo 数组中不存在你要查找的$num
fi
2、折半查找(二分法查找)
1.1 基本思想
首先将给定值key与表中中间位置元素的关键字比较,若相等,则查找成功,返回该元素的存储位置;若不等,则所需查找的元素只能在中间元素以外的前半部分或后半部分(例如,在查找表升序排列时,若给定值key大于中间元素的关键字,则所查找的元素只可能在后半部分)。然后在缩小的范围内继续进行同样的查找,如此重复,直到找到为止,或确定表中没有所需要查找的元素,则查找不成功,返回查找失败的信息。
1.2 时间复杂度
二分查找因为每次都是从中间点开始查找,所以每次都是n/2,在最坏的情况下,时间复杂度综合位O(log(n))。
1.3 Shell的实现
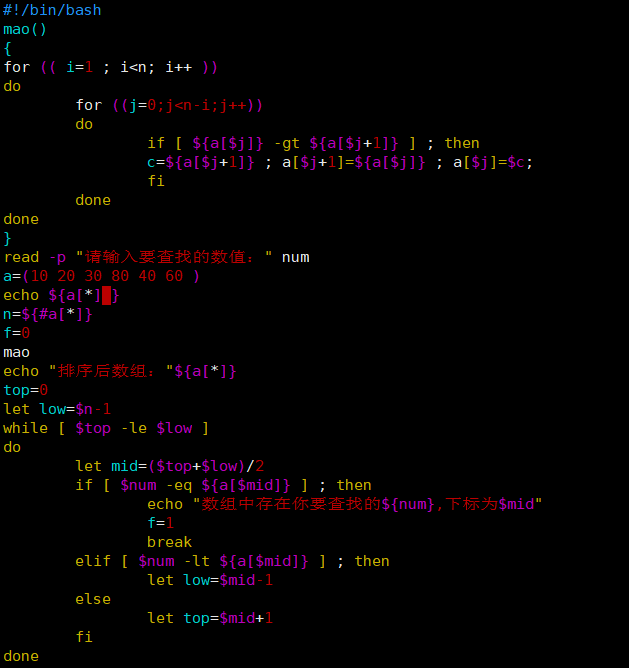
#!/bin/bash
mao() //冒泡排序
{
for (( i=1 ; i<n; i++ ))
do
for ((j=0;j<n-i;j++))
do
if [ ${a[$j]} -gt ${a[$j+1]} ] ; then
c=${a[$j+1]} ; a[$j+1]=${a[$j]} ; a[$j]=$c;
fi
done
done
}
read -p "请输入要查找的数值:" num
a=(10 20 30 80 40 60 )
echo ${a[*] }
n=${#a[*]}
f=0
mao
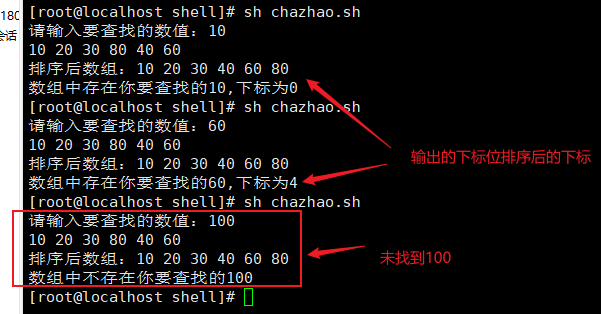
echo "排序后数组:"${a[*]} //调用冒泡排序函数后输出排序后的数组
top=0
let low=$n-1
while [ $top -le $low ]
do
let mid=($top+$low)/2 //去上下限值的中间值
if [ $num -eq ${a[$mid]} ] ; then
echo "数组中存在你要查找的${num},下标为$mid"
f=1
break
elif [ $num -lt ${a[$mid]} ] ; then
let low=$mid-1 //修改上限值
else
let top=$mid+1 //修改下限值
fi
done














 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









