







论文
Zhang X, Chen Q, Ng R, et al. Zoom to learn, learn to zoom[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 3762-3770.
主要贡献
- 构建了HR-LR真实数据对,提出SR-RAW数据集;
- 引入CoBi损失,解决真实数据对引起的两幅图像的对齐问题。
背景
Existing learning-based super-resolution methods do not use real sensor data, instead operating on processed RGB images.
一般的超分辨方法在构建数据集时,多采用的是人工对HR图像进行降级,通过双三次降采样、最近邻插值、添加噪声、模糊核模糊等操作,即使融合了更复杂的降级流程(例如在BSRGAN和RealESRGAN),得到的图像对仍然不是最原生的图像对。即使是kernelGAN通过生成的LR图像和原生HR图像的图像像素分布进行限制,仍然只能模拟、逼近真实LR图像。这就使得生成的LR图像和真实场景下的图像并不匹配,从而导致在这种数据集上训练的模型,只能处理生成的LR图像。
因此作者提出使用相机变焦采集真实的HR-LR对,而减少后续的人工处理。但直接采集真实的HR-LR对时,会导致在训练时产生图像的像素配准问题,针对这一问题,作者参考CX损失,融合图像的空间坐标和特征信息,设计了CoBi损失。
创新点一、SR-RAW数据集
we collect a diverse dataset, SR-RAW, that contains raw sensor data and ground-truth high-resolution images taken with a zoom lens at various zoom levels.
作者收集的HR-LR对是RAW格式的(RAW格式是数码相机拍摄后得到的原始图像数据,我们熟知的jpg、png、bmp等都是在RAW的基础上处理得到)。通过不同的焦距即可获得不同分辨率的原始图像。这种做法可以直接获得X4倍的RAW格式的图像对。
采用这种做法时,不用对LR图像进行额外的人工处理,也不能进行额外的人工处理,因为作者的初衷便是得到最真实的LR数据。
We first match the field of view (FOV) between RAW-L and RGB-H.
但由于RAW格式的图像需要专业软件才能打开,我们平时的软件更多的是能打开RGB类型的图像。因此,为对标现实生活,数据集中低分辨的图像LR可以仍保持RAW格式,而高分辨图像HR需要使用RGB类型的。这可以帮助数码设备在获得原始RAW数据后直接进行超分辨为RGB类型的图像,可以直接由软件读入。
Alignment is then computed between RGB-L and RGB-H to account for slight camera movement caused by manually zooming the camera to adjust focal lengths.
Furthermore, when aligning images with different resolutions, sharp edges in the high-resolution image cannot be exactly aligned with blurry edges in the lowresolution image. The described misalignment in SR-RAW usually causes 40-80 pixel shifts in an 8-megapixel image pair.
通过真实数据对进行训练时的一个最重要的问题是LR和HR之间不能做到完全的对齐,并且,由于LR和HR使用不同焦距的镜头拍摄得到,还有景深、对焦等问题。因此即便在进行对齐矫正后,也难以真正避免对齐问题。如作者所言,图像对常常会产生40-80的像素点偏移。
创新点二、CoBi损失函数
Pixelto-pixel losses such as L1 and L2 generate blurred images due to misalignment in the training data. On the other hand, the recently proposed Contextual Loss (CX) for unaligned data is also unsatisfactory as it only considers features but not their spatial location in the image.
由于使用的数据集的特殊性,作者不能使用任一常用的损失函数,因为这些损失函数作用的数据集都是配准好的。即使是CX损失,对于为配准的图像也不能达到好的效果。因此可以考虑在CX损失的基础上进行改进,CX损失的定义如下:
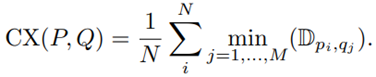
Given input image P and its target Q, the contextual loss tries to minimize the summed distance of all matched feature pairs.
P表示生成图像的特征点的集合,Q表示目标图像特征点的集合,CX损失函数表示:对于P的每一个特征点,找到在Q中的某个点,使得这两点间距离最短,然后将P中特征点对应的所有最短距离求和。
Inspired by the edge-preserving bilateral filter, we integrate the spatial pixel coordinates and pixel-level RGB information into the image features.
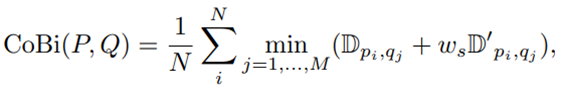
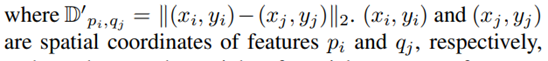
在CX损失的基础上,添加了特征的空间坐标信息。不仅强调了特征之间的相似度,而且还强调了这些相似度高的特征的空间距离的接近程度。因为我们现在考虑的是图像的配准问题,所以必须要考虑生成图像和目标图像的特征的空间关系。使用的具体的网络中,CoBi的公式如下:
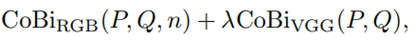
RGB表示直接对生成图像P和目标图像Q进行操作,n表示图像被切分后的patch的大小为n X n;VGG表示将生成图像P和目标图像Q输入到VGG网络后提取得到中间特征图,然后在进行计算损失。
结果
对比实验

消融实验

结论
这篇文章帮助理解了TPGSR中的数据集构建,虽然在我们的数据集中,并不会用到真实的RAW格式的数据集。但是其CoBi损失对我们仍有启迪意义,即使作者是针对配准问题提出的CoBi损失,但是这种损失利用了单个像素的坐标信息,进而会利用到单个像素的周边像素信息,提升像素信息的利用率。















 1742
1742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











