






共分三步走
第一步:下载ExDark数据集
先从这里下载ExDark原始数据集,下好解压了是这个样子:
数据集地址:
方式一:我的百度云链接:https://pan.baidu.com/s/1hYT2qe5TaI_x59XQf0IuUg
提取码:8888
方式二:官网:https://aistudio.baidu.com/datasetdetail/129450
解压好的样子: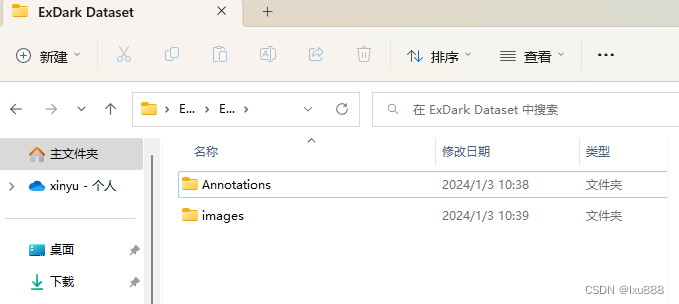
第二步:准备
原本的(标注)格式:
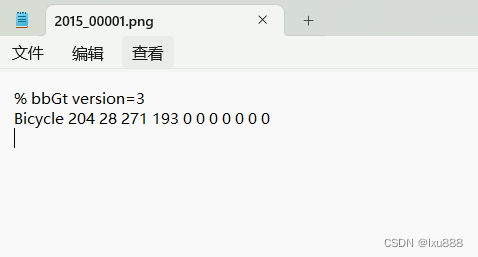
转换后的(标注)格式:
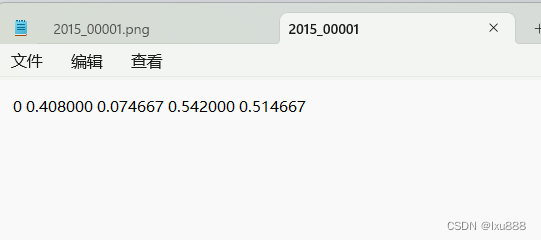
转换条件:
在同一目录下,
①新建一个文件夹“output”——存放转换后的数据集
②新建一个py代码“recipy”——转换的程序
目前文件夹内是长这样的:
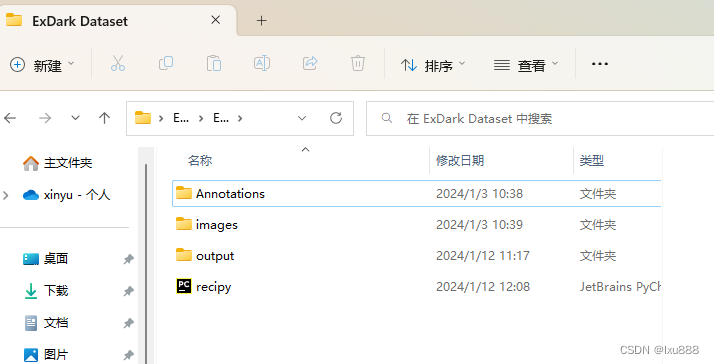
将以下代码放进recipy:
注:先完整的复制过去,我在下面说改哪里,怎么改
# ExDark数据集转化为YOLO格式
import os
from PIL import Image
import argparse
import shutil
labels = ['Bicycle', 'Boat', 'Bottle', 'Bus', 'Car', 'Cat', 'Chair', 'Cup', 'Dog', 'Motorbike', 'People', 'Table']
def ExDark2Yolo(txts_dir: str, imgs_dir: str, ratio: str, version: int, output_dir: str):
ratios = ratio.split(':')
ratio_train, ratio_test, ratio_val = int(ratios[0]), int(ratios[1]), int(ratios[2])
ratio_sum = ratio_train + ratio_test + ratio_val
dataset_perc = {'train': ratio_train / ratio_sum, 'test': ratio_test / ratio_sum, 'val': ratio_val / ratio_sum}
for t in dataset_perc:
os.makedirs('/'.join([output_dir, 'images', t]))
os.makedirs('/'.join([output_dir, 'labels', t]))
for label in labels:
print('Processing {}...'.format(label))
filenames = os.listdir('/'.join([txts_dir, label]))
cur_idx = 0
files_num = len(filenames)
for filename in filenames:
cur_idx += 1
filename_no_ext = '.'.join(filename.split('.')[:-2])
if cur_idx < dataset_perc.get('train') * files_num:
set_type = 'train'
elif cur_idx < (dataset_perc.get('train') + dataset_perc.get('test')) * files_num:
set_type = 'test'
else:
set_type = 'val'
output_label_path = '/'.join([output_dir, 'labels', set_type, filename_no_ext + '.txt'])
yolo_output_file = open(output_label_path, 'a')
name_split = filename.split('.')
img_path = '/'.join([imgs_dir, label, '.'.join(filename.split('.')[:-1])])
try:
img = Image.open(img_path)
except FileNotFoundError:
img_path = '/'.join([imgs_dir, label, ''.join(name_split[:-2]) + '.' + name_split[-2].upper()])
img = Image.open(img_path)
output_img_path = '/'.join([output_dir, 'images', set_type])
shutil.copy(img_path, output_img_path)
width, height = img.size
txt = open('/'.join([txts_dir, label, filename]), 'r')
txt.readline() # ignore first line
line = txt.readline()
while line != '':
datas = line.strip().split()
class_idx = labels.index(datas[0])
x0, y0, w0, h0 = int(datas[1]), int(datas[2]), int(datas[3]), int(datas[4])
if version == 5:
x = (x0 + w0/2) / width
y = (y0 + h0/2) / height
elif version == 3:
x = x0 / width
y = y0 / height
else:
print("Version of YOLO error.")
return
w = w0 / width
h = h0 / height
yolo_output_file.write(' '.join([str(class_idx),
format(x, '.6f'),
format(y, '.6f'),
format(w, '.6f'),
format(h, '.6f'),
]) + '\n')
line = txt.readline()
yolo_output_file.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('anndir', type=str, default='C:/MEC/Desktop/ExDark Dataset/ExDark Dataset/Annotations', help="ExDark annotations directory.") #ExDark的标注目录
parser.add_argument('imgdir', type=str, default='C:/Users/MEC/Desktop/ExDark Dataset/ExDark Dataset/images', help="ExDark images directory.") #ExDark的图像目录
parser.add_argument('--ratio', type=str, default='8:1:1', help="Ratio between train/test/val, default 8:1:1.") #train/test/val之间的比例,默认为8:1:1
parser.add_argument('--version', type=int, choices=[3, 5], default=3, help="Version of YOLO(3 or 5), default 3.")#YOLO版本(3或5)
parser.add_argument('--output-dir', type=str, default="output", help="Images and converted YOLO annotations output directory.")#图像和转换后的yolo标注的输出目录
args = parser.parse_args()
ExDark2Yolo(args.anndir, args.imgdir, args.ratio, args.version, args.output_dir)
修改:
1:第82行,default=’ ’ , 两个’ 直接,放你的Annotations的路径,这里我建议放绝对路径
2:第83行,default=’ ’ , 两个’ 直接,放你的images的路径,这里我建议放绝对路径
3:第84行,default=‘8:1:1’,我这里是把train/test/val之间的比例,设置为8:1:1,可以根据自己喜好设置
4:第85行,是选择yolov3还是yolov5的,在default= * ,自己设置
5:输出文件夹,就是转换后的数据集放哪里,按照我们上面说的,这里都默认是在“output”文件夹里
**注:**我所给的代码中,12是必改,345看个人喜好
第三步:转换
上面的都设置好之后,还有最重要的一件事:
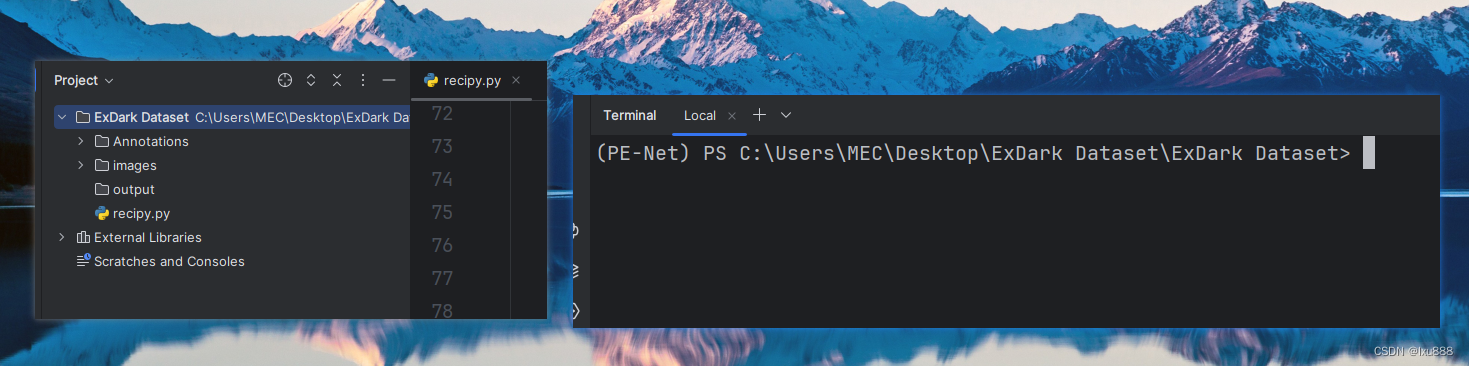
将pytharm的终端的位置拉到这个文件夹目录下:比如,我的是在
C:\Users\MEC\Desktop\ExDark Dataset\ExDark Dataset>
这个目录下,如图:
最后的最后,在这个环境终端下,运行:
(这行代码最后分配的比例是8:1:1,且是yolov3,且输出文件夹是output
python recipy.py Annotations images --ratio 8:1:1 --version 3 --output-dir output
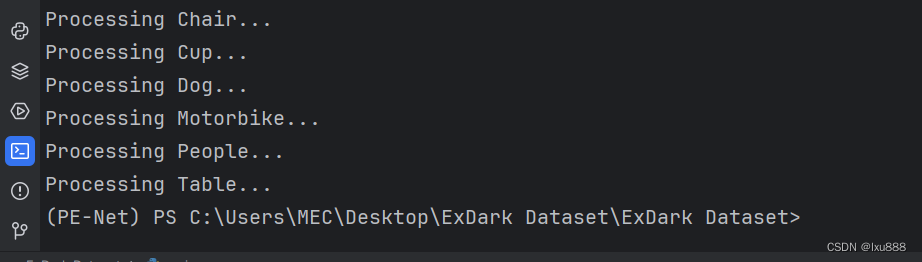
运行状态:

完成了:
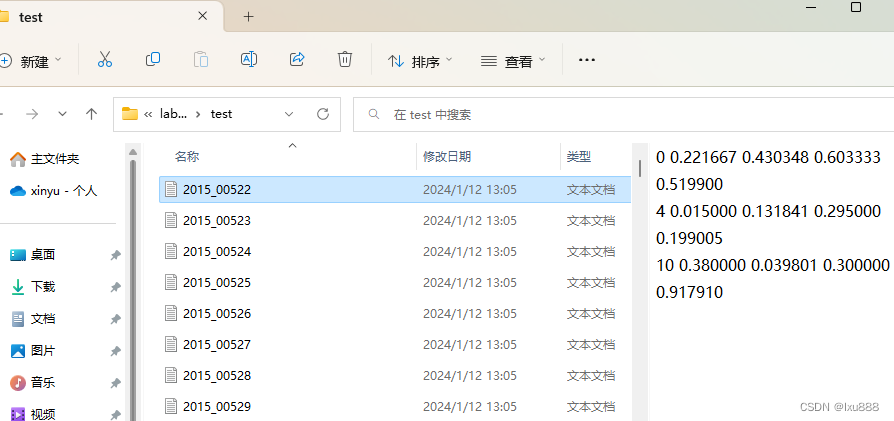
最终在文件夹中查看结果:
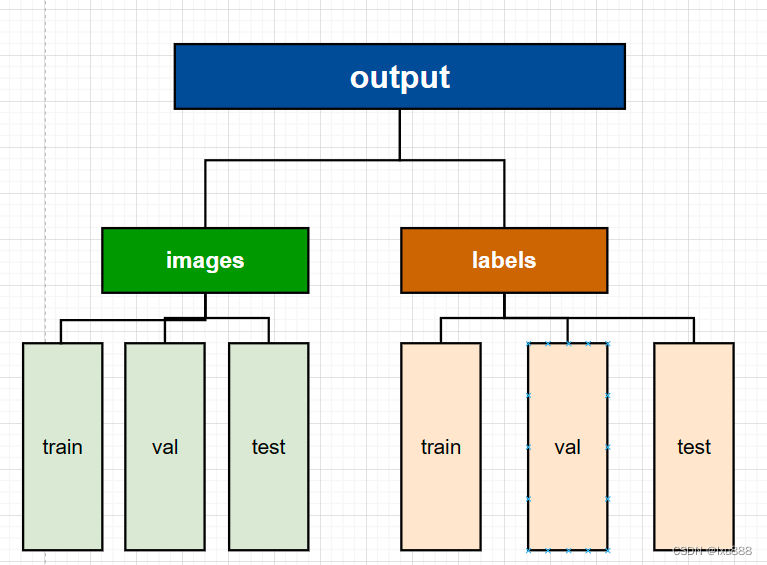
输出文件构成为:
结束了,谢谢大家
有任何问题请指正















 1674
1674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









