






 BERT是一种基于Transformer的预训练模型,通过MLM和NSP任务提升文本理解能力。文章介绍了BERT的输入处理、输出结构、预训练任务以及在意图识别和语义槽填充中的应用。
BERT是一种基于Transformer的预训练模型,通过MLM和NSP任务提升文本理解能力。文章介绍了BERT的输入处理、输出结构、预训练任务以及在意图识别和语义槽填充中的应用。
BERT
BERT( Bidirectional Encoder Representationform Transformers)是于2018年由Google团队根据transformer和ELMO思想提出的一种新的预训练模型。Bert 采用多个Transformer- Encoder结构堆叠的方式,在训练时通过无监督学习的方式集合大规模语料在两个预训练任务上获得预训练模型,实际运用时仅需对预训练好的模型进行微调即可,无需根据实际数据集再训练出一个模型,大大提升了泛化能力。
BERT的优势
BERT模型具有以下优势:
以往的预训练模型以单向语言模型为基础,文本表征能力受到限制,只能捕捉到单方向的上
- 下文信息。BERT以双向Transformer作为基础,采用MLM的预训练方式,可以更好地捕捉文本深层的语义特征,并具有学习文本上下文信息的能力。
- BERT预训练完成后,只需在模型的末尾添加一个额外的输出层进行微调(fine-tune),就可以实现对各种下游NLP任务的适配,在这过程中不需要对BERT模型本身进行修改。
BERT的训练
(1) BERT的输入
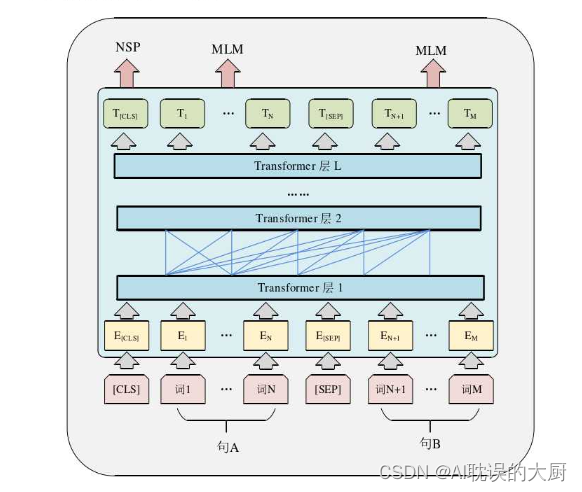
BERT中的词表征示意图BERT的输入为一系列单词(图中的粉色块)对应的表征(图中的黄色块),单词字典采用WordPiece算法进行构建。为了实现对文本的分类,BERT在每一个序列的开始部分都插入了一一个特定的“分类”表示词(“[CLS]”),用来聚合最后一个Transformer 层的输出。BERT采用了两种方法来分辨输入的序列是来自处理单句的任务(文本分类、序列标注等)还是处理两个句子的任务(语义匹配、问答匹配等):
- 在每个句子的末尾插入一个“分割”表示词(“[SEP]"), 以区分不同的句子词;
- 为每一个词的表征都添加一个可学习的“段落表征”来表示其属于哪一个句子。
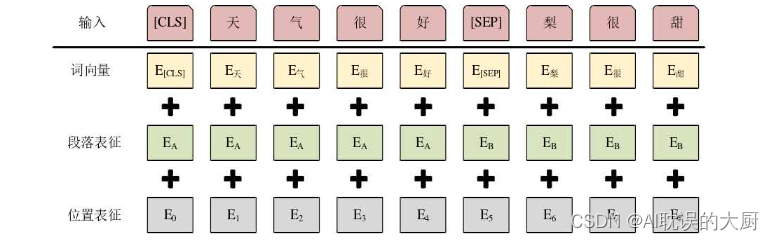
最终,模型的输入序列如图中粉色块所示(如果输入序列只有一个句子的话,则没有[SEP]及之后的词)。在输入序列中,每一个词对应的表征由三部分组成,分别是:词向量(token embedding)、段落表征(segment embedding)和位置表征(position embedding),如下图所示:
BERT中的词表征示意图
输入部分,BERT模型的输入包含三个编码:分别是词嵌入,位置编码和分割编码,相比Transformer输入,多出来的分割编码是用来区分输入中的两个句子,告知模型哪一字词是前一个句子的,哪一些字词属于后一个句子。而这个编码的引入是因为BERT的NSP预训练任务中需要用到两个句子作为输入,为此需要人为区别输入的这两个句子。此外与Transformer不太一样,BERT模型输入的词嵌入,位置编码全都是随机初始化的,需要后续随着模型预训练任务学习得到的,并且预训练之前,需要对位置编码的最大可能长度(BERT源码中为512)和对分割编码中包含的句子个数(BERT源码中为2)进行设置。
(2) BERT的输出
BERT实质上是多层Transformer的堆叠,因此也具有输出与输入的维度相同的特点。图2.10中的绿色块序列为BERT模型的输出,其中T[CLS]和Ti分别为[CLS]和序列中第i个词在最后一层Transformer的输出。对于句子级别的任务(如文本分类等),则把T[CLS]送到额外的输出层中进行学习。
(3) BERT的预训练任务
BERT构建了两个预训练任务,分别是掩码语言模型(masked language model, MLM)和承接句预测(next sentence prediction, NSP)。
- 遮蔽语言模型MLM
上下文信息提取是词语预测的重要组成部分,使用,双向LSTM提取句子特征时,例如在句子“南京的江苏是省会”中,想要预测“江苏”这个词语时,首先在正向LSTM中可以提取到“省会”,然后在反向LSTM中提取到“南京”,最终将两个LSTM网络的输出组合起来,通过计算进行预测。但是这种模型只是通过网络的叠加来实现双向语言模型的效果,而真正的双向语言模型应该在预测“江苏”的时候,同时获取“南京”和“省会”两个词语,于是出现了MLM模型。MLM模型的思想是遮挡输入句子中15%的部分,然后用剩下的部分来预测遮挡的部分,具体遮挡的逻辑是让句子中随机15%的token被选中,例如:“广式月饼口味甜”,被遮挡的词是“甜”,而这15%被选中的token中的遮挡策略包括三种:
(1)80%会被mask用于预测:“广式月饼口味甜”→“广式月饼口味[MASK]"。令BERT对序列中的所有单词都敏感,从而提高模型的学习能力。
(2)10%会替换成随机的词:“广式月饼口味甜”→“广式月饼口味咸”。用于防止模型过拟合。
(3)10%会保持不变:“广式月饼口味甜”→“广式月饼口味甜”。防止在后续微调时有没看到的单词。
- 下一句预测NSP
由于一些任务(如文本匹配)需要捕捉两个句子之间的关系,而MLM倾向于学习单词级别的特征,难以直接学习到句子级别的特征。为了使模型捕捉到句子级别的特征,能够更好地理解句子之间的连贯性,BERT在预训练中添加了NSP任务。具体做法是:先从语料库中挑选出句子A和句子B组成一对训练样例,50%的情况下句子B就是句子A的下一句(标注为“IsNext"),剩下50%的情况下句子B是语料库中一个随机的句子(标注为“NotNext");再将训练样例输入到BERT模型中进行二分类任务,预测前后输入的两个句子是否为连续的上下句。
BERT的PyTorch实现
BertModel
根据任务需要,如果不需要为指定任务finetune,可以选择使用BertModel
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs[0]
# The last hidden-state is the first element of the output tuple
参数:
input_ids、attention_mask、token_type_ids、position_ids、head_mask、inputs_embeds、
encoder_hidden_states、encoder_attention_mask、output_attentions、output_hidden_states
模型至少需要有1个输入: input_ids 或 input_embeds。
input_ids 就是一连串 token 在字典中的对应id。形状为 (batch_size, sequence_length)。
token_type_ids 可选。就是 token 对应的句子id,值为0或1(0表示对应的token属于第一句,1表示
属于第二句)。形状为(batch_size, sequence_length)。
- input_ids
就是一连串 token 在字典中的对应id。形状为 (batch_size, sequence_length)。Bert 的输入需要用 [CLS] 和 [SEP] 进行标记,开头用 [CLS],句子结尾用 [SEP],bert模型对应的输入格式如下所示:
bert: [CLS] + tokens + [SEP] + padding
- token_type_ids
可选。就是 token 对应的句子id,值为0或1(0表示对应的token属于第一句,1表示属于第二
句)。形状为(batch_size, sequence_length)。如为None则BertModel会默认全为0(即a句)。
tokens:[CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
token_type_ids:0 0 0 0 0 0 0 0 1 1 1 1 1 1
tokens:[CLS] the dog is hairy . [SEP]
token_type_ids:0 0 0 0 0 0 0
- attention_mask
可选。各元素的值为 0 或 1 ,避免在 padding 的 token 上计算 attention (1不进行masked,0则 masked)。形状为(batch_size, sequence_length)。如为None则BertModel默认全为1。
- position_ids
可选。表示 token 在句子中的位置id。形状为(batch_size, sequence_length)。形状为(batch_size,sequence_length)。如为None则BertModel会自动生成。这个目前没有用到,没有研究。
形如[0,1,2,…,seq_length - 1],
- head_mask
可选。各元素的值为 0 或 1 ,1 表示 head 有效,0无效。形状为(num_heads,)或(num_layers,num_heads)。
- input_embeds
可选。替代 input_ids,我们可以直接输入 Embedding 后的 Tensor。形状为(batch_size,
sequence_length, embedding_dim)。
- encoder_hidden_states
可选。encoder 最后一层输出的隐藏状态序列,模型配置为 decoder 时使用。形状为(batch_size,sequence_length, hidden_size)。
- encoder_attention_mask
可选。避免在 padding 的 token 上计算 attention,模型配置为 decoder 时使用。形状为
(batch_size, sequence_length)。
bert的输出是由四部分组成:
- last_hidden_state
类型:torch.FloatTensor ,形状: (batch_size, sequence_length, hidden_size)
hidden_size=768,它是模型最后一层输出的隐藏状态。(通常用于命名实体识别)
- pooler_output
类型:torch.FloatTensor,形状 (batch_size, hidden_size)这是序列的第一个token(classification token)的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的。(通常用于句子分类,至于是使用这个表示,还是使用整个输入序列的隐藏状态序列的平均化或池化,视情况而定)
- hidden_states
这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size,sequence_length, hidden_size)
- attentions
这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元
组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
我们在使用Bert进行微调的时候,通常都会使用bert的隐含层的输出,然后再接自己的任务头。
import torch
from transformers import BertTokenizer, BertModel
bertModel = BertModel.from_pretrained('bert-base-chinese',
output_hidden_states=True, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
text = '让我们来看一下bert的输出都有哪些'
input_ids = torch.tensor([tokenizer.encode(text)]).long()
outputs = bertModel(input_ids)
print(len(outputs))
print(outputs.keys())
print(outputs['last_hidden_state'].shape)
print(outputs['pooler_output'].shape)
print(len(outputs['hidden_states']))
结果:
4
odict_keys([‘last_hidden_state’, ‘pooler_output’, ‘hidden_states’,
‘attentions’])
torch.Size([1, 18, 768])
torch.Size([1, 768])
13
12
Tokenzier
BERT 使用当初 Google NMT 提出的 WordPiece Tokenization ,将本来的 words 拆成更小粒度的wordpieces,有效处理不在字典里头的词汇 。中文的话大致上就像是 character-level tokenization,而有 ## 前缀的 tokens 即为 wordpieces。
BERT Tokenizer 是一个将文本转换为数字化输入的工具,它可以将一段文本拆分成一系列的 tokens(标记),并将每个 token 转换为相应的数字表示,以便后续将其输入到 BERT 模型中进行预测。
tokenizer是一个将纯文本转换为编码的过程,该过程不涉及将词转换成为词向量,仅仅是对纯文本进行分词,并且添加[MASK]、[SEP]、[CLS]标记,然后将这些词转换为字典索引。
除了一般的wordpieces以外,BERT还有5个特殊tokens:
-
[CLS]:在做分类任务时其最后一层的表示.会被视为整个输入序列的表示;
-
[SEP]:有两个句子的文本会被串接成一个输入序列,并在两句之间插入这个token作为分割;
-
[UNK]:没出现在BERT字典里头的字会被这个token取代; [PAD]:zero
-
padding掩码,将长度不一的输入序列补齐方便做batch运算;
-
-[MASK]:未知掩码,仅在预训练阶段会用到。
下面是一个简单的 BERT Tokenizer 的使用示例:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(text)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(tokens)
print(ids)
结果:
[‘Using’, ‘a’, ‘transform’, ‘##er’, ‘network’, ‘is’, ‘simple’]
[7993, 170, 11303, 1200, 2443, 1110, 3014]
在这个示例中,我们首先通过 BertTokenizer.from_pretrained() 方法加载了预训练的 BERT 模型,然后将一段文本传递给 tokenizer.tokenize() 方法进行拆分,得到了一系列的 tokens。最后,我们使用 tokenizer.convert_tokens_to_ids() 方法将这些 tokens 转换为数字表示。
这些输出一旦转换为适当的框架张量,就可以用作模型的输入。
需要注意的是,在使用 BERT Tokenizer 进行文本处理时,需要根据具体的任务选择合适的预训练模型和 Tokenizer,以及进行必要的数据预处理和后处理。
JointBERT
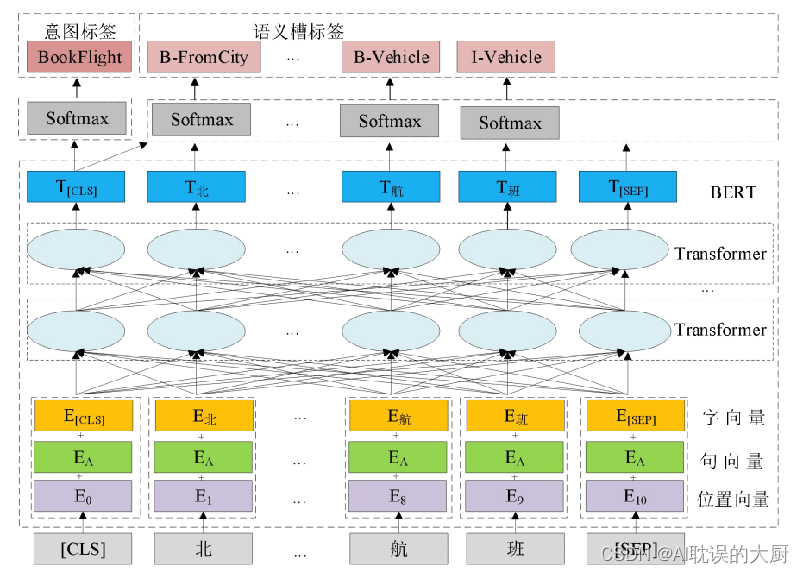
JointBERT是一种基于 BERT 的意图识别和语义槽填充联合建模。在意图识别任务中,基于 BERT 模型的联合建模在每个输入本文前都添加一个特殊标签[CLS],然后 Transformer 忽略空间和距离的把全局信息编码进每个位置,因此,经过Transformer 深度编码的[CLS]标签包含了整个输入本文的语义信息,可以学到整个输入序列的上层特征,将[CLS]标签的最终隐藏状态输入到 softmax 层经过线性变化得到意图标签。对于语义槽填充任务,基于 BERT 模型的联合建模中,将输入文本中其他词项的最终隐藏状态输入到 softmax 层,对每一个输出进行线性变换得到对应的语义槽标签。
基于BERT模型的意图识别和语义槽填充联合建模
源码 main.py
import argparse
from trainer import Trainer
from utils import init_logger, load_tokenizer, read_prediction_text, set_seed,
MODEL_CLASSES, MODEL_PATH_MAP
from data_loader import load_and_cache_examples
def main(args):
init_logger()
set_seed(args)
tokenizer = load_tokenizer(args)
train_dataset = load_and_cache_examples(args, tokenizer, mode="train")
dev_dataset = load_and_cache_examples(args, tokenizer, mode="dev")
test_dataset = load_and_cache_examples(args, tokenizer, mode="test")
trainer = Trainer(args, train_dataset, dev_dataset, test_dataset)
if args.do_train:
trainer.train()
if args.do_eval:
trainer.load_model()
trainer.evaluate("test")

















 3615
3615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









