







 “喂,兄弟,最近无聊透顶了,有没有什么书可看?”“我这有《三国演义》的电子书,你要不要?”“‘既生瑜,何生亮。’ 《三国演义》好呀,你邮件发给我!”“OK!,文件1M多大小,好像大了点。我打个包,稍等……哈哈,少了一半,压缩效果不错呀。”“太棒了,快点传给我把。” ——《大话数据结构》压缩和哈夫曼编码息息相关,压缩的原理简单点来说就是将要压缩的文本重新编码,减少不必要的空间,那哈夫曼编码要如何生成呢?哈夫曼编码的生成就得需要 哈夫曼树。那哈夫曼树是怎么生成的呢?假如,有 A(5) , B(
“喂,兄弟,最近无聊透顶了,有没有什么书可看?”“我这有《三国演义》的电子书,你要不要?”“‘既生瑜,何生亮。’ 《三国演义》好呀,你邮件发给我!”“OK!,文件1M多大小,好像大了点。我打个包,稍等……哈哈,少了一半,压缩效果不错呀。”“太棒了,快点传给我把。” ——《大话数据结构》压缩和哈夫曼编码息息相关,压缩的原理简单点来说就是将要压缩的文本重新编码,减少不必要的空间,那哈夫曼编码要如何生成呢?哈夫曼编码的生成就得需要 哈夫曼树。那哈夫曼树是怎么生成的呢?假如,有 A(5) , B(
“喂,兄弟,最近无聊透顶了,有没有什么书可看?”
“我这有《三国演义》的电子书,你要不要?”
“‘既生瑜,何生亮。’ 《三国演义》好呀,你邮件发给我!”
“OK!,文件1M多大小,好像大了点。我打个包,稍等……哈哈,少了一半,压缩效果不错呀。”
“太棒了,快点传给我把。” ——《大话数据结构》

压缩和哈夫曼编码息息相关,压缩的原理简单点来说就是将要压缩的文本重新编码,减少不必要的空间,那哈夫曼编码要如何生成呢?
哈夫曼编码的生成就得需要 哈夫曼树。
那哈夫曼树是怎么生成的呢?
假如,有 A(5) , B(15) ,C(40) ,D(30) ,E(10) 这五个数,括号里为对应的权值.
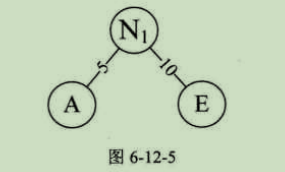
首先,就是取这个序列里,最小的那个和次小的那两个,然后这个最小的和次小的作为一个新的结点N1的左孩子和右孩子(为了统一,规定小的为左边,大的为右边),然后最小的自然是 A(5)和E(10) ,然后它两生成一个结点N1,其权值为他们两个权值的和,就是5+10=15,然后A(5) 和E(10)会从序列里 “抹去” (知道这个方便理解哦)
此时序列中只剩下B(15),C(40),D(30) ,N1(15) ,第一步生成的二叉树为下图6-12-5.
接着,重复上诉操作 得到下图6-12-6:

接着得到图6-12-7:

直到最后一个元素和生成的那个Nn 成为了最后一个结点T的左右孩子,这个最优的哈夫曼树就生成了。
如图6-12-8:

具体实现代码如下:
#include<iostream>
#include<cstring>
#include<math.h>
#include<stdio.h>
#include<stdlib.h>
#include<conio.h>
#include<vector>
#include<queue>
#include<stack>
using namespace std;
struct HuffmanNode//哈夫曼树的结点
{
char data ;//待编码的符号
double weight ;//符号出现的频率
int parent ,lchild,rchild; //父母结点和 左右结点
};
class HuffmanTree//哈夫曼树的一个类
{
private:
vector<HuffmanNode> hufftree; //哈夫曼树
int n;//最优生成树的结点个数
public:
HuffmanTree(vector<HuffmanNode>&leafs);//哈夫曼编码的构造函数
//~HuffmanTree();
vector<int>GetCode(int i );//得到哈夫曼编码
string Decode(vector<int>&source); //传参为向量的解码 函数
string Decode(string &source);// 传参为字符串的解码函数
void SelectSmall(int &least_index ,int &less_index ,int n );//找出树中最小值和次小值的一个函数,注意,这里n是字符串出现同一类型字母的个数 开始计算的,比如abcac ,这样的n=3;
//然后,这个less,和 least都是从函数里传出来的,可以不赋予初始值。
};
void HuffmanTree::SelectSmall(int &least_index ,int &less_index ,int n )//因为这个最小和次小下标要传出来,所以是引用哦
{
int least_weight,less_weight;//最小权值,和次小权值
int i =0;//循环变量
while(hufftree[i].parent!=-1)
{
i++;
}
int k = i+1;
while(hufftree[k].parent!=-1)
{
k++;
}
//以上两个循环必然 会出现两个hufftree[i OR k].parent!=-1 ,然后它两进行比较,得出最小值;
if 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1763
1763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











