







目录
垃圾回收器的基本原理是什么?有什么办法主动通知虚拟机进行垃圾回收?
String, Stringbuffer, StringBuilder 的区别
break ,continue ,return 的区别及作用
为什么重写 equals 方法,还必须要重写 hashcode 方法
JDK 和 JRE 有什么区别?
- JDK:java 开发工具包,提供了 java 的开发环境和运行环境。
- JRE: java 运行环境,为 java 的运行提供了所需环境。
具体来说 JDK 其实包含了 JRE,同时还包含了编译 java 源码的编译器 javac,还包含了很多 java 程序调试和分析的工具。简单来说:如果你需要运行 java 程序,只需安装 JRE 就可以了,如果你需要编写 java 程序,需要安装 JDK。
什么是跨平台性?原理是什么
所谓跨平台性,是指 java 语言编写的程序,一次编译后,可以在多个系统平台上运行。
实现原理:Java 程序是通过 java 虚拟机在系统平台上运行的,只要该系统可以安装相应的 java 虚拟机,该系统就可以运行 java 程序。
栈、堆、方法区分别存储什么内容
栈中保存基本数据类型的值和对象以及基础数据的引用;
堆中存储的全部是对象,每个对象都包含一个与之对应的class的信息;
方法区被所有的线程所共享,方法区包含所有的class和static变量。
JVM的体系结构
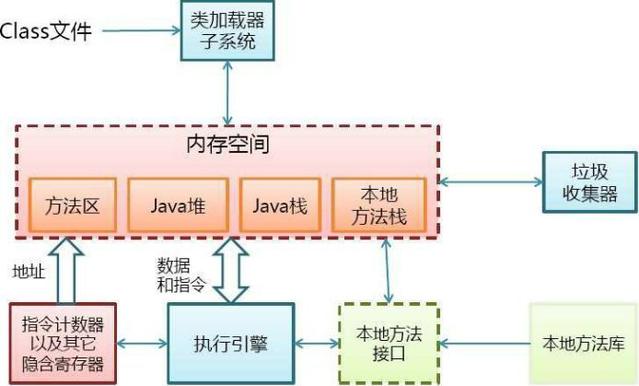
类装载器(ClassLoader)(用来装载.class文件)
执行引擎(执行字节码,或者执行本地方法)
运行时数据区(方法区、堆、java栈、PC寄存器、本地方法栈)
有两种算法可以判定对象是否存活:
1.)引用计数算法:给对象中添加一个引用计数器,每当一个地方应用了对象,计数器加1;当引用失效,计数器减1;当计数器为0表示该对象已死、可回收。但是它很难解决两个对象之间相互循环引用的情况。
2.)可达性分析算法:通过一系列称为“GC Roots”的对象作为起点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连(即对象到GC Roots不可达),则证明此对象已死、可回收。Java中可以作为GC Roots的对象包括:虚拟机栈中引用的对象、本地方法栈中Native方法引用的对象、方法区静态属性引用的对象、方法区常量引用的对象。
在主流的商用程序语言(如我们的Java)的主流实现中,都是通过可达性分析算法来判定对象是否存活的。
什么情况下会发生栈内存溢出
思路: 描述栈定义,再描述为什么会溢出,再说明一下相关配置参数,OK的话可以给面试官手写是一个栈溢出的demo。
栈是线程私有的,他的生命周期与线程相同,每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口等信息。局部变量表又包含基本数据类型,对象引用类型
如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常,方法递归调用产生这种结果。
如果Java虚拟机栈可以动态扩展,并且扩展的动作已经尝试过,但是无法申请到足够的内存去完成扩展,或者在新建立线程的时候没有足够的内存去创建对应的虚拟机栈,那么Java虚拟机将抛出一个OutOfMemory 异常。(线程启动过多)
参数 -Xss 去调整JVM栈的大小
GC的机制是什么?
GC是垃圾收集的意思(Gabage Collection),内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java语言没有提供释放已分配内存的显示操作方法
垃圾回收的优点和原理。
Java语言中一个显著的特点就是引入了垃圾回收机制,它使得Java程序员在编写程序的时候不再需要考虑内存管理。垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低级别的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清楚和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。回收机制有分代复制垃圾回收和标记垃圾回收,增量垃圾回收。
垃圾回收器的基本原理是什么?有什么办法主动通知虚拟机进行垃圾回收?
对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是"可达的",哪些对象是"不可达的"。当GC确定一些对象为"不可达"时,GC就有责任回收这些内存空间。可以。程序员可以手动执行System.gc(),通知GC运行,但是Java语言并不保证GC一定会执行。
GC算法和回收策略
GC最基础的算法有三种: 标记 -清除算法、复制算法、标记-压缩算法,但是我们常用的垃圾回收器一般都采用分代收集算法。
标记-清除算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
复制收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
标记-压缩算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
分代收集算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法
新生代中的对象“朝生夕死”,每次GC时都会有大量对象死去,少量存活
长期存活的对象进入老年代:JVM给每个对象定义一个对象年龄计数器,如果对象在Eden出生并经过第一次Minor GC后仍然存活,并且能被Survivor容纳,将被移入Survivor并且年龄设定为1。没熬过一次Minor GC,年龄就加1,当他的年龄到一定程度(默认为15岁,可以通过XX:MaxTenuringThreshold来设定),就会移入老年代。但是JVM并不是永远要求年龄必须达到最大年龄才会晋升老年代,如果Survivor 空间中相同年龄(如年龄为x)所有对象大小的总和大于Survivor的一半,年龄大于等于x的所有对象直接进入老年代,无需等到最大年龄要求。
jvm调优
设定堆内存大小
-Xmx:堆内存最大限制。
设定新生代大小。 新生代不宜太小,否则会有大量对象涌入老年代
-XX:NewSize:新生代大小
-XX:NewRatio 新生代和老生代占比
-XX:SurvivorRatio:伊甸园空间和幸存者空间的占比
设定垃圾回收器 年轻代用 -XX:+UseParNewGC
年老代用-XX:+UseConcMarkSweepGC
基本数据类型
整型:
- byte(1) short(2) int(4) long(8)
浮点型:
- float(4) double(8)
字符型:
- char(2)
布尔型:
- Boolean(1)
堆内存中数据的默认值
整数类型:0
浮点数:0.0
boolean:false
char:空字符串
引用数据类型:null
java的自动装箱和拆箱:
自动装箱
Integer total= 99;
//自动拆箱
Int totalprim = total;
简单说,装箱就是自动将基本数据类型转换为包装类型;拆箱就是自动将包装类型转换为基本数据类型。
类加载过程
加载:将class文件加载到内存中,并在方法区创建对应的class对象
验证:校验加载的class文件是否符合字节码规范
准备:完成验证阶段之后,jvm开始为静态static变量分配内存并初始化零值。
初始化:到了初始化阶段,用户定义的 Java 程序代码才真正开始执行。在这个阶段,JVM 会根据语句执行顺序对类对象进行初始化。
使用:当 JVM 完成初始化阶段之后,程序就可以开始使用。
卸载:当用户程序代码执行完毕后,JVM 便开始销毁创建的 Class 对象,最后负责运行的 JVM 也退出内存。
双亲委派模型
双亲委派模型是指当我们调用类加载器的loadClass方法进行类加载时,该类加载器会首先请求它的父类加载器进行加载,依次递归。如果所有父类加载器都加载失败,则当前类加载器自己进行加载操作。这样做可以保证Java核心类的安全,比如说你不能够去覆盖java.lang.String类。
Java 中的值传递和引用传递
- 值传递
在方法的调用过程中,实参把它的实际值传递给形参,此传递过程就是将实参的值复制一份传递到函数中,这样如果在函数中对该值(形参的值)进行了操作将不会影响实参的值。因为是直接复制,所以这种方式在传递大量数据时,运行效率会特别低下。
- 引用传递
引用传递弥补了值传递的不足,如果传递的数据量很大,直接复过去的话,会占用大量的内存空间,而引用传递就是将对象的地址值传递过去,函数接收的是原始值的首地址值。在方法的执行过程中,形参和实参的内容相同,指向同一块内存地址,也就是说操作的其实都是源数据,所以方法的执行将会影响到实际对象. 结论: 基本数据类型传值,对形参的修改不会影响实参; 引用类型传引用,形参和实参指向同一个内存地址(同一个对象),所以对参数的修改会影响到实际的对象。 String, Integer, Double 等 immutable 的类型特殊处理,可以理解为传值,最后的操作不会修改实参对象。
阐述静态变量和实例变量的区别?
静态变量: 是被 static 修饰符修饰的变量,也称为类变量,它属于类,不属于类的任何一个对象,一个类不管创建多少个对象,静态变量在内存中有且仅有一个拷贝;
实例变量: 必须依存于某一实例,需要先创建对象然后通过对象才能访问到它。静态变量可以实现让多个对象共享内存。
public、private、protected区别
public的访问权限:当前类,子类,当前类所在的包下,以及其他包下都可以进行访问。
protected的访问权限:除了当前类所在的包下、以及子类都可以访问,其他的包下都不能进行访问。(可以用肥水不流外人田记忆,哈哈)
默认的话:只能当前类和当前类所在的包下可以访问,当前类的子类和其他包下都不能进行访问。
private的访问权限:只有当前类可以访问(你可以理解成,加了private的话,这个人的钱就只能他自己知道他有多少钱,别人都不知道)
内部类,外部类,匿名内部类
我们定义一个类,在类中再定义一个类,这样内部定义的类就是内部类,外面的类就是外部类。
访问特点:
内部类可以直接访问外部类的属性方法,包括私有的
外部类想要访问内部类的属性方法,需要先实例化内部类,先new出来,才能调用,包括私有。
匿名内部类是内部类的简化写法
开发中最常用到的内部类就是匿名内部类了,以接口举例, 当你使用一个接口时,得做如下几步操作, 1.定义子类 2.重写接口中的方法 3.创建子类对象 4.调用重写后的方法
前提: 存在一个类或者接口,这里的类可以是抽象类
比如说有一个抽象类,你想调用里面的抽象方法,你就必须new 这个抽象类,然后重写里面的抽象方法,这就是匿名内部类的用法。
Java中的抽象类和接口的区别?
抽象类中可以有非抽象方法,可以有构造方法。接口中则不能有构造方法也不能有实现方法。
一个类只能使用一次继承关系。但是,一个类却可以实现多个接口。
jdk1.8以后接口中可以定义static方法和default方法。接口中定义的成员变量,实际上是常量。
接口和抽象类都不可以new,new出来的是一个实现接口的匿名类,然后去实现接口,并不是说直接new了一个接口出来。
new一个对象:
Object o = new Object();
new一个接口:
Interface I = new Interface(){
……
}
构造器 Constructor 是否可被 override
构造器(构造方法)Constructor 不能被继承,因此不能重写 Override,但可以被重载 Overload(不同参数即可)。
每一个类必须有自己的构造函数,在创建对象时自动调用,如果添加有参构造函数后,默认无参构造函数则被覆盖。子类不会覆盖父类的构造函数,但是在创建子类对象的时候,会自动调用父类构造函数。
方法的重写和重载的区别
重写:子类继承父类的方法,并重新实现该方法(相当于覆盖)
重载:方法名相同,但是参数必须得有区别(参数不同可以使类型不同,个数不同)
static,final,privite修饰的方法,都不能被子类重写。
==和equals的区别
==:
如果比较的是基本数据类型,比较的就是数值是否相等。
如果比较的是引用数据类型,比较的就是地址值是否相等。
equals:
1、equals的话,它是属于java.lang.Object类里面的方法,如果该方法没有被重写过默认也是==;
我们可以看到String,Integer等常用类的equals方法是被重写过的。
2、具体要看自定义类里有没有重写Object的equals方法来判断。
3、通常情况下,重写equals方法,会比较类中的相应属性是否都相等。
String能被继承吗?为什么?
不可以,因为String类有final修饰符,而final修饰的类是不能被继承的,实现细节不允许改变。平常我们定义的 String str="a"; 其实和 String str=new String("a") 还是有差异的。
第一个a保存在常量池中,第二个a保存在堆内存中
String, Stringbuffer, StringBuilder 的区别
String 字符串常量(final修饰,不可被继承),String是常量,当创建之后即不能更改。(可以通过StringBuffer和StringBuilder创建String对象) StringBuffer 字符串变量(线程安全),其也是final类别的,不允许被继承,其中的绝大多数方法都进行了同步处理,包括常用的Append方法也做了同步处理(synchronized修饰)。
String类型和int类型互相转化
String -> int int a = Integer.parseInt("str");
int -> String
int a = 10;
(1) string str = a + "";
(2) String str = String.valueOf(a);
(3) String str = Integer.toString(a);
String有哪些常用方法
int length();返回字符串的长度
string[] split(string char);字符串切割,返回字符串数组String[];
string subString(int beginIndex, int endIndex) 从beginIndex位置起,从当前字符串中取出到endIndex-1位置的字符作为一个新的字符串返回。
char charAt(int index) 返回字符串中指定位置的字符
int compareTo(String anotherString) 对字符串按字典顺序进行大小比较 返回正整数,负整数,0.
string concat(String str);字符串拼接 返回新字符串
int indexOf(int ch/String str)用于查找当前字符串中字符或子串,返回字符或子串在当前字符串中从左边起首次出现的位置,若没有出现则返回-1。
String toLowerCase() 全部转成小写字母
String toUpperCase() 全部转成大写字母
String replace(char oldChar, char newChar) 字符串替换
String trim() 截去字符串两端的空格,但对于中间的空格不处理。
boolean startsWith(String prefix)或boolean endWith(String suffix)
boolean equals(string otherString) 字符串匹配
Arrays常用的静态方法
Arrays.asList(T a) (将数组转换为集合类型List);
Arrays.equals(int[] a, int[] a2) (比较数组内容是否相等);
Arrays.sort(int[] a) (按照数字顺序排列整个数组);
Arrays.toString(int[] a) (返回指定数组的内容的字符串表示形式)
Object类有哪些常用方法
hashCode()和equale() 用来判断对象是否相同,
toString() 用于打印,看看对象信息
getClass() 多用于反射
wait(),notify(),notifyAll()
-
在使用的时候要求在synchronize语句中使用
-
wait()用于让当前线程进入等待序列
-
notify()用于随机唤醒一个持有对象的锁的线程
-
notifyAll()用于唤醒所有持有对象的锁的线程
clone() 用来另存一个当前存在的对象。
finalize() 这个函数在进行垃圾回收的时候会用到,匿名对象回收之前会调用到
break ,continue ,return 的区别及作用
break 跳出上一层循环,不再执行循环(结束当前的循环体),结束switch语句
continue 跳出本次循环,继续执行下次循环(结束正在执行的循环 进入下一个循环条件)
return 程序返回,不再执行下面的代码(结束当前的方法 直接返回)
为什么重写 equals 方法,还必须要重写 hashcode 方法
hash 类存储结构(HashSet、HashMap 等等)添加元素会有重复性校验,校验的方式就是先取 hashCode 判断是否相等(找到对应的位置,该位置可能存在多个元素),然后再取 equals方法比较(极大缩小比较范围,高效判断),最终判定该存储结构中是否有重复元素 hashCode 主要用于提升查询效率,来确定在散列结构中对象的存储地址; 重写 equals()必须重写 hashCode(),二者参与计算的自身属性字段应该相同;
hash 类型的存储结构,添加元素重复性校验的标准就是先取 hashCode 值,后判断 equals(); equals()相等的两个对象,hashcode()一定相等; 反过来:hashcode()不等,一定能推出 equals()也不等; hashcode()相等,equals()可能相等,也可能不等
总结来说就是两点:
- 使用hashcode方法提前校验,可以避免每一次比对都调用equals方法,提高效率
- 保证是同一个对象,如果重写了equals方法,而没有重写hashcode方法,会出现equals相等的对象,hashcode不相等的情况,重写hashcode方法就是为了避免这种情况的出现。
什么是反射?
反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;
对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 Java 语言的反射机制。
如何使用Java的反射?
Class.forName(className);
类名.class;
this.getClass();
然后就可以获取到类中的构造方法,属性,方法(包括私有)
缺点:效率比普通java语句低
破坏了封装性,直接获取到了私有的属性方法
优点:增加代码灵活性
对于任何一个类,我们都可以暴力获取它的任何一个属性和方法
面向对象的特性
封装
隐藏对象的属性和实现细节,仅对外提供公共访问方式,外面看不到内部方法和数据,保证独立性
封装原则 : 将不需要对外提供的内容都隐藏起来,把属性都隐藏,提供公共方法对其访问。
提供构造方法(有了构造方法才能通过new去构建一个对象
1.构造方法必须和类名称一样
2.构造方法不能有返回值)。
空参构造系统默认存在,但是当你手动加入了有参构造,默认的空参构造将不再存在。
好处:便于使用;提高复用性;安全性。
继承
子类可以继承父类的方法及属性,实现了多态以及代码的重用,因此也解决了系统的重用性和扩展性,但是继承破坏了封装,因为他是对子类开放的,修改父类会导致所有子类的改变,因此继承一定程度上又破坏了系统的可扩展性,所以继承需要慎用。
好处:
- 提高代码的复用性
- 让类和类产生了关系,是多态的前提
注意:
- 子类中所有的构造函数都会默认访问父类的无参构造方,因为每一个子类构造内第一行都有默认的语句super();
- 如果父类没有无参构造方法。那么子类的构造函数内,必须通过super语句指定要访问的父类中的构造函数。
- 如果子类构造函数中用this来指定调用子类自己的构造函数,那么被调用的构造函数也一样会访问父类中的构造函数。
多态
指的是属性或者方法在子类中表现为多种形态
同一个对象,在不同时刻表现出来的不同形态
体现:父类引用或者接口的引用指向了自己的子类对象
好处:提高了程序的扩展性
缺点:当父类引用指向子类对象时,虽然提高了扩展性,但是只能访问父类具备的方法,不可以访问子类中特有的方法。
多态的必要条件
- 必须要有关系,比如继承或者重写
- 父类引用指向子类实现
抽象
共性抽取
抽象是把多个事物的共性的内容抽取出来,本质就是把我们关注的内容抽取出来。(比如:宝马、奔驰都属于汽车,汽车是我们抽象出的概念)
抽象方法中没有方法体,包含抽象方法的类一定要为抽象类,它的作用是可以在继承时再具体实现这个方法。
synchronized和lock的区别
synchronized是jvm层面的,lock是一个类,是API层面的锁
synchronized修饰静态方法,是类锁,会锁住类。修饰成员方法,只锁住对象。
锁的释放:
synchronized:获取锁的线程执行完同步代码,释放锁,或者线程发生异常,jvm会让线程释放锁
lock:在finally中必须unlock释放锁不然会死锁
锁的获取
synchronized:假设a线程获得锁,b线程等待,如果a线程堵塞,b线程会一直等待
lock:能通过trylock去尝试获取锁
异常的处理机制
try catch finnally
throw throws
如何自定义一个异常
写一个类,extends继承Exception父类就行,然后写下无参有参构造,就可以用了。在业务代码中try catch 主动抛出自定义的异常,再用catch捕获。
throw和throws的区别
throw表示主动抛出异常,强调动作
throws表示声明此处可能会出现异常,可用在方法和类上,强调声明。
Cookie和Session的区别
Cookie功能需要浏览器的支持,禁用后就不可用
Cookie是不可跨域名的。比如你登录百度时保存了密码,下次登录百度就会提示出保存的密码,但如果你去登录网易,就不会弹出百度的密码。
Cookie有大小限制,不同浏览器大小限制不同。
Cookie的生命周期,在浏览器关闭后就结束了。cookie信息是以请求头的方式发送到服务器端的,通过request对象就可以获取所有的cookie。
Session的生命周期,服务器关闭后,session销毁,默认失效时间是30min。
cookie 存在于客户端,临时文件夹中; session存在于服务器的内存中,一个session域对象为一个用户浏览器服务.
cookie是以明文的方式存放在客户端的,安全性低,可以通过一个加密算法进行加密后存放; session存放于服务器的内存中,所以安全性好
get请求和post请求的区别
get和post都有自己的语意,不能随便混用
get请求浏览器会把header和data一并发送过去,服务器响应200 OK。
post请求浏览器会先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 OK。
post比get安全,get参数会直接暴露在浏览器路径
get请求参数通过url传递,post放在Request body中
讲讲WebService
Web Service是基于网络的、分布式的模块化组件,它执行特定的任务,遵守具体的技术规范,这些规范使得Web Service能与其他兼容的组件进行互操作。
JAXP(Java API for XML Parsing) 定义了在Java中使用DOM, SAX, XSLT的通用的接口。这样在你的程序中你只要使用这些通用的接口,当你需要改变具体的实现时候也不需要修改代码。
JAXM(Java API for XML Messaging) 是为SOAP通信提供访问方法和传输机制的API。
WSDL是一种 XML 格式,用于将网络服务描述为一组端点,这些端点对包含面向文档信息或面向过程信息的消息进行操作。这种格式首先对操作和消息进行抽象描述,然后将其绑定到具体的网络协议和消息格式上以定义端点。相关的具体端点即组合成为抽象端点(服务)。
SOAP即简单对象访问协议(Simple Object Access Protocol),它是用于交换XML编码信息的轻量级协议。
UDDI 的目的是为电子商务建立标准;UDDI是一套基于Web的、分布式的、为Web Service提供的、信息注册中心的实现标准规范,同时也包含一组使企业能将自身提供的Web Service注册,以使别的企业能够发现的访问协议的实现标准。
java设计模式
单例模式:单例模式重点在于在整个系统上共享一些创建时较耗资源的对象。整个应用中只维护一个特定类实例,它被所有组件共同使用。项目中数据库的连接,redis的连接就用到了单例模式,只会创建一次连接。
模板模式:模板模式就是通过抽象类来定义一个模板,然后将无法决定的部分抽象成抽象类交由子类来实现,一般这些抽象类的调用逻辑还是在抽象类中完成的。比如我们定义一个抽象的盖房子类,里面定义一个公共的,都必须遵守的方法,装修房子方法,里面有盖窗户,盖墙,盖们,具体怎么盖,又子类继承去自己实现。
工厂模式:比如说现在有一批桌子,有塑料的,木制的,大理石的,如果要用塑料的,就得new一个塑料桌子对象,如果要用木制的,就得new一个木制桌子对象,就会new 很多次,很麻烦,那我们就可以创建一个桌子工厂类,里面定义一个方法,可以根据传入的参数返回不同的对象,比如传入塑料,就返回一个塑料桌子对象,这样我们就不需要自己一个一个new不同对象了,交给工厂去解决。当然缺点就是如果要创建新的对象,还需要去改动工厂,会比较麻烦。
适配器模式:适配器就是一种适配中间件,它存在于不匹配的二者之间,用于连接二者,将不匹配变得匹配,简单点理解就是平常所见的转接头,转换器之类的存在。
当我们要访问的接口A中没有我们想要的方法 ,却在另一个接口B中发现了合适的方法,我们又不能改变访问接口A,在这种情况下,我们可以定义一个适配器p来进行中转,这个适配器p要实现我们访问的接口A,这样我们就能继续访问当前接口A中的方法(虽然它目前不是我们的菜),然后再继承接口B的实现类BB,这样我们可以在适配器P中访问接口B的方法了,这时我们在适配器P中的接口A方法中直接引用实现类BB中的合适方法,这样就完成了一个简单的类适配器。
观察者模式:观察者模式,又可以称之为发布-订阅模式,观察者,顾名思义,就是一个监听者,类似监听器的存在,一旦被观察/监听的目标发生的情况,就会被监听者发现,这么想来目标发生情况到观察者知道情况,其实是由目标将情况发送到观察者的。
观察者模式多用于实现订阅功能的场景,例如微博的订阅,当我们订阅了某个人的微博账号,当这个人发布了新的消息,就会通知我们。
比如之前定义了一个volite修饰的boolean变量,a线程把变量值修改掉,b,c线程就可以监听到这个变化,并作出相应的反应。
责任链模式:将请求的处理对象像一条长链一般组合起来,形成一条对象链。请求并不知道具体执行请求的对象是哪一个,这样就实现了请求与处理对象之间的解耦。
比如说当你提交一份文件给你的上级时,若他觉得自己不够资格处理,会将文件传递为他的上级,这样文件就会在这条链中传递,直到被某位有足够资格处理文件的人给处理掉为止。
业务id的生成规则,有哪些方式
1.uuid 几千万的数据基本没有重复的可能
但是是无序的,字符串,占用较大,不适合排序
2.数据库自增id,对于可以暴露的id来讲没问题
3.mongodb自己生成的_id,这个是适合分布式系统的,而且自带排序,很好
4.雪花算法 long类型的,绝对不会重复,自增排序,但占用还是比较大















 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









