






目录
前言
🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)
说在前面
本周学习目标:基本要求——学会自定义一个MyDataset加载车牌数据集并完成车牌识别(前面的文章学习中都是直接使用的datasets.ImageFolder加载Dataset);拔高要求——对单张车牌进行识别
我的环境:Python3.8、Pycharm2020、torch1.12.1+cu113
数据来源:[K同学啊](https://mtyjkh.blog.csdn.net/)
一、导入数据
1.1 导入所需的包并设置GPU
代码如下:
#一、导入数据
'''
1.1设置GPU
'''
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
import torch.nn.functional as F
import matplotlib.pyplot as plt
import pandas as pd
from torchvision.io import read_image
from torch.utils.data import Dataset
import torch.utils.data as data
from PIL import Image
import copy
warnings.filterwarnings("ignore") #忽略警告信息--???怎么突然增加一个这个
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)打印输出:cuda
1.2 获取类别名
这里的车牌图片的数据文件如右图所示,没有进行分类的,所以通过获取各个图片文件名作作为一类的名称

代码如下:
'''
1.2 获取类别名
'''
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data_dir = './015_licence_plate/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[1].split("_")[1].split(".")[0] for path in data_paths]
print(classeNames)
#这里一个车牌就是一类,因为我们的这里的数据是没有分类的,一个车牌就是一类
data_paths = list(data_dir.glob('*'))
data_paths_str = [str(path) for path in data_paths]
print(data_paths_str)打印输出:

1.3 数据可视化
查看车牌图片的示例
代码如下:
'''
1.3 数据可视化
'''
plt.figure(figsize=(14, 5))
plt.suptitle("数据示例", fontsize=15)
for i in range(18):
plt.subplot(3, 6, i+1)
images = plt.imread(data_paths_str[i])
plt.imshow(images)
plt.show()
输出结果如下:

1.4 标签数字化
实现了怎么样的一个功能:将文本数据转换为向量形式。首先定义了一个包含汉字、数字和字母的字符集合(char_set),然后定义了一个函数(text2vec),该函数接受一个文本输入并将其转换为向量形式。在函数中,对输入文本中的每个字符进行遍历,找到其在char_set中的索引,并将对应位置的值设置为1,其余位置为0,最终返回一个向量表示该文本。
最后,通过循环遍历所有的类别名称(classeNames),将每个类别名称转换为向量形式,并将这些向量存储在all_labels列表中
为什么需要这样操作:将字符集合中的每个字符映射到一个固定长度的向量中,其中字符对应的位置设置为1,其他位置设置为0。这种编码方式称为one-hot编码,可以将离散的文本数据转换为稠密的向量表示,方便后续的处理
代码如下:
'''
1.4 标签数字化
'''
import numpy as np
char_enum = ["京","沪","津","渝","冀","晋","蒙","辽","吉","黑","苏","浙","皖","闽","赣","鲁",\
"豫","鄂","湘","粤","桂","琼","川","贵","云","藏","陕","甘","青","宁","新","军","使"]
number = [str(i) for i in range(0, 10)] # 0 到 9 的数字
alphabet = [chr(i) for i in range(65, 91)] # A 到 Z 的字母
char_set = char_enum + number + alphabet
char_set_len = len(char_set)
label_name_len = len(classeNames[0])
#将字符串数据化
def text2vec(text):
vector = np.zeros([label_name_len, char_set_len])
for i, c in enumerate(text):
idx = char_set.index(c)
vector[i][idx] = 1.0
return vector
all_labels = [text2vec(i) for i in classeNames]1.5 加载数据文件
代码如下:
'''
1.5 加载数据文件
'''
class MyDataset(data.Dataset):
def __init__(self, all_labels, data_paths_str, transform):
self.img_labels = all_labels #获取标签信息
self.img_dir = data_paths_str #图像目录路径
self.transform = transform #目标转换函数
def __len__(self):
return len(self.img_labels)
def __getitem__(self, index):
image = Image.open(self.img_dir[index]).convert('RGB')
# plt.imread(self.img_dir[index]) # 使用 torchvision.io.read_image 读取图像
label = self.img_labels[index] # 获取图像对应的标签
if self.transform:
image = self.transform(image)
return image, label
total_datadir = './03_traffic_sign/'
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std =[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = MyDataset(all_labels, data_paths_str, train_transforms)
print(total_data)打印输出:<__main__.MyDataset object at 0x000001ADA417A160>
1.6 划分数据
1)取全部数据的80%作为训练集、剩下的20%作为测试集,并随机分割数据集为训练集测试集
torch.utils.data.random_split(dataset, lengths, generator=<torch._C.Generator object>)
随机将一个数据集分割成给定长度的不重叠的新数据集。可选择固定生成器以获得可复现的结果(效果同设置随机种子)。
dataset (Dataset) – 要划分的数据集。
lengths (sequence) – 要划分的长度。
generator (Generator) – 用于随机排列的生成器。
2)加载训练数据器和测试数据器
代码如下:
'''
1.6 划分数据
'''
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_size, test_size)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=16,
shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=16,
shuffle=True)
print("The number of images in a training set is: ", len(train_loader)*16)
print("The number of images in a test set is: ", len(test_loader)*16)
print("The number of batches per epoch is: ", len(train_loader))
for X, y in test_loader:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break输出结果:
10940 2735
The number of images in a training set is: 10944
The number of images in a test set is: 2736
The number of batches per epoch is: 684
Shape of X [N, C, H, W]: torch.Size([16, 3, 224, 224])
Shape of y: torch.Size([16, 7, 69]) torch.float64
二、自建模型
2.1 模型说明
模型是由输入层、卷积层和批归一化层、池化层、全连接层和一个自定义重塑层构成的,其中卷积层和批归一化层是有四层的
Input: [batch_size, 3, height, width]
|
Conv2d (3 -> 12, kernel_size=5, stride=1, padding=0) -> BatchNorm2d -> ReLU
|
Conv2d (12 -> 12, kernel_size=5, stride=1, padding=0) -> BatchNorm2d -> ReLU
|
MaxPool2d (kernel_size=2, stride=2)
|
Conv2d (12 -> 24, kernel_size=5, stride=1, padding=0) -> BatchNorm2d -> ReLU
|
Conv2d (24 -> 24, kernel_size=5, stride=1, padding=0) -> BatchNorm2d -> ReLU
|
MaxPool2d (kernel_size=2, stride=2)
|
Flatten (24 * 50 * 50)
|
Linear (24*50*50 -> label_name_len * char_set_len)
|
Reshape [batch_size, label_name_len, char_set_len]
|
Output: [batch_size, label_name_len, char_set_len]2.2 模型搭建代码
代码如下:
#二、自建模型
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2, 2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24 * 50 * 50, label_name_len * char_set_len)
self.reshape = Reshape([label_name_len, char_set_len])
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24 * 50 * 50)
x = self.fc1(x)
# 最终reshape
x = self.reshape(x)
return x
#定义Reshape层
class Reshape(nn.Module):
def __init__(self, shape):
super(Reshape, self).__init__()
self.shape = shape
def forward(self, x):
return x.view(x.size(0), *self.shape)
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
print(model)
模型打印输出如下:
Using cuda device
Network_bn(
(conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))
(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))
(bn2): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv4): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(bn4): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv5): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))
(bn5): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc1): Linear(in_features=60000, out_features=483, bias=True)
(reshape): Reshape()
)
2.3 模型结构查看
代码如下:
import torchsummary
'''显示网络结构'''
torchsummary.summary(model, (3, 224, 224))需要注意一点:
本次模型的输出是[-1,7,69],但是之前的网络结构输出是两维数据
这里的-1是代表对于不确定的维度大小可以在计算中自动推断它,
-1告诉 PyTorch 在计算中自动推断这个维度的大小,以确保其他维度的尺寸不变,并且能够保持张量的总大小不变。例如,
[-1, 7, 69]表示这个张量的形状是一个三维张量,其中第一个维度的大小是不确定的,第二维大小为7,第三大小分别为69。-1的作用是使得总的张量大小等于7 * 69,以适应实际的输入数据大小后续在更新准确率的过程中也会因为这里的不同导致代码的设定和前面不一样
输出如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 12, 220, 220] 912
BatchNorm2d-2 [-1, 12, 220, 220] 24
Conv2d-3 [-1, 12, 216, 216] 3,612
BatchNorm2d-4 [-1, 12, 216, 216] 24
MaxPool2d-5 [-1, 12, 108, 108] 0
Conv2d-6 [-1, 24, 104, 104] 7,224
BatchNorm2d-7 [-1, 24, 104, 104] 48
Conv2d-8 [-1, 24, 100, 100] 14,424
BatchNorm2d-9 [-1, 24, 100, 100] 48
MaxPool2d-10 [-1, 24, 50, 50] 0
Linear-11 [-1, 483] 28,980,483
Reshape-12 [-1, 7, 69] 0
================================================================
Total params: 29,006,799
Trainable params: 29,006,799
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 26.56
Params size (MB): 110.65
Estimated Total Size (MB): 137.79
三、模型训练
3.1 优化器与损失函数
代码如下:
#三、模型训练
'''
3.1 优化器与损失函数
'''
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=0.0001)
loss_model = nn.CrossEntropyLoss()3.2 训练函数和测试函数
代码如下:
'''
3.2 训练函数和测试函数
'''
import torch
from torch.autograd import Variable
def test(model, test_loader, loss_model):
size = len(test_loader.dataset)
num_batches = len(test_loader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in test_loader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_model(pred, y).item()
# 计算准确率_它计算了在一个批次(batch)中,模型预测的标签与真实标签相同的数量占总数量的比例
# 假设这里是多类分类任务
#pred_labels = torch.argmax(pred, dim=-1) # [batch, 7]
#true_labels = torch.argmax(y, dim=-1) # [batch, 7]
#correct += (pred_labels == true_labels).float().sum().item() / (y.size(1) * y.size(0))
test_loss /= num_batches
#accuracy = correct / size
print(f"Avg loss: {test_loss:>8f} \n")
#print(f"Avg accuracy: {accuracy:>8f} \n")
return correct, test_loss
def train(model, train_loader, loss_model, optimizer):
model = model.to(device)
model.train()
for i, (images, labels) in enumerate(train_loader, 0): # 0是标起始位置的值。
images = Variable(images.to(device))
labels = Variable(labels.to(device))
optimizer.zero_grad()
outputs = model(images)
loss = loss_model(outputs, labels)
loss.backward()
optimizer.step()
if i % 1000 == 0:
print('[%5d] loss: %.3f' % (i, loss))
3.3 正式训练
代码如下:
'''
3.3 模型的训练
'''
test_acc_list = []
test_loss_list = []
epochs = 30
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model,train_loader,loss_model,optimizer)
test_acc,test_loss = test(model, test_loader, loss_model)
test_acc_list.append(test_acc)
test_loss_list.append(test_loss)
print("Done!")训练过程打印如下:
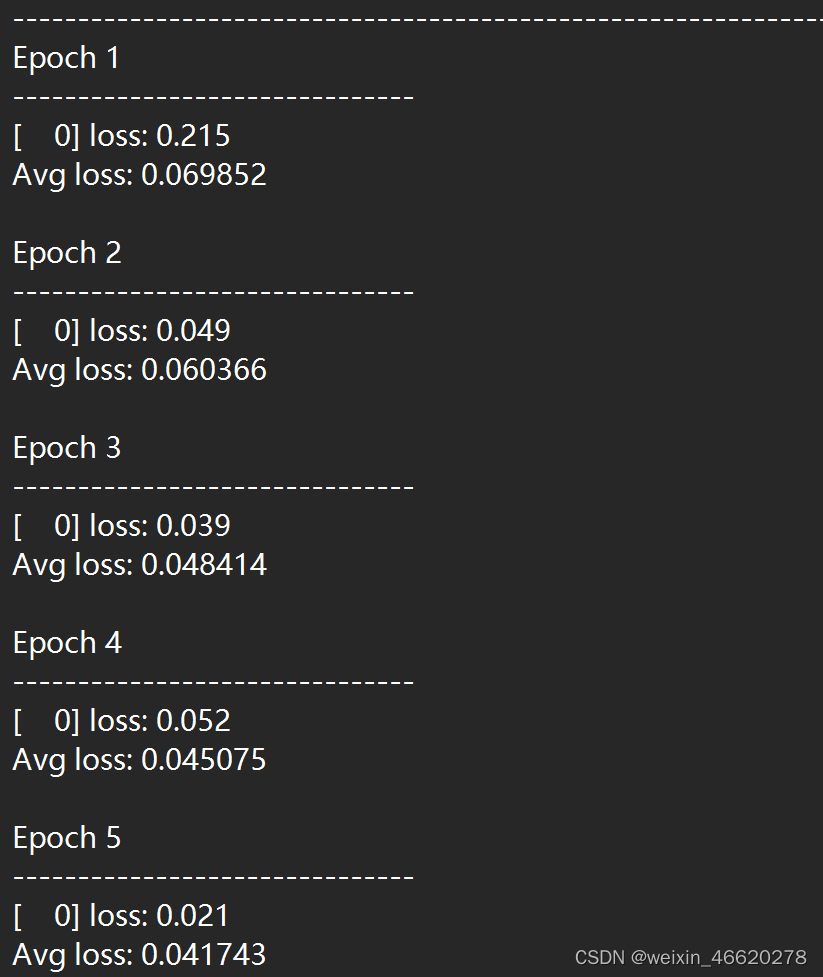
...

四、结果分析
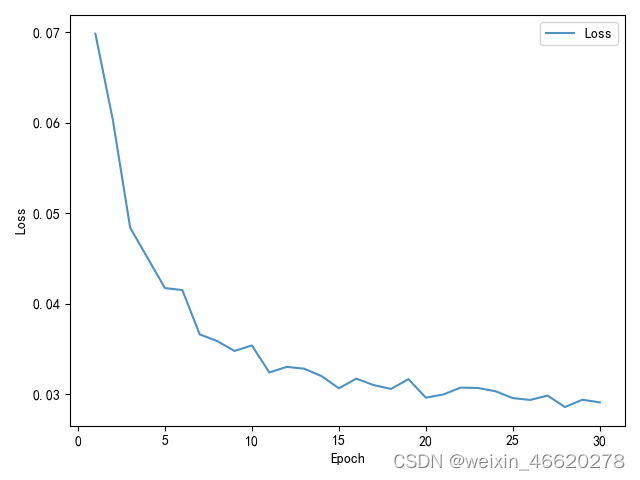
这里对测试集上的loss进行可视化
#四、结果分析
x = [i for i in range(1, 31)]
plt.plot(x, test_loss_list, label='Loss', alpha=0.8)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()输出图如下:
五、拔高尝试
增加对test_acc的统计更新
代码修改如下:
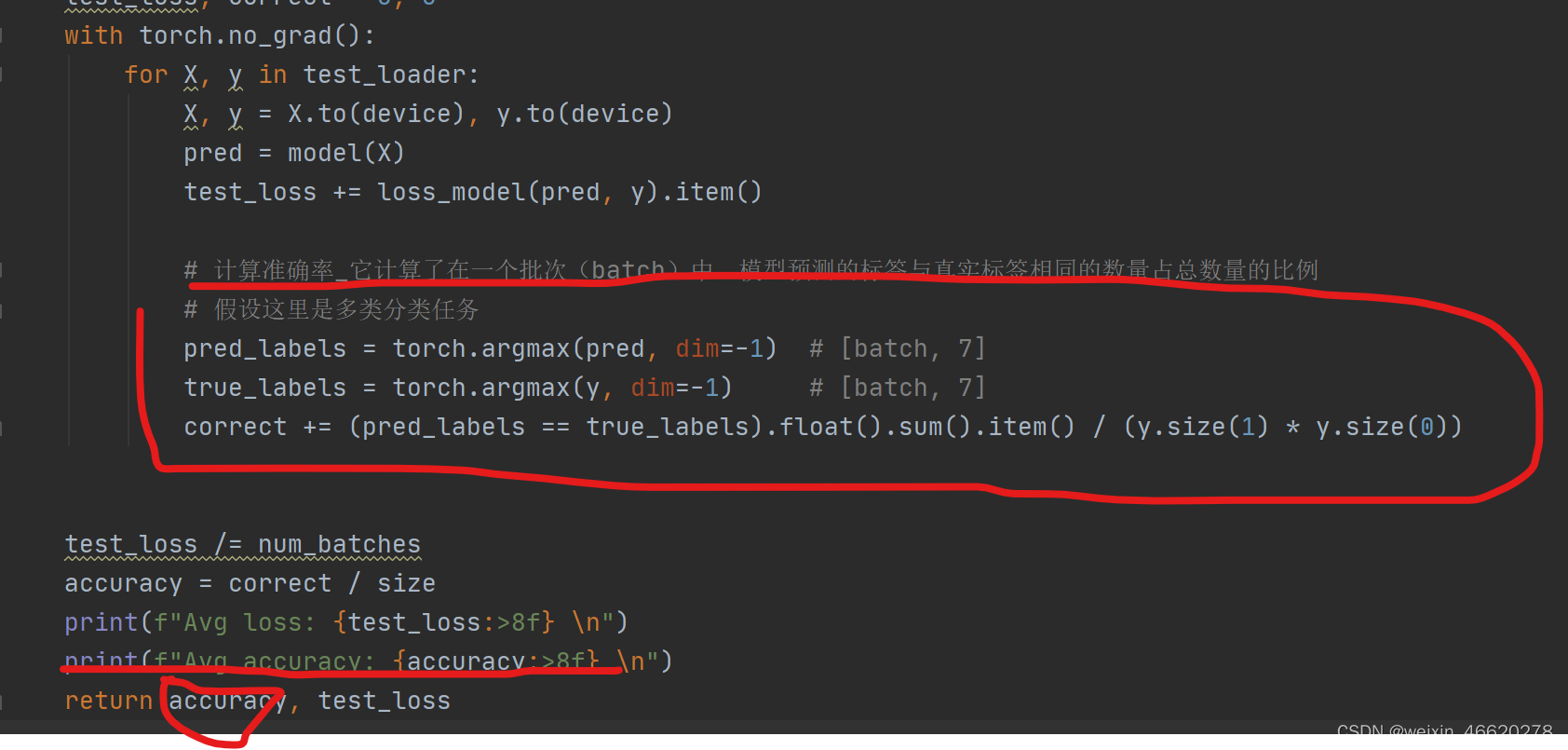
训练过程打印为:能达到65%左右的准确率

总结
- 学会了自己搭建Mydataset的方法
- 尝试对test_acc进行统计更新,由于这里涉及到模型输出维度是多维的和之前的二维的输出不同,这里计算了在一个批次(batch)中,模型预测的标签与真实标签相同的数量占总数量的比例















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









