







一、查找
- 查找可以分为两个方面进行阐述。一是数据通过查找表的方式进行组织。二是查找方法的选择进行查找。
- 对查找表可以进行查找、检索、插入、删除等操作。
- 查找表可以分为静态查找表和动态查找表。静态查找表仅支持只读。动态查找表还支持插入、删除的操作。
- 查找表通过关键字比较进行查找。
平均查找长度(比较查找效率)
ASL=p1c1+p2c2+…+pncn;
pi:第i个元素的概率
ci:第i个元素需要比较的次数
常见的查找算法
顺序查找
二分查找
索引查找
哈希查找
二、顺序查找
从表中指定位置开始将关键字与记录进行比较,若相等则查找成功。
int seqsearch(DataType R[], key) {
int i = R.length;
if (!R[0]){
int tmp;
tmp = R[0];
R[0] = key;
while (R[i] != key){
i = i - 1;
}
R[0] = tmp;
}else
{
R[0] = key;
while (R[i] != key){
i = i - 1;
}
R[0] = NULL;
}
return i;
}
算法评价
空间复杂度O(1)
时间复杂度:最好情况O(1),最坏情况O(n),平均情况O(n)
三.折半查找
折半查找要求表是有序表
只适用于顺序结构
将待查关键字与有序表中间位置的记录进行比较,若相等查找成功。否则根据大小情况到表的前后半部分进行比较查找
代码如下(示例):
int BinarySearch(DataType SL[], KeyType key, int n) {
int low = 1;
int high = n;
while (low<=high){
int mid = (low + high) / 2;
if (key==SL[mid]){
return mid;
}
else if (key>SL[mid]){
low = mid + 1;
}
else{
high = mid - 1;
}
return 0;
}
}
算法评价:
折半查找效率高
平均查找性能与最坏情况接近
只适用于顺序结构
四.索引查找
对于那些数据量庞大且无序的记录通常使用索引查找配合顺序或折半查找来进行。
- 建立索引
- 快速定位
- 顺序或折半查找
索引表的构建
- 分块
- 建立索引项:关键字项:记录该块中最大关键字值。指针项:记录该块第一个记录在表中的位置。
- 所有索引项组成索引表

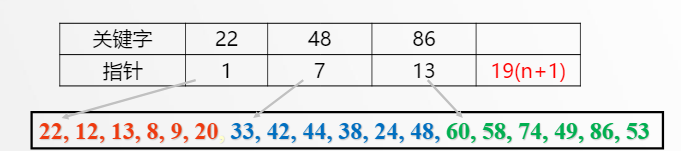
// 索引表结构
typedef struct IndexType {
KeyType key;
int link;
};
//索引表顺序查找法
int IndexSequelSeach(IndexType ls[], DataType s[], int m, KeyType key) {
int i = 0;
while (i<m&&key>ls[i]){
i++;
}
if (i==m){
return -1;
}
//表内
else{
int j = ls[i].link;
while (key!=s[j]&&j<ls[i+1].link){
j++;
}
if (key==s[j]){
return j;
}
else {
return - 1;
}
}
}
5.哈希查找
- 哈希查找是建立在哈希表的基础上进行的。
- 哈希表是根据设定的哈希函数再加上处理冲突的方法,将一组关键字映射到一个地址的连续地址空间上。
- 也就是说我们可以通过关键字+哈希函数,直接得到记录所存储的地址值。直接读取记录
5-1哈希函数
构造哈希函数方法:
直接哈希函数:取关键字本身或关键字的某个线性函数值作为哈希地址
数字分析法:选取关键字中某些位数上关键字均匀分布的数字组合起来作为哈希地址
平方取中法:取平方后的中间几位作为哈希地址
折叠法:针对关键字位数较长时,可将关键字分割成位数相等的几部分。取它们的叠加和(舍去高位的进位)作为哈希地址。
除留取余法:除p取余。p的选择很重要
随机数法
5-2字符串哈希查找
利用关键字ASCLL码的和+取余法来求得哈希地址
通过关键字位数转移和仔细地寻找关键字规律
5-3冲突处理
开放地址法
再哈希法
链地址法
公共溢出区法
1.开放地址法
H0=H(key)
Hi=(H(key)+di) %m i=1,2,3,4
{Hi为第i次冲突的地址;H(key)为hash函数值;m为Hash表长;di为增量序列;}
线性探测再散列di=c*i
平方探测再散列di=12,22,32
随即探测再散列di伪随机
2.再哈希法
将n个不同哈希函数排成一个序列,当发生冲突时,由RHi确定第i次冲突的地址Hi。
Hi=RHi(key) i=1,2,3…n
RHi为不同哈希函数
3.链地址法

4.公共溢出区法

5-4哈希表构建
Status SearchHash(HashTable H, KeyType key, int& p, int& c) {
p = Hash(k);
while (H.data[p].key!=NULL&&H.data[p].key!=key)
collision(p, ++c);
if (H.data[p].key==key)
{
return true;
}
else {
return false
}
}
Status InsertHash(HashTable& H, DataType e) {
c = 0;
if (SearchHash(H,e.key,p,c)
return false;
else if(c<hashsize[H.sizeindex]/2)
{
H.data[p]=e;
++H.count;
return true;
}
else
{
RecreatHashTable(H);
return true;
}
}















 82
82











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









