






一. 相关知识
数据报告 :
- 传统零售 : - 代理商 : 压货 挣差价 - 层层分级别
- 网络零售 : - 代运营 : 了解代理品牌 了解品类市场 竞品
- 数据报告 PPT(活动) (日报EXCEL 周报 月报)
二. 读取数据(循环一次性读取下列文件)
'.\\灭鼠杀虫剂市场近三年交易额.xlsx' '.\\电蚊香套装市场近三年交易额.xlsx' '.\\盘香灭蟑香蚊香盘市场近三年交易额.xlsx' '.\\蚊香加热器市场近三年交易额.xlsx' '.\\蚊香液市场近三年交易额.xlsx' '.\\蚊香片市场近三年交易额.xlsx' '.\\防霉防蛀片市场近三年交易额.xlsx'
import os
os.chdir("./data/驱虫剂市场") # 这是更改当前目录
1. 获取 ...交易额的所有 .xlsx文件名称
files = glob.glob("./*交易额.xlsx")
/*
'.\\灭鼠杀虫剂市场近三年交易额.xlsx'
'.\\电蚊香套装市场近三年交易额.xlsx'
'.\\盘香灭蟑香蚊香盘市场近三年交易额.xlsx'
'.\\蚊香加热器市场近三年交易额.xlsx'
'.\\蚊香液市场近三年交易额.xlsx'
'.\\蚊香片市场近三年交易额.xlsx'
'.\\防霉防蛀片市场近三年交易额.xlsx'
*/
2. 读取数据,
dfs = []
for f in files: # f是上面每个文件的名字
df = pd.read_excel(f) # 读取每一个数据
# 现在的时间列数据类型是int64,我们想把它改为时间类型
if df.时间.dtype == "int64":
#unit是单位是天, origin是开始时间
df["时间"] = pd.to_datetime(df.时间,unit="D",origin=pd.Timestamp("1899-12-30"))
# 将 时间列 作为 index,行标签
df.set_index(["时间"],inplace = True)
# t是把 "灭鼠杀虫剂市场近三年交易额"通过 市场进行分割, 然后得到 灭鼠杀虫剂
t = f.split("市场")[0][2:]
df.columns = [t + "交易金额"] #灭鼠杀虫剂 与 交易金额 拼接
# dfs 里面就是标题为 灭鼠杀虫剂交易金额,和类似这种的数据
dfs.append(df)
#dfs是一个标题一组数据,一共有七个 排成一列的 列表,
# concat 把每组数据拼接起来, axis = 1 进行横向拼接,行索引是年,每一列就是各种交易金额
df = pd.concat(dfs,axis=1)
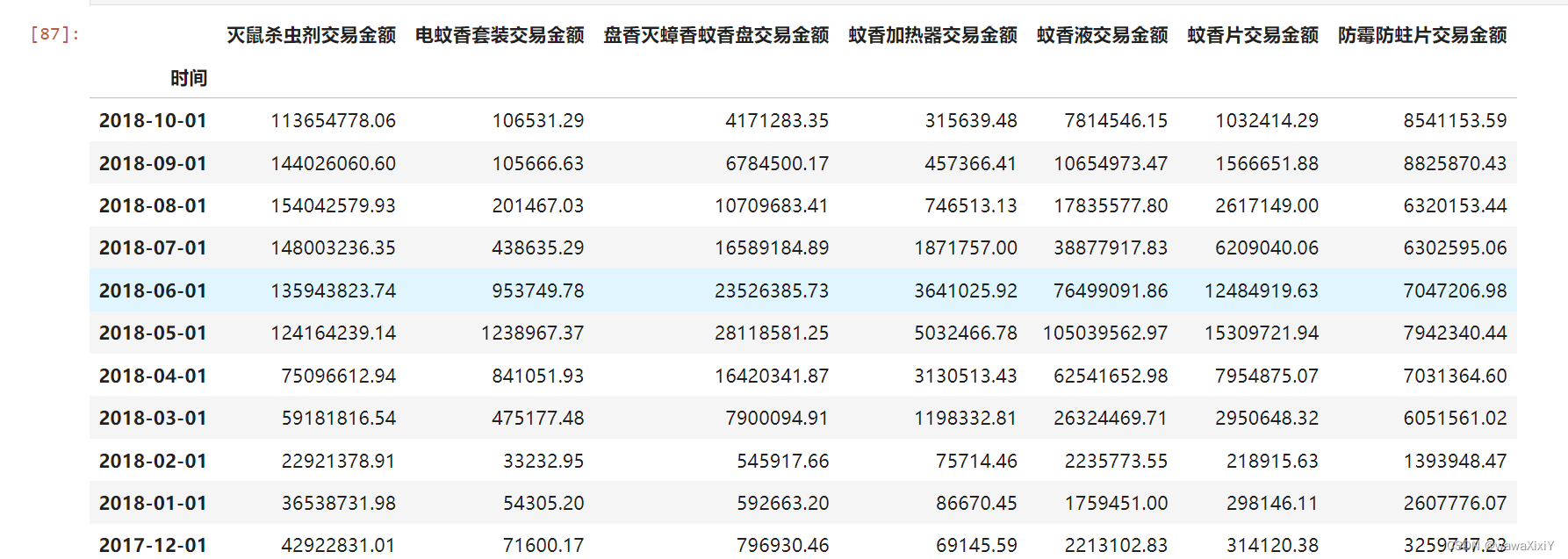
三. 检测数据(空值、数据类型、绘图看趋势)
df.isnull().sum()
灭鼠杀虫剂交易金额 0
电蚊香套装交易金额 0
盘香灭蟑香蚊香盘交易金额 0
蚊香加热器交易金额 0
蚊香液交易金额 0
蚊香片交易金额 0
防霉防蛀片交易金额 0
dtype: int64
df.dtypes
灭鼠杀虫剂交易金额 float64
电蚊香套装交易金额 float64
盘香灭蟑香蚊香盘交易金额 float64
蚊香加热器交易金额 float64
蚊香液交易金额 float64
蚊香片交易金额 float64
防霉防蛀片交易金额 float64
dtype: object
df.plot()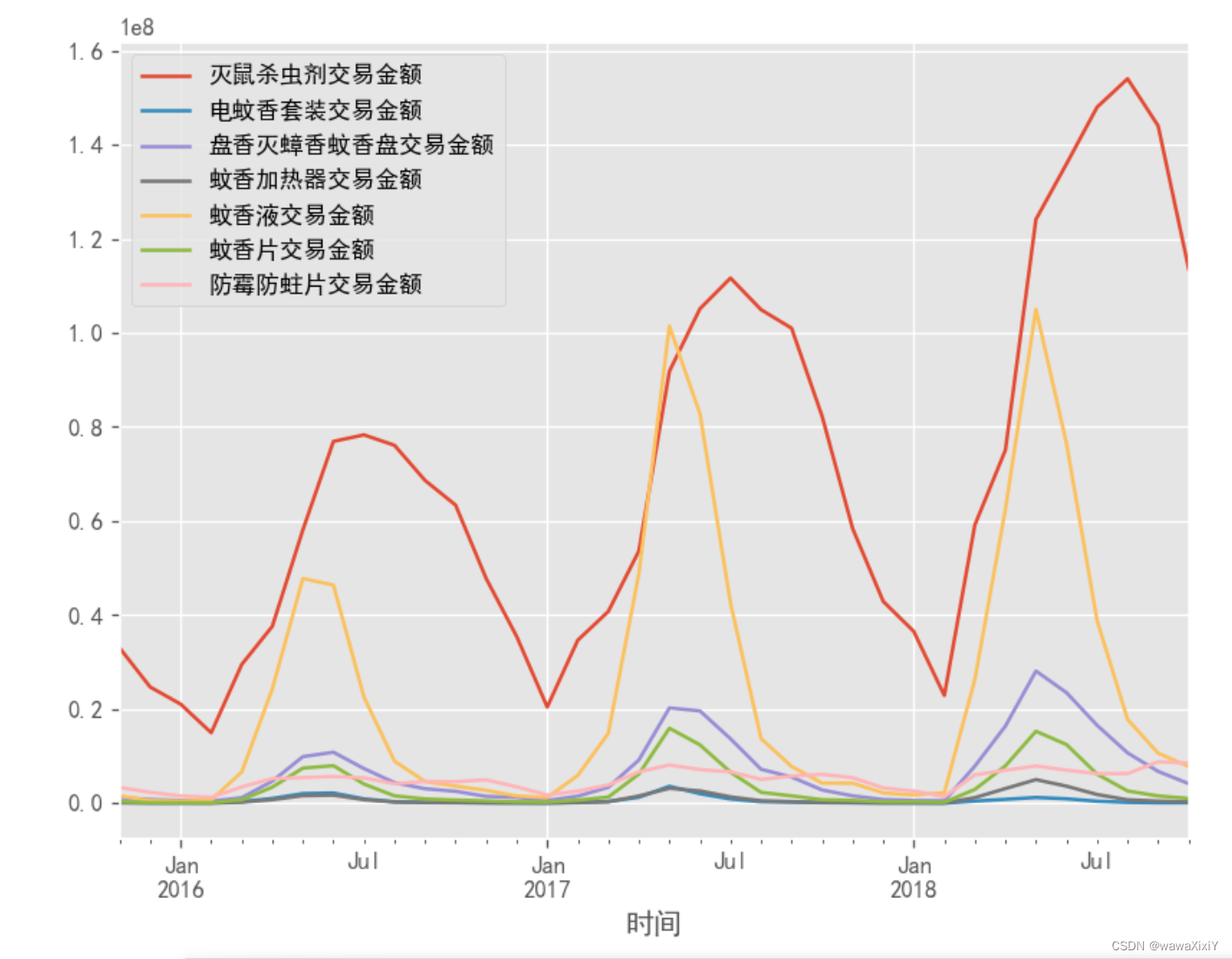
四. 简单的线性回归说明
X = np.array([
[1,1],
[2,4]
])
y = np.array([
[35],
[94]
])
y = wx
- 线性代数 当中 矩阵 没有除法计算
- 矩阵 有乘法
- 矩阵的倒数 叫做逆矩阵 (只有方阵 才能求逆)
- ((XTX)^-1 XTX)单位矩阵是 线性代数当中 的 1
- XT .X X.XT 都是当前矩阵的平方 (方阵)
y = w x
(XTX)^-1 XT y = w (XTX)^-1 XTX
w = (XTX)^-1 XT y
#先把任何形状的矩阵转变为方阵
XTX = np.dot(X.T,X)
#求出方阵的 逆矩阵
INV = np.linalg.inv(XTX)
np.dot(INV,X.T)from sklearn.linear_model import LinearRegression #线性回归
# fig_intercept=False 这个就是y=kx + b 时 没有这个b
model = LinearRegression(fig_intercept=False).fit(X,y)
model.coef_ # 回归系数 计算k的五 . 预测数据
def predict(df=None, year=None ,month=None):
df = df.reset_index()
df["年份"] = df["时间"].dt.year
df["月份"] = df["时间"].dt.month
# x 代表 预测的依据(根据什么来的) y是结果
X_train = df.query(f"月份 == {month}")[["年份","月份"]] # 比如我要预测2018年11月的,这里记录的是依据往年 的11月数据
y_train = df.query(f"月份 == {month}").iloc[:,1:-2] # 这里记录的就是 7个交易金额列
#预测的时间
X_pred = np.array([[year,month]]) #array([[2018, 11]])
#拼接时间格式(因为现在X_pred 没有正式的时间格式,自己建立)
y_index = [datetime(year,month,1)] # 这是 最后拼接的结果 第一列时间 后面都是交易金额 ["2018-11-01",1,2,3,4,5,6,7]
for i in range(y_train.columns.size): # y_train 就是那7列 交易金额
y_tra = y_train.iloc[:,i] # 每次循环出 一列 交易金额,一次一列
model = LinearRegression().fit(X_train,y_tra) #预测 会记录 系数 和偏置项
#预测的结果
y_pred = model.predict(X_pred) #预测就是给时间 返回 金额值
y_index.append(y_pred[0]) #list
df.drop(columns=["年份","月份"],inplace=True)
new_df = pd.DataFrame(pd.Series(y_index,index=df.columns)).T
return pd.concat([new_df,df]).set_index("时间")
先预测 2018 11 和 12 月份数据
df = predict(df,year=2018,month=11)
df = predict(df,year=2018,month=12)
2019 - 2027年的数据
year = range(2019,2022)
month = range(1,13)
for y in year:
for m in month:
df = predict(df,year=y,month=m)
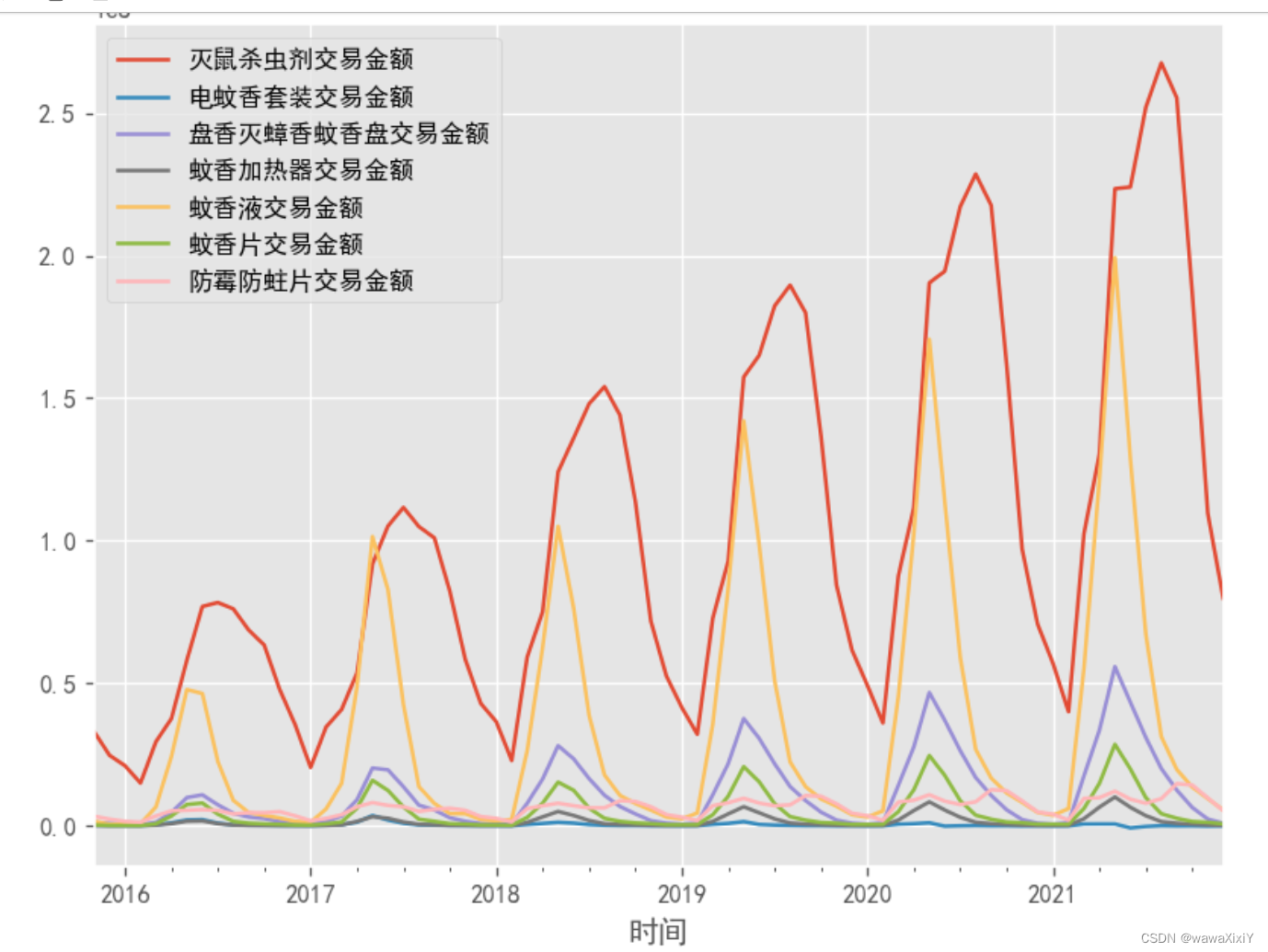
df.plot()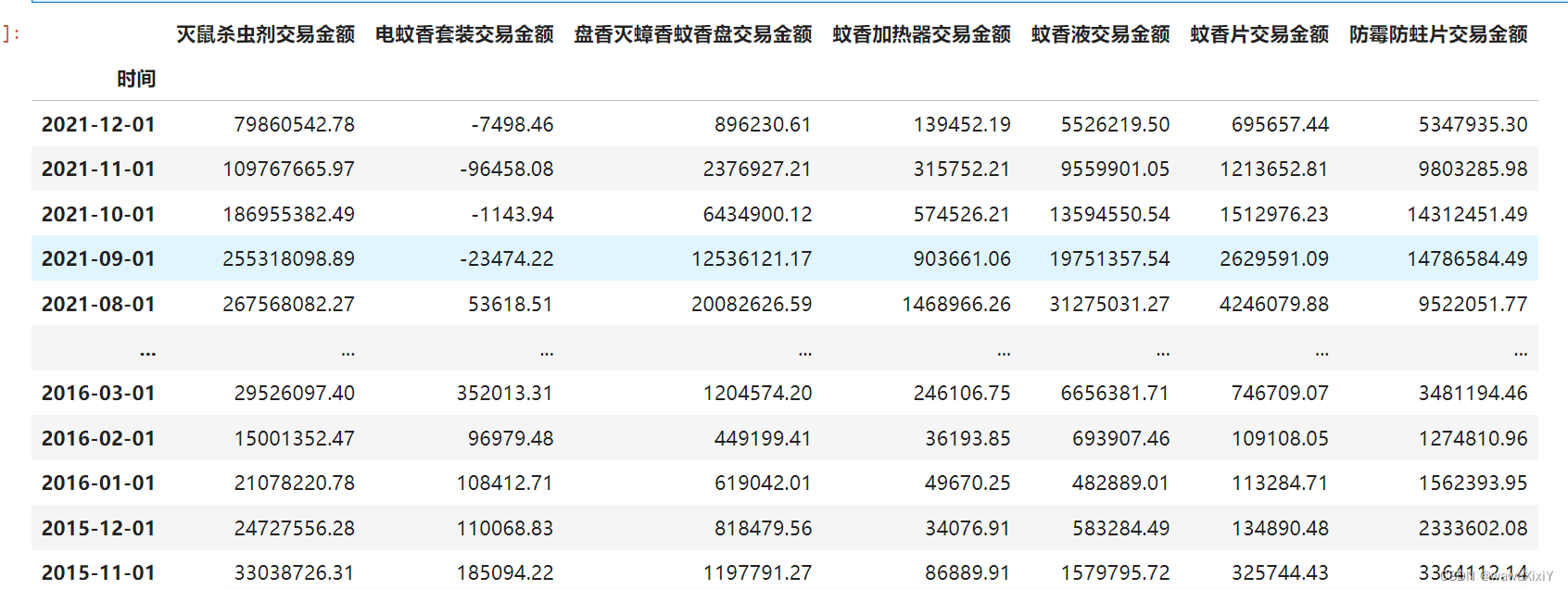
六. 市场容量
1. 数据
计算每年 每一列 金额总和
dfgp = df.reset_index().groupby(by=[df.reset_index().时间.dt.year])[df.columns].sum()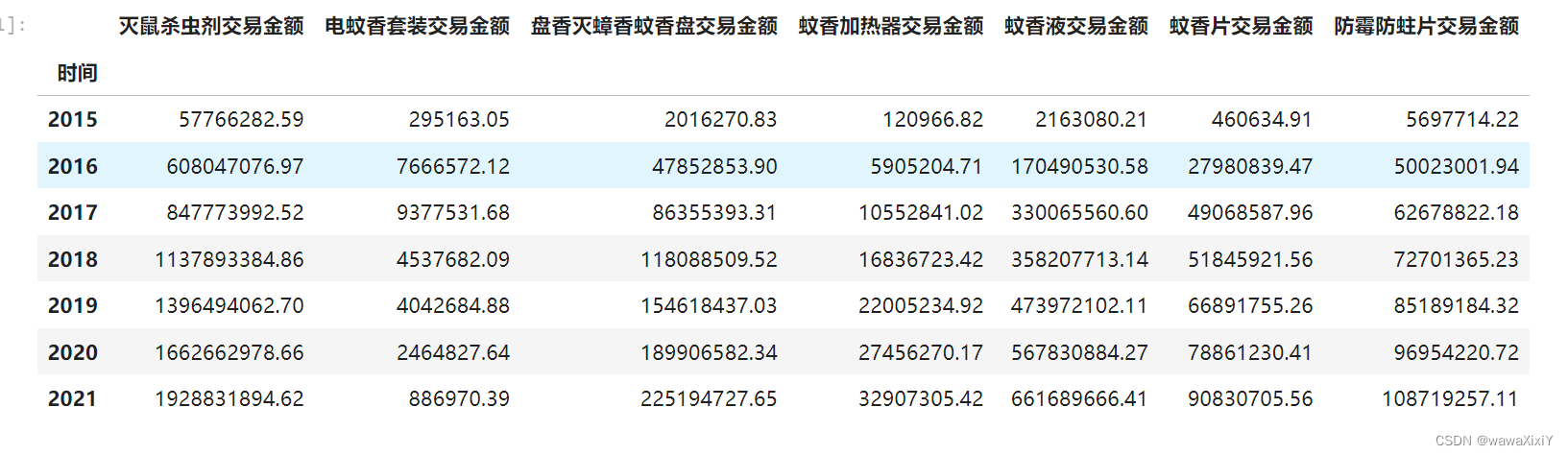
将上列 每一年 进行横向计算
dfgp["总额"] = dfgp.sum(axis=1)dfgp.style.format("¥{:,.2f}",na_rep="-")
xinds = range(dfgp.index.size)
plt.bar(xinds,dfgp.总额)
plt.xticks(xinds,dfgp.index)
#把增长率放到 注释中
for a,b in list(zip(xinds,list(zip(dfgp.总额,dfgp.总额.pct_change().fillna(0) )))):
plt.text(a-0.35,b[0],s=f"同比增长率:{round(b[1]*100,2)}%\n年销售额:{round(b[0],2)}")
plt.title("2015~2021灭鼠杀虫市场容量和增长率")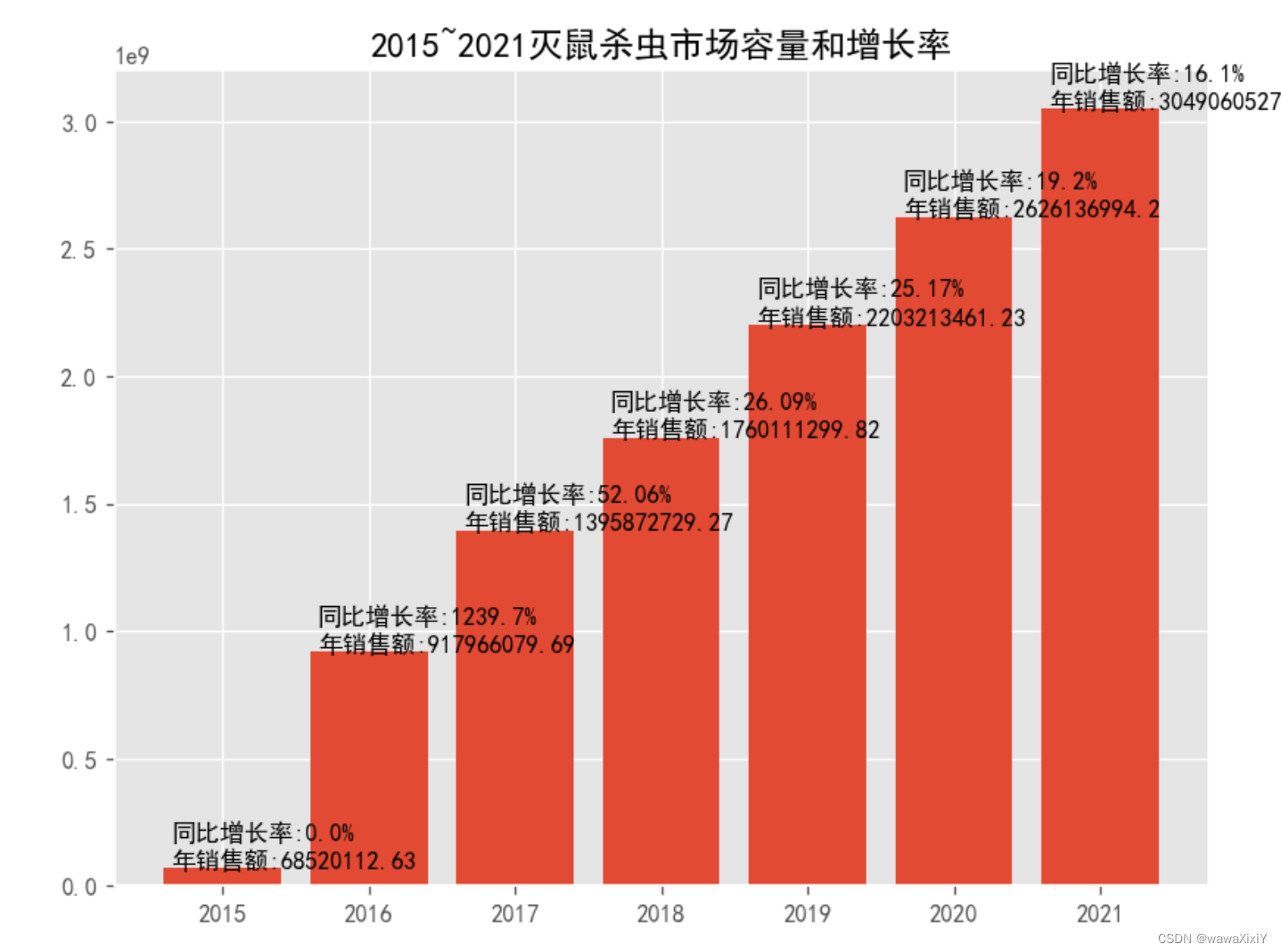
如果企业的增幅 低于 GDP 说明公司业绩在下降 如果企业的增幅 持平 GDP 说明公司业绩持平 企业的增幅速度 必须 要大于GDP 才是健康状态
市场的份额逐渐扩大,增长率逐步减缓 ,说明增量市场 逐步转化 存量市场
七.细分市场的趋势(每一列都进行绘图)
xinds = range(dfgp.shape[0]) #行数
colors = sns.color_palette("rainbow",dfgp.shape[0])
#局部调节
plt.figure(figsize=(20*2,10*4)) #第一个参数是列 第二参数是行
#多图型绘制方法
i=1
for c in dfgp.columns[:-1]:
#第一个参数是行数 第二个参数是列数 ,第三个参数是画布的编号(必须从1开,编号不能一致)
axes = plt.subplot(4,2,i) #返回的是一个画布对象
data = dfgp.reset_index().loc[:,["时间",c]]
sns.barplot(data=data,x="时间",y=c,ax=axes,color=colors[i-1])
sns.pointplot(data=data,x="时间",y=c,ax=axes)
axes.set_title(c)
for a,b in list(zip(xinds,list(zip(dfgp[c],dfgp[c].pct_change().fillna(0) )))):
plt.text(a-0.35,b[0],s=f"同比增长率:{round(b[1]*100,2)}%",fontsize=20)
i+=1
plt.savefig("./1.png")八. 细分市场的占比
dfgp.iloc[:,:-1].div(dfgp.iloc[:,-1],axis=0)

dfgp.iloc[:,:-1].div(dfgp.iloc[:,-1],axis=0).plot(kind="bar",stacked=True)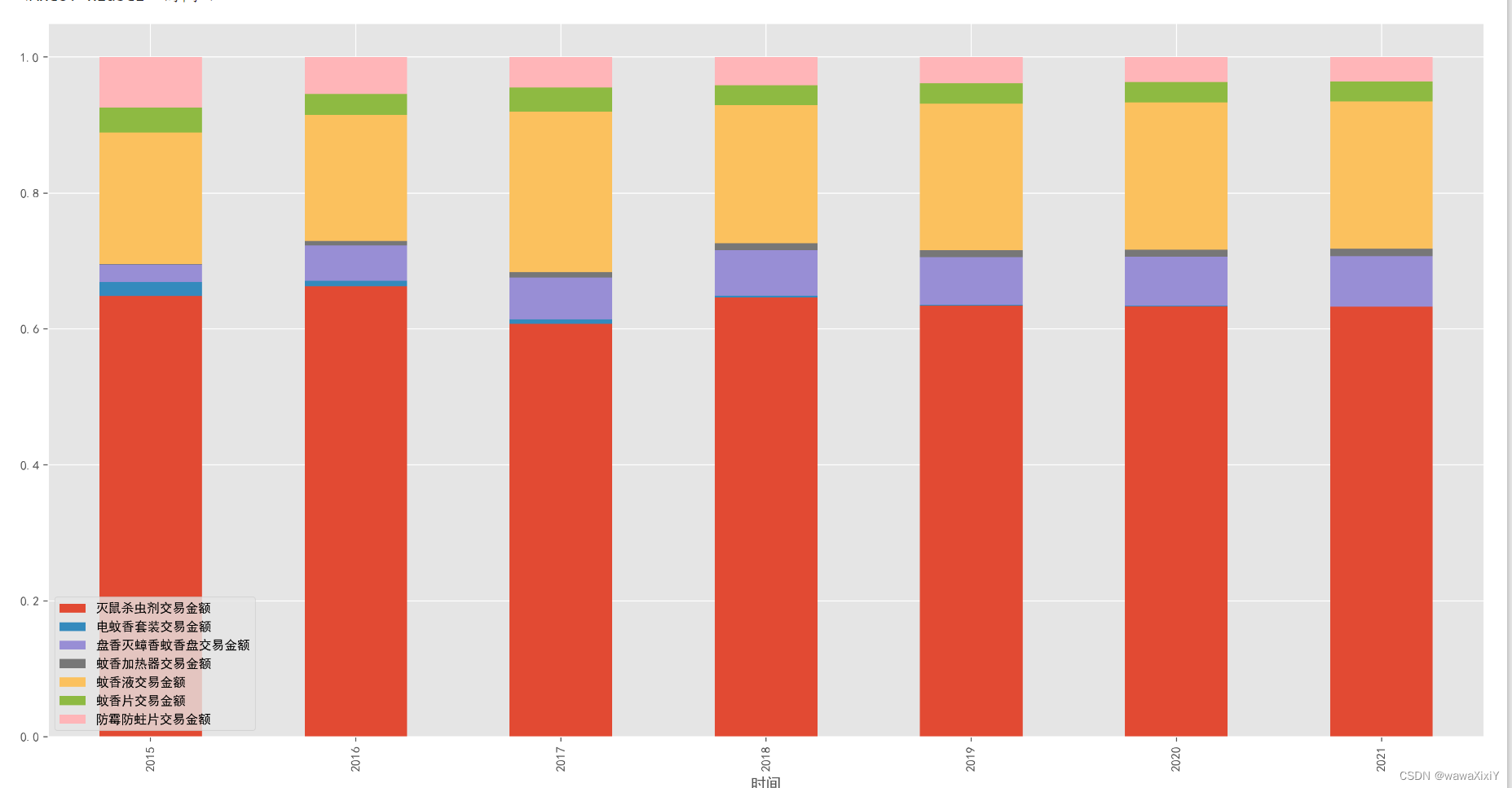
九.市场的竞争度
top100 = pd.read_excel("./top100品牌数据.xlsx").iloc[:,:-1]
#数据银行 : 交易指数 销售额 销售量 点击数 收藏量 .....
#交易指数 指数越大,说明 当前 产品的影响力 越大
top100["交易指数比"] = top100.交易指数.div(top100.交易指数.sum()) #总额百分比
top100["累计交易指数比"] = top100["交易指数比"].cumsum()plt.figure(figsize=(20,6))
axes1 = plt.gca()
sns.barplot(top100,x="品牌",y="交易指数比",ax=axes1,color="skyblue")
axes2 = axes1.twinx()
sns.pointplot(top100,x="品牌",y="累计交易指数比",ax=axes2,color="orange")
# axes1.set_xticks()
a = axes1.set_xticklabels(top100.品牌,rotation=90)
axes1.vlines(19+0.5,0,0.035,ls="--")
#累计图像当中会出现比较明显的 拐点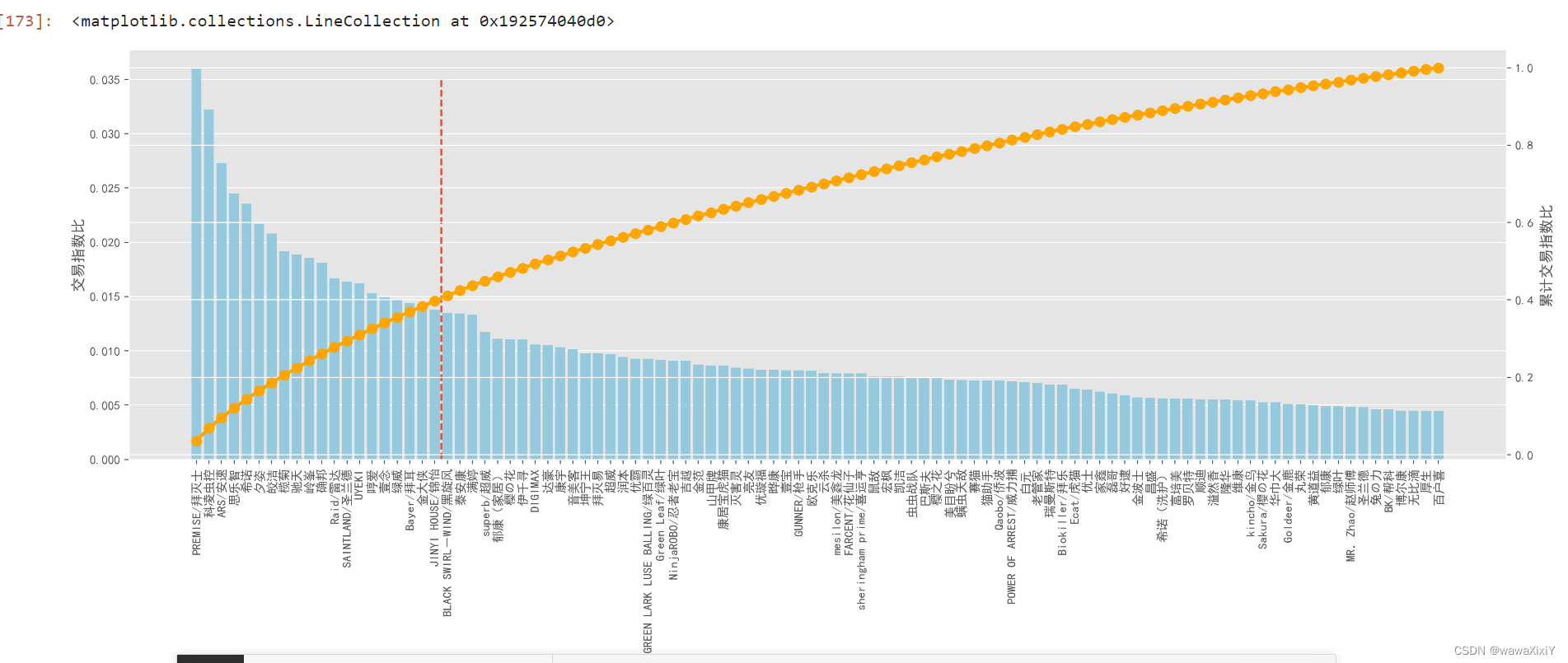
赫芬达尔赫希曼指数
- ΣS^2
- S : 市场占有份额(总额百分比)
- HHI :
- 小于0.01 : 高度自由竞争
- 小于0.15 : 垄断不集中
- 小于0.25 : 垄断高度集中
- 小于0.4 : 高度垄断
假设现在有100公司 期中有一家占据89%的份额 其它的99家平分11%的份额 假设现在有100公司 期中有一家占据50%的份额 其它的99家平分50%的份额 假设现在有100公司 期中有一家占据30%的份额 其它的99家平分70%的份额
.89**2 + (0.11/99)**2 * 99
0.7922222222222223
.5**2 + (0.5/99)**2 * 99
0.25252525252525254
.3**2 + (0.7/99)**2 * 99
0.09494949494949495
















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









