







文章目录
1.双流join的实现思路
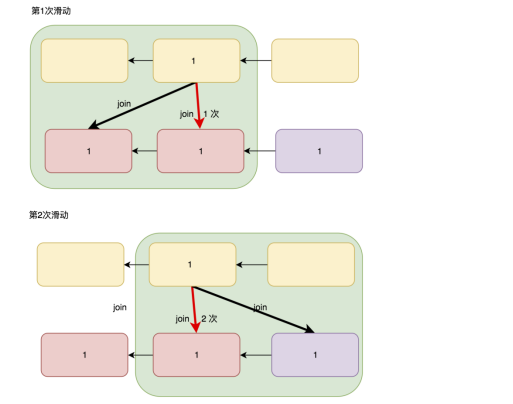
1.1 使用滑动window完成join
由于各种原因,两张表同时产生的时候,不能同批次得到,但是实际不会差太多批次,在join的时候,可以使用滑动窗口来覆盖多个批次,从而可以让同时产生的数据处于同一个窗口中。
但是会出现一条数据,出现在多个窗口中,需要把聚合后的数据做去重处理
1.2 使用缓存实现
Join的时候,如果在对方流的同批次中找不到数据,则可以去对方的缓存中查找,缓存必须是第三方的缓存,不能是spark-streaming中自己的内存,第三方缓存一般使用redis
2.升级BaseApp——多个topic多个流
package com.atguigu.realtime
import com.atguigu.realtime.util.{MyKafkaUtil_1, OffsetManager}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.json4s.CustomSerializer
import org.json4s.JsonAST.{JDouble, JInt, JLong, JString}
import scala.collection.mutable.ListBuffer
/**
同时消费多个topic,每个topic单个流
*/
abstract class BaseAppV3 {
//消费者组和主题
val master:String
val appName:String
val groupId :String
val topics:Seq[String]
val bachTime:Int
val toLong: CustomSerializer[Long] = new CustomSerializer[Long](ser = format => ({
case JString(s) => s.toLong
case JInt(s) => s.toLong
},{
case s:Long => JLong(s)
}))
val toDouble = new CustomSerializer[Double](ser = format => ({
case JString(s) => s.toDouble
case JDouble(s) => s.toDouble
},{
case s:Long => JDouble(s)
}))
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster(master).setAppName(appName)
val ssc: StreamingContext = new StreamingContext(conf, Seconds(bachTime))
//对比将多个topic放到一个流的存储方法:多个topic都在一个流中,所以不用区分是哪个流的偏移量
val offsetRanges: ListBuffer[OffsetRange] = ListBuffer.empty[OffsetRange]
//我们将不同topic的偏移量存在不同的流中,所以需要区分是哪个流哪个topic的偏移量,将其整成一个map集合,k值为topic
val offsetRanges: Map[String, ListBuffer[OffsetRange]] = topics.map(topic => (topic,ListBuffer.empty[OffsetRange])).toMap
//存储的是多个topic的offsets
val offsets: Map[TopicPartition, Long] = OffsetManager.readOffsets(groupId, topics)
topic.map (topic => {
//过滤出一个topic的偏移量
val currentTopicOffset:Map[TopicPartition,Long] = offset.filter(_._1.topic() == topic)
val stream:Dstream[ConsumerRecord[String,String]] = MykafkaUtil
//得到指定分区,指定主题,指定偏移量开始消费的流
.getKafkaStream(ssc,groupId,topic,currentTopicOffset)
//对其偏移量进行处理,将其偏移量保存下来
.transform(rdd => {
offsetRanges(topic).clear() //清空的时候也是指定清空某个topic的偏移量,而不会将所有偏移量全清理完
//将从kafka直接得到的数据进行强转,得到他的offsetRange,为新的偏移量
val newOffsetRanges:Array[OffsetRange] = rdd.asInstancdOf[HasOffsetRanges].offsetRange
//指定是哪个主题的偏移量
offsetRAnge(topic) ++= newOffsetRanges
rdd
/*
保存偏移量,将相同topic的value做reduce操作,拼接起来
OffsetManager.saveOffsets(offsetRangers.value.reduce(_ ++ _),groupId,topics)
*/
})
//返回某个主题和这个主题的数据
(topic,stream)
})
//转成一个不可变的map
.toMap
run(ssc,sourceStreams,offsetRanges: Map[String, ListBuffer[OffsetRange]])
ssc.start()
ssc.awaitTermination()
}
def run(ssc: StreamingContext,
sourceStream: Map[String, DStream[ConsumerRecord[String, String]]],
offsetRanges: Map[String, ListBuffer[OffsetRange]])
}
3.代码实现
3.1 将dwd层中order_info和order_detail的两个流的数据进行双流join
方法一、使用滑动窗口
创建类DwsOrderWideApp,继承升级的BaseApp,实现其run方法
override def run(ssc: StreamingContext,
sourceStream: Map[String,DStream[ConsumerRecord[String, String]]],
offsetRanges: Map[String, ListBuffer[OffsetRange]]): Unit ={
//获取dwd_order_info主题的数据,转换orderInfo的样例类类型
val orderInfoStream: DStream[(Long, OrderInfo)] = sourceStream("dwd_order_info").map(record => {
implicit val f = org.json4s.DefaultFormats
val orderInfo: OrderInfo = JsonMethods.parse(record.value()).extract[OrderInfo]
//将其封装成元组,便于后续join
(orderInfo.id, orderInfo)
})
//直接给流加窗口 window(窗口长度,滑动步长)滑动步长和时间都和产生数据的间隔时间相同
.window(Seconds(bachTime * 5),Seconds(bachTime))
//获取dwd_order_detail主题店数据,并将该主题的数据转成orderDetail格式的样例类
val orderDetailStream: DStream[(Long, OrderDetail)] = sourceStream("dwd_order_detail").map(record => {
implicit val f = org.json4s.DefaultFormats
val orderDetail: OrderDetail = JsonMethods.parse(record.value()).extract[OrderDetail]
//将其封装成元组,便于后续join
(orderDetail.order_id, orderDetail)
})
.window(Seconds(bachTime * 5),Seconds(bachTime))
//对两个流进行join,左连接和右连接都会丢数据,所以用全连接
val orderWideStream: DStream[OrderWide] = orderInfoStream.join(orderDetailStream)
.map {
//模式匹配,将同一个id的数据进行join
case (orderId, (orderInfo, orderDetail)) =>
//得到一个新的样例类,将其封装
new OrderWide(orderInfo, orderDetail)
}
//对数据进行去重,对每个分区的数据进项去重,读写redis使用set去重
orderWideStream
//一个分区的所有数据,每个分区去重,将来要返回集合,集合中的数据过滤掉一部分就是去重
.mapPartitions(orderWideIt =>{
//获取redis的客户端
val client: Jedis = MyRedisUtil.getClient
//过滤出指定key值的数据
val result: Iterator[OrderWide] = orderWideIt.filter(orderWide => {
val key = s"order_join_${orderWide.order_id}"
//使用order_detail_id去重,如果等于1,说明该订单详情已经存在
//存在的话就设置过期时间,返回值是1的时候返回
val r = 1 == client.sadd(key, orderWide.order_detail_id.toString)
if (r) client.expire(key, 60 * 30)
r
})
client.close()
result
})
}
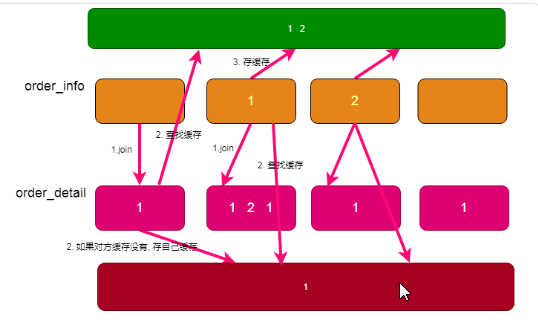
方法二、使用缓存
--order_info缓存类型:
容易存, 容易读
key value
"order_info:"+order_id OrderInfo的json字符串格式 {"": "", "": ""}
--order_detail缓存类型:
容易存, 容易读
key value
"order_detail:"+order_id value(hash)
field value
order_detail_id OrderDetail的json字符串格式 {"": "", "": ""}
//将数据orderinfo的数据存入redis
def cacheOrderInfo(client: Jedis, orderInfo: OrderInfo) = {
implicit val f = org.json4s.DefaultFormats
val key = s"order_info:${orderInfo.id}"
val value = Serialization.write(orderInfo)
//给orderInfo数据加上延迟时间
client.setex(key,60*10,value)
}
//将orderDetail的数据存入缓存
def cacheOrderDetail(client: Jedis, orderDetail: OrderDetail) ={
implicit val f =org.json4s.DefaultFormats
val key = s"orderDetail:${orderDetail.order_id}"
val field = orderDetail.id.toString
val value = Serialization.write(orderDetail)
//将orderdetail数据存入redis
client.hset(key,field,value)
}
"实现run方法"
override def run(ssc: StreamingContext,
sourceStream: Map[String, DStream[ConsumerRecord[String, String]]],
offsetRanges: Map[String, ListBuffer[OffsetRange]]): Unit = {
//得到两个流的数据
val orderInfoStream: DStream[(Long, OrderInfo)] = sourceStream("dwd_order_info").map(reduce => {
implicit val f = org.json4s.DefaultFormats
val orderInfo: OrderInfo = JsonMethods.parse(reduce.value()).extract[OrderInfo]
(orderInfo.id, orderInfo)
})
val orderDetailStream = sourceStream("dwd_order_detail")
.map(reduce => {
implicit val f =org.json4s.DefaultFormats
val orderDetail: OrderDetail = JsonMethods.parse(reduce.value()).extract[OrderDetail]
(orderDetail.order_id,orderDetail)
})
"================================================================================================================================="
//对两个流做满外连接
orderInfoStream
.fullOuterJoin(orderDetailStream)
//每个分区调用一次redis
.mapPartitions(it => {
implicit val f = org.json4s.DefaultFormats
val client: Jedis = MyRedisUtil.getClient
//最后返回的数据有可能为一个或者多个,这里用flatmap将数据拼接后压平
val result = it.flatMap {
case (orderId, (Some(orderInfo), Some(orderDetail))) => {
//将orderInfo存入缓存
cacheOrderInfo(client,orderInfo)
//和同批次的join
val orderWide: OrderWide = new OrderWide(orderInfo, orderDetail)
//读取对方缓存
val key = s"order_detail${orderId}"
val r= client.hgetAll(key).asScala
.map {
case (orderDetail, orderDetailStr) =>
val orderDetail: OrderDetail = JsonMethods.parse(orderDetailStr).extract[OrderDetail]
new OrderWide(orderInfo, orderDetail)
}
.toList
client.del(key)
orderWide :: r
}
"================================================================================================================================="
case (orderId, (Some(orderInfo), none)) => {
//把orderInfo的数据存入缓存,定义一个方法,将数据存入orderInfo的缓存
cacheOrderInfo(client, orderInfo)
//流中没有orderDetail的数据,去orderDetail的缓存中找数据,怎么取由怎么存决定
//获取key值
val key: String = s"order_detail:${orderId}"
//通过key值获取它所有的数据
val r = client.hgetAll(key).asScala
.map {
case (orderDetailId, orderDetailStr) =>
//将读取到的数据封装成orderDetail样例类类型的数据
val orderDetail: OrderDetail = JsonMethods.parse(orderDetailStr).extract[OrderDetail]
new OrderWide(orderInfo, orderDetail)
}
//将数据转换成list格式
.toList
//join完之后要将缓存清空
client.del(key)
r
}
"================================================================================================================================="
case (orderId, (none, Some(orderDetail))) => {
//这种情况流中没有orderInfo的数据,我们取缓存看看有没有
//通过key值取出order_info的缓存
val orderInfoStr: String = client.get(s"order_info:${orderId}")
//判断是否为空,不为空,将缓存数据与信赖的orderDetail的数据join
if (orderInfoStr != null) {
//将读取到的orderInfoStr的数据封装成orderInfo样例类格式
val orderInfo: OrderInfo = JsonMethods.parse(orderInfoStr).extract[OrderInfo]
//将数据封装成orderWide样式
new OrderWide(orderInfo, orderDetail) :: Nil
}
//如果缓存没有,将来的orderDetail的数据存入orderDetail的缓存
else {
//创建一个方法将数据存入orderDetail,方法中传入客户端和数据
cacheOrderDetail(client, orderDetail)
Nil
}
}
}
client.close()
result
})
}














 2791
2791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









