






慢慢来,会更好!
大家好,我是一个想研究又不会研究的研究生
陪伴大家一起学习成长!
我们先来学习Bert这个model
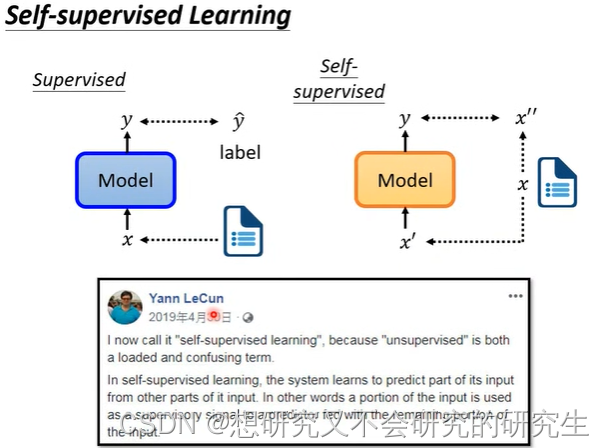
什么是Self-supervised Learning呢?
supervised:比如说现在输入一篇文章,判断它是正面还是负面文章
我们就需要文章和label(它是正面还是负面)才能够进行train
self-supervised:在没有label的情况下,自己想办法做supervised
假设现在只有一堆文章,没有标注
想办法让一部分文章作为model的输入,另一部分作为label
让y与x11越接近越好
接下来,我们拿BERT这个model详细说一下self-supervised到底是怎么做的呢?
BERT一般用在自然语言、文字上,输入一排向量,输出一排向量
用的是Transformer Encoder架构
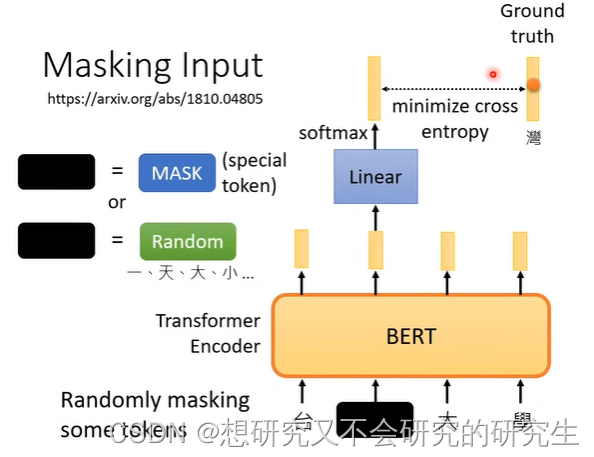
随机的遮住一些tokens,盖住哪些,随机决定。
1.把句子里面的某一字换成特殊的符号(可以想像成新的中文的字,在字典里从来没有出现过)
2.随机把某一个字换成另一个字(随便换成某一个字)
被遮盖的单位输出的向量经过linear(乘上一个矩阵),再经过softmax输出一个向量,
去和所有的字体做对比,通过计算minimize cross entropy,来找出被遮盖的字最可能是什么字。
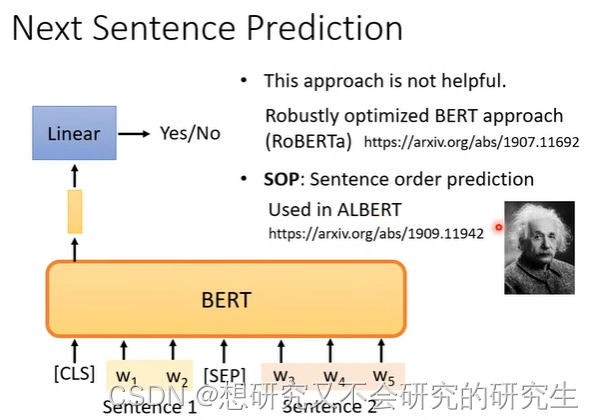
Next sentence Prediction (观察两个数据是相连还是不相连)
input:两个句子 output:YES/NO
SEP:分隔符号,代表两个不同的句子
CLS:输出Yes/No:这两个句子是不是相接的,如果是输出YES,反之NO
但是这个Next sentence Prediction对于接下来BERT想做的事情是不太有用的
原因可能是对于BERT来说,要分辨两个句子是不是相接可能是容易的
没有借由Next sentence Prediction这个任务学到太多的东西
而另一招和Next sentence Prediction相像的SOP是有用的
SOP(让BERT分辨哪一句在前面,这两句是相接的,让判断顺序)
那BERT怎么用呢?
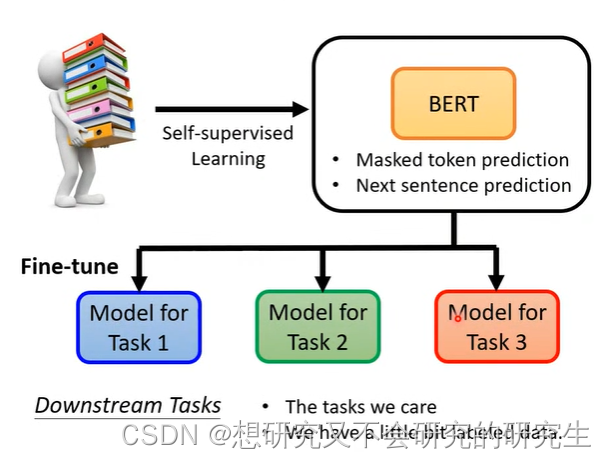
BERT除了做填空题(Masked),还能用在解各式各样的任务呢
BERT真正的任务就是DownStream Tasks
1.产生BERT的过程叫做Pre-train,
该过程一般需要进行masking input 和next sentence prediction这两个操作。
2.产生出来的BERT只会做填空题,BERT做过fine-tune(微调)之后才能做各式各样的任务。
3.pre-train过程是unsupervised learning,fine-tune过程是supervised learning,
所以整个过程是semi-supervised。
在学习BERT是怎样Fine-tune之前,我们先来看看它的能力

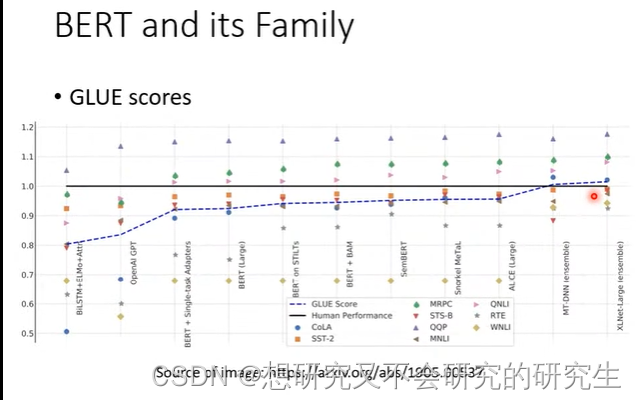
GLUE(用来测试BERT的能力)
GLUE是自然语言处理任务,总共有九个任务。
BERT分别微调之后做这9个任务,将9个测试分数做平均后代表BERT的能力高低。
那么,BERT到底是怎么被使用的呢?我们会举四个BERT的case来说明。
这四个案例的BERT都是经过pre-train的BERT,会做填空题了,同时这个BERT的初始化参数来自学会做填空题的BERT。
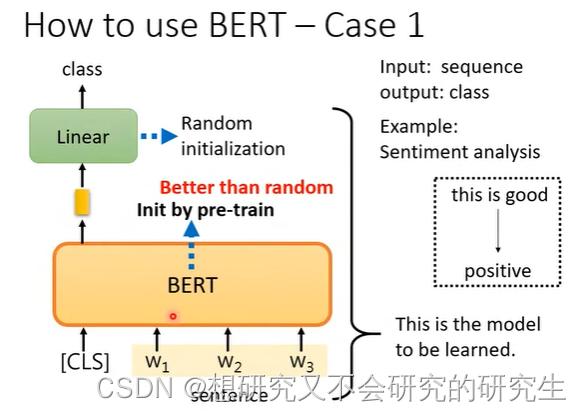
Case1
输入:句子
输出:类别
我们仍然需要下游任务的标注资料,提供给大量的句子和label
才能去训练这个model
linear的参数是随机初始化的。训练就是更新BERT和linear这两个模型里的参数。
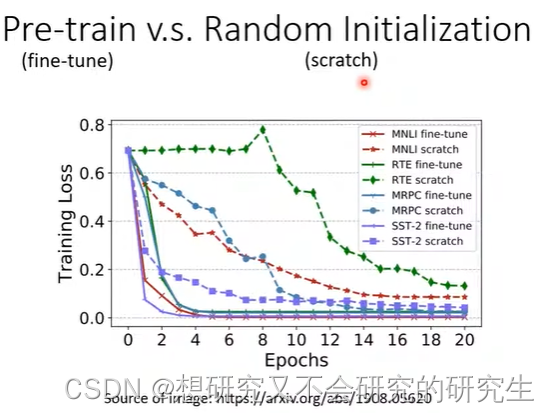
会做填空题BERT的初始化参数比随机初始化要好
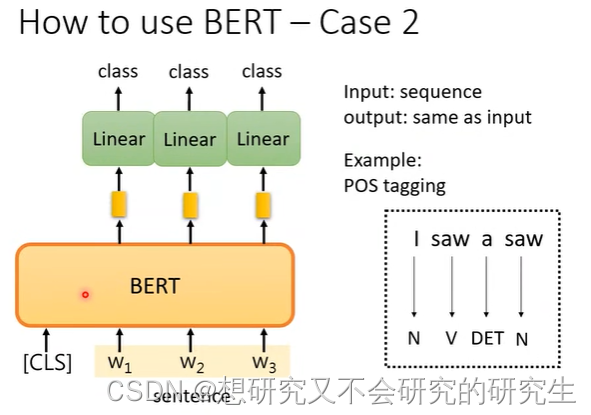
Case2
输入:sequence
输出:长度和输出一样
输入:两个句子
输出:一个类别
注意:虽然Bert举的例子都是文字上的,但是也可以把它用在语音方面

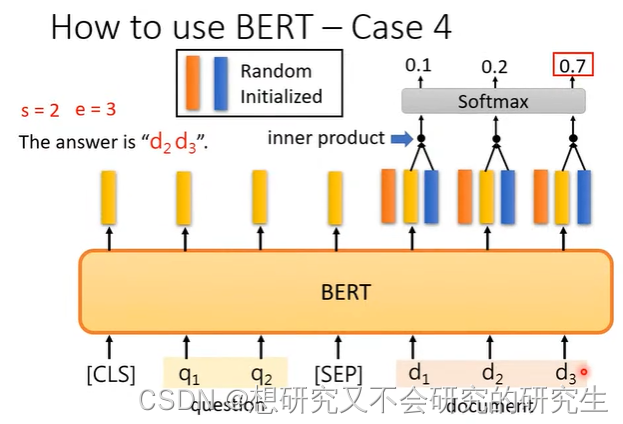
Case4 问答系统
针对回答能在文中找到的问答。输入问题和文章,输出两个正整数s,e,表示第s个字到第e个字之间的字就是答案。

经过内积之后通过softmax,分数最高的位置就是起始或终止位置。
橙色向量代表答案的起始位置,蓝色向量代表答案的结束位置。
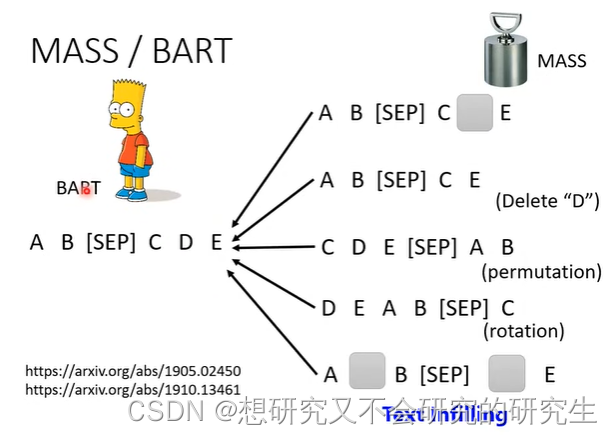
在一个transformer的模型中,输入的序列损坏,输出的是还原损坏的输入。
如何损坏输入数据呢?
可以采用mass或BART手段
1.mass是盖住某些数据(类似于masking)
2.BART是下图右边所有的方法(盖住数据、删除数据、打乱数据顺序、旋转数据等等)
可见,BART要比mass好















 1633
1633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









