







 本文详细介绍了如何判断变量间相关性及其强度,一元线性回归模型的建立过程,包括参数估计、模型检验、预测及残差分析的重要性和方法。通过R²和t检验评估模型效果,以及如何利用回归方程进行预测和残差图形解读误差假设。
本文详细介绍了如何判断变量间相关性及其强度,一元线性回归模型的建立过程,包括参数估计、模型检验、预测及残差分析的重要性和方法。通过R²和t检验评估模型效果,以及如何利用回归方程进行预测和残差图形解读误差假设。
本章内容:
- 判断两个变量间是否有相关关系,且关系强度如何?
- 如何建立一元线性回归模型,且模型效果如何?
- 如何利用回归方程进行预测?
- 为什么要进行残差分析,及如何进行分析?
索引
📌 专业名词
🔑 公式记忆
📖 摘抄
☑️ 有序事项
11.1 变量间是否有相关关系,且关系强度如何?
11.1.2 相关关系的描述与测量
📌 相关关系:变量之间存在的不确定的数量关系,称为相关关系。
📖 相关分析就是对两个变量之间线性关系的描述与度量,要解决的问题如下:
- 变量之间是否存在关系?
- 如果存在关系,它们之间是什么关系?
- 变量之间的关系强度如何?
- 样本反映的变量之间的关系能否代表总体变量之间的关系?
进行相关分析时,对总体主要有以下两个假定:
- 两个变量都是线性关系
- 两个变量都是随机变量
📖 如何判断变量之间的相关形态?
-
散点图——用于判断是否存在关系、什么关系
-
相关系数——用于判断关系强度如何?
🔑 相关关系计算公式
若相关系数是根据总体全部数据计算的,称为总体相关系数,记为
ρ
\rho
ρ; 若是根据样本数据计算的,称为样本相关系数,记为
r
r
r,计算公式如下:
r = n ∑ x y − ∑ x ∑ y n ∑ x 2 − ( ∑ x ) 2 ⋅ n ∑ y 2 − ( ∑ y ) 2 r=\frac{ n\sum{xy}-\sum{x}\sum{y} }{ \sqrt{ n\sum{x^2}-(\sum{x})^2 }\cdot{ \sqrt{ n\sum{y^2}-(\sum{y})^2 } } } r=n∑x2−(∑x)2⋅n∑y2−(∑y)2n∑xy−∑x∑y
上式计算得出的相关系数也称为线性相关系数,或皮尔逊(Pearson)相关系数。
Excel中,计算两组数据的相关系数,公式为:CORREL(array1,array2)
【工具】-【数据分析】
📖 相关系数的性质:
- 取值范围是[-1,1]。 如果 0 < r ≤ 1 0<r≤1 0<r≤1,表明x与y之间存在正线性相关关系; 如果 − 1 ≤ r < 0 -1≤r<0 −1≤r<0,表明x与y之间存在负线性相关关系; 如果 r = 1 r=1 r=1,表明x与y之间存在完全正线性相关关系; 如果 r = − 1 r=-1 r=−1,表明x与y之间存在完全负线性相关关系; 如果 r = 1 r=1 r=1,表明x与y之间不存在相关关系;
- 对称性,即 r x y = r y x r_{xy}=r_{yx} rxy=ryx。
- r的数值大小与x和y的原点及尺度无关。改变x和y的数据原点及计量尺度,并不改变数值大小。
- r仅仅是x与y之间线性关系的一个度量,不能用于描述非线性关系。即 r = 0 r=0 r=0只能表示变量之间不存在线性相关关系,不说明变量之间没有任何相关关系。
- r不意味着x与y一定有因果关系。
🔑 r的大小与相关程度划分
当
∣
r
∣
≥
0.8
|r|≥0.8
∣r∣≥0.8时,可视为高度相关;
当
0.5
≤
∣
r
∣
<
0.8
0.5≤|r|<0.8
0.5≤∣r∣<0.8时,可视为中度相关;
当
0.3
≤
∣
r
∣
<
0.5
0.3≤|r|<0.5
0.3≤∣r∣<0.5时,可视为低度相关;
当
∣
r
∣
<
0.3
|r|<0.3
∣r∣<0.3时,可视为相关性极弱,可视为不相关;
但这种解释必须建立在对相关系数的显著性进行检验的基础之上!
11.1.3 相关关系的显著性检验
📖 为什么要进行显著性检验?
因为总体相关系数
ρ
ρ
ρ通常未知,一般使用样本相关系数
r
r
r来代替总体相关系数,但是样本相关系数受到抽样数据的影响,所以需要对样本相关系数说明总体的相关程度,即进行显著性检验
📖 r的抽样分布
样本相关系数r的显著性与r的抽样分布相关;r的抽样分布随着总体相关系数和样本量的大小而变化。
当样本数据来自正态总体时,随着n的增大,r的抽样分布趋于正态分布。
当总体相关系数接近0时,r趋于正态分布的趋势非常明显;反之r的抽样分布呈现一定的偏态。
当
ρ
ρ
ρ为较大的正值时,
r
r
r呈现左偏分布;
当
ρ
ρ
ρ为较大的负值时,r呈现右偏分布。 只有当
ρ
ρ
ρ接近于0,而样本量n很大时,才能认为r是接近于正态分布的随机变量。
☑️ r的显著性检验
- 提出假设
H 0 : ρ = 0 ; H 1 : ρ ≠ 0 H_0:ρ=0;H_1:ρ≠0 H0:ρ=0;H1:ρ=0
-
计算检验的统计量:t统计量 t = ∣ r ∣ n − 2 1 − r 2 ∼ t ( n − 1 ) t=|r|\sqrt{\frac{ n-2 }{ 1-r^2 }}\sim{t(n-1)} t=∣r∣1−r2n−2∼t(n−1) 其自由度为: n − 2 n-2 n−2
-
进行决策 根据给定的显著性水平 α \alpha α和自由度,计算 t α / 2 t_{\alpha/2} tα/2。 若 ∣ t ∣ > t α / 2 |t|>t_{α/2} ∣t∣>tα/2,则拒绝原假设 H 0 H_0 H0,表明总体的两个变量之间存在显著的线性关系。
11.2 如何建立一元线性回归模型,且进行模型检验?
📖 相关分析的目的在于考察变量之间的关系强度;
回归分析的目的在于考察变量之间的数量关系,并通过一定的数学表达式将这种关系描述出来,进而确定一个或几个变量的变化对另一个特定变量的影响程度。
回归分析解决的问题:
- 从样本数据出发,确定变量之间的数学关系式;
- 对这些关系式的可信程度进行各种统计检验,并从影响某一特定变量的诸多变量中找出哪些变量的影响是显著的,哪些是不显著的;
- 利用所求的关系式,根据一个或几个变量的取值来估计或预测另一个特定变量的取值,并给出这种估计或预测的可靠程度。(这部分内容实际放在11.3章来讲解)
11.2.1 一元线性回归
📌 常见专业名词解释
因变量
被预测或被解释的变量称为因变量,用y表示。
自变量
用来预测或解释因变量的一个或多个变量称为自变量,用x表示。
一元回归
当回归中只涉及一个自变量时,称为一元回归。
一元线性回归
若因变量x和自变量y之间为线性关系,称为一元线性回归。
📖 本章所讨论的回归方法对于自变量是预先固定的、自变量是随机的情况都使用;
因为固定自变量的情况比较容易描述,因此下面主要讲述固定自变量的回归问题。
📌 回归模型
对于具有线性关系的两个变量,可以用一个线性方程来表示它们之间的关系。 描述因变量y如何依赖于自变量x和误差项 ε ε ε的方程,称为回归模型。
📌 理论回归模型
对于只涉及一个自变量的一元线性回归模型可表示为:
y = β 0 + β 1 x + ε y=β_0+β_1x+\varepsilon y=β0+β1x+ε
其中 β 0 + β 1 x β_0+β_1x β0+β1x反映了由于x的变化,引起y的线性变化; ε \varepsilon ε是误差项的随机变量,反映了线性关系之外的随机因素对y的影响。 β 0 、 β 1 \beta_0、\beta_1 β0、β1称为模型的参数。
📖 理论回归模型的假定
①因变量y与自变量x之间具有线性关系;
②在重复抽样中,自变量x的取值是固定的,即假定x是非随机的;
③误差项 ε \varepsilon ε是一个期望值为0的随机变量,即 E ( ε ) = 0 E(\varepsilon)=0 E(ε)=0;
④对于所有的x值, ε \varepsilon ε的方差 σ 2 \sigma^2 σ2都相同;因为误差与x、y都无关。
⑤误差项
ε
\varepsilon
ε是一个服从正态分布的随机变量,且独立,即
ε
∼
N
(
0
,
σ
2
)
\varepsilon\sim{N(0,σ^2)}
ε∼N(0,σ2)。
E(y)的值随着x的不同而变化,但无论x怎么变化,
ε
\varepsilon
ε和y的概率分布都是正态分布,并且具有相同的方差。
📌 回归方程
描述因变量y的期望值如何依赖于自变量x的方程,称为回归方程。
一元线性回归方程也称为直线回归方程,公式如下:
E ( y ) = β 0 + β 1 x E(y)=β_0+β_1x E(y)=β0+β1x
β 0 \beta_0 β0为截距, β 1 \beta_1 β1为斜率。
📌 估计的回归方程
由于总体是未知的,所以采用样本统计量
β
0
^
\hat{\beta_0}
β0^、
β
1
^
\hat{\beta_1}
β1^代替回归方程中的未知参数
β
0
\beta_0
β0、
β
1
\beta_1
β1,得到估计的回归方程。
一元线性回归下,估计的回归方程为:
y ^ = β ^ 0 + β ^ 1 x \hat{y}=\hat{β}_0+\hat{β}_1x y^=β^0+β^1x
11.2.2 参数的最小二乘估计
📖 最小二乘法是确定直线代表最强代表性的方法。
因为描述x,y的n对观测值的直线,有多条,所以需要找到一种方法,来确定最佳代表两个变量之间关系的直线。
📌 最小二乘法
代表两个变量之间关系的标准之一:该直线距离各个观测点的距离最近。
通过使用因变量的观测值
y
i
y_i
yi,和估计值
y
^
i
\hat{y}_i
y^i之间的离差平方和来估计参数
β
0
\beta_0
β0、
β
1
\beta_1
β1的方法,称为最小二乘法,也称为最小平方法。
📖 优势如下:
①根据最小二乘法得到的回归直线能使离差平方和达到最小,虽然这并不能保证它就是拟合数据的最佳直线,但这毕竟是一条与数据拟合良好的直线应有的性质;
②由最小二乘法求得的回归直线可知β0和β1的估计量的抽样分布;
③在某些条件下β0和β1的最小二乘估计量同其他估计量相比,其抽样分布具有较小的标准差。
🔑 求解 β 0 ^ \hat{\beta_0} β0^、 β 1 ^ \hat{\beta_1} β1^
构建最小二乘法公式:
∑ ( y i − y ^ i ) 2 = ∑ ( y i − β ^ 0 − β ^ 1 x i ) 2 \sum{(y_i-\hat{y}_i)}^2 =\sum{ ( y_i-\hat{β}_0-\hat{β}_1x_i )^2 } ∑(yi−y^i)2=∑(yi−β^0−β^1xi)2
根据最小二乘法原理,要求得上式最小值。根据微积分的极限定理,令 Q = ∑ ( y i − y ^ i ) 2 Q=\sum{(y_i-\hat{y}_i)}^2 Q=∑(yi−y^i)2,即对Q求相应于 β 0 ^ \hat{\beta_0} β0^、 β 1 ^ \hat{\beta_1} β1^的偏导数,并令其等于0。 \ 求解 β 0 ^ \hat{\beta_0} β0^、 β 1 ^ \hat{\beta_1} β1^公式:
{ ∂ Q ∂ β 0 ∣ β 0 = β ^ 0 = − 2 ∑ i = 1 n ( y i − β ^ 0 − β ^ 1 x i ) 2 = 0 ∂ Q ∂ β 1 ∣ β 1 = β ^ 1 = − 2 ∑ i = 1 n x i ( y i − β ^ 0 − β ^ 1 x i ) 2 = 0 \left\{ \begin{aligned} \frac{ \partial{Q} }{ \partial{\beta_0} }|_{\beta_0=\hat{\beta}0} & = -2\sum_{i=1}^n ( y_i-\hat{β}_0-\hat{β}1x_i )^2 =0\\ \frac{ \partial{Q} }{ \partial{\beta_1} }|_{\beta_1=\hat{\beta}1} & = -2\sum_{i=1}^n x_i( y_i-\hat{β}_0-\hat{β}_1x_i )^2 =0 \end{aligned} \right. ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧∂β0∂Q∣β0=β^0∂β1∂Q∣β1=β^1=−2i=1∑n(yi−β^0−β^1xi)2=0=−2i=1∑nxi(yi−β^0−β^1xi)2=0
{ β ^ 1 = n ∑ i = 1 n x i y i − ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n x i 2 − ( ∑ i = 1 n x i ) 2 β ^ 0 = y ˉ − β ^ 1 x ˉ \left\{ \begin{aligned} \hat{\beta}1 & = \frac{ \displaystyle n\sum_{i=1}^nx_iy_i-\sum_{i=1}^nx_i \sum_{i=1}^ny_i }{ \displaystyle n\sum_{i=1}^nx_i^2-( \sum_{i=1}^nx_i)^2 } \\ \hat{\beta}_0 & = \bar{y}-\hat{\beta}_1\bar{x} \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧β^1β^0=ni=1∑nxi2−(i=1∑nxi)2ni=1∑nxiyi−i=1∑nxii=1∑nyi=yˉ−β^1xˉ
excel中,求解一元线性回归方程的方式为:
【工具】-【回归】
11.2.3 回归直线的拟合优度
📌 拟合优度 回归直线与各观测点的接近程度称为回归直线对数据的拟合优度。 各观测点越是紧密围绕直线,说明一元线性回归模型对观测数据的拟合程度越好。
🔑 判定系数-
R
2
R^2
R2
判定系数是对估计的回归方程拟合优度的度量,其公式如下:
R 2 = S S R S S T = ∑ ( y ^ i − y ˉ i ) 2 ∑ ( y i − y ˉ i ) 2 R^2=\frac{SSR}{SST} =\frac{ \sum{(\hat{y}_i-\bar{y}_i)}^2 }{ \sum{(y_i-\bar{y}_i)}^2 } R2=SSTSSR=∑(yi−yˉi)2∑(y^i−yˉi)2
判定系数就是:回归平方和/总平方和;判定系数越接近1,说明回归直线的拟合效果越好;反之。
判定系数的实际意义:在y取值的变动中,有 R 2 R^2 R2(这是个百分比)的部分可以由x与y之间的线性关系来解释;即y中有 R 2 R^2 R2是由x决定的。
📌 估计标准误差
度量各个实际观测点在直线周围的散布状况的一个统计量,用来说明实际观测值与回归估计值之间的差异程度。
🔑 估计标准误差的公式为:
s e = ∑ ( y i − y ^ i ) 2 n − 2 = S S E n − 2 = M S E s_e=\sqrt{\frac{ \sum{(y_i-\hat{y}_i)^2} }{ n-2 }} =\sqrt{\frac{ SSE }{ n-2 }} =\sqrt{MSE} se=n−2∑(yi−y^i)2=n−2SSE=MSE
可以看做在排除了x对y的线性影响后,y随机波动大小的一个估计量。 反映了用估计的回归方程预测因变量y时预测误差的大小。
和判定系数
R
2
R^2
R2的差异:
判定系数是百分比,不是实际的数值,
1
−
R
2
1-R^2
1−R2在一定程度上也衡量了差异程度,但是不是具体的差异值;
估计标准误差是具体的差异值。
11.2.4 显著性检验
📖 回归分析中的显著性检验包括2部分:
线性关系的检验_F统计量
回归系数的检验_t统计量
☑️ 线性关系检验 _F统计量
检验自变量x和因变量y之间的线性关系是否显著,即它们之间能否使用一元线性回归模型来表示。
-
构造统计量
F = S S R / 1 S S E / ( n − 2 ) = M S R M S E ∼ F ( 1 , n − 2 ) F=\frac{ SSR/1 }{ SSE/(n-2) } =\frac{MSR}{MSE}\sim{F(1,n-2)} F=SSE/(n−2)SSR/1=MSEMSR∼F(1,n−2)
即:
F = 回 归 平 方 和 / 自 由 度 : k ( 自 变 量 的 个 数 ) 残 差 平 方 和 / 自 由 度 : n − k − 1 = 均 方 回 归 均 方 残 差 ∼ F ( 1 , n − 2 ) F=\frac{ 回归平方和/自由度:k(自变量的个数) }{ 残差平方和/自由度:n-k-1 } =\frac{ 均方回归 }{ 均方残差 }\sim{F(1,n-2)} F=残差平方和/自由度:n−k−1回归平方和/自由度:k(自变量的个数)=均方残差均方回归∼F(1,n−2) -
提出假设: H 0 : β 1 = 0 H_0:\beta_1=0 H0:β1=0,两个变量之间的线性关系不显著,即没有线性关系。
-
计算统计量F
-
做出决策
若 F > F α F>F_\alpha F>Fα,拒绝原假设,两个变量之间有线性关系;
若 F < F α F<F_\alpha F<Fα,接受原假设,两个变量之间有线性关系。
☑️ 回归系数检验 _t统计量
检验自变量对因变量的影响是否显著,也是检查两个变量之间有没有线性关系的。
如果
β
1
=
0
\beta_1=0
β1=0,那么两个变量之间没有线性关系;
如果
β
1
≠
0
\beta_1≠0
β1=0,那么两个变量之间有线性关系。
为什么不能直接计算
β
1
\beta_1
β1来判断两个变量的线性关系呢?
因为总体的数据量是未知的,所以不能计算
β
1
\beta_1
β1,只能通过样本量得到
β
^
1
\hat{\beta}_1
β^1;通过
β
^
1
\hat{\beta}_1
β^1的统计量检验,才能判断总体
β
1
\beta_1
β1的情况。
-
构建统计量t
t = β ^ 1 − β 1 s β ^ 1 ∼ t ( n − 2 ) t=\frac{ \hat{\beta}1-\beta_1 }{ s{\hat{\beta}_1} }\sim{t(n-2)} t=sβ^1β^1−β1∼t(n−2)
自由度为:n-2
其中 s β ^ 1 s_{\hat{\beta}_1} sβ^1计算公式如下:
s β ^ 1 = s e ∑ x i 2 − 1 n ( ∑ x i ) 2 s_{\hat{\beta}_1}=\frac{ s_e }{ \sqrt{ \sum{x_i^2}-\frac{1}{n}(\sum{x_i})^2 } } sβ^1=∑xi2−n1(∑xi)2se
s e = ∑ ( y i − y ^ i ) 2 n − 2 = S S E n − 2 = M S E s_e=\sqrt{\frac{ \sum{(y_i-\hat{y}_i)^2} }{ n-2 }} =\sqrt{\frac{ SSE }{ n-2 }} =\sqrt{MSE} se=n−2∑(yi−y^i)2=n−2SSE=MSE
其中, s e s_e se是 σ \sigma σ的估计量,称为估计标准误差;因为 σ \sigma σ通常未知,所以用 s β ^ 1 s_{\hat{\beta}1} sβ^1作为 σ β ^ 1 \sigma{{\hat{\beta}_1}} σβ^1的估计量。 -
提出检验: H 0 : β 1 = 0 H_0:\beta_1=0 H0:β1=0,两个变量之间的线性关系不显著,即没有线性关系。
-
计算检验统计量t
-
做出决策
若 ∣ t ∣ > t α / 2 |t|>t_{\alpha/2} ∣t∣>tα/2,拒绝原假设,两个变量之间有线性关系;
若 ∣ t ∣ < t α / 2 |t|<t_{\alpha/2} ∣t∣<tα/2,接受原假设,两个变量之间没有线性关系。
📖 excel数据分析中,其他参数的计算公式:
11.2.5 回归分析结果的评价
☑️ 如何判断一元线性回归模型的效果
(1)看 β ^ 1 \hat{β}_1 β^1:所估计的回归系数 β ^ 1 \hat{β}_1 β^1的符号是否与理论或事先预期相一致;
(2)看t检验:判断回归系数是否显著。如果理论上认为y与x之间的关系不仅是正的,而且是统计上显著的,那么所建立的回归方程也应该如此;
(3)看 R 2 R^2 R2:可以用判定系数 R 2 R^2 R2来回答回归模型在多大程度上解释了因变量y取值的差异;
(4)看F检验:考察关于误差项ε的正态性假定是否成立。
11.3 如何利用回归方程进行预测?
11.3.1 点估计
📖 利用估计的回归方程,对于x的一个特定值x0,求出y的一个估计值就是点估计。
点估计可分为两种:
一是平均值的点估计;
二是个别值的点估计。
在点估计的条件下,对于同一个x0,平均值的点估计和个别值的点估计的结果是一样的,但在区间估计中则有所不同。
11.3.2 区间估计
📖 利用估计的回归方程,对于x的一个特定值x0,求出y的一个估计值的区间就是区间估计。
区间估计也有两种类型:
一是置信区间估计,它是对x的一个给定值x0,求出y的平均值的估计区间,这一区间称为置信区间;
二是预测区间估计,它是对x的一个给定值x0,求出y的一个个别值的估计区间,这一区间称为预测区间。
🔑 置信区间估计
通过
y
^
0
\hat{y}_0
y^0估计
E
(
y
0
)
E(y_0)
E(y0)的区间,需要知道
y
^
0
\hat{y}_0
y^0的标准差,用
s
y
^
0
s_{\hat{y}_0}
sy^0表示
y
^
0
\hat{y}_0
y^0的标准差的估计量。
y ^ 0 \hat{y}_0 y^0的置信区间如下:
y ^ 0 ± t α / 2 s e 1 n + ( x 0 − x ˉ ) 2 ∑ i = 1 n ( x i − x ˉ ) 2 \hat{y}0\pm{t}{\alpha/2}s_e \sqrt{ \frac{1}{n} +\frac{ (x_0-\bar{x})^2 }{\displaystyle \sum_{i=1}^n(x_i-\bar{x})^2 } } y^0±tα/2sen1+i=1∑n(xi−xˉ)2(x0−xˉ)2
🔑 预测区间估计
y ^ 0 ± t α / 2 s e 1 + 1 n + ( x 0 − x ˉ ) 2 ∑ i = 1 n ( x i − x ˉ ) 2 \hat{y}0\pm{t}{\alpha/2}s_e \sqrt{ 1+ \frac{1}{n} +\frac{ (x_0-\bar{x})^2 }{\displaystyle \sum_{i=1}^n(x_i-\bar{x})^2 } } y^0±tα/2se1+n1+i=1∑n(xi−xˉ)2(x0−xˉ)2
对比预测区间估计、置信区间估计的公式,预测区间估计的公式根号内多了一个1。
可见,预测区间要比置信区间更宽。
📖 注意:在利用回归方程进行估计或预测时,不要用样本数据最大最小值之外的x值去预测相对应的y值,结果会比较不理想。
11.4 为什么要进行残差分析,及如何分析?
11.4.1 残差与残差图
📖 一元相信回归模型中,假定 ε \varepsilon ε是期望值为0、方差相等且服从正态分布的一个随机变量。
如果假定不满足,则检验、估计和预测则可能站不住脚,所以需要对 ε \varepsilon ε的假定是否成立进行判断,方法之一就是残差分析。
📌 残差
因变量的观测值
y
i
y_i
yi与根据估计的回归方程求出的预测值
y
^
i
\hat{y}_i
y^i之差,用
e
e
e表示。
反映了用估计的回归方程去预测
y
i
y_i
yi引起的误差,公式如下:
e i = y i − y ^ i e_i=y_i-\hat{y}_i ei=yi−y^i
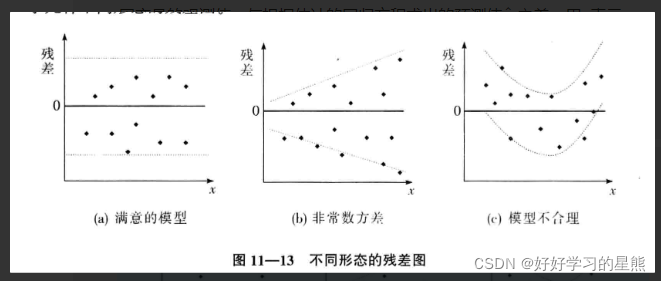
📌 残差图
用于判断
ε
\varepsilon
ε的假定是否成立;其中x为横轴,
e
e
e为纵轴。
11.4.2 标准化残差
标准化残差
用于判断
ε
\varepsilon
ε的假定是否成立;是残差除以它的标准差后得到的数值,用
z
e
z_e
ze表示,公式如下:
z
e
i
=
e
i
s
e
=
y
i
−
y
^
i
s
e
z_{e_i}=\frac{e_i}{s_e}=\frac{y_i-\hat{y}_i}{s_e}
zei=seei=seyi−y^i
如果误差项
ε
ε
ε服从正态分布这一假定成立,那么标准化残差的分布也应服从正态分布。
因此,在标准化残差图中,大约有95%的标准化残差在-2~+2之间。
书籍:《统计学(第六版)》
书籍作者:贾俊平
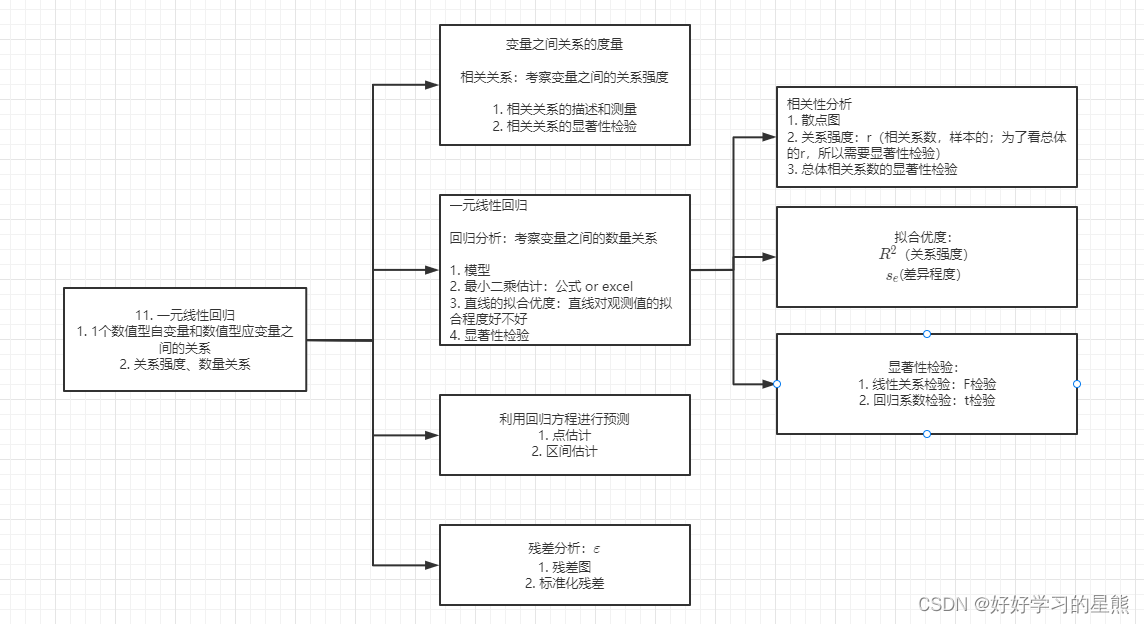
内容思维导图

















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









