







强化学习中的策略梯度(Policy Gradient)
强化学习和深度学习中的策略梯度不同点
用分类问题来解释
在做分类的问题时,要有输入和正确的输出,要有训练数据。而这些训练数据是从采样的过程来的。假设在采样的过程里面,在某一个状态,你采样到你要采取动作 a, 你就把这个动作 a 当作是你的 ground truth。你在这个状态,你采样到要向左。 本来向左这件事概率不一定是最高, 因为你是采样,它不一定概率最高。假设你采样到向左,在训练的时候,你告诉机器说,调整网络的参数, 如果看到这个状态,你就向左。在一般的分类问题里面,其实你在实现分类的时候,你的目标函数都会写成最小化交叉熵(cross entropy),其实最小化交叉熵就是最大化对数似然(log likelihood)。
做分类的时候,目标函数就是最大化或最小化的对象, 因为我们现在是最大化似然(likelihood),所以其实是最大化, 你要最大化的对象,如下式所示:
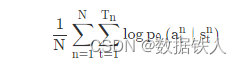
像这种损失函数,你可在 TensorFlow 里调用现成的函数,它就会自动帮你算,然后你就可以把梯度计算出来。这是一般的分类问题,RL 唯一不同的地方是 loss 前面乘上一个权重:整场游戏得到的总奖励 R,它并不是在状态 s 采取动作 a 的时候得到的奖励,如下式所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 44
44











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









