






虚拟内存其实是 CPU 和操作系统使用的一个障眼法,联手给进程编织了一个假象,让进程误以为自己独占了全部的内存空间:
- 在 32 位系统中,进程以为自己独占了 3G 的内存空间。
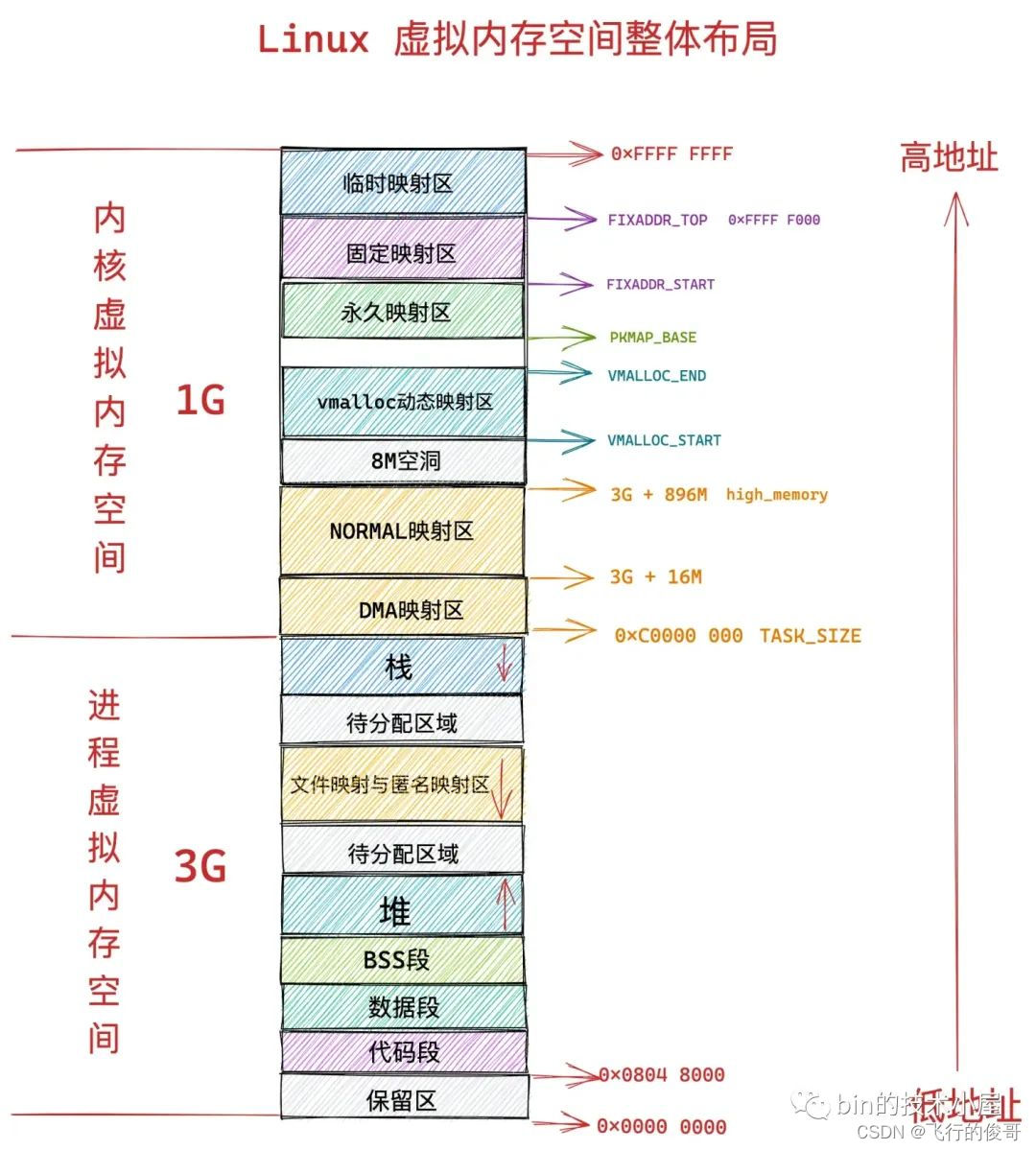

- 在 64 位系统中,进程以为自己独占了 128T 的内存空间。
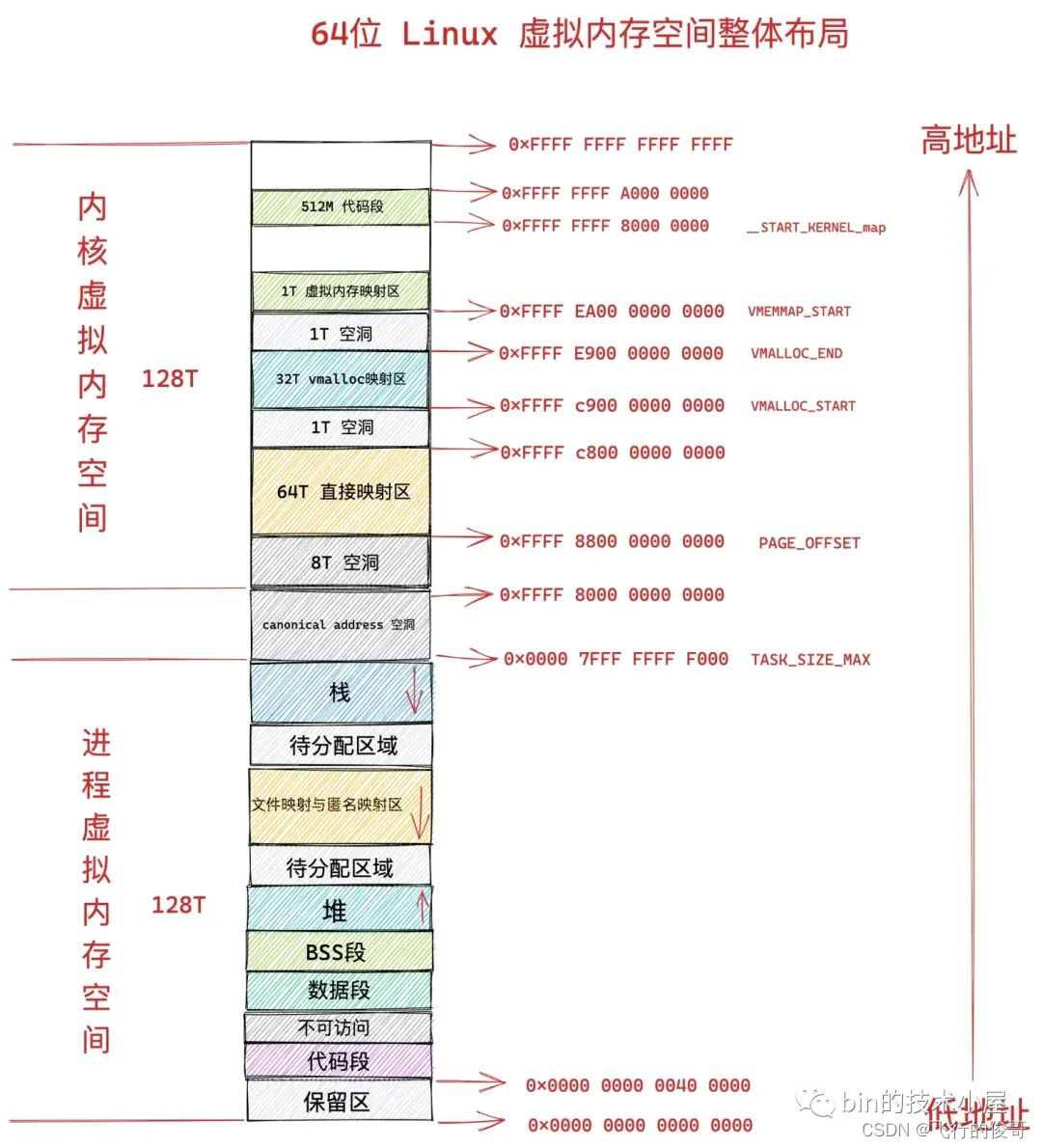
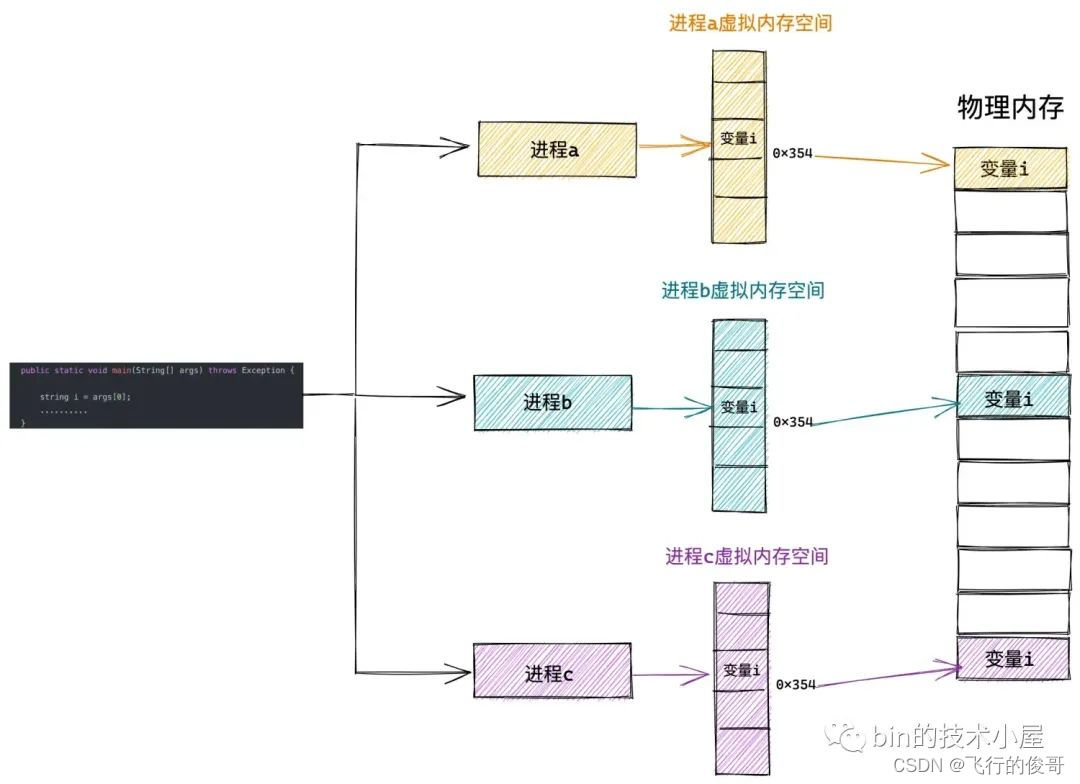
这么做的好处是,操作系统为每个进程营造出一片独立的虚拟地址空间,使得进程与进程之间相互隔离,互不干扰的,解决了多进程同时运行时产生的内存地址冲突问题。
之前一直纠结,如果好多个进程,那么内存如何分配?不同进程的堆栈代码空间等是放在一起还是单独放(进程1 栈空间 进程2 栈空间。。。进程N栈空间, 进程1堆空间, 进程2堆空间。。。进程N堆空间 还是进程1 栈空间堆空间代码空间进程2栈空间堆空间代码空间。。。)。所以说,对于每一个进程来说,都觉得自己可以把所有的内存占用掉,然后通过内核的一些机制把它们映射到物理空间。
3.1. 虚拟内存如何与物理内存映射起来
内核会将整个物理内存空间划分为一页一页大小相同的的内存块,每个内存块大小为 4K,称为一个物理内存页。
一页大小的内存块在内核中用 struct page 结构体来进行管理,struct page 中封装了每页内存块的状态信息,比如:组织结构,使用信息,统计信息,以及与其他内核结构的关联映射信息等。
内核会为每个物理内存页 page 进行统一编号。这个编号称之为 PFN(Page Frame Number),PFN 与 struct page 是一一对应的关系并且全局唯一。然后内核会将划分出来的这些一页一页的内存块统一组织在一个全局数组 mem_map 中管理。后续虚拟内存与物理内存的映射以及调度均是以页为单位进行的。
然后内核会将划分出来的这些一页一页的内存块统一组织在一个全局数组 mem_map 中管理。后续虚拟内存与物理内存的映射以及调度均是以页为单位进行的。

3.2. 内核如何通过页表来管理内存映射关系
内核会从物理内存空间中拿出一个物理内存页来专门存储进程里的这些内存映射关系,而这种物理内存页我们将其称之为页表,从这里可以看出页表的本质其实就是一个物理内存页。
而内核会在页表中划分出来一个个大小相等的小内存块,这些小内存块我们称之为页表项 PTE(Page Table Entry),正是这个 PTE 保存了进程虚拟内存空间中的虚拟页与物理内存页的映射关系,以及控制物理内存访问的相关权限位。
在 32 位系统中页表中的 PTE 占用 4 个字节,64 位系统中页表的 PTE 占用 8 个字节。
因为内存映射的粒度是按照页为单位进行的,所以进程虚拟内存空间中的每个虚拟页在页表中都会有一个 PTE 与之对应,而虚拟页背后映射的物理内存页的起始地址就保存在 PTE 中。
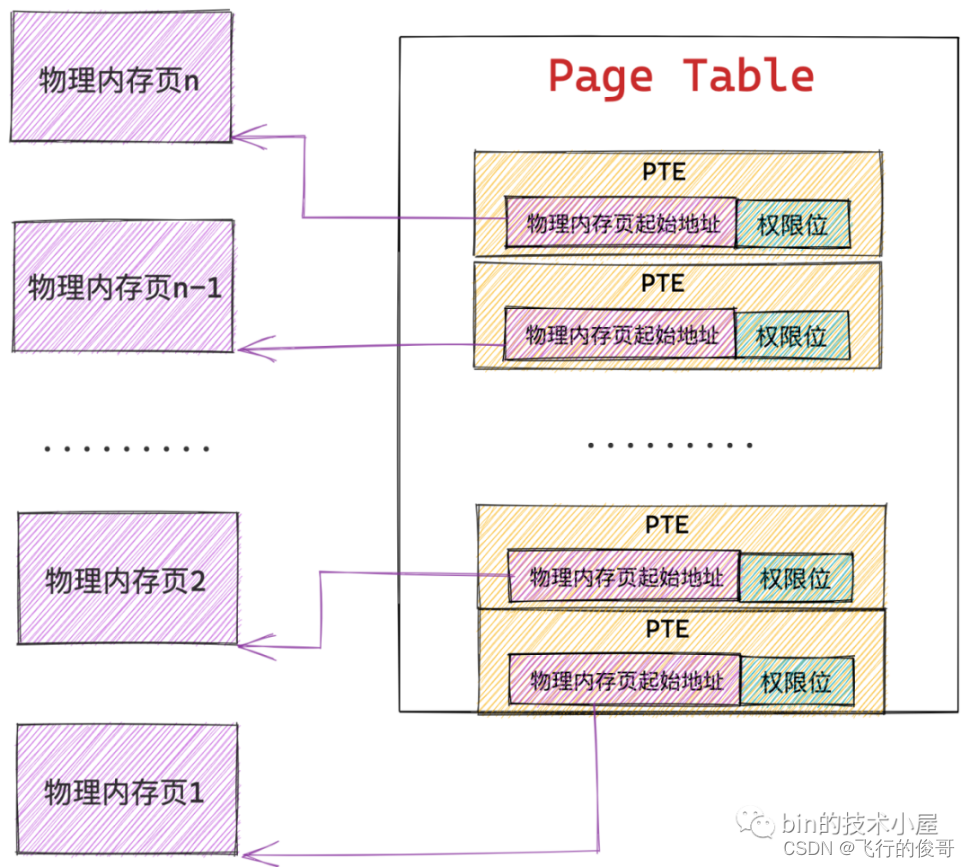
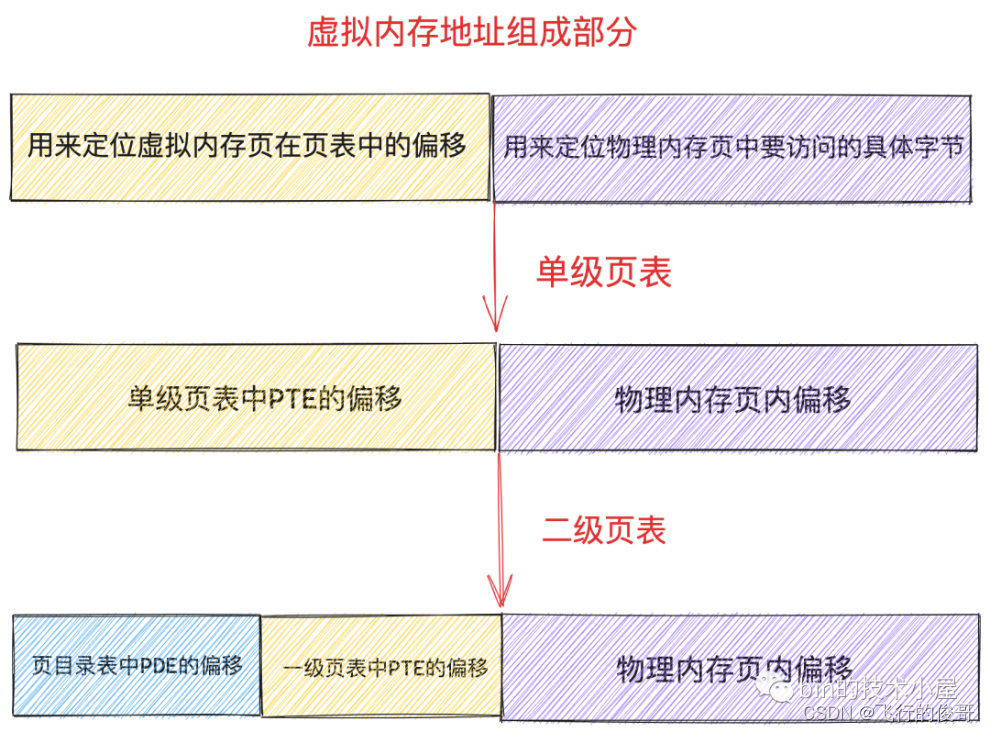
而进程虚拟内存空间中的每一个字节都有一个虚拟内存地址来表示,格式为:页表内偏移 + 物理内存页内偏移
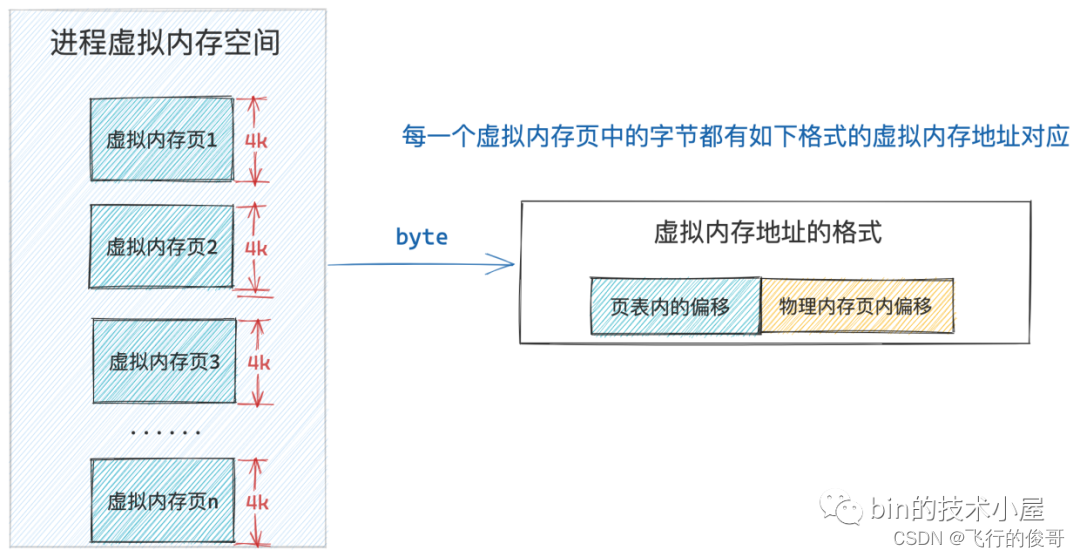
这样一来,给定一个虚拟内存地址,内核会先从这个虚拟内存地址中提取出 页表内偏移 ,然后根据 页表起始地址 + 页表内偏移 * sizeof(PTE) 就能获取到该虚拟内存地址所在虚拟页在页表中对应的 PTE 了。
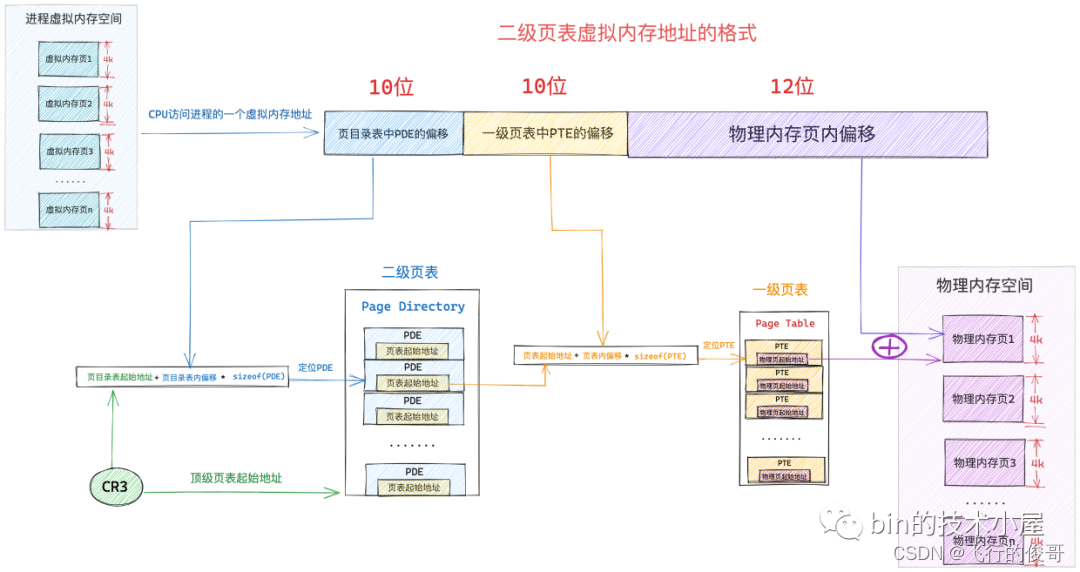
cr3 寄存器中保存的就是当前进程顶级页表的起始物理内存地址了(区分不同进程的变量,使得不同进程映射到不同的物理地址,虽然虚拟地址可以一样),当 CPU 通过下图所示的虚拟内存地址访问进程的虚拟内存时,CPU 首先会从 cr3 寄存器中获取到当前进程的顶级页表起始地址,然后从虚拟内存地址中提取出虚拟内存页对应 PTE 在页表内的偏移,通过 页表起始地址 + 页表内偏移 * sizeof(PTE) 这个公式定位到虚拟内存页在页表中所对应的 PTE。
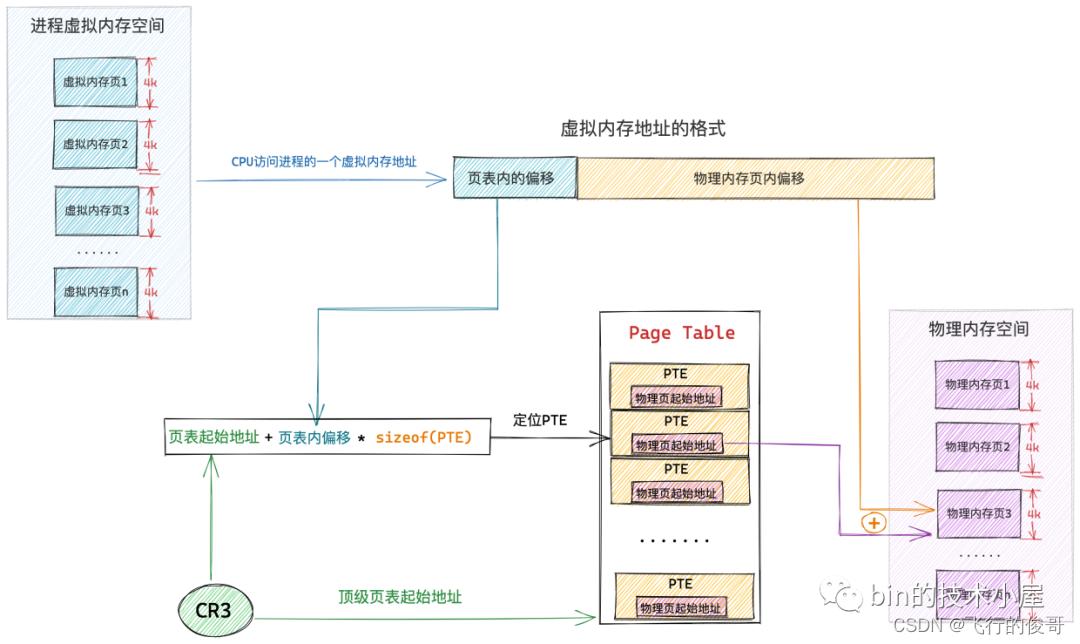
3.3 多级页表
在 32 位系统中,一个 PTE 占用 4 个字节,可以映射 4K 的物理内存,一张页表本身占用 4K 的物理内存(1024 entry),可以映射 4M 的物理内存。我们必须要为进程额外分配 4M 的连续物理内存来存放 1024 张页表(4G)。
如果现在我们在拿出一个 4K 的物理内存页作为页表,然后将这个页表放在单级页表的前面,组成一个二级页表的体系,情况会变成什么样呢?
当前系统中,进程只有一张页目录表,页目录表里的 PDE 没有映射任何东西,这时进程需要访问一个物理内存页,而对物理内存页的映射任务主要是在一级页表的 PTE 中,所以现在首要的任务就是建立一张一级页表出来,并用页目录表索引起来
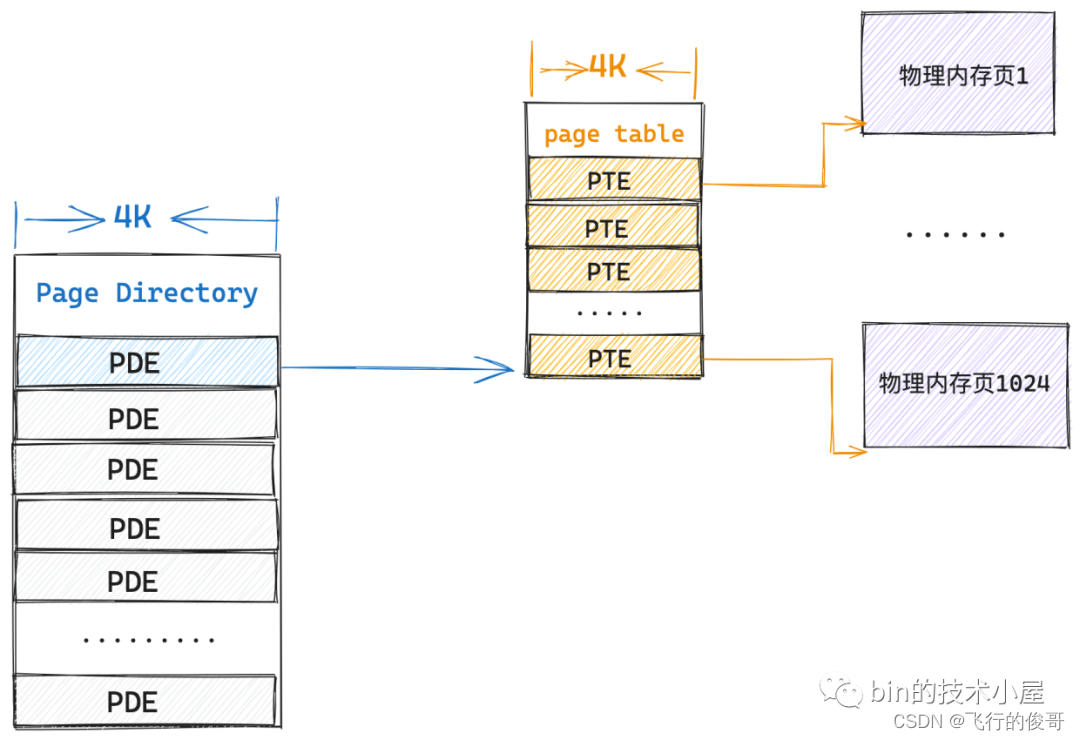
在二级页表的情况下,内核只需要一张 4K 的页目录表和一张 4K 的一级页表总共 8K 的内存就可以支持进程访问一个 4K 物理页面了,而根据程序的空间局部性原理,在不久的将来,进程只会访问与该物理内存页临近的页面,所以事实上,即使进程访问 4M 的内存,依然只需要一张 4K 的页目录表和一张 4K 的一级页表就可以满足了。

当进程需要访问下一个 4M 的物理内存时,这时候第一个一级页表已经映射满了,那就需要再创建第二张页表用来映射下一个 4M 的物理内存,当然了,第二张页表依然需要索引在页目录表的 PDE 中。
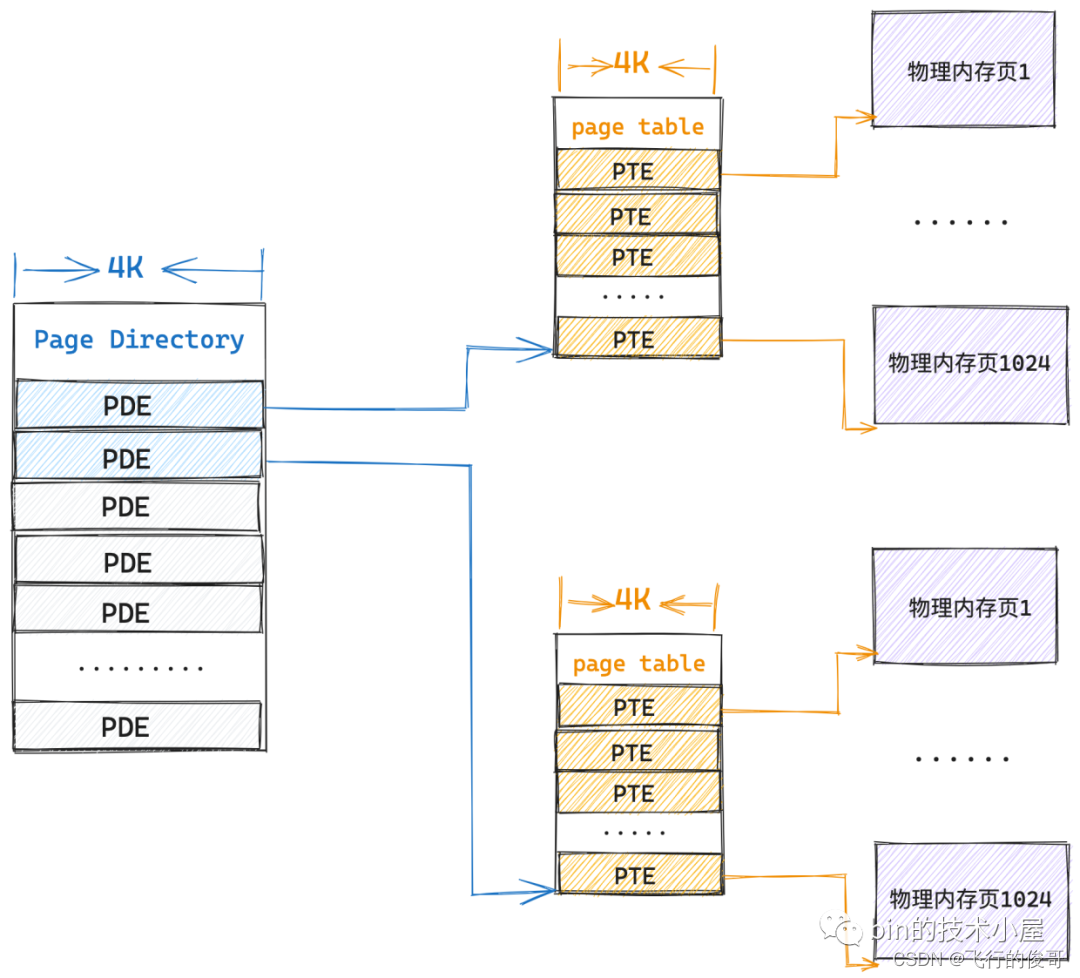
这时候内核就需要一张页目录表和两张一级页表共 12K 额外的物理内存来映射,这依然比单级页表的 4M 连续物理内存开销小很多。
同理,随着进程一个 4M 接着一个 4M 物理内存的访问,在极端的情况下整个页目录表都被映射满了,这时候内核就需要 4K(页目录表)+ 4M(1024张一级页表)的额外内存来保存映射关系了,这种情况下看起来会比单级页表下的 4M 内存开销大了那么一点点,但这种属于极端情况,非常少见,极大部分情况下还是比单级页表开销少很多很多的。
那么如何二级页表寻址呢?
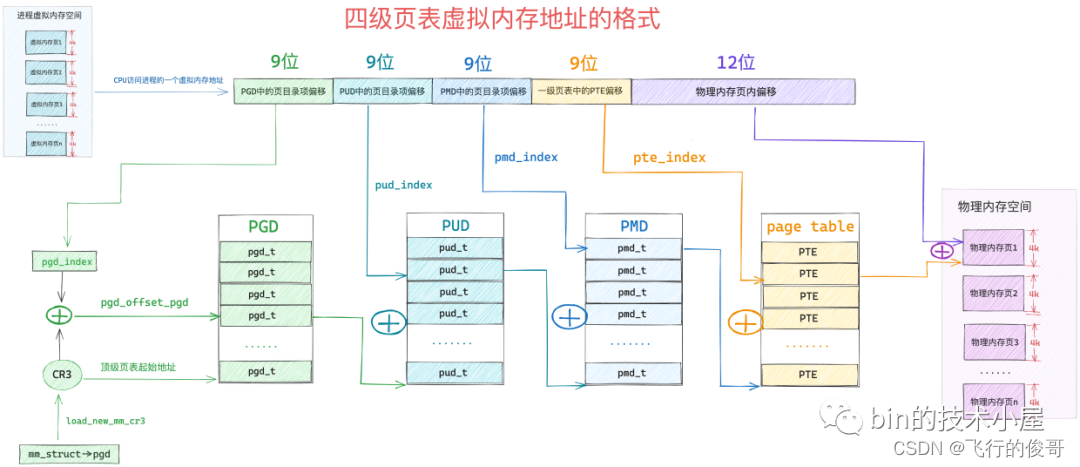
同理, 64位操作系统因为虚拟内存空间很大,一般需要四级页表体系。
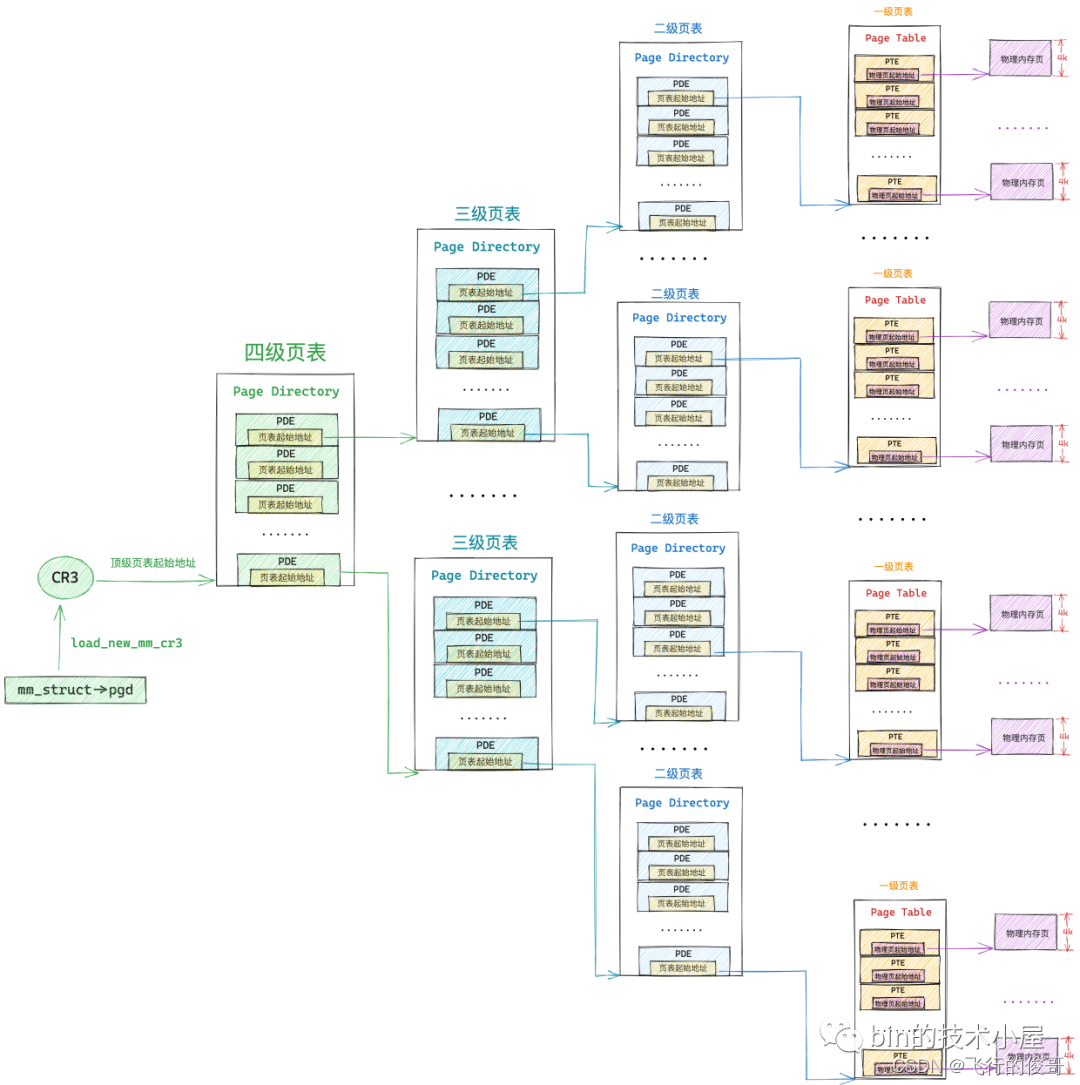
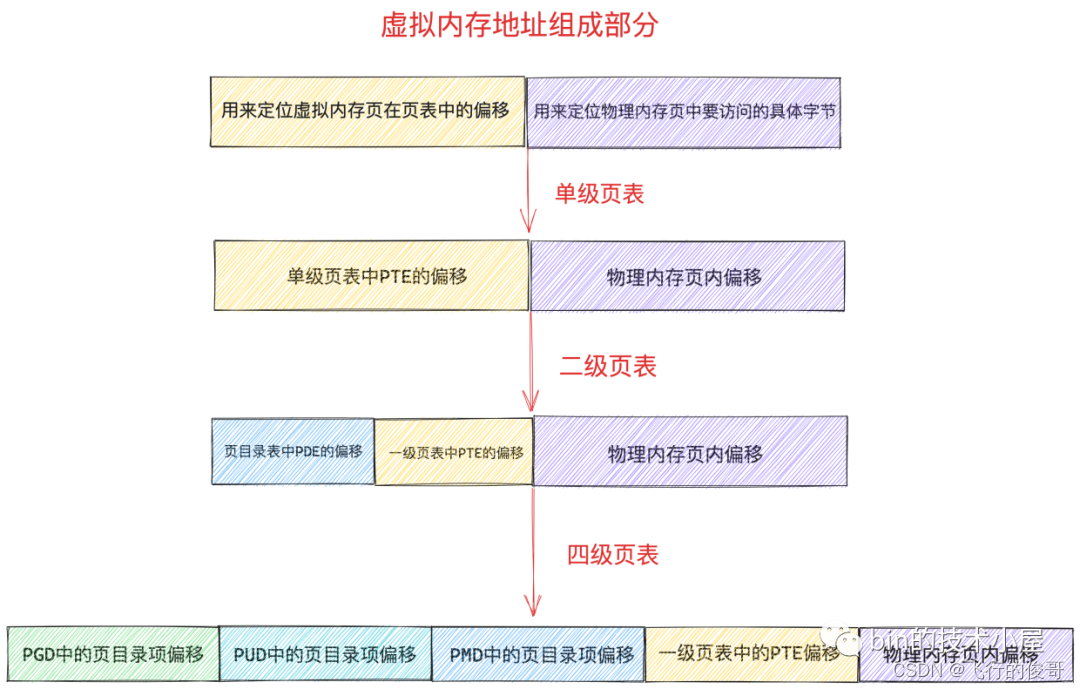
32 位系统中的页目录表,页表和 64 位系统中的页目录表,页表在内核中都是使用一个普通 4K 的物理内存页存储映射关系的,不同的是 64 位系统中的页表中的 PTE 以及页目录表(PGD,PUD,PMD)中的 PDE 都是占用 8 个字节
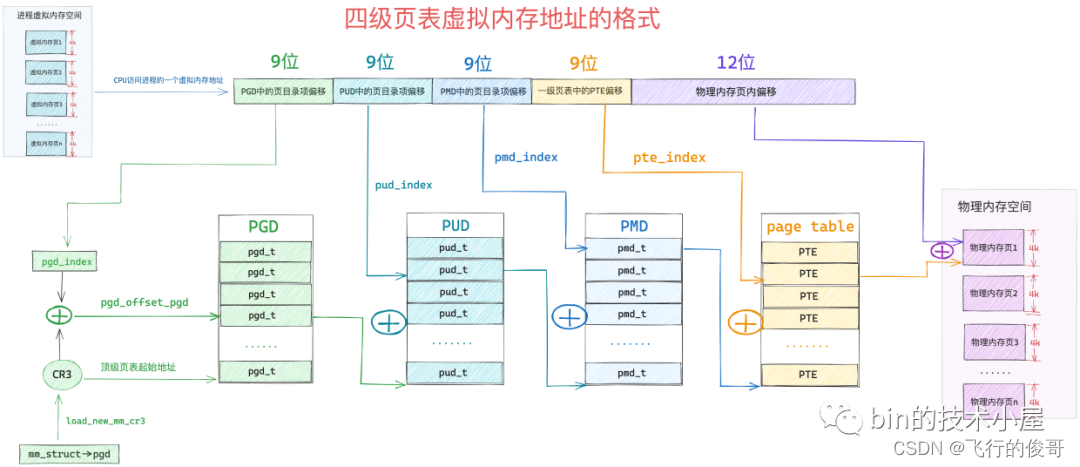
3.4 CPU的寻址过程
经过本文前边内容的介绍,上图中的这个四级页表的遍历过程,我们已经非常的清楚了,我们可以明显的体会到整个地址翻译的过程需要的步骤还是比较多的,而 CPU 访问内存的操作是非常非常频繁的,如果我们采用内核这种软件的方式对页表进行遍历,效率会非常的差。
而采用一种专门的硬件来对软件进行加速,无疑是一种最简单,最直接有效的优化手段,于是在 CPU 中引入了一个专门对页表进行遍历的地址翻译硬件 MMU(Memory Management Unit),有了 MMU 硬件的加持整个地址翻译的过程就非常的快了。
事实上,上图中展示的四级页表的整个遍历操作均是在 MMU 中进行的:
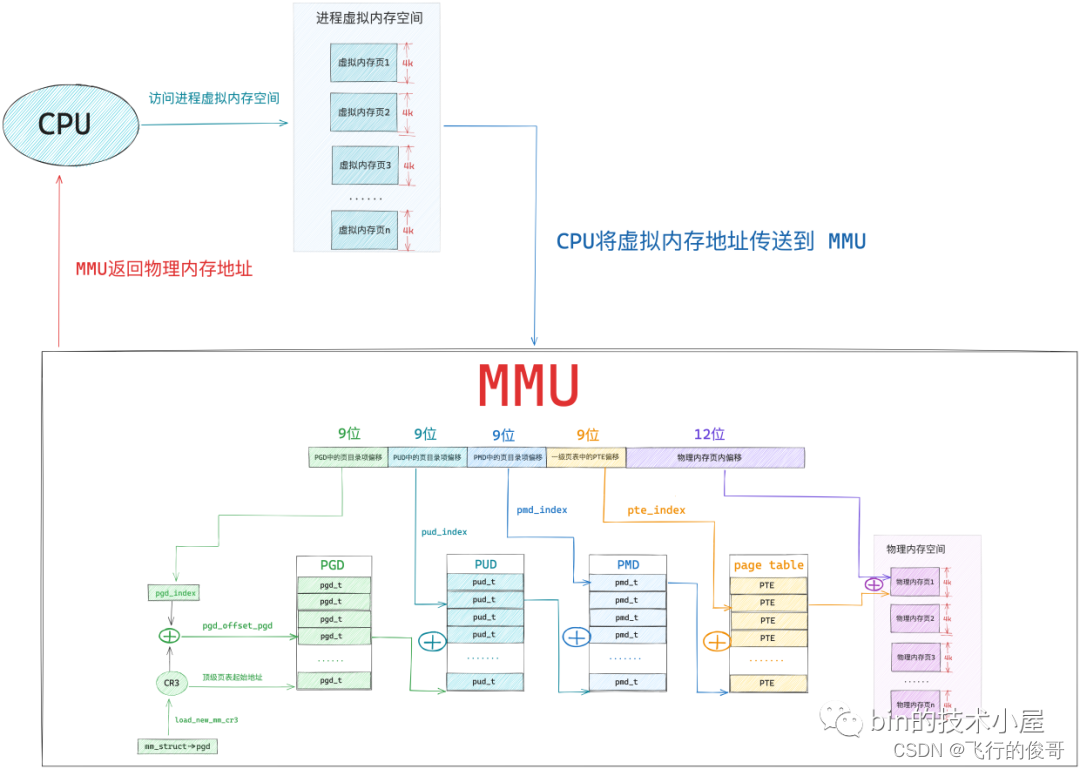
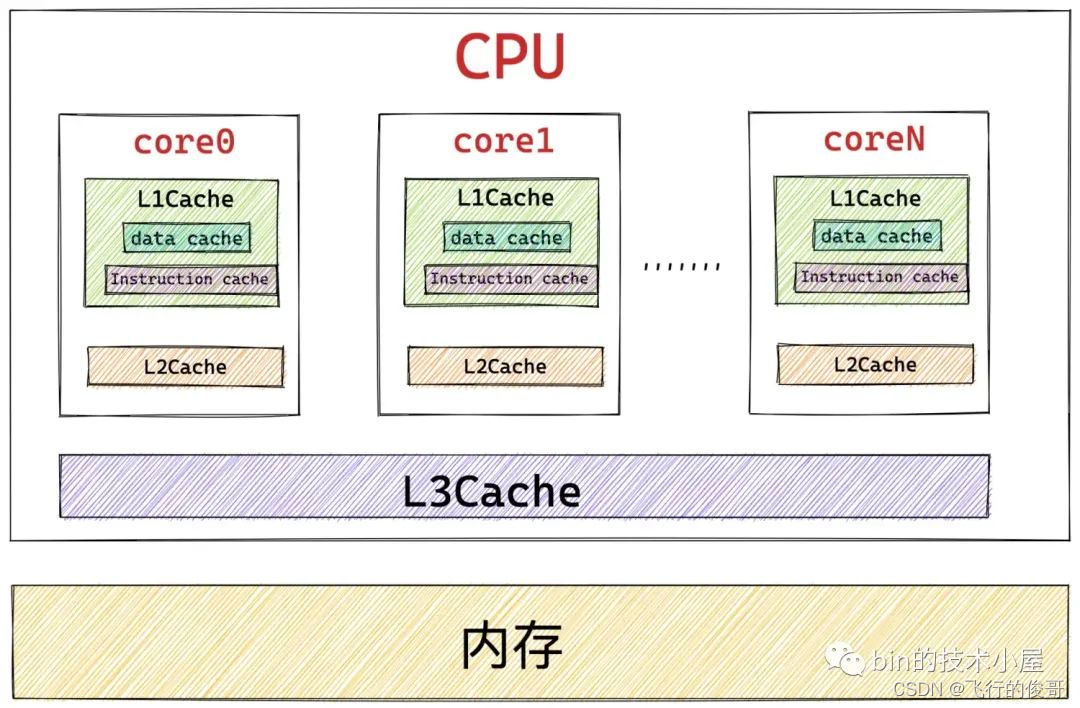
经过前边的内容我们知道,这些页目录,页表的本质其实在内核看来都是一张普通的 4K 大小的物理内存页,而物理内存页中经常被访问到的内存数据都是缓存在 CPU 的高速缓存 L1 ,L2,L3 CACHE 中的,这样可以利用局部性原理加速 CPU 对内存的访问。
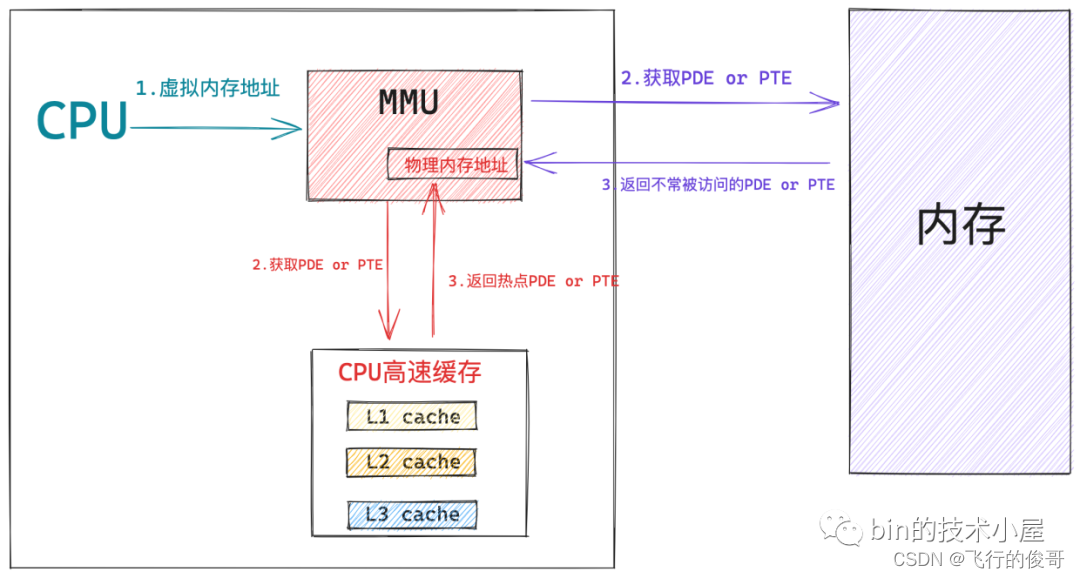
所以页目录表和页表中那些经常被 MMU 遍历到的页目录项 PDE,页表项 PTE 均会缓存在 CPU 的 CACHE 中,这样 MMU 就可以直接从 CPU 高速缓存中获取 PDE , PTE 了,近一步加速了整个地址翻译的过程。
当 MMU 拿到一个 CPU 正在访问的虚拟内存地址之后, MMU 首先会从 CR3 寄存器中获取顶级页目录表 PGD 的起始内存地址,然后从虚拟内存地址中提取出 pgd_index,从而定位到 PGD 中的一个页目录项 pdg_t,MMU 首先会从 CPU 的高速缓存中去获取这个 pgd_t,如果 pgd_t 经常被访问到,那么此时它已经存在于高速缓存中了,MMU 直接可以进行下一级页目录的地址翻译操作,避免了慢速的内存访问。
同样的道理,在 MMU 经过层层的页目录遍历之后,终于定位到了一级页表中的 PTE,MMU 也是先会从 CPU 高速缓存中去获取 PTE,如果 PTE 不在高速缓存中,MMU 才会去内存中去获取。获取到 PTE 之后,MMU 就得到了虚拟内存地址背后映射的物理内存地址了。
在我们引入 MMU 之后,虽然加快了整个页表遍历的过程,但是 CPU 每访问一个虚拟内存地址,MMU 还是需要查找一次 PTE,即便是最好的情况,MMU 也还是需要到 CPU 高速缓存中去找一下的,即便这样开销已经很小了,但是我们还是想近一步降低这个访问 CPU CACHE 的开销,让 CPU 访存性能达到极致,那么该怎么办呢?
既然 MMU 每次都需要查找一次 PTE,那么我们能不能在 MMU 中引入一层硬件缓存,这样 MMU 可以把查找到的 PTE 缓存在硬件中,下次再需要的时候直接到硬件缓存中拿现成的 PTE 就可以了,这样一来,CPU 的访存效率又被近一步加快了。
这个 MMU 中的硬件缓存就叫做 TLB(Translation Lookaside Buffer),TLB 是一个非常小的,虚拟寻址的硬件缓存,专门用来缓存被 MMU 翻译之后的热点 PTE。当我们引入 TLB 之后,整个寻址过程就又有了一些新的变化:
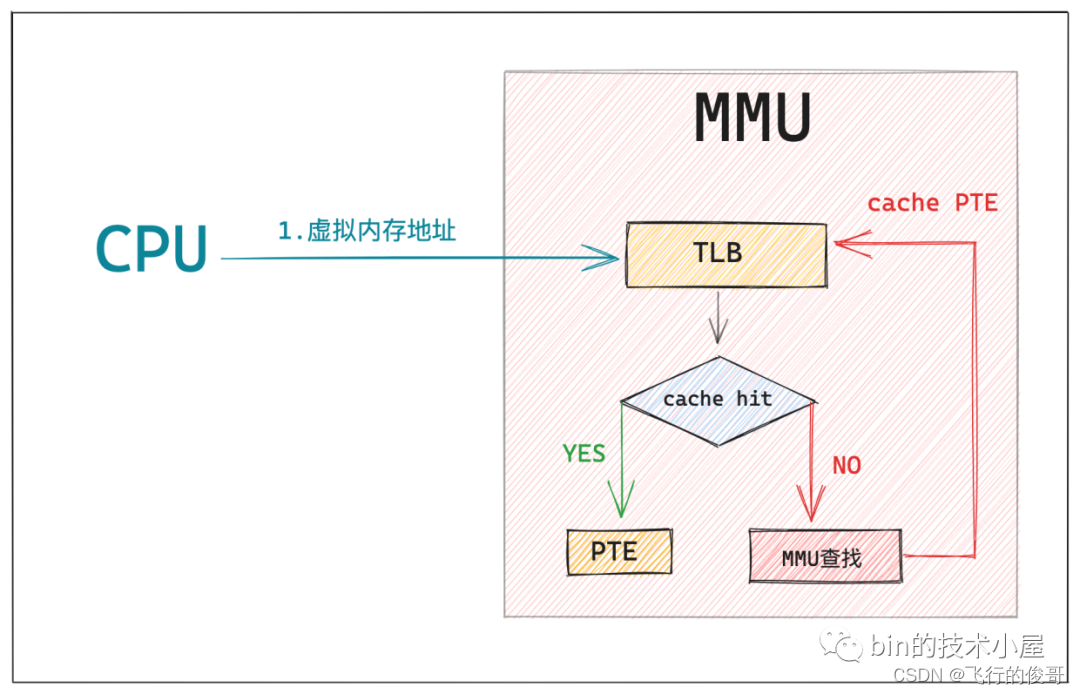
当 CPU 将要访问的虚拟内存地址送到 MMU 中翻译时,MMU 首先会在 TLB 中通过虚拟内存寻址查找其对应的 PTE 是否缓存在 TLB 中,如果 cache hit ,那么 MMU 就可以直接获得现成的 PTE,避免了漫长的地址翻译过程。
如果 cache miss,那么 MMU 就需要重新遍历页表,然后获取 PTE 的内存地址,从 CPU 高速缓存或者内存中去查找 PTE,慢速路径下获取到 PTE 之后,MMU 会将 PTE 缓存到 TLB 中,加快下一次获取 PTE 的速度。
当 MMU 获取到 PTE 之后,就可以从 PTE 中拿到物理内存页的起始地址了,在加上虚拟内存地址的低 12 位(物理内存页内偏移)这样就获取到了虚拟内存地址映射的物理内存地址了。
那么当 MMU 拿到我们最终要访问的物理内存地址之后,又该怎么办呢?
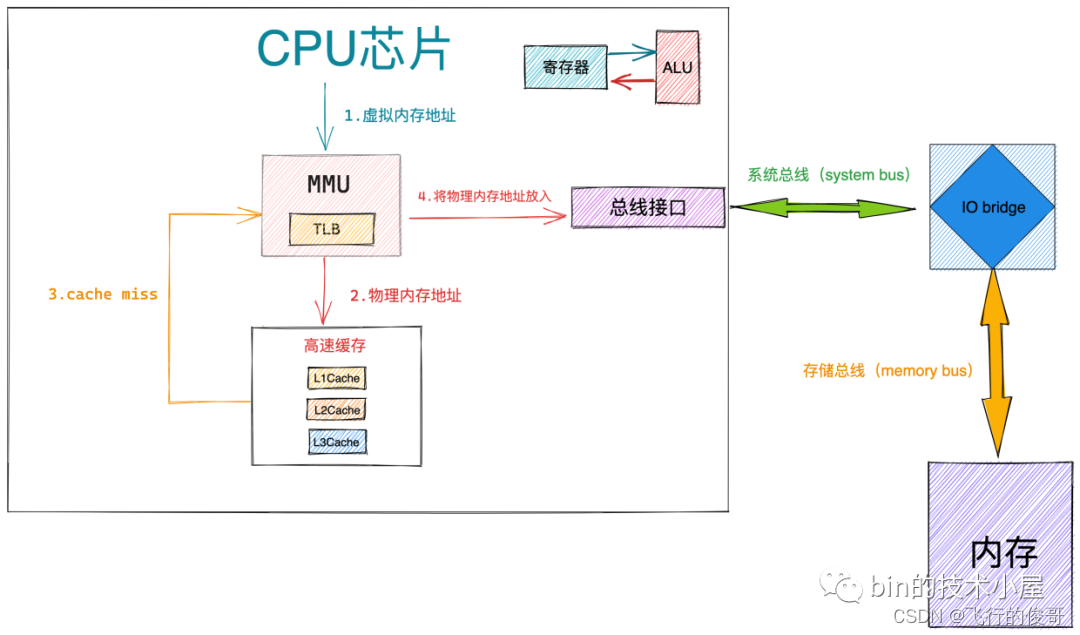
- 当 MMU 获取到最终的物理内存地址,首先会根据物理内存地址到 CPU 高速缓存中去查找数据,如果 cache hit,整个访存操作快速结束。
- 如果 cache miss,那么 MMU 会将物理内存地址放到系统总线上传输,随后 IO bridge 会将系统总线上传输的地址信号传递到存储总线上。
- 内存中的存储控制器感受到存储总线上的地址信号之后,会将物理内存地址从存储总线上读取出来。并根据物理内存地址定位到具体的存储器模块,随后解析物理内存地址从 DRAM 芯片中取出对应物理内存地址里的数据。















 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









