







样本数据
% 西瓜数据样本
% 密度,含糖量
D=[0.697 0.460;
0.774 0.376;
0.634 0.264;
0.608 0.318;
0.556 0.215;
0.403 0.237;
0.481 0.149;
0.437 0.211;
0.666 0.091;
0.243 0.267;
0.245 0.057;
0.343 0.099;
0.639 0.161;
0.657 0.198;
0.360 0.370;
0.593 0.042;
0.719 0.103;
0.359 0.188;
0.339 0.241;
0.282 0.257;
0.748 0.232;
0.714 0.346;
0.483 0.312;
0.478 0.437;
0.525 0.369;
0.751 0.489;
0.532 0.472;
0.473 0.376;
0.725 0.445;
0.446 0.459;];
y=[zeros(length(1:8),1);
ones(length(9:21),1);
zeros(length(22:30),1);];
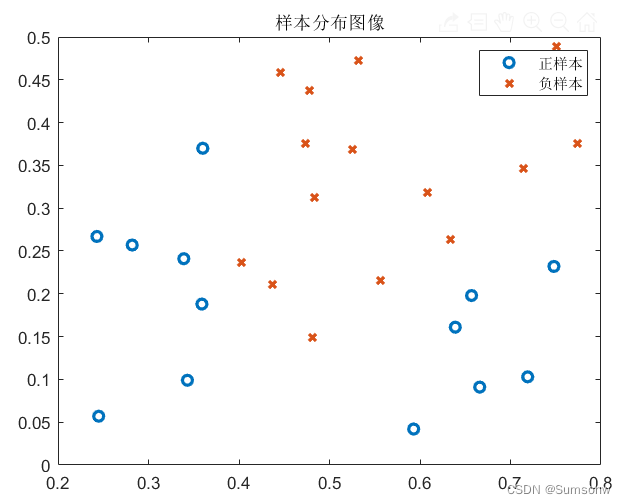
% 样本图像
figure(1)
plot(D(y==1,1),D(y==1,2),'o','LineWidth',2);
hold on
plot(D(y==0,1),D(y==0,2),'x','LineWidth',2);
title('样本分布图像')
legend('正样本','负样本')
K-mean:
聚类性能指标-外部指标
chap9_4.mlx文件

%% 1.随机生成聚类簇类
k=3;% 假设聚类簇类=3
index_u=randperm(size(D,1),k);
u=D(index_u,:);% 均值向量
echo=1000;
flag_exit=zeros(k,1);
while(echo~=0)
for i=1:k
C{i}=[];
end
%% 2.计算样本与均值向量的距离,并划分簇类
for j=1:size(D,1)
x=D(j,:);
distance_x=zeros(k,1);
for numk=1:k
distance_x(numk,:)=norm(x-u(numk,:),2);
end
[min_distance_x,index_minu]=min(distance_x);
temp=[j;x'];
C{index_minu}=[C{index_minu},temp];
end
%% 3.更新均值向量
dot_u=[];
for numC=1:k
absC=size(C{numC},2);
dot_u(numC,:)=sum(C{numC}(2:end,:)')/absC;
if dot_u(numC,:)~=u(numC,:)
u(numC,:)=dot_u(numC,:);
elseif dot_u(numC,:)==u(numC,:)
flag_exit(numC,:)=1;
end
end
if flag_exit==ones(k,1)
disp('簇类中点找到');
break;
end
echo=echo-1;
end% 循环终结
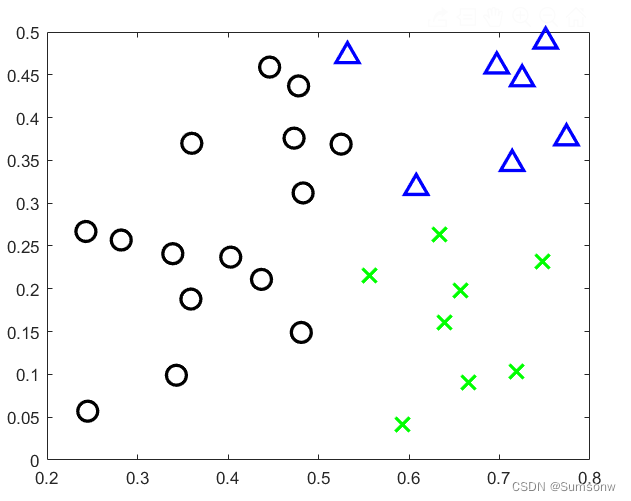
%% 显示
C1=C{1}(2:end,:)';
C2=C{2}(2:end,:)';
C3=C{3}(2:end,:)';
figure(1)
hold on
plot(C1(:,1),C1(:,2),'ko','LineWidth',2,'MarkerSize',12);
plot(C2(:,1),C2(:,2),'gx','LineWidth',2,'MarkerSize',12);
plot(C3(:,1),C3(:,2),'b^','LineWidth',2,'MarkerSize',12)


性能指标:
% 学习分类
indexc1=C{1}(1,:)'; % 分类为0
indexc2=C{2}(1,:)'; % 分类为1
yc=-1.*ones(length(indexc2)+length(indexc1),1);
yc(indexc1,:)=zeros(length(indexc1),1);
yc(indexc2,:)=ones(length(indexc2),1);
indexy1=find(y==0);
indexy2=find(y==1);
a=length(find(y(indexc1)==0))+length(find(y(indexc2)==1))
b=length(find(y(indexc1)~=0))+length(find(y(indexc2)~=1))
c=length(find(yc(indexy2)==0))+length(find(yc(indexy1)==1))
d=length(find(yc(indexy2)~=0))+length(find(yc(indexy1)~=1))
%% 三个指标
Jc=a/(a+b+c)
FMI=sqrt(a^2/((a+b)*(a+c)))
RI=2*(a+d)/(size(D,1)*(size(D,1)-1))
学习向量量化(Learning Vector Quantization)
伪代码:

% 西瓜数据样本
% 密度,含糖量
D=[0.697 0.460;0.774 0.376;0.634 0.264;0.608 0.318;0.556 0.215;
0.403 0.237;0.481 0.149;0.437 0.211;0.666 0.091;0.243 0.267;0.245 0.057;
0.343 0.099;0.639 0.161;0.657 0.198;0.360 0.370;0.593 0.042;0.719 0.103;
0.359 0.188;0.339 0.241;0.282 0.257;0.748 0.232;0.714 0.346;0.483 0.312;
0.478 0.437;0.525 0.369;0.751 0.489;0.532 0.472;0.473 0.376;0.725 0.445;0.446 0.459;];
y=[2*ones(length(1:8),1);
ones(length(9:21),1);
2*ones(length(22:30),1);];% 注意分类的标签
[m,n]=size(D);
%% LVQd 目标是学习一组n维原型的向量{p1,...pq}
% 1.初始化原型向量p={p1,.....pq}
q=5;% 聚类簇的个数
yita=0.3;%学习率
index_p=randperm(m,q);
p=D(index_p,:);
mark=2;% 样本分类标签
C=randi([1,mark],1,q);% 划分类别(假标签)
echo=1000;
% 2.LVQ算法循环-学习原型向量p
while(echo~=0)
y_index=randperm(m,1); %真实标签序列
y_flag=y(y_index,:);% 真实类别标签
xrand=D(y_index,:); %随机抽取样本
distance_xp=-ones(q,1);
for i=1:q
distance_xp(i,:)=norm(xrand-p(i,:),2);
end
[min_p_distance,min_p_index]=min(distance_xp);
p_flag=C(min_p_index);%假标签类别标签
if p_flag==y_flag
p(min_p_index,:)=p(min_p_index,:)+yita.*(xrand-p(min_p_index,:));
else
p(min_p_index,:)=p(min_p_index,:)-yita.*(xrand-p(min_p_index,:));
end
echo=echo-1;
end
% 3.划分数据-Voronoi剖分
indexR=[1:q];
disxp2=-ones(q-1,1);
flag=[];
for ii=1:q
R{ii}=[];
end
for i=1:m
x=D(i,:);
for numR=1:q
pi=p(numR,:);
pi_=p(indexR~=numR,:);
% 判断当前数据是否小于其他原型向量距离
disxp1=norm(x-pi,2);
for j=1:size(pi_,1)
disxp2(j,:)=norm(x-pi_(j,:),2);
if disxp1<disxp2(j,:)
flag(j,:)=1;
else
flag(j,:)=0;
end
end
if sum(flag)==(q-1)
R{numR}=[R{numR};x];
end
flag=[];
end
end
% 检查空簇类
for j=1:q
if isempty(R(j))==1
if j~=q
R{j}=R{q};
R{q}=[];
elseif j==q
break;
end
end
end
Color={'ro','gx','b+','k^','yv'};
%显示
hold on
plot(R{1}(:,1),R{1}(:,2),'ro','LineWidth',2,'Markersize',15)
plot(R{2}(:,1),R{2}(:,2),'gx','LineWidth',2,'Markersize',15)
plot(R{3}(:,1),R{3}(:,2),'b+','LineWidth',2,'Markersize',15)
plot(R{4}(:,1),R{4}(:,2),'k^','LineWidth',2,'Markersize',15)

高斯混合聚类:
伪代码

% 随机变量 z
k=3;% 簇类个数
echo=50;% 迭代次数
% 高斯混合分布参数初始化
% 初始均值,选取初始的簇类中心点
gauss(1).mu=D(6,:);
gauss(2).mu=D(22,:);
gauss(3).mu=D(27,:);
for i=1:k
gauss(i).sigma=0.1.*eye(n,n);
gauss(i).a=1/k;
end
while(echo~=0)
% 1.计算后验概率
for j=1:m
pz_den=0;% 求和后验概率的项先清零
x=D(j,:);
for i=1:k
% 先验概率
px(j,i)=mypro(x,gauss(i));
% 全概率
pz_den=pz_den+gauss(i).a*px(j,i);
end
% 后验概率
for i=1:k
pz(j,i)=(gauss(i).a*px(j,i))/pz_den;
end
end
sum_pz=sum(pz);
% 2.更新高斯分布参数
for i=1:k
% 更新新的均值向量
gauss(i).mu=pz(:,i)'*D./sum_pz(:,i);
% 更新新的协方差矩阵
gauss(i).sigma=(pz(:,i).*(D-gauss(i).mu))'*(D-gauss(i).mu)/(sum_pz(:,i));
% 更新新的混合系数
gauss(i).a=sum_pz(:,i)/m;
end
echo=echo-1;
end
[gamma_m,~]=size(pz);
for j=1:k
C{j}=[];
end
for i=1:gamma_m
[~,index_max]=max(pz(i,:));
x=D(i,:);
C{index_max}=[C{index_max};x];
end
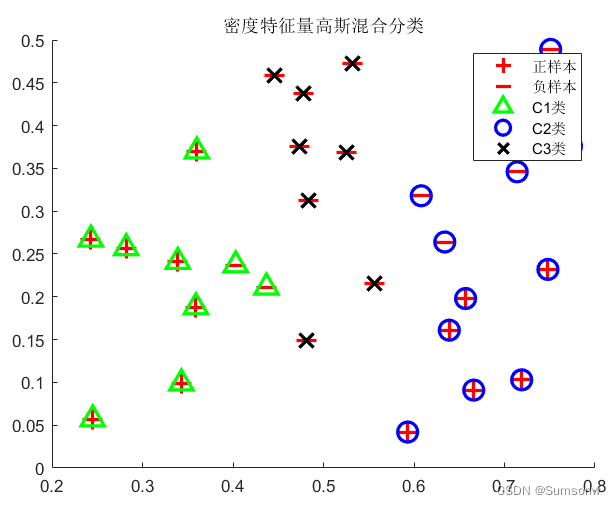
marksize=12;
figure(1)
hold on
plot(D(y==1,1),D(y==1,2),'r+','LineWidth',2,'MarkerSize',marksize)
plot(D(y==2,1),D(y==2,2),'r_','LineWidth',2,'MarkerSize',marksize)
plot(C{1}(:,1),C{1}(:,2),'g^','LineWidth',2,'MarkerSize',marksize)
plot(C{2}(:,1),C{2}(:,2),'bo','LineWidth',2,'MarkerSize',marksize)
plot(C{3}(:,1),C{3}(:,2),'kx','LineWidth',2,'MarkerSize',marksize)
legend('正样本','负样本','C1类','C2类','C3类')
title('密度特征量高斯混合分类')
%% 先验函数
function p=mypro(x,gauss)
[~,n]=size(gauss.mu);
nem=((2*pi)^(n/2))*sqrt(det(gauss.sigma));
den=exp(-0.5*((x-gauss.mu)*pinv(gauss.sigma)*(x-gauss.mu)'));
p=den/nem;
end
DBSCAN算法:
待续

AGNES算法
待续
















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









