






大概几天前 周末的时候,收到了一条异常短信通知:项目炸了 --> 内存溢出。
周末能给老板干活吗?肯定不干的。同时由于近期这个项目更新内容较多,其中包括PDF生成、HTML转PDF等等这些较为吃内存的接口。所以先让那边多加点内存重跑一下得了。
然后昨天又炸了。
还是得重视一下,马上就去看内存分析了,果然 内存泄露了。
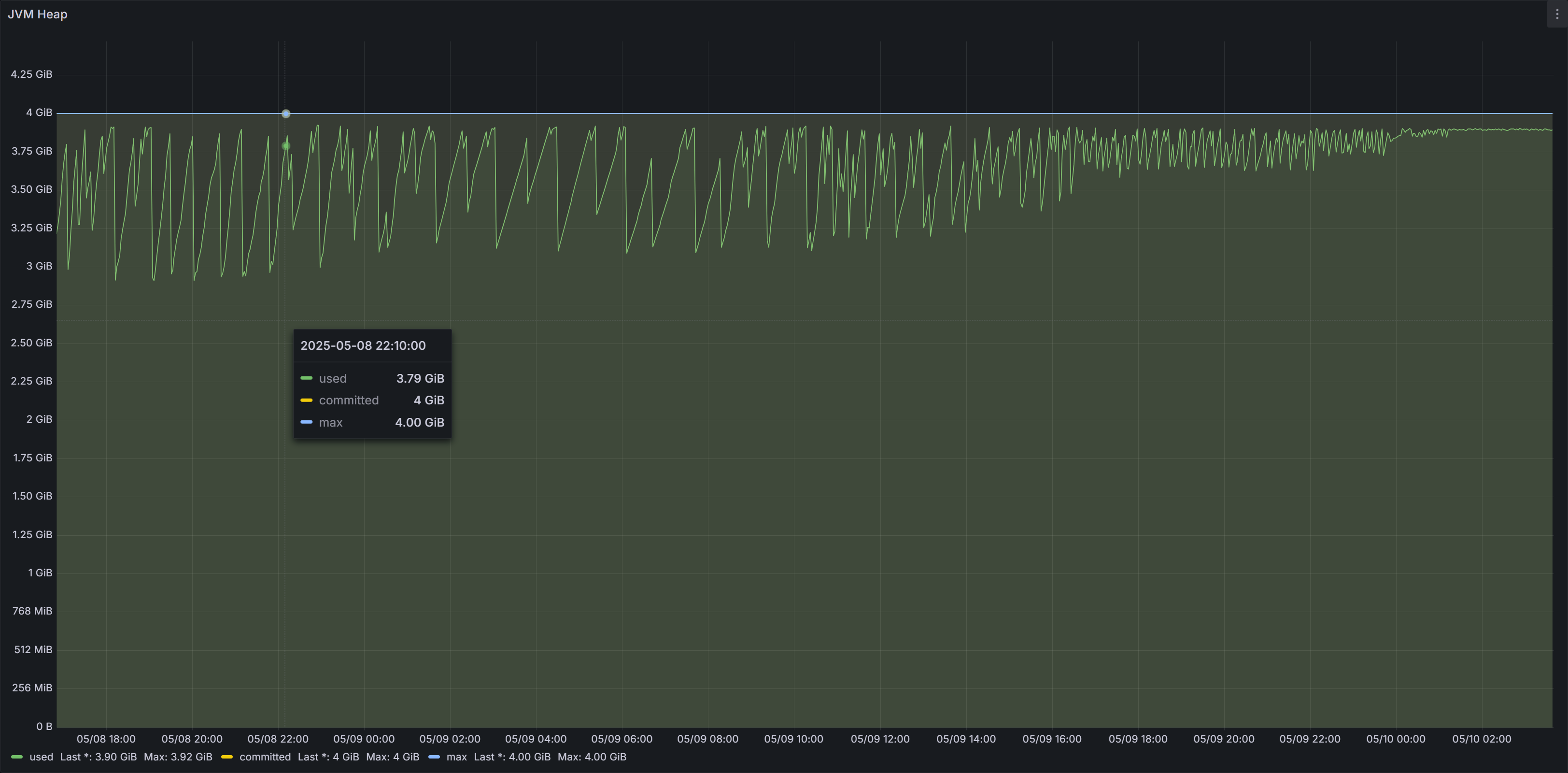
小知识点:GC 越来越频繁,且每次 GC 后内存下降幅度越来越小 大概率就是内存泄露了。
开始找问题:
1,下载内存快照

1,如果你在启动的时候,有配置自动导出内存快照,那就下载下来这个快照。也就是这个:
-Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./dump 这三个命令的意思是,记录下gc的日志,并且如果发生了OOM,自动导出堆内存快照,存放在./dump目录下。
2,如果没有,且报OOM之后,项目还未停止或重启。那可以执行这个命令导出快照:
jmap -dump:format=b,file=heap.hprof pidpid就是你要分析的 Java 进程号。可以用jps 或者 ps -ef |grep .jar找到。
那如果你没有自动导出快照,项目也重启了,那就等下次的OOM吧。
2,分析内存快照
市面上有很多分析工具,我一般就用idea 比较方便,很多参数是不如一些市面上别的产品来的直观的。但是它免费,而且啥都不用下载。感觉很不错了。后面有时间了我会分享一些别的工具。
2.1 使用idea分析hprof文件
打开心爱的IDEA,直接File -> Open 选择这个hprof打开,它会自动帮你打开好Profiler。
当然 你也可以在idea内直接打开Profiler 然后打开这个文件:
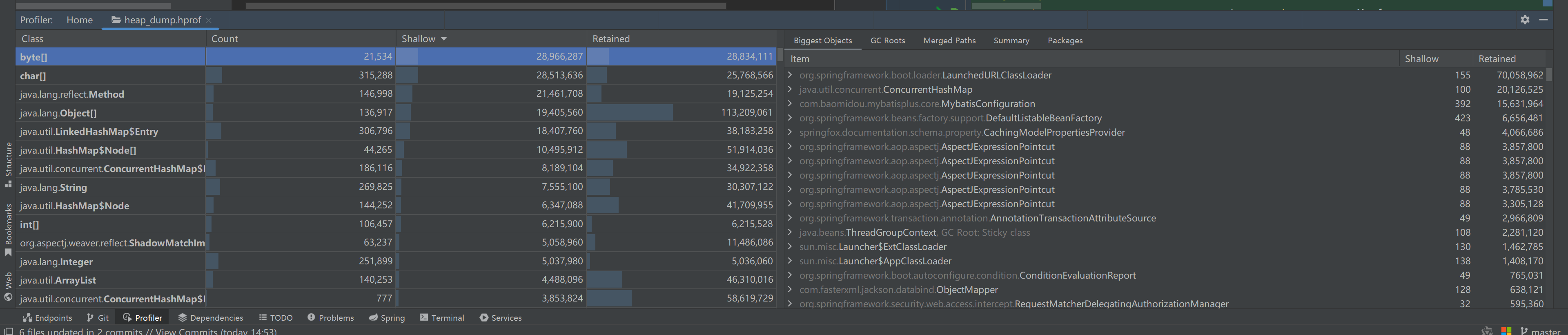
打开后就是这样:
2.2 参数详解
不论是是什么分析工具,最关键的几个肯定都有:
| 类名(Class Name) | 实例数(Instance Count) | 浅堆大小(Shallow Heap) | 保留堆大小(Retained Heap) |
|---|---|---|---|
[Ljava.lang.String; | 1000000 | 200MB | 500MB |
java.util.HashMap | 50000 | 150MB | 100MB |
| 名称 | 中文解释 | 通俗理解 |
|---|---|---|
| Shallow Heap | “浅堆大小” | 这个对象本身占了多少内存 |
| Retained Heap | “保留堆大小” | 如果释放这个对象,能一并释放的所有对象总大小(它+它引用的孩子们) |
这个保留堆大概意思是:
举个通俗的例子
一个部门主管(对象A)管理了一个部门(对象B、C、D),部门主管如果了,大家一起滚。他们都在内存中:
对象A(主管)
├─ 对象B(员工)
├─ 对象C(员工)
└─ 对象D(员工)
| 对象 | Shallow Heap | Retained Heap |
|---|---|---|
| A | 32KB | 128KB(它+它下面所有员工) |
| B | 32KB | 32KB |
| C | 32KB | 32KB |
| D | 32KB | 32KB |
那么:
-
A 的 Shallow Heap 是它自己占了 32KB
-
A 的 Retained Heap 是它+它引用的员工对象共 128KB
-
如果把 A 干掉(让它被 GC),B/C/D 也都被释放
所以排查内存问题的话有两个方面要注意 一个是它本身占用巨大,还有一个是 比如它本身占用非常小,但是保留堆巨大,是很有可能有泄露的。
所以我们直接按保留堆去排序,object就不看了。能看到几个 ConcurrentHashMap 占用巨大。
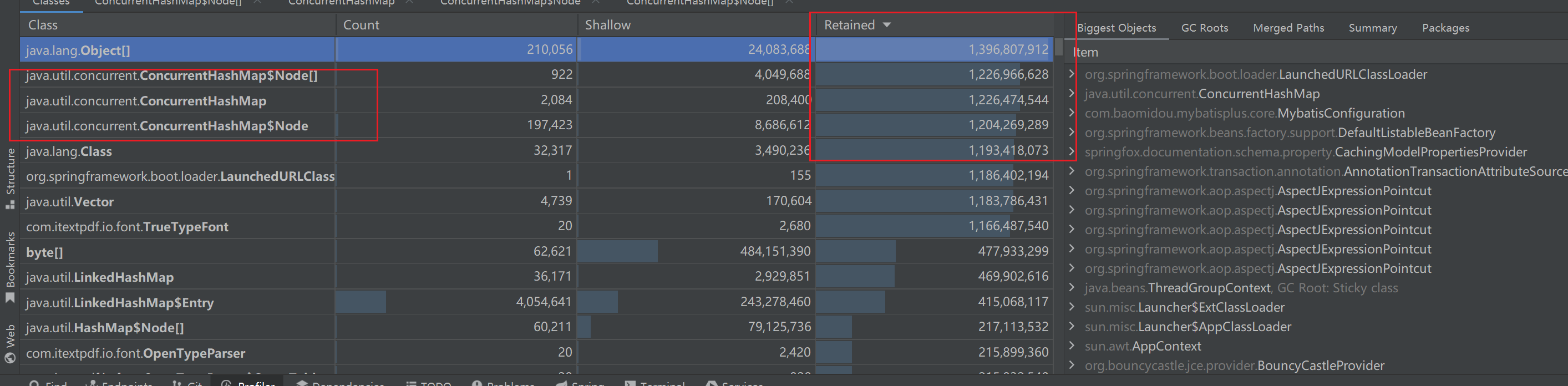
然后右边的这些的含义我列一下吧:
| 列名(标题) | 含义 | 举例说明 |
|---|---|---|
| Shortest Paths | 到 GC Root(不可回收对象根节点)的最短路径 | 是谁“绑住了”这个对象不让 GC,顺着这个路径可以找到“根源” |
| Incoming References | 谁在引用这个对象(可用于查看引用链) | 比如你看到 FontCache → ConcurrentHashMap |
| Dominators | 当前对象是否是其它对象的“主导对象” | 就是:这个对象不释放,下面的都不会释放 |
| Retained Objects | 被这个对象保持住的对象数量(不是大小) | 比如这个 Map 里面可能有 20,000 个条目 |
| Dominator Tree | 树状结构,显示主导引用链 | 你已经处在这树的某一支上了(被撑爆的那支) |
3、定位问题
从这里看过去 我们能得出几个重要结论:
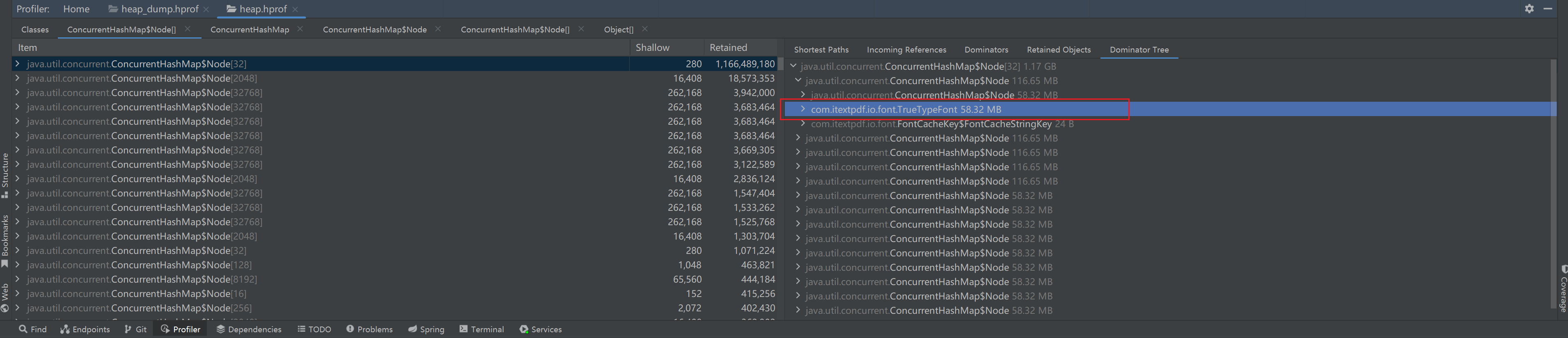
问题根源是:
com.itextpdf.io.font.FontCache
它持有了一个:
java.util.concurrent.ConcurrentHashMap
这个 Map 的大小是:
1.17 GB
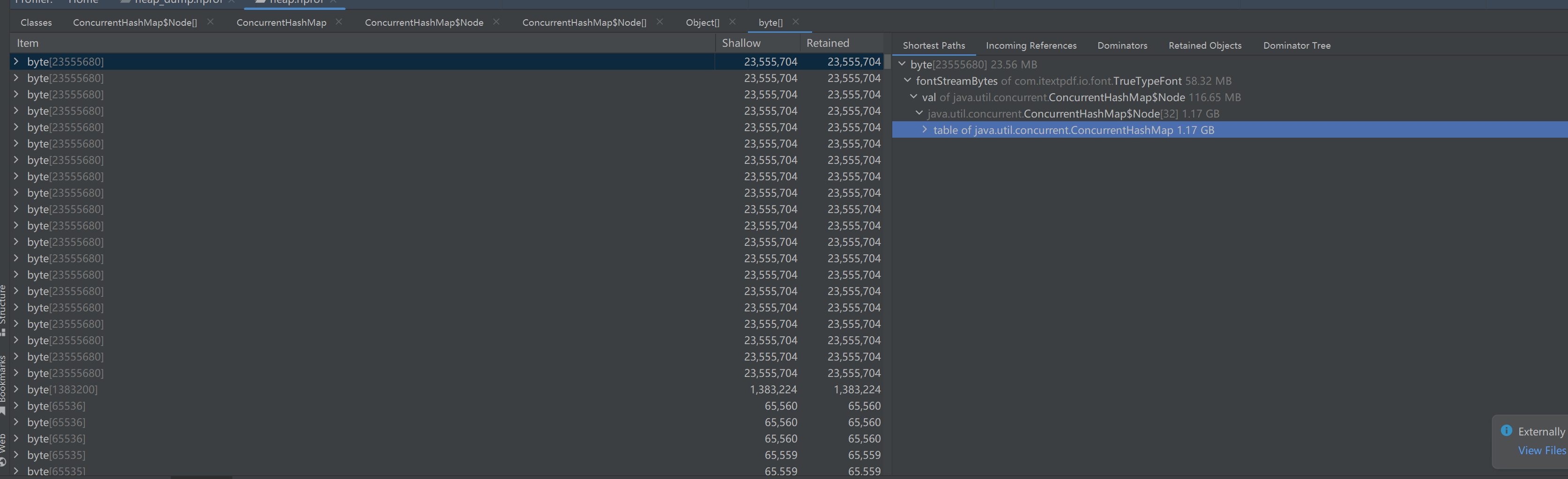
它通过:
table → ConcurrentHashMap$Node[] → elementData of Vector
保存了大约 20480 个对象,共计 1.18 GB。
我们找到 com.itextpdf.io.font.FontCache 这个类
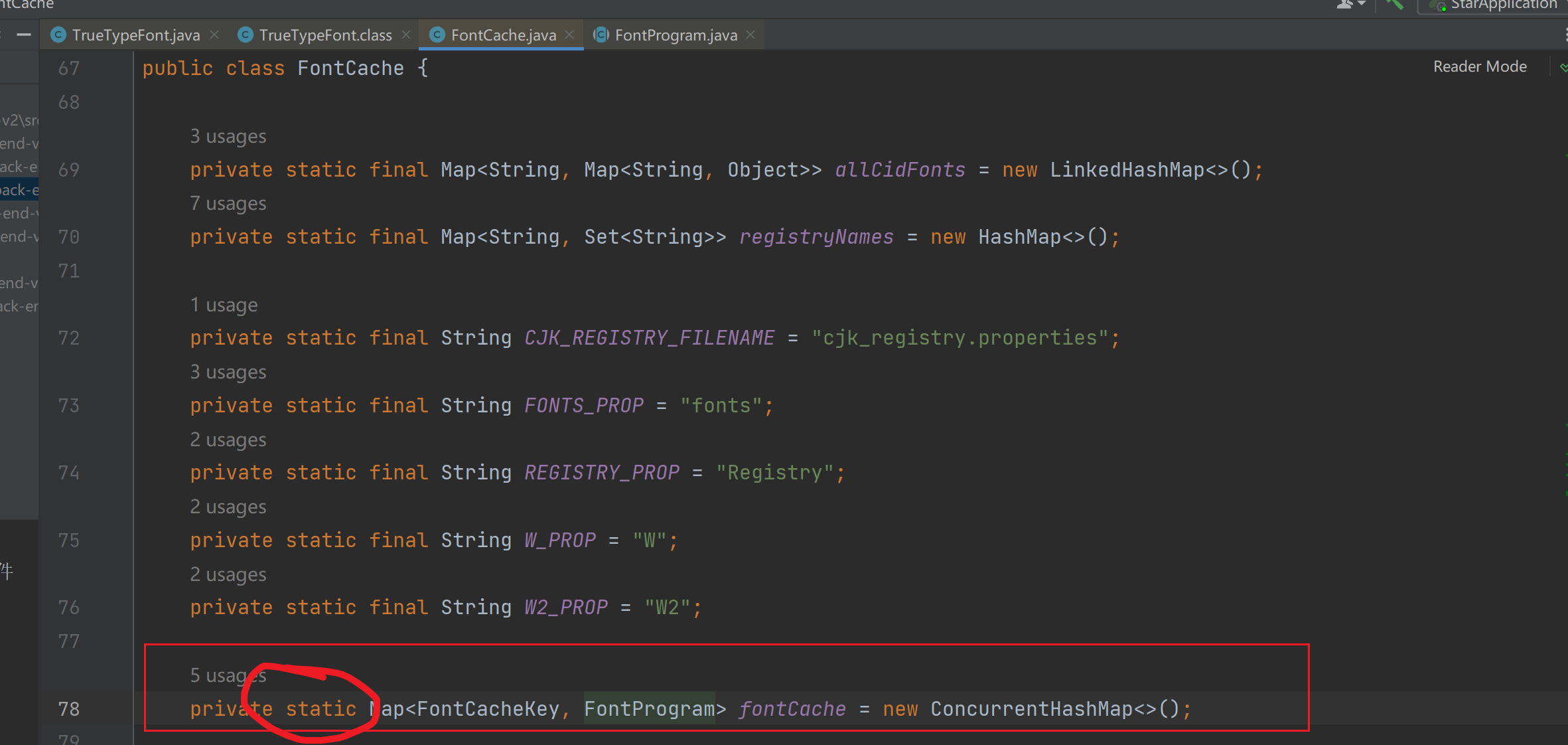
可以看到一个static的Map,也就是说它可能永远不会被 GC。
这是HTML转PDF的字体的缓存。业务代码中只有一个地方用到了这类代码:
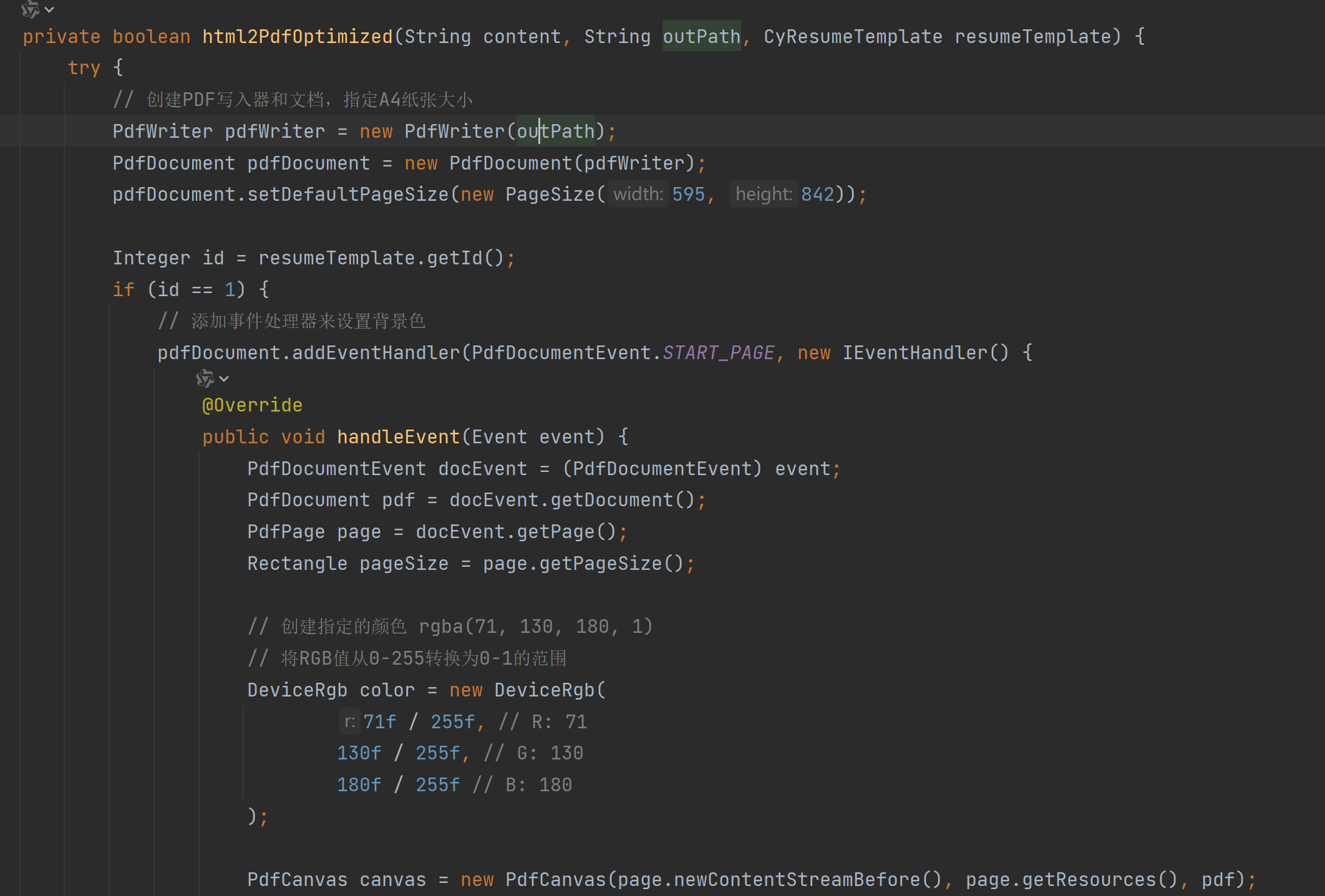
3.1 猜测
实际上还挺经常 我们定位问题是靠猜的。就感觉这里有问题,然后就去测一下。
我直接写个test接口,循环100次,就知道了。
@PostMapping("buildPdfTest")
@Anonymous
public ResponseStatusResult<String> buildPdfTest() {
try {
for (int i = 0; i < 100; i++) {
File pdfFile = null;
try {
Map<String, Object> dataModel = mock();
// 生成HTML内容
String htmlContent = freeMarkerUtils.generateFromTemplateContent(AAA, dataModel);
// 使用临时文件
pdfFile = File.createTempFile("resume_", ".pdf");
String pdfPath = pdfFile.getAbsolutePath();
boolean success = html2PdfOptimized(htmlContent, pdfPath);
// FontCache.clearSavedFonts();
} catch (Exception e) {
log.error("第{}次生成PDF失败: {}", i, e.getMessage(), e);
} finally {
if (pdfFile != null && pdfFile.exists()) {
pdfFile.delete();
}
}
}
} catch (Exception e) {
throw new BusinessStatusException(2, "批量生成PDF失败: " + e.getMessage());
}
return ResponseStatusResult.success();
}
mock 写点模拟数据
private Map<String, Object> mock() {
Map<String, Object> dataModel = new HashMap<>();
// ================= Mock 用户信息 =================
PdfUserInfoVO userInfo = new PdfUserInfoVO();
userInfo.setAvatarUrl("https://thirdwx.qlogo.cn/mmopen/vi_32/POgEwh4mIHO4nibH0KlMECNjjGxQUq24ZEaGT4poC6icRiccVGKSyXwibcPq4BWmiaIGuG1icwxaQX6grC9VemZoJ8rg/132");
userInfo.setName("张三");
userInfo.setGender("男");
userInfo.setNation("汉族");
userInfo.setEmail("zhangsan@example.com");
userInfo.setNativePlace("四川成都");
userInfo.setPhone("13812345678");
userInfo.setPersonalAdvantage("学习能力强,抗压能力强");
userInfo.setSchool("测试大学");
userInfo.setDepartment("计算机学院");
userInfo.setMajor("软件工程");
// ================= Mock 教育经历 =================
List<PdfEducationalExperienceVO> educationalExperiences = new ArrayList<>();
PdfEducationalExperienceVO edu1 = new PdfEducationalExperienceVO();
edu1.setSchoolName("测试大学");
edu1.setGraduationTime("软件工程");
edu1.setEnrollmentTime("2019-09");
edu1.setMajorName("2023-07");
edu1.setAssociationActivity("本科");
edu1.setRunningLevel("本科");
educationalExperiences.add(edu1);
// ================= Mock 工作经历 =================
List<PdfWorkExperienceVO> workExperiences = new ArrayList<>();
PdfWorkExperienceVO work1 = new PdfWorkExperienceVO();
work1.setCorporateName("字节跳动");
work1.setTitleOfPosition("Java开发实习生");
work1.setWorkingHoursS("2023-01");
work1.setWorkingHoursE("2023-06");
work1.setJobContent("参与后端接口开发与优化<br>负责用户模块的重构");
work1.setSalary("5k-8k/月");
workExperiences.add(work1);
// 添加到模型
dataModel.put("userInfo", userInfo);
dataModel.put("educationalExperiences", educationalExperiences);
dataModel.put("workExperiences", workExperiences);
return dataModel;
}
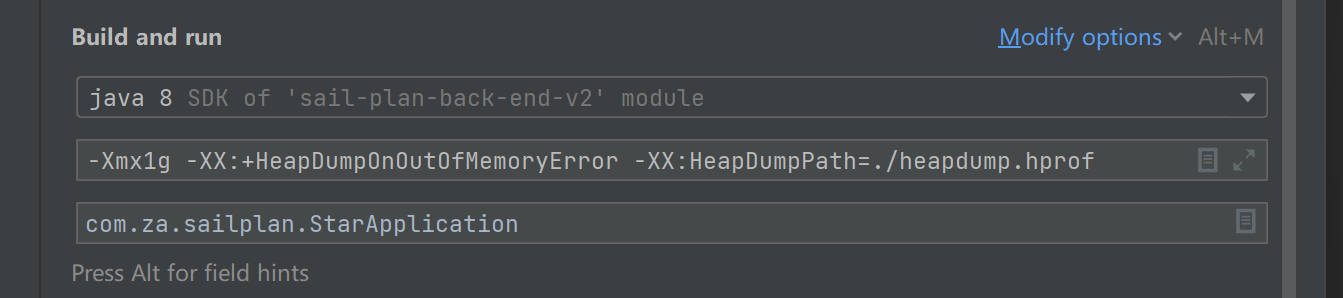
启动参数设一下:最大1G,OOM了自动生成快照
3.2 jvisualvm使用
另外这里我再教大家用个工具:jvisualvm。
在JDK的目录下的bin目录下:
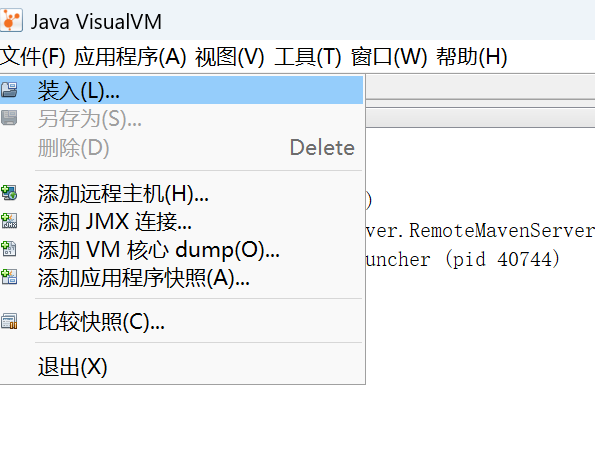
打开之后,左上角 这里装入也是能选择快照文件的。
不过我现在不是用来分析快照的。我是用来看JVM内存的,运行项目:
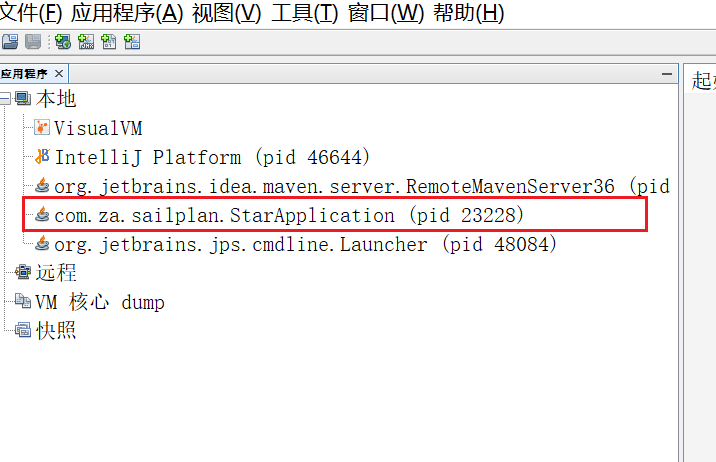
这里就能看到你的项目的pid了,双击打开 然后点击上方的监视,一个JVM的监视图就有了。
然后我们执行这个test接口,也就是循环100次,看着堆往上飙。。。
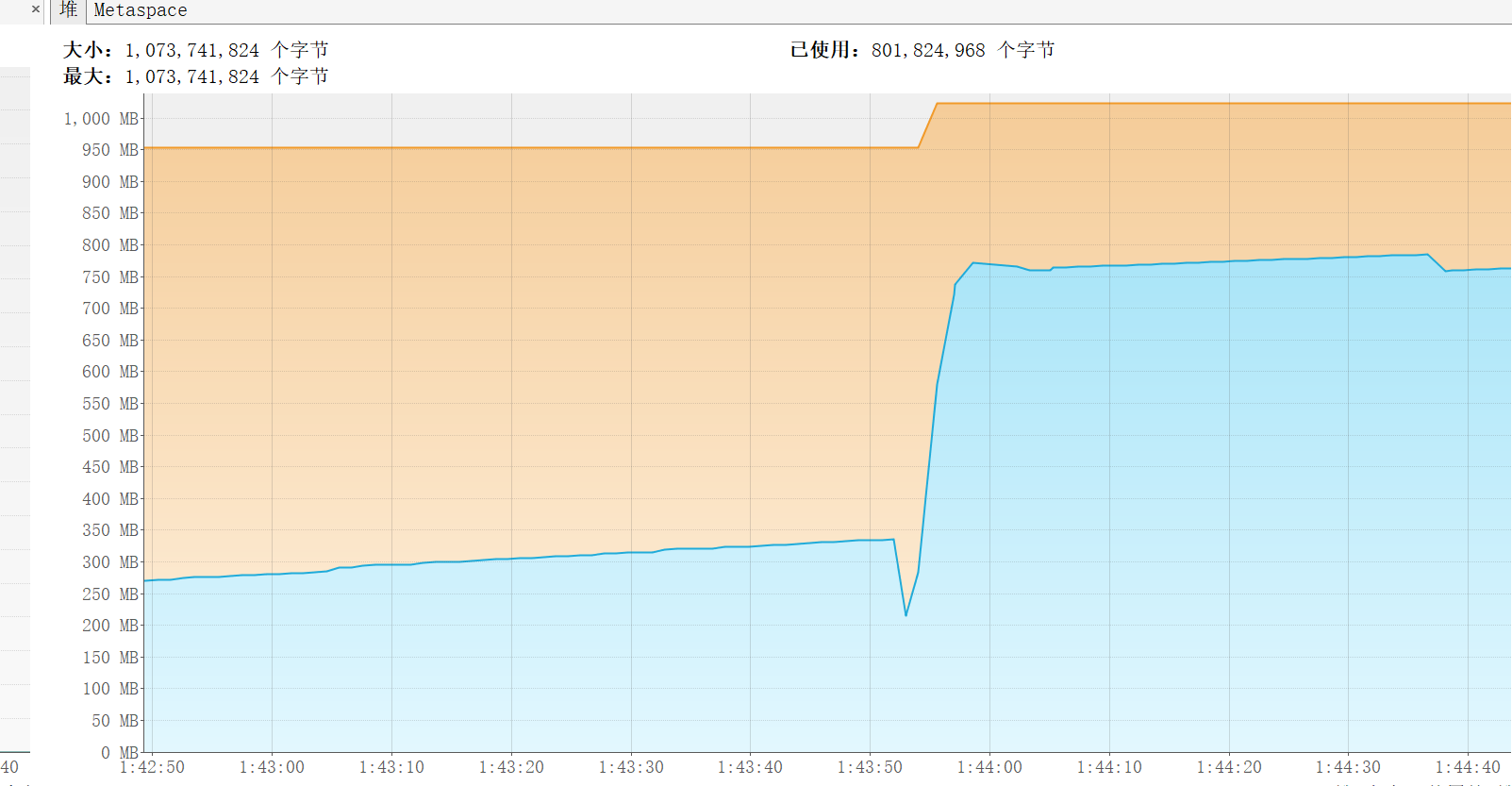
很快就OOM了。

那么这个问题就定位到了。基本上也就是按着这么个思路来,定位问题代码,然后测试一下就行。
4,问题修复
写在前头:这部分已经涉及到业务代码,和最终的PDF生成功能结合得比较紧密。也就是不关心业务的小伙伴可以跳过,或者看看思路就好了。
在调试过程中我们发现,生成 PDF 的过程中,字体文件被重复加载了很多次。从下图中我们可以看出,字体文件在不同线程/任务中不断重复被加载,这直接导致内存占用飙升,甚至出现了 OOM(内存溢出)的问题。
那么无非就是以下三种优化思路:
4.1 清理缓存 Map
首先第一种就是 Map 占用着不释放,那在转PDF之后,把map清了不就好了。
大多数 PDF 字体管理类中都会维护一个缓存 Map,避免每次都重新加载字体资源。一般这种类中都会提供一个clear之类的方法:
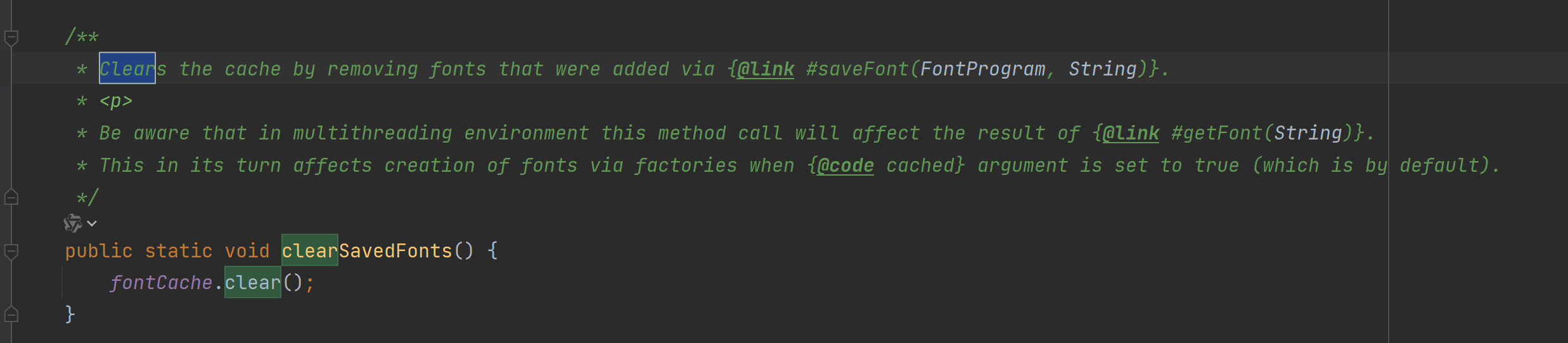
也就是这样:

不过这个方法注释上面也写了,会影响到getFont,所以在业务方要评估好会不会在高并发下频繁失效;但是我看了一遍源码,发现它的key是带时间戳的。也就是基本永远命中不了,到时让接口的开发去看看。测试后可用。
4.2 做成单例的字体加载器
第二种就是,如果我们的字体是固定使用的一种(例如统一使用“思源黑体”),那其实完全可以将字体加载器做成单例模式,只加载一次,全局复用。
优点:
-
避免重复加载
-
代码改动小,接入简单
-
性能提升明显
缺点就很明显了:并发环境下,需要保证单例是线程安全的(可以加锁或用volatile)
测试一下:
搞个单例的 FONT_PROVIDER,然后生成的代码用这个就行了。
再弄个Test2,也是一样循环100次。
@PostMapping("buildPdfTest2")
@Anonymous
public ResponseStatusResult<String> buildPdfTest2() {
try {
File pdfFile = null;
try {
Map<String, Object> dataModel = mock();
// 生成HTML内容
String htmlContent = freeMarkerUtils.generateFromTemplateContent(AAA, dataModel);
// 使用临时文件
pdfFile = File.createTempFile("resume_", ".pdf");
String pdfPath = pdfFile.getAbsolutePath();
CyResumeTemplate resumeTemplate = new CyResumeTemplate();
resumeTemplate.setId(1);
boolean success = Html2PdfOptimizedUtils.html2PdfOptimized(htmlContent, pdfPath, resumeTemplate);
// success 可用于记录日志
} catch (Exception e) {
log.error("生成PDF失败: {}", e.getMessage(), e);
} finally {
if (pdfFile != null && pdfFile.exists()) {
pdfFile.delete();
}
}
} catch (Exception e) {
throw new BusinessStatusException(2, "批量生成PDF失败: " + e.getMessage());
}
return ResponseStatusResult.success();
}
看看内存:
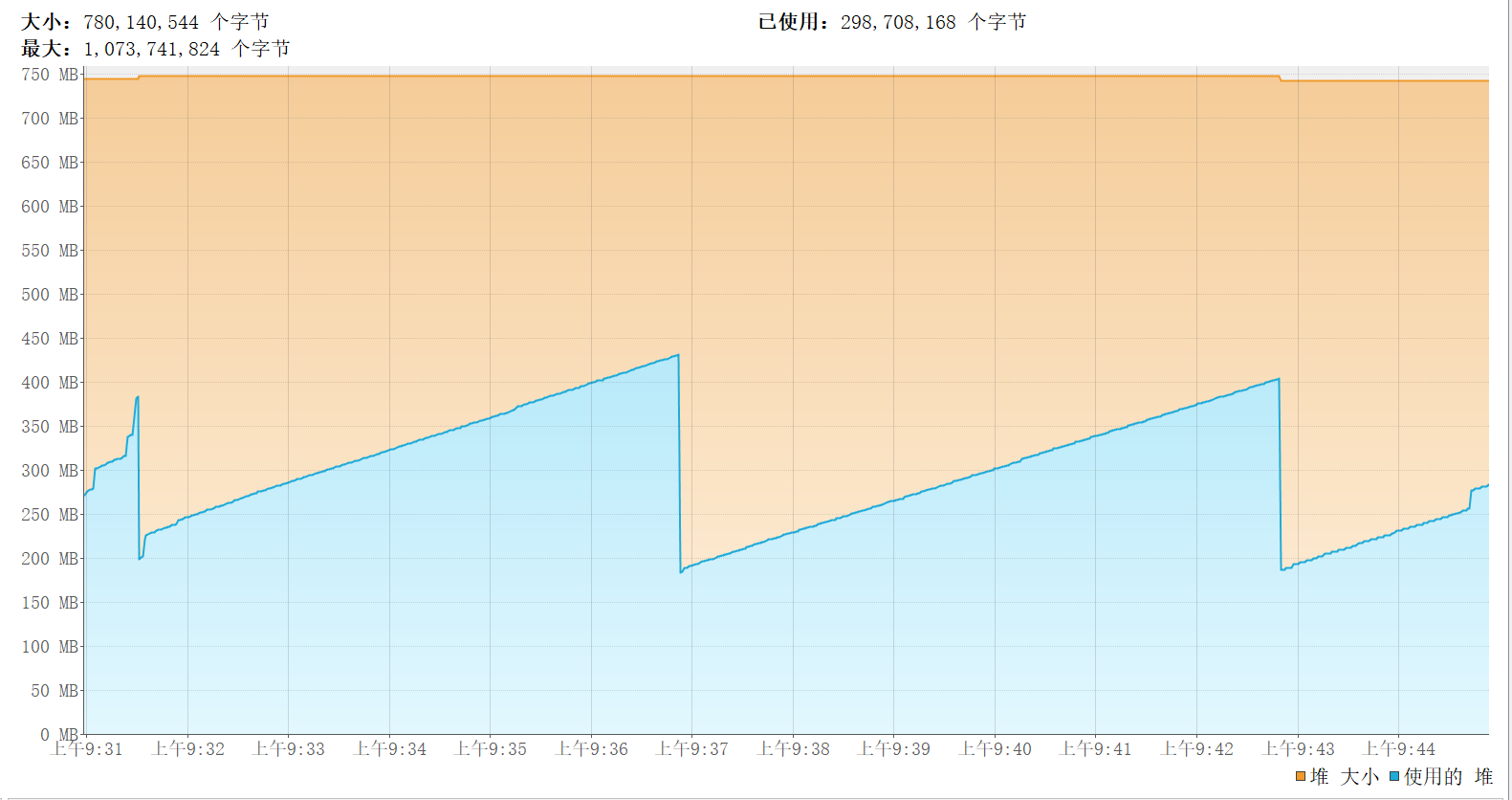
这就合理多了。
4.3 使用线程池异步执行 + 单例字体加载
其实是第二种的完善版。使用线程池 排队执行。这样就不会有并发问题,而且这样异步的处理,可以很大程度的减轻服务器压力。我个人认为我现在这个场景就完美适配。生成简历这种吃CPU的动作,还是可以这样的,然后生成完给用户发个小程序通知一下,不是完美。只不过这种需要跟产品那边商量了。我觉得麻烦,按第二点来做了。
业务流程如下:
用户点击“生成简历” → 异步线程执行 PDF 生成 → 存储文件 → 推送消息通知用户查看结果
优点:
-
性能更强,适合高并发
-
异步非阻塞,用户体验好
-
可扩展性强,后续还可以接入任务队列
好了,整体思路差不多就是这样。总的来说就是通过内存快照,找到有问题的点,再结合业务调整。
本例中的问题其实不算很简单的,因为它并不是我们自己写的代码泄露,而是业务逻辑和引入的三方包叠加导致的资源浪费。如果是自己写的类导致内存泄漏,其实反而更容易看清楚问题所在。
大家如果感兴趣的话,可以自己写一个简单的例子试试,比如搞个 for 循环,不断 new 对象然后塞进一个 List 里不释放,模拟一个典型的内存泄漏场景,内存分析一看就非常直观了。

















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









