






有一组数据,通过这组数据来建立回归方程:
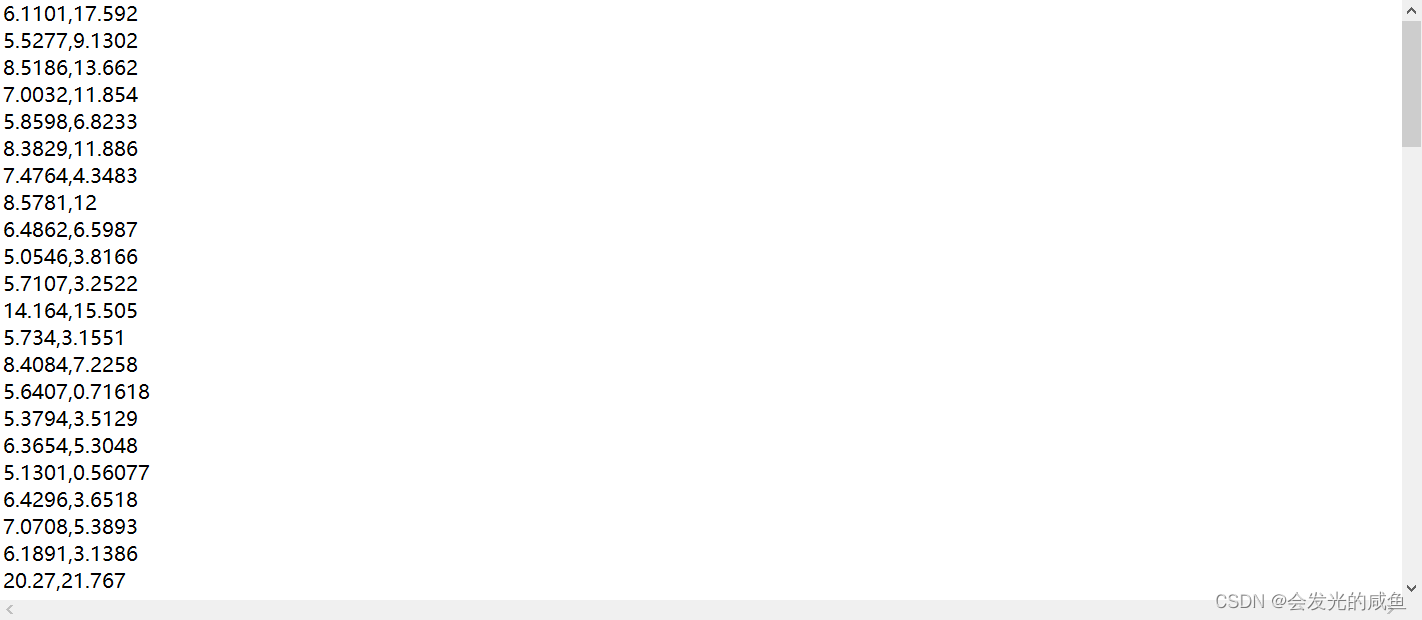 先画一个散点图:
先画一个散点图:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
#设置中文显示
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
path = 'C:/Users/Lenovo/Desktop/shuzizuoye/example/data.txt'
data = pd.read_csv(path, header=None)
plt.scatter(data[:][0], data[:][1], marker='+')#画出数据散点图
data = np.array(data)
y = data[:, 1]#y取第二列数据
x = data[:, :1]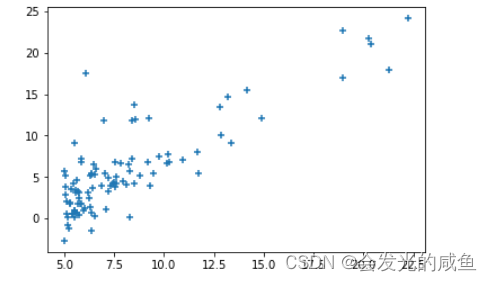
model = LinearRegression()
model.fit(x,y)
plt.scatter(x,y)
plt.plot(x,model.predict(x),color='red')
plt.xlabel('人口')#x轴随便命名--例如人口
plt.ylabel('工资')#y轴随便命名--例如工资
plt.show()
model.coef_,model.intercept_ 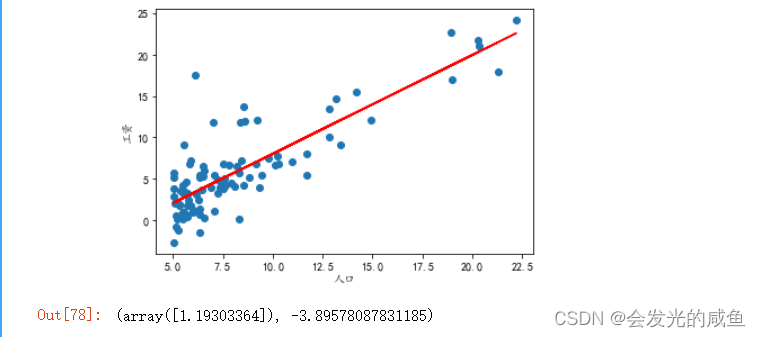
这里的1.19就是y=ax+b中的a,-3.89就是b。
但是对于有些数据来说不适合使用一次线性回归,更适合二次或者更高的此时,这里还是使用这组数据举例。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
path = 'C:/Users/Lenovo/Desktop/shuzizuoye/example/data.txt'
data = pd.read_csv(path, header=None)
plt.scatter(data[:][0], data[:][1], marker='+')#画出数据散点图
data = np.array(data)
y = data[:, 1]#y取第二列数据
x = data[:, :1]
# 用于增加一个多次项内容的模块PolynomialFeatures
from sklearn.preprocessing import PolynomialFeatures
# 设置最高次项为二次项,为生成二次项数据(x^2)做准备
poly_reg = PolynomialFeatures(degree=2)
# 将原有的X转换为一个新的二维数组X_,该二维数组包含新生成的二次项数据(x^2)和原有的一次项数据(x)。
X_ = poly_reg.fit_transform(x)
model = LinearRegression()
model.fit(X_,y)
plt.scatter(x,y)
plt.plot(x,model.predict(X_),color='r')
plt.show()
model.coef_,model.intercept_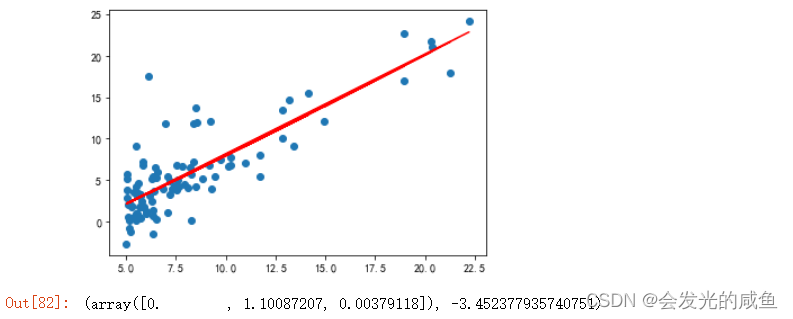 这里0代表y=ax^2+bx+c中的c,1.1代表b,0.003代表a。
这里0代表y=ax^2+bx+c中的c,1.1代表b,0.003代表a。

当degree=1时与一次回归方程一样。
建立完回归方程之后需要对方程进行评估,
R-squared(即统计学中的R2)、Adj.R-squared(即Adjusted R2)、P值。
其中R-squared和Adj.R-squared用来衡量线性拟合的优劣,P值用来衡量特征变量的显著性。
R-squared和Adj.R-squared的取值范围为0~1,它们的值越接近1,则模型的拟合程度越高;P值在本质上是个概率值,其取值范围也为0~1,P值越接近0,则特征变量的显著性越高,即该特征变量真的和目标变量具有相关性。
原文链接:https://blog.csdn.net/qq_42433311/article/details/124097370
import statsmodels.api as sm
# add_constant()函数给原来的特征变量X添加常数项,并赋给X2,这样才有y=ax+b中的常数项,即截距b
X2 = sm.add_constant(X_)
# 用OLS()和fit()函数对Y和X2进行线性回归方程搭建
est = sm.OLS(y,X_).fit()
est.summary()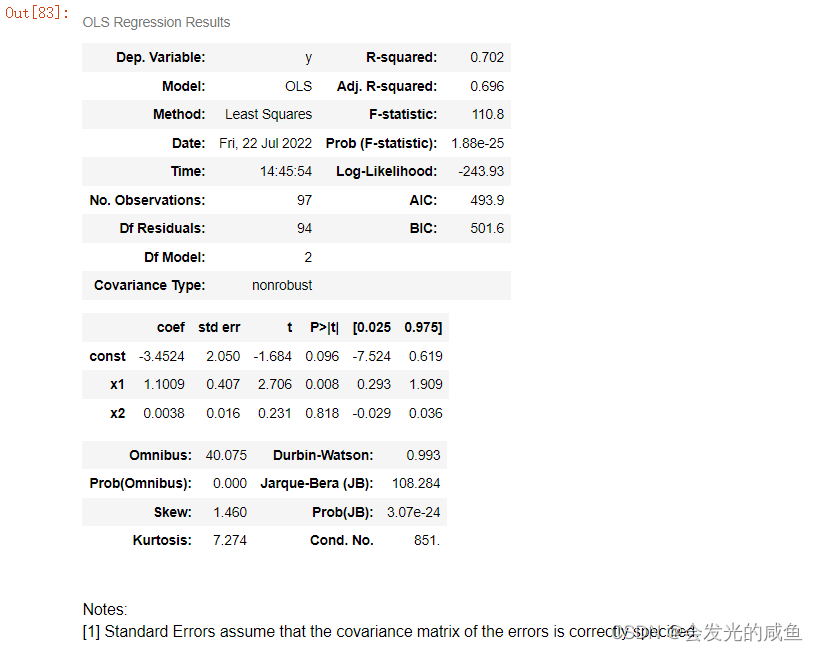
另一种计算r2的方式:
from sklearn.metrics import r2_score
r2 = r2_score(y,model.predict(X_))
print(r2)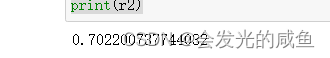


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









