






关键字: [reInforce, Bedrock, Vulnerability Threat Modeling, Role-Based Access Controls, Retrieval Augmented Generation, Fine-Tuned Model Protection, Training Data Selection]
本文字数: 1100, 阅读完需: 6 分钟
导读
在一场会议上,Dutch 和 Matrea 两位演讲者展示了”生成式人工智能用例的安全控制”。在这个演示中,他们探讨了如何根据人工智能用例的范围应用适当的安全控制措施,以保护生成式人工智能应用程序。具体而言,他们阐明对于面向消费者的人工智能应用程序(范围1和2),可以采用标准的安全控制措施,如访问控制和数据防丢失。对于使用预训练模型(范围3)或微调模型(范围4)的应用程序,需要额外的控制措施,如保护模型工件、过滤输入/输出以及控制模型访问。对于自定义构建的模型(范围5),组织需要负起确保负责任的人工智能实践并保护训练数据的责任。该演示重点介绍了亚马逊云科技服务(如Bedrock、IAM和KMS)如何通过提供模型访问、数据过滤和加密控制,实现安全部署生成式人工智能应用程序。
演讲精华
以下是小编为您整理的本次演讲的精华,共800字,阅读时间大约是4分钟。
荷兰和Matrea阐述了一种全面的方法,将技术实力与战略治理相结合,以确保生成式人工智能(Generative AI)用例的有效应用。他们的见解为人工智能的变革潜力释放出一条前进之路,同时降低了固有风险。
该方法的核心是AI范围矩阵(AI Scoping Matrix),这是一种强大的工具,将人工智能应用划分为五个不同的范围。从范围1(Scope 1)代表最小程度集成人工智能的消费者应用,到范围5(Scope 5)客户承担模型提供者的角色,从头开始构建定制的基础模型。该矩阵成为一种通用语言,有助于清晰、精确地解决每个范围所面临的独特挑战。
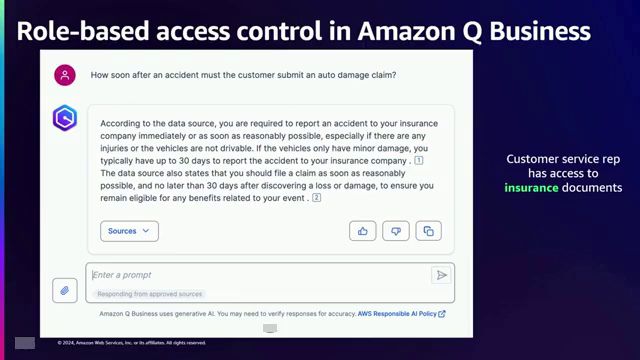
对于范围1和2,荷兰确认已建立的安全最佳实践和控制措施仍然有效。访问控制、数据防丢失措施和网络代理继续成为防范潜在漏洞的坚实屏障。他以客户服务应用程序为例阐释了这一概念,其中基于角色的访问控制(RBAC)可用于根据用户角色和所需数据来限制访问权限。例如,在保险场景中,客户服务代表可能需要访问汽车客户文档,而电子商务代表可能需要访问发票和付款信息,但无法访问技术人员可访问的技术文档。
Matrea在探索范围3至5时展现出色的专业知识,在这些范围内,人工智能集成变得更加突出。在范围3中,预训练模型或现成的基础模型(如语言模型)成为焦点。他生动地描绘了一个汽车诊断应用程序,该系统检索相关文档,将其与用户查询打包,然后发送给语言模型以获得总结响应,利用了检索增强生成(RAG)模式。该应用程序旨在通过快速获取诊断代码的根本原因、补救措施和修复方法,为汽车技术人员提供支持,从而简化故障排除过程。
对于范围3的应用程序,威胁建模需要考虑控制对模型推理端点的访问、过滤有害内容的输入和输出,以及实施传统控制措施,如Web应用程序防火墙(WAF)和速率限制。演讲者强调利用Bedrock Guardrails等功能的重要性,这些功能能够检测并拒绝有害内容,如毒性、仇恨言论或提示注入尝试,从而保护应用程序的完整性。
范围4引入了使用特定领域数据(如汽车术语和聊天记录)对预训练模型进行微调的概念。这种定制模型需要加强保护措施,包括使用亚马逊云科技 Key Management Service (KMS)密钥加密模型工件,并通过亚马逊云科技 Identity and Access Management (IAM)策略控制对微调模型推理端点的访问。演讲者提供了IAM策略提供的细粒度控制的一瞥,其中特定身份可被授予调用特定定制模型的权限,同时拒绝访问所有其他模型。
在范围5中,客户承担了模型提供商的角色,使用SageMaker等工具从头开始构建自定义基础模型。在这种情况下,责任转移到客户身上,需要选择合适的训练数据、应用负责任的AI原则并保护模型工件。演讲者强调仔细策划训练数据的至关重要性,因为删除特定数据点可能需要重新训练整个模型,这是一个资源密集型的工作。
演讲者强调利用AI范围矩阵来理解应用程序类型并应用适当的技术控制措施的重要性。这些控制措施包括访问控制、内容过滤和模型保护机制。然而,他们也强调了非技术控制措施(如流程、培训和治理)的不可或缺的作用,正如NIST网络安全框架2.0中所介绍的那样,承认确保AI应用程序安全性的多方面性质。
在整个讨论过程中,Dutch 和 Matrea 融入了现实世界的实例和应用场景,以阐明他们的观点。汽车诊断应用程序作为一个具体的场景,展示了如何采用检索增强生成(RAG)模式来提高系统响应的质量,利用相关文档和用户查询。他们还深入探讨了亚马逊云科技服务(如 IAM 和 KMS),这些服务为组织提供了精细的控制,使其能够精确管理对定制模型及其相关加密密钥的访问。
他们的演讲最终呼吁安全从业者采用一种全面的方法,将技术和非技术控制相结合,并根据特定的应用场景和范围进行量身定制。通过采用这种全面的策略,组织可以自信地驾驭生成式人工智能应用程序的复杂环境,降低风险,释放这些变革性技术的全部潜力,同时确保遵守负责任的人工智能原则,并保护专有数据和知识产权。
下面是一些演讲现场的精彩瞬间:
在这一段中,演讲者将简要概述在使用人工智能应用程序时如何考虑控制或补偿控制措施。

基于角色的访问控制(RBAC)是根据用户的角色来确定其对数据和应用程序的访问权限,从而实现精细化的权限管理。
汽车制造商利用预训练语言模型构建交互式诊断手册应用程序,帮助技术人员快速解决问题并获取修复方案。

通过语义搜索和语言模型,该应用程序能够快速为诊断技师提供相关文档、可能的故障根源及排除步骤,大大提高了故障诊断和修复的效率。

因此,对于生成式人工智能应用程序,需要采取额外的安全措施,例如控制对模型推理端点的访问权限,确保只有经过授权的应用程序才能调用模型,这不仅出于安全原因,也出于成本原因,因为每次调用模型都会产生费用。

重要的是,在使用数据训练模型时,要非常小心谨慎地选择训练数据集,因为一旦包含了个人身份信息等敏感数据,要移除它们就需要重新训练整个模型。

总结
- 针对面向消费者的应用程序(范围1和2),传统的安全控制措施如基于角色的访问控制(RBAC)、数据丢失防护(DLP)和网络代理(Web Proxies)依旧适用,因为人工智能组件并不会从根本上改变安全格局。
- 在使用预训练模型或对其进行微调时(范围3和4),保护模型工件(Model Artifacts)、控制模型推理端点(Model Inference Endpoints)以及过滤有害输入/输出等额外措施变得至关重要。
- 在从头构建定制模型的情况下(范围5),责任转移到组织层面,以确保在训练过程中遵循负责任的人工智能实践、数据隐私和偏差缓解。
总的来说,信息强调了采用整体方法的必要性,该方法将技术控制措施(如访问管理、内容过滤和加密)与非技术措施(如治理框架、培训和组织准备)相结合。通过了解其人工智能应用程序的范围并实施适当的保护措施,组织可以在确保生成式人工智能安全的同时,发挥其变革潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









