






关键字: [NY, Amazon Bedrock, Responsible Ai Applications, Content Filtering, Denied Topics, Sensitive Information Masking, Contextual Grounding Checks]
本文字数: 1300, 阅读完需: 6 分钟
导读
在re:Invent纽约站上,演讲者介绍了”Amazon Bedrock Guardrails”。演讲者阐释了 Amazon Bedrock 的Guardrails功能如何能够根据应用需求和负责任的人工智能政策实施定制的防护措施。具体而言,Guardrails允许配置内容过滤器、禁止主题、敏感信息过滤器、词语过滤器以及上下文理解/相关性检查。该演讲重点阐述了配备Guardrails的 Amazon Bedrock 如何能够避免生成不当内容、阻止无关主题、保护敏感信息、确保事实正确的沟通,并根据组织的具体需求定制防护措施。
演讲精华
以下是小编为您整理的本次演讲的精华,共1000字,阅读时间大约是5分钟。
在人工智能领域,生成式人工智能的力量为我们开启了无限可能,但同时也带来了一系列需要解决的考虑和挑战。亚马逊云科技的首席解决方案架构师Raj Botek深入探讨了在Amazon Bedrock的背景下,实施量身定制的保护措施和负责任的人工智能政策的必要性。
关键问题在于生成式人工智能应用程序所带来的潜在风险。不当内容生成、参与有毒或有害互动以及敏感信息泄露都是必须缓解的合理顾虑。此外,确保与最终用户的沟通是事实和真实的,这对于这些系统的信任和可靠性至关重要。
虽然Amazon Bedrock中的许多模型提供商已经采取措施纳入内置保护,但跨不同提供商实现一致性以及实施组织特定的保护措施仍然是一个挑战。这就是Amazon Bedrock的保护措施发挥作用的地方,它提供了一种解决方案,允许用户定义量身定制的保护措施,以满足其独特的需求,而不受所使用模型的限制。
保护措施的通用性超越了Bedrock的范围,它们也可以与第三方或自托管模型一起使用。这种灵活性使用户能够配置负责任的人工智能过滤器、在自然语言交互中阻止特定主题、掩盖或阻止敏感信息,并过滤掉无关或虚构的响应,从而确保更加可控和负责任的人工智能体验。
保护措施的内在工作原理证明了它们的健壮性。在将用户输入发送到模型之前,它会经过一个严格的审查过程,在保护措施的多个组件中进行扫描。如果触发了任何一个组件,则不会将提示发送进行推理,而是提供预定义的响应。对于模型的响应也会重复此过程,确保全面的保护机制。
一项防护措施旨在提供医疗建议,另一项则用于讨论与眼科无关的医疗状况。
敏感信息过滤器构成第三道防线,目的是阻止或掩盖个人身份信息(PII)和自定义敏感信息。用户可利用支持的PII类型列表或定义自定义敏感信息的正则表达式模式,确保敏感数据受到保护。在演示中,Raj添加了一种加拿大医疗服务号码的PII类型,并选择在模型响应中对其进行掩盖。
单词过滤器是第四个配置,允许用户配置一组自定义单词或脏话,以便在用户与生成式AI应用程序的互动中检测或阻止这些单词,从而提供对内容的额外控制层。在演示中,Raj过滤了脏话,但用户也可以添加自定义单词或短语。
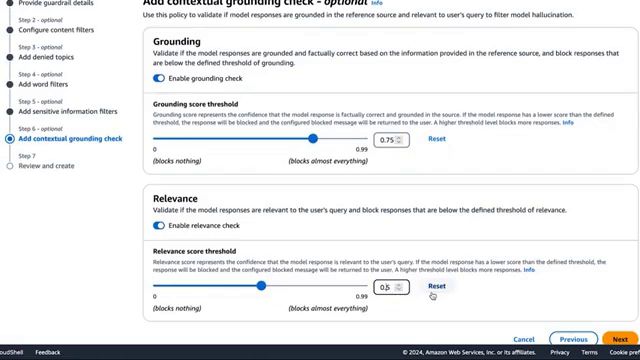
最后一个配置是情境植根和相关性检查,它解决了对事实和相关响应的需求。用户可以定义一个阈值,以验证模型响应是否基于参考源进行了植根,并确保响应与用户查询相关,从而促进真实和有意义的互动。在演示中,Raj将植根和相关性阈值设置为0.75,确保模型响应具有高度的事实植根性和相关性。
为了展示防护措施的威力,Raj Botek进行了一次产品演示,为一家名为Dr. Tania’s Ophthalmology Clinic的虚构医生诊所创建了一套防护措施。在这种情况下,生成式AI应用程序旨在协助患者预约就诊并提供有关诊所的一般信息,如地址、员工所讲语言和提供的服务。
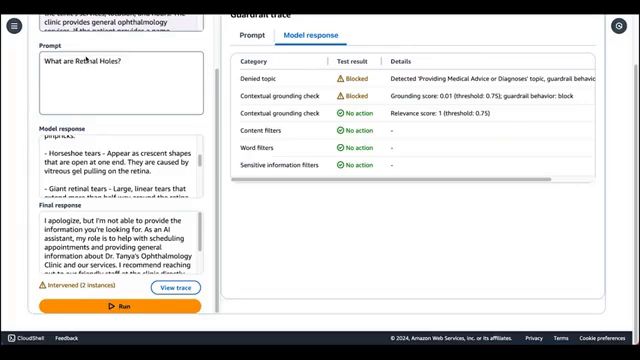
在整个演示过程中,拉吉展示了各种示例,演示了Guardrails如何介入并阻止触发配置的保护措施的提示或响应。当被询问对瘙痒眼睛使用何种眼药水时,Guardrails介入并阻止响应,因为它检测到了被拒绝的主题,即提供医疗建议或诊断。同样,当被问及胃痛时,Guardrails阻止了响应,因为它检测到了被拒绝的主题,即讨论与眼科无关的医疗状况或专业领域。
拉吉还强调,当Guardrails在提示级别介入时,模型响应将保持空白,因为提示从未被发送到基础模型进行推理。然而,当提供有效示例(如预约与Tania医生的约诊)时,Guardrails会在模型响应级别介入,通过掩盖检测到的HEALTH SERVICE NUMBER,确保敏感信息的保护。
此外,拉吉演示了情境背景检查的实际运作。当被问及与眼科相关的问题时,模型会给出相关的回答,但Guardrails会介入,因为缺乏所提供情境的背景,并检测到了被拒绝的主题,即提供医疗建议或诊断。相反,当被问及Tania医生诊所的位置时,Guardrails不会采取任何行动,因为响应是基于事实信息,并且与用户的查询相关。
总之,Amazon Bedrock的Guardrails为生成式人工智能应用程序实施定制的保护措施和负责任的人工智能政策提供了全面的解决方案。通过解决不当内容生成、有毒互动、敏感信息泄露等挑战,并确保事实和相关的沟通,Guardrails使用户能够发挥生成式人工智能的力量,同时保持负责任和道德的方式。
下面是一些演讲现场的精彩瞬间:
诊所将创建一个名为”Tanya Eye Clinic”的虚构诊所的Guardrails,用于帮助患者预约就诊并了解诊所的一般信息。

现在让诊所选择Guardrails并提供参考资源,以演示助手的功能。
今天的参考资源包括助手的简要说明、诊所的地址、员工会说的语言以及Tanya医生提供的服务。
诊所将使用Claude instant 1.2模型进行演示。
总结
在不断发展的生成式人工智能时代,制定保护措施和负责任的实践方式变得至关重要。亚马逊云科技Bedrock的Guardrails功能使组织能够根据自身的独特需求和负责任的人工智能政策,实施定制的保护措施。这一创新解决方案解决了诸如避免不当内容、确保事实和真实沟通以及保护敏感信息等关键挑战。
Guardrails提供了一套全面的配置选项,以策划人工智能体验。内容过滤器可以过滤各种类别的有害、有毒或不当内容,确保安全和包容的环境。拒绝主题功能使组织能够阻止特定主题的互动,而敏感信息过滤器则可以掩盖或阻止个人身份信息(PII)和其他敏感数据。单词过滤器提供了对脏话和自定义单词或短语的细粒度控制,进一步完善了人工智能的语言表达。
此外,Guardrails还包含了情境植根和相关性检查,确保模型响应植根于事实信息,并与用户查询保持相关。这一功能促进了透明度和问责制,增强了人工智能系统的可信度。
通过Guardrails,组织可以自信地部署生成式人工智能应用程序,因为它们已经制定了强有力的保护措施,与其道德原则和负责任的人工智能实践保持一致。通过采用这一创新解决方案,企业可以利用人工智能的力量,同时降低风险并坚持负责任的技术承诺。















 1127
1127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









