







文章目录
基础网络结构
facenet
-
主干网络:resnet50
-
损失函数:nn.CrossEntropyLoss() + 三元组损失
pyTorch实现
facenet
import torch
from torchvision.models.resnet import resnet50
from torch import nn
import torch
from torch.nn import functional as F
class FaceNetModel(nn.Module):
def __init__(self, emd_size = 256, num_class = 1000):
super(FaceNetModel, self).__init__()
self.emd_size = emd_size
self.resnet = resnet50()
self.faceNet = nn.Sequential(
self.resnet.conv1,
self.resnet.bn1,
self.resnet.relu,
self.resnet.maxpool,
self.resnet.layer1,
self.resnet.layer2,
self.resnet.layer3,
self.resnet.layer4,
)
self.fc = nn.Linear(32768, emd_size)
self.l2_norm = torch.nn.functional.normalize
self.fc_class = nn.Linear(emd_size, num_class)
def forward(self, x):
x = self.faceNet(x)
#x = x.view(x.size(0), -1)
x = torch.flatten(x, 1)
x = self.fc(x)
x = self.l2_norm(x)
return x
def forward_class(self, x):
x = self.forward(x)
x = self.fc_class(x)
return x
if __name__ == '__main__':
from torchsummary import summary
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = FaceNetModel().to(device)
summary(model, input_size = (3, 128, 128))
用LFW数据集测试,模型收敛良好。
注意力机制
SENET
实现方式
-
对输入进来的特征层进行全局平均池化。
-
然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
-
在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
-
在获得这个权值后,我们将这个权值乘上原输入特征层即可。
pyTorch实现
# -*- encoding: utf-8 -*-
"""
@File : seNet.py
@Time : 2021-12-29 17:44
@Author : XD
@Email : gudianpai@qq.com
@Software: PyCharm
"""
import torch
from torch import nn
from torchsummary import summary
class seNet(nn.Module):
def __init__(self, channel, ratio = 16):
super(seNet, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias = False),
nn.ReLU(),
nn.Linear(channel // ratio, channel, bias = False),
nn.Sigmoid()
)
def forward(self, x):
b, c, h, w = x.size()
# b, c, h, w -> b, c, 1, 1
avg = self.avg_pool(x).view(b, c)
#b, c, h, w -> b, c // ratio -> b, c -> b, c, 1, 1
fc = self.fc(avg).view(b, c, 1, 1)
return x * fc
model = seNet(channel = 512)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
print(model)
summary(model, input_size = [(512, 26, 26)], batch_size = 2, device = "cuda")
测试
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
AdaptiveAvgPool2d-1 [2, 512, 1, 1] 0
Linear-2 [2, 32] 16,384
ReLU-3 [2, 32] 0
Linear-4 [2, 512] 16,384
Sigmoid-5 [2, 512] 0
================================================================
Total params: 32,768
Trainable params: 32,768
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 2.64
Forward/backward pass size (MB): 0.02
Params size (MB): 0.12
Estimated Total Size (MB): 2.79
----------------------------------------------------------------
Process finished with exit code 0
CBAM
实现方式
图像的上半部分为通道注意力机制,通道注意力机制的实现可以分为两个部分,我们会对输入进来的单个特征层,分别进行全局平均池化和全局最大池化。之后对平均池化和最大池化的结果,利用共享的全连接层进行处理,我们会对处理后的两个结果进行相加,然后取一个sigmoid,此时我们获得了输入特征层每一个通道的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。图像的下半部分为空间注意力机制,我们会对输入进来的特征层,在每一个特征点的通道上取最大值和平均值。之后将这两个结果进行一个堆叠,利用一次通道数为1的卷积调整通道数,然后取一个sigmoid,此时我们获得了输入特征层每一个特征点的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
pyTorch实现
# -*- encoding: utf-8 -*-
"""
@File : CBAM.py
@Time : 2021-12-29 17:44
@Author : XD
@Email : gudianpai@qq.com
@Software: PyCharm
"""
from torchsummary import summary
import torch
from torch import nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 利用1x1卷积代替全连接
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class cbam_block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(cbam_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x
model = cbam_block(channel = 512)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
print(model)
summary(model, input_size = [(512, 26, 26)], batch_size = 2, device = "cuda")
测试
Layer (type) Output Shape Param #
================================================================
AdaptiveAvgPool2d-1 [2, 512, 1, 1] 0
Conv2d-2 [2, 64, 1, 1] 32,768
ReLU-3 [2, 64, 1, 1] 0
Conv2d-4 [2, 512, 1, 1] 32,768
AdaptiveMaxPool2d-5 [2, 512, 1, 1] 0
Conv2d-6 [2, 64, 1, 1] 32,768
ReLU-7 [2, 64, 1, 1] 0
Conv2d-8 [2, 512, 1, 1] 32,768
Sigmoid-9 [2, 512, 1, 1] 0
ChannelAttention-10 [2, 512, 1, 1] 0
Conv2d-11 [2, 1, 26, 26] 98
Sigmoid-12 [2, 1, 26, 26] 0
SpatialAttention-13 [2, 1, 26, 26] 0
================================================================
Total params: 131,170
Trainable params: 131,170
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 2.64
Forward/backward pass size (MB): 0.08
Params size (MB): 0.50
Estimated Total Size (MB): 3.22
----------------------------------------------------------------
ECA
实现方式
ECANet的作者认为SENet对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。在ECANet的论文中,作者认为卷积具有良好的跨通道信息获取能力。ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。
pyTorch实现
class eca_block(nn.Module):
def __init__(self, channel, b=1, gamma=2):
super(eca_block, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
测试
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
AdaptiveAvgPool2d-1 [2, 512, 1, 1] 0
Conv1d-2 [2, 1, 512] 5
Sigmoid-3 [2, 512, 1, 1] 0
================================================================
Total params: 5
Trainable params: 5
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 2.64
Forward/backward pass size (MB): 0.02
Params size (MB): 0.00
Estimated Total Size (MB): 2.66
----------------------------------------------------------------
NEXT
模型融合
将注意力机制引入我们的主干网络,以提高性能。
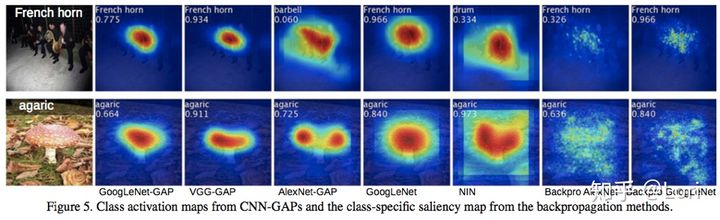
CAM可视化
可视化必要性:CAM可以帮助我们发现问题,改进结构。解释模型。
2
Params size (MB): 0.00
Estimated Total Size (MB): 2.66
# NEXT
## 模型融合
将注意力机制引入我们的主干网络,以提高性能。
## CAM可视化
可视化必要性:CAM可以帮助我们发现问题,改进结构。解释模型。
















 2437
2437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









