







文章目录
1. DDL数据库定义语言扩展
1.1 手撕一张表
-- USE oldboy 因为下面指定了oldboy.student库和表,这个地方可以不写
CREATE TABLE oldboy.student(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(64) NOT NULL COMMENT '学生名',
age TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄',
gender TINYINT NOT NULL DEFAULT 2 COMMENT '0 代表女,1代表男,2代表不详',
addr ENUM('北京市','上海市','天津市') NOT NULL DEFAULT '北京市' COMMENT '地址',
cometime DATETIME NOT NULL DEFAULT NOW() COMMENT '入学时间',
telnum BIGINT NOT NULL UNIQUE KEY COMMENT '手机号'
)ENGINE=INNODB CHARSET=utf8mb4;
小提示:
(1)每一种字符集都会有一个默认的校对规则(大小写不敏感)
1.2 DDL操作对生产的影响
线上DDL(alter)操作对于生产的影响?
SQL审核平台:yearning,inception
说明:
元数据是什么? ----> 类似于Linux inode信息
在MySQL中,DDL语句对表进行操作时,是要锁"元数据表"的,此时所有修改类的命令无法正常运行。
所以:
在对于大表,业务繁忙的表,进行线上DDL操作时,要谨慎。
尽量避开业务繁忙期间,进行DDL。
面试题回答要点:(面试题下图所示)
1. SQL语句的意思是什么?
以上4条语句是对两张核心业务表,进行DDL操作。
2. 以上操作带来的影响?
在MySQL中,DDL语句在对标进行操作时,是要锁"元数据表"的,第十,所有修改类的命令无法正常运行。
在对于大表,业务繁忙的表,进行线上DDL操作时,要谨慎。
3. 我们的建议?
(1)尽量避开业务繁忙期间,进行DDL。走流程(真要执行找项目经理批准)
(2)建议使用: pt-osc(pt-online-schema-change) gh-ost工具进行DDL操作,减少锁表的影响
(3)如果时8.0版本,可以不用pt工具,8.0以前一般需要借助于以上工具。
任务: 自己扩展pt-osc工具的使用:往表中加列。理解pt-osc的工作原理
https://www.jianshu.com/p/c97228b6f60c

小提示:
(1)alter table t1 add [column] age xxx # 这个column可以省略不写(上图中就没有写)
(2)inode存的是文件的属性,对文件修改属性内容的时候inode会发生变化
(3)mysql元数据什么时候变化?表的属性,内容变化,创建表,删除表,修改表
(4)表数据分为元数据和数据行
(5)DDL DCL其实都是做一些元数据的操作,DML DQL主要对真实数据进行操作
2. DCL数据控制语言
常用的两个命令(前面已经学过了)
grant 授权
revoke 回收权限
3. DML数据操作语言
作用:表中数据行进行操作
3.1 insert
-- 建一张student表
USE oldboy
CREATE TABLE oldboy.student(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(64) NOT NULL COMMENT '学生名',
age TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄',
gender TINYINT NOT NULL DEFAULT 2 COMMENT '0 代表女,1代表男,2代表不详',
addr ENUM('北京市','上海市','天津市') NOT NULL DEFAULT '北京市' COMMENT '地址',
cometime DATETIME NOT NULL DEFAULT NOW() COMMENT '入学时间',
telnum BIGINT NOT NULL UNIQUE KEY COMMENT '手机号'
)ENGINE=INNODB CHARSET=utf8mb4;
-- 查看表结构
DESC student;
-- 规范用法
INSERT INTO
student(id,sname,age,gender,addr,cometime,telnum)
VALUES(1,'张三',18,1,'北京市','2022-09-14 11:50:00',110);
-- 简约的用法
INSERT INTO
student
VALUES(2,'李四',40,1,'北京市','2022-09-14 11:50:00',115);
-- 部分录入数据(只要有默认值或者自增字段的可以不写)
INSERT INTO
student(sname,telnum)
VALUES('王二',120);
-- 批量录入方式
INSERT INTO
student(sname,telnum)
VALUES('zhangsan',111),('wanger',222),("lisi",333);
-- 查看表数据
SELECT * FROM student;
3.2 update
-- update应用
-- 修改指定数据行的值
-- 前提: 必须要明确要改哪一行,一般update语句都有where的条件
UPDATE student SET sname='xiaoming' WHERE id=1;
3.3 delete
-- delete应用
-- 删除指定数据行的值
-- 前提:必须要明确要删哪些行,一般delete语句都有where的条件
DELETE FROM student WHERE id=1;
扩展1 : 伪删除
-- 伪删除
-- 需求:删除id=2的数据行
-- 原操作:
DELETE FROM student WHERE id=2;
-- 查询数据
SELECT * FROM student;
-- 修改表结构,添加state状态列
ALTER TABLE student ADD COLUMN state TINYINT NOT NULL DEFAULT 1;
-- 删除数据改为update
UPDATE student SET state=0 WHERE id=2;
-- 查询语句修改为
SELECT * FROM student WHERE state=1
扩展2 : delete from student , drop table student, truncate table student区别
说明:
1. 以上三条命令都可以删除全表数据
2. 区别:
delete from student:
逻辑上,逐行删除。数据行多,操作很慢。
并没有真正从磁盘上删除,只是在存储层打标机,磁盘空间不立即释放。HWM高水位线不会降低。
drop table student:
将表结构(元数据)和数据行物理层次删除。
truncate table student
清空表段中的所有数据页。物理层次删除全表数据,磁盘空间立即释放,HWM高水位线会降低。
小提示:
(1) select其实实在DML里面因为比较重要单独放到 DQL中去了
(2) HWM高水位线,一直会顺位增长的,
例如: id为1,有录入了一条数据重复了报错了,然后又录入一个正确的一条数据,这是id为3。
(3) 如果彻底点的话整表删除的话用drop table student
如果快一点清空表数据的话,可以用truncate table student
如果删除部分行的话只能用delete from table where id=1
(4) delete,drop,truncate如果不小心删除了,他们都可以恢复吗?(可以恢复)
常规方法: 都可以通过 备份+日志,恢复数据。
灵活办法: delete可以通过,翻转日志(binlog)。
三种删除数据情况,也可以通过《延时从库》进行恢复
4. DQL数据查询语言
4.1 select
4.1.1 select功能
获取表中的数据行
4.1.2 select单独使用(mysql独家)
--(1) select配置内置函数使用
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2022-09-18 08:22:48 |
+---------------------+
mysql> use mysql;
mysql> select database();
+------------+
| database() |
+------------+
| mysql |
+------------+
mysql> select concat("hello world");
+-----------------------+
| concat("hello world") |
+-----------------------+
| hello world |
+-----------------------+
mysql> select concat(user,"@",host) from mysql.user;
+-------------------------+
| concat(user,"@",host) |
+-------------------------+
| root@% |
| mysql.session@localhost |
| mysql.sys@localhost |
| root@localhost |
+-------------------------+
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.30 |
+-----------+
mysql> select user();
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
小提示: mysql有单独调用函数的功能,和别的数据库可能有些区别。别的数据库要向单独使用函数,必须
select user() from dual; 标准的sql语法里面必须要有from这个东西的,select设计之初
是用来查询表数据,所以要from一张表,但是查函数是没有表的,所以要加上from dual,dual可以
理解为一个通用的空表
-- (2) 计算
mysql> select 10*1000;
-- (3) 查询数据库参数
mysql> select @@port;
+--------+
| @@port |
+--------+
| 3306 |
+--------+
1 row in set (0.00 sec)
mysql> select @@socket;
+-----------------+
| @@socket |
+-----------------+
| /tmp/mysql.sock |
+-----------------+
1 row in set (0.00 sec)
mysql> select @@datadir;
+-------------+
| @@datadir |
+-------------+
| /data/3306/ |
+-------------+
1 row in set (0.00 sec)
-- 这种变量太长,有可能记不住,下面有解决方案
mysql> select @@innodb_flush_log_at_trx_commit;
+----------------------------------+
| @@innodb_flush_log_at_trx_commit |
+----------------------------------+
| 1 |
+----------------------------------+
-- 替代方案:
mysql> show variables; --现实mysql中所有参数信息,不嫌麻烦一个一个的找
mysql> show variables like '%trx%';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_api_trx_level | 0 |
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
2 rows in set (0.00 sec)
小提示:
-- 1. 查看mysql函数帮助
mysql> help
mysql> help contents;
mysql> help Functions;
-- 下面是用的最多的函数(时间函数、聚合函数、数字函数、字符串函数)
Date and Time Functions
GROUP BY Functions and Modifiers
Numeric Functions
String Functions
4.1.3 select标准用法
select标准用法,配合其他子句使用
-- 单表
-- 默认执行顺序
select
1. from 表1,表2...
2. where 过滤条件1,过滤条件2...
3. group by 条件列1, 条件列2
3.5 select_list 列名列表(例如:select usr,host)
4. having 过滤条件1,过滤条件2...
5. order by 条件列1,条件列2
6. limit 限制
-- 实验使用的数据库为world,官方提供的
[root@db01 ~]# mysql -uroot -p123456
world -- 世界库
city -- 城市表
country -- 国家表
countrylanguage -- 国家语言
city -- 城市表
ID -- 主键ID
Name -- 城市名
CountryCode -- 城市所在国家代号(CHN、JPN、USA...)
District -- 区域:省,州...
Population -- 人口数
-- 1. select 配合from子句的使用
-- 语法:
-- select 列 from 表; cat /etc/passwd
-- 例子1:
-- 查询表中所有的数据,类似于: cat /etc/passwd
SELECT id,NAME,countrycode,district,population FROM world.city
SELECT * FROM world.city;
-- 查询部分列值,类似于:awk取列
-- 例子2:查询城市名和对应的人口数
SELECT id,NAME,population FROM world.city;
-- 2. select + from + where配合使用==》相当于grep功能
-- 2.1 WHERE 配合比较判断符号=,>,<,>=,<=,!=
-- 例子3:查询city中,中国所有城市信息。
SELECT * FROM world.`city` WHERE countrycode='CHN';
-- 例子4:查询city中,人口数量小于1000人的城市。
SELECT * FROM `city` WHERE population<1000;
-- 2.2 WHERE 配合LIKE语句 模糊查询
-- 例子5:查询city中,国家代号是CH开头的城市信息。
SELECT * FROM world.city WHERE countrycode LIKE 'CH%';
-- 注意:like语句在使用时,切记不要出现前面带%的模糊查询,不走索引
-- 错误例子:
SELECT * FROM world.city WHERE countrycode LIKE '%CH%';
-- 2.3 WHERE 配合逻辑连接符 AND OR
-- 例子6:查询中国城市中,人口大于500w的
SELECT * FROM world.city
WHERE countrycode='CHN' AND population>5000000;
-- 例子7:查询中国或美国的城市信息
SELECT * FROM world.`city`
WHERE countrycode='CHN' OR countrycode='USA';
-- 例子8:查询中国或美国的城市信息,并且人口数量超过500w的
SELECT * FROM world.`city`
WHERE countrycode IN ('CHN','USA') AND population>5000000;
-- 2.4 WHERE配合 BETWEEN AND
-- 例子9:查询城市人口数在100w到200w之间的
SELECT * FROM world.`city`
WHERE population>=1000000 AND population<=2000000
-- 与上面的语句相同[100000,200000]
SELECT * FROM world.`city`
WHERE population BETWEEN 100000 AND 2000000
-- 3. select + from + where + group by
-- group by 配合聚合函数(max(),min(),avg(),count(),sum(),group_concat)使用
-- 聚合函数:
max() : 最大值
min() : 最小值
avg() : 平均值
count() : 统计个数
sum() : 求和
group_concat() : 列转行
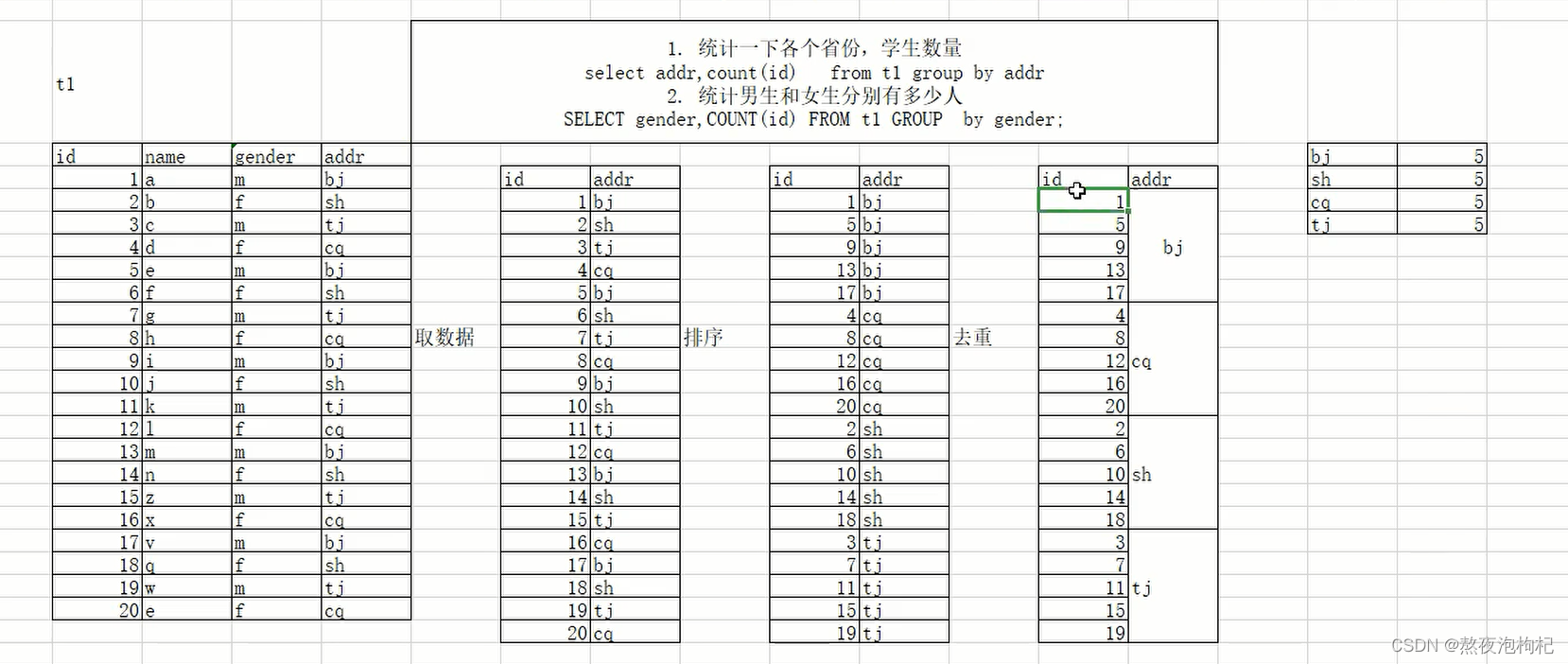
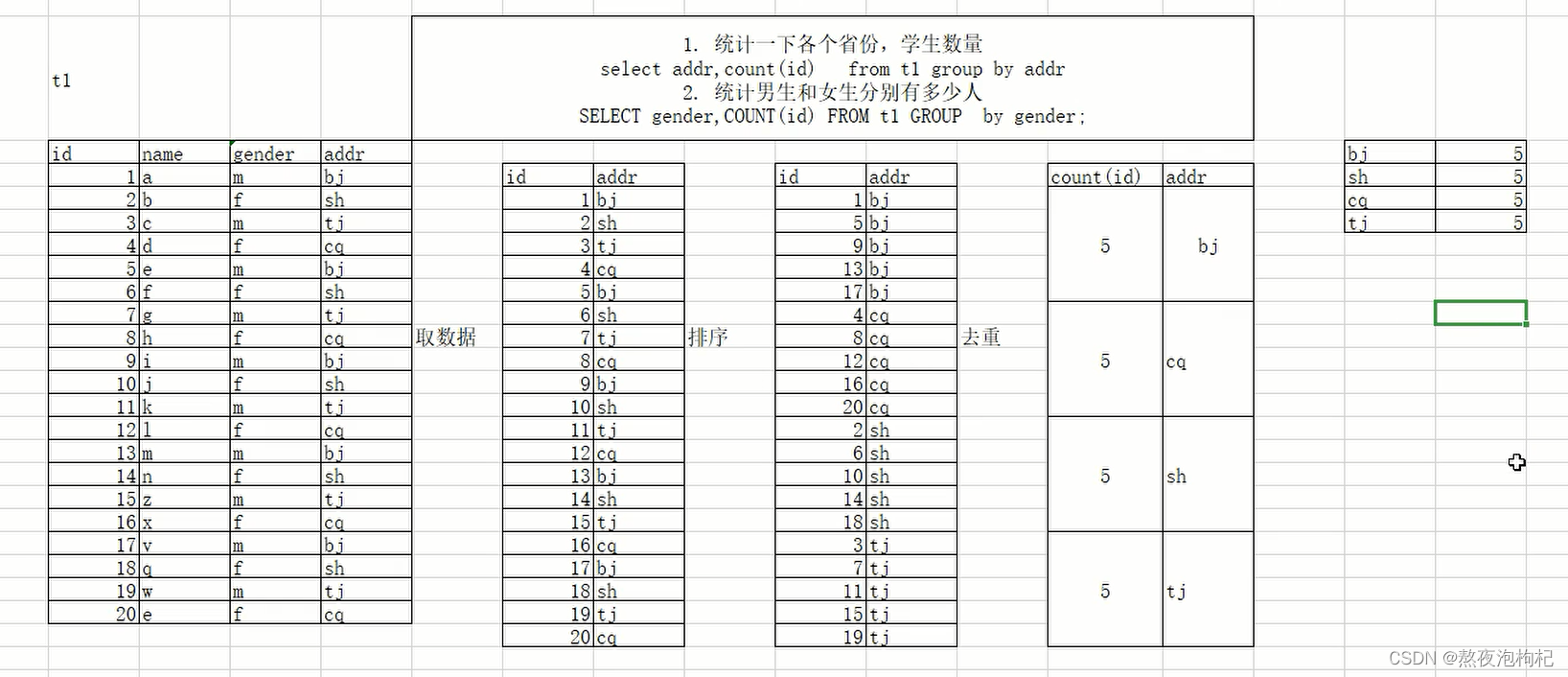
说明: 碰到group by 必然会有聚合函数。
-- 例子10; 统计city中,每个国家的城市个数
SELECT countrycode,COUNT(id)
FROM world.`city`
GROUP BY countrycode;
-- 例子11: 统计中国,每个省的城市个数
SELECT district,COUNT(id) FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district;
任务:
(1)自己扩展pt-osc工具的使用:往表中加列。理解pt-osc的工作原理
https://www.jianshu.com/p/c97228b6f60c
(2) 完成下面题目
-- 例子12:统计每个国家的总人口
SELECT countrycode,SUM(population)
FROM world.`city`
GROUP BY countrycode;
-- 例子13:统计中国,每个省的总人口
SELECT District,SUM(population)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY District;
-- 例子14:统计中国,每个省总人口,城市个数,城市名列表
-- 这种是错误写法,district列在group by的作用下已经进行过排序去重了,然而NAME还没有去重,产生了一对多的错误关系
SELECT district,SUM(Population),COUNT(id),NAME FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
-- 报错(在mysql5.6中不报错(sqlyog也不报错,因为有内置sql_mode,sqlyog版本过低的原因),但是没有显示出所有的城市名,只截取了第一个城市名,形成一对一的关系,但是在5.7之后的版本都会报错)
ERROR 1055 (42000): Expression #4(第四列的NAME) of SELECT list is not in GROUP BY clause and contains nonaggregated column 'world.city.Name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
-- 正确写法,把name值列转行,解决了一对多的错误关系
SELECT district,SUM(Population),COUNT(id),GROUP_CONCAT(NAME)
FROM world.`city`
WHERE countrycode='CHN'
GROUP BY district
小提示:
5.7 SQL_mode的区别 sql_mode = only_full_group_by
说明: select list中的列,要么是group by的条件,要么在聚合函数中出现。
原理: mysql不支持结果集是1行对多行的显示方式
后续见下文....
单表查询sql执行顺序:
理解记忆: wgshol (无功受禄) 执行顺序
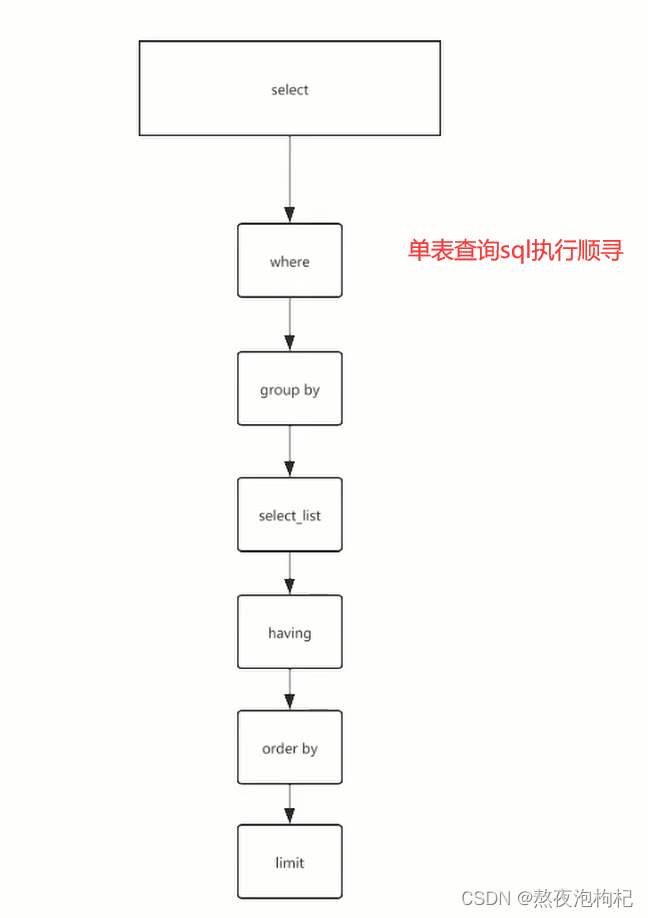
group by配合聚合函数执行过程原理图:
小提示:mysql中一个值不能对应多行值,所以需要用到聚合函数
4.2 show
后文中涉及
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









