







三个稠密矩阵A,B,C的乘积ABC,假设三个矩阵的尺寸分别为mn,np,pq,且m<n<p<q,以下计算顺序效率最高的是?
提示:
题目
在深度学习中,涉及到大量矩阵相乘,现在需要计算三个稠密矩阵A,B,C的乘积ABC,假设三个矩阵的尺寸分别为mn,np,p*q,且m<n<p<q,以下计算顺序效率最高的是:()
A(BC)
(AB)C
(AC)B
所有效率都相同
二、解题
矩阵乘积数学公式:
假设存在两个矩阵A为m×n矩阵,B为k×l矩阵,若需要计算AB则必须n=k,若需要计算BA必须l=m否则无法进行计算,先假定n=k即B为n×l矩阵则AB的结果为一个m×l的矩阵并且该矩阵每个点的元素的值表示为Cij则:
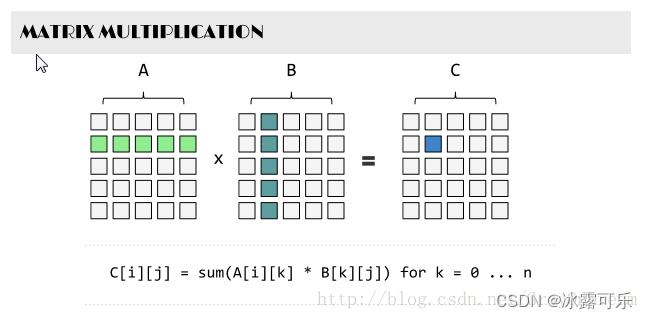
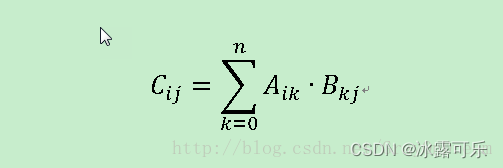
ab,bc两矩阵相乘效率为acb
ABC=(AB)C=A(BC).
(AB)C = mnp + mpq,
A(BC)=npq + mnq.
mnp<mnq,mpq< npq, 所以 (AB)C 最小

小×小<小×大
总结
提示:重要经验:
1)小×小<小×大
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











