










数据挖掘,计算机网络、操作系统刷题笔记49
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
【35】数据挖掘,计算机网络、操作系统刷题笔记35
【36】数据挖掘,计算机网络、操作系统刷题笔记36
【37】数据挖掘,计算机网络、操作系统刷题笔记37
【38】数据挖掘,计算机网络、操作系统刷题笔记38
【39】数据挖掘,计算机网络、操作系统刷题笔记39
【40】数据挖掘,计算机网络、操作系统刷题笔记40
【41】数据挖掘,计算机网络、操作系统刷题笔记41
【42】数据挖掘,计算机网络、操作系统刷题笔记42
【43】数据挖掘,计算机网络、操作系统刷题笔记43
【44】数据挖掘,计算机网络、操作系统刷题笔记44
【45】数据挖掘,计算机网络、操作系统刷题笔记45
【46】数据挖掘,计算机网络、操作系统刷题笔记46
【47】数据挖掘,计算机网络、操作系统刷题笔记47
【48】数据挖掘,计算机网络、操作系统刷题笔记48
数据挖掘分析应用:集成方法
将多种机器学习模型集成在一起
三个臭皮匠
订个诸葛亮

最好别指数级别,阶乘啥的



集成学习:bagging法
投票
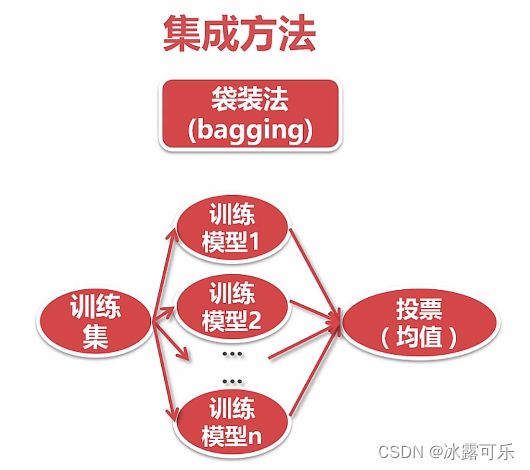
每个模型之间独立,放在bag中,一起决定
随机森林决策树:集成学习bagging典例
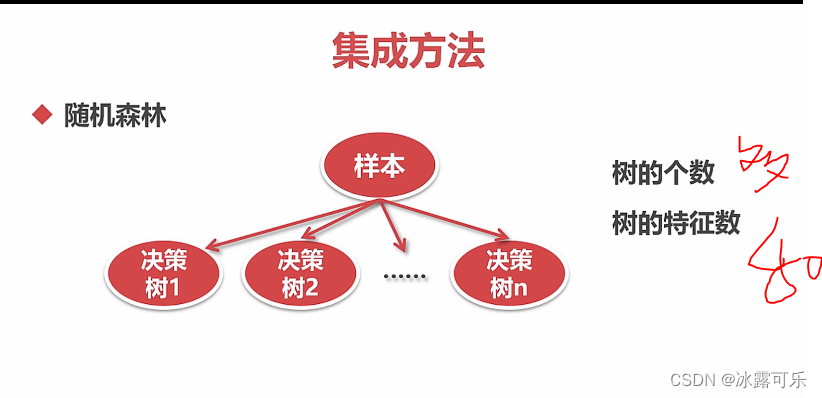
特征尽量别太多
树放多一些OK
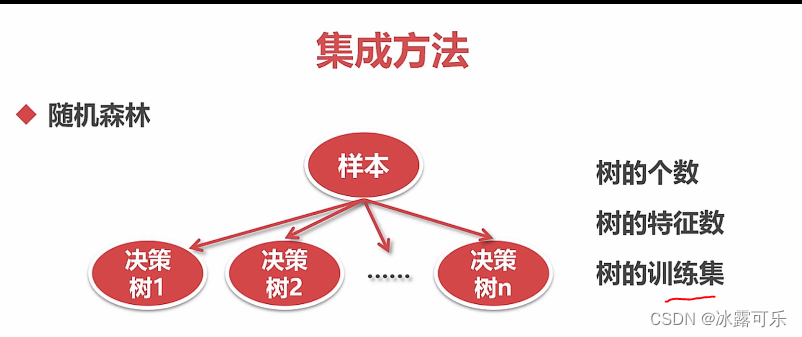
训练集是子集,数量,如何产生,好像是bootstrap
随机森林的本质就是样本的随机,特征随机
这样搞出来的
每个决策树用一点特征
不需要像一棵树那种,不用剪枝,有效防止过拟合
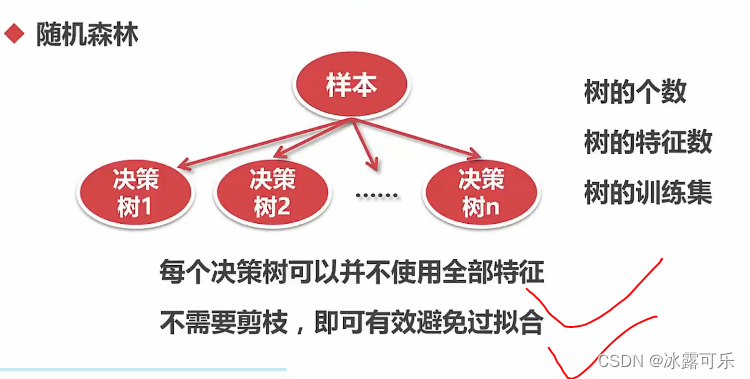
接下来代码演示:
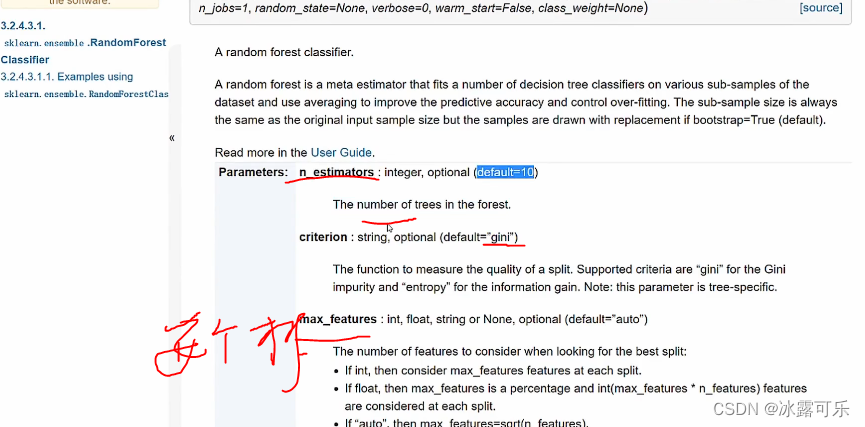
自己可以查官网的介绍


oob是out of bag
又放回的话,有的样本是没有采样到的,它很倒霉
如果oob出现了,那就用这些没有选择到的数据去测试
njobs并行
# 演示SVM--Random
# 模型
def hr_modeling_all_saveDT_SVM(features, label):
from sklearn.model_selection import train_test_split
# 切分函数
#DataFrame
feature_val = features.values
label_val = label
# 特征段
feature_name = features.columns
train_data, valid_data, y_train, y_valid = train_test_split(feature_val, label_val, test_size=0.2) # 20%验证集
train_data, test_data, y_train, y_test = train_test_split(train_data, y_train, test_size=0.25) # 25%测试集
print(len(train_data), len(valid_data), len(test_data))
# KNN分类
from sklearn.neighbors import NearestNeighbors, KNeighborsClassifier
from sklearn.metrics import accuracy_score, recall_score, f1_score # 模型评价
from sklearn.naive_bayes import GaussianNB, BernoulliNB # 高斯,伯努利,都是对特征有严格要求,离散值最好
from sklearn.tree import DecisionTreeClassifier, export_graphviz # 决策树
from io import StringIO
import pydotplus
import os
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier # 随机森林
os.environ["PATH"] += os.pathsep+r'D:\Program Files\Graphviz\bin'
models = [] # 申请模型,挨个验证好坏
knn_clf = KNeighborsClassifier(n_neighbors=3) # 5类
bys_clf = GaussianNB()
bnl_clf = BernoulliNB()
DT_clf = DecisionTreeClassifier()
SVC_clf = SVC()
rdn_clf = RandomForestClassifier()
models.append(("KNN", knn_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("GaussianNB", bys_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("BernoulliNB", bnl_clf)) # 代码一个个模型测--放入的是元祖
models.append(("Decision Tree", DT_clf)) # 代码一个个模型测--放入的是元祖
models.append(("SVM classifier", SVC_clf)) # 代码一个个模型测--放入的是元祖
models.append(("Random classifier", rdn_clf)) # 代码一个个模型测--放入的是元祖
# 不同的模型,依次验证
for modelName, model in models:
print(modelName)
model.fit(train_data, y_train) # 指定训练集
# 又集成化数据集
data = [(train_data, y_train), (valid_data, y_valid), (test_data, y_test)]
for i in range(len(data)):
print(i)
y_input = data[i][0]
y_label = data[i][1] # 输入输出预测
y_pred = model.predict(y_input)
print("acc:", accuracy_score(y_label, y_pred))
print("recall:", recall_score(y_label, y_pred))
print("F1:", f1_score(y_label, y_pred))
print("\n")
# 不考虑存储,你看看这个模型就会输出仨结果
if __name__ == '__main__':
features, label = pre_processing(sl=True, le=True, npr=True, amh=True, wacc=True, pla=True, dep=False, sal=True,
lower_d=True, ld_n=3)
# print(df, label)
# 灌入模型
hr_modeling_all_saveDT_SVM(features, label)
8999 3000 3000
KNN
0
acc: 0.9588843204800533
recall: 0.9334257975034674
F1: 0.9160617059891107
1
acc: 0.9343333333333333
recall: 0.8821022727272727
F1: 0.8630993745656705
2
acc: 0.9193333333333333
recall: 0.8650568181818182
F1: 0.8342465753424658
Decision Tree
0
acc: 1.0
recall: 1.0
F1: 1.0
1
acc: 0.9423333333333334
recall: 0.9076704545454546
F1: 0.8807718814610613
2
acc: 0.9386666666666666
recall: 0.8977272727272727
F1: 0.8729281767955801
SVM classifier
0
acc: 0.9009889987776419
recall: 0.7489597780859917
F1: 0.784313725490196
1
acc: 0.9113333333333333
recall: 0.7571022727272727
F1: 0.8003003003003002
2
acc: 0.902
recall: 0.7286931818181818
F1: 0.7772727272727272
Random classifier
0
acc: 1.0
recall: 1.0
F1: 1.0
1
acc: 0.9643333333333334
recall: 0.9261363636363636
F1: 0.9241672572643516
2
acc: 0.962
recall: 0.9232954545454546
F1: 0.9193776520509193
Process finished with exit code 0
这随机森林有点牛逼啊
比KNN还屌
很强哦
!!!!
随机森林很可
集成学习:提升法boost,串联训练
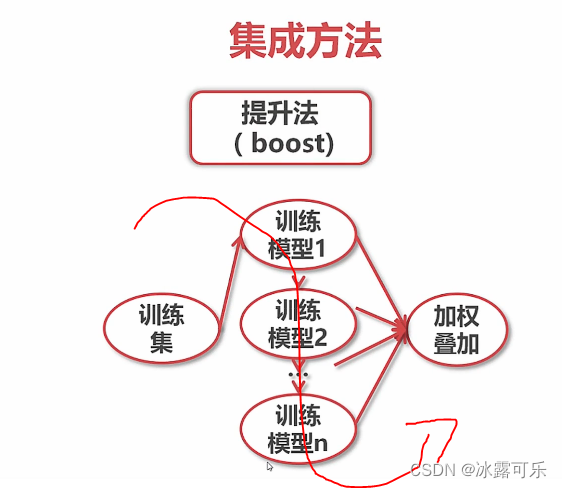
结果是各个模型的加权叠加

例子
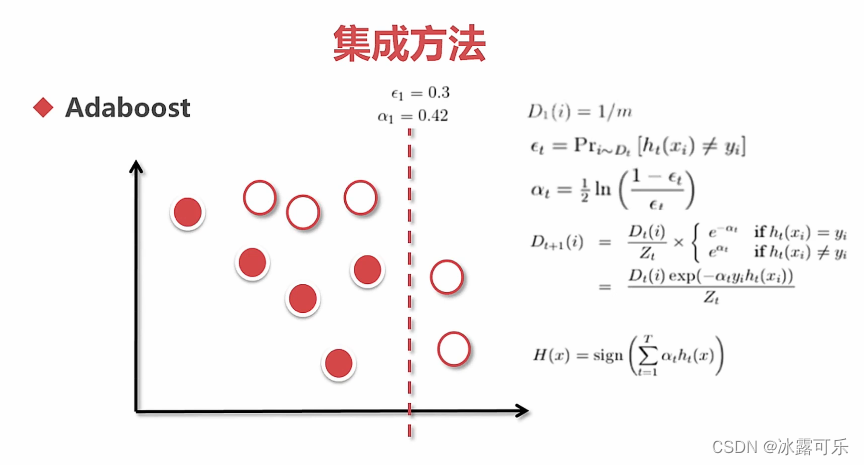
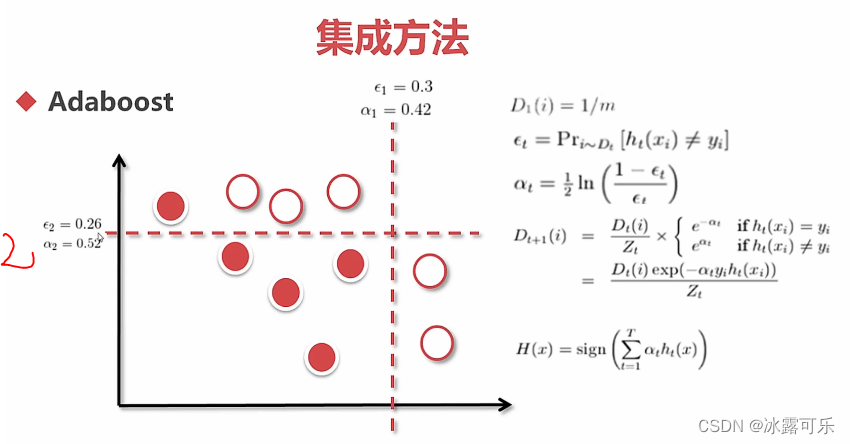
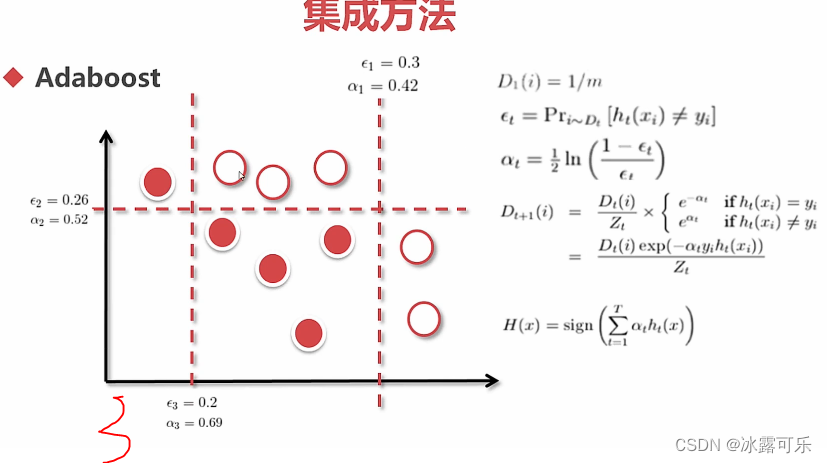

adaboost很牛的
代码看看
# 演示SVM--Random--adaboost
# 模型
def hr_modeling_all_saveDT_SVM(features, label):
from sklearn.model_selection import train_test_split
# 切分函数
#DataFrame
feature_val = features.values
label_val = label
# 特征段
feature_name = features.columns
train_data, valid_data, y_train, y_valid = train_test_split(feature_val, label_val, test_size=0.2) # 20%验证集
train_data, test_data, y_train, y_test = train_test_split(train_data, y_train, test_size=0.25) # 25%测试集
print(len(train_data), len(valid_data), len(test_data))
# KNN分类
from sklearn.neighbors import NearestNeighbors, KNeighborsClassifier
from sklearn.metrics import accuracy_score, recall_score, f1_score # 模型评价
from sklearn.naive_bayes import GaussianNB, BernoulliNB # 高斯,伯努利,都是对特征有严格要求,离散值最好
from sklearn.tree import DecisionTreeClassifier, export_graphviz # 决策树
from io import StringIO
import pydotplus
import os
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.ensemble import AdaBoostClassifier
os.environ["PATH"] += os.pathsep+r'D:\Program Files\Graphviz\bin'
models = [] # 申请模型,挨个验证好坏
knn_clf = KNeighborsClassifier(n_neighbors=3) # 5类
bys_clf = GaussianNB()
bnl_clf = BernoulliNB()
DT_clf = DecisionTreeClassifier()
SVC_clf = SVC()
rdn_clf = RandomForestClassifier()
adaboost_clf = AdaBoostClassifier()
# models.append(("KNN", knn_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("GaussianNB", bys_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("BernoulliNB", bnl_clf)) # 代码一个个模型测--放入的是元祖
models.append(("Decision Tree", DT_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("SVM classifier", SVC_clf)) # 代码一个个模型测--放入的是元祖
models.append(("Random classifier", rdn_clf)) # 代码一个个模型测--放入的是元祖
models.append(("adaboost classifier", adaboost_clf)) # 代码一个个模型测--放入的是元祖
# 不同的模型,依次验证
for modelName, model in models:
print(modelName)
model.fit(train_data, y_train) # 指定训练集
# 又集成化数据集
data = [(train_data, y_train), (valid_data, y_valid), (test_data, y_test)]
for i in range(len(data)):
print(i)
y_input = data[i][0]
y_label = data[i][1] # 输入输出预测
y_pred = model.predict(y_input)
print("acc:", accuracy_score(y_label, y_pred))
print("recall:", recall_score(y_label, y_pred))
print("F1:", f1_score(y_label, y_pred))
print("\n")
# 不考虑存储,你看看这个模型就会输出仨结果
if __name__ == '__main__':
features, label = pre_processing(sl=True, le=True, npr=True, amh=True, wacc=True, pla=True, dep=False, sal=True,
lower_d=True, ld_n=3)
# print(df, label)
# 灌入模型
hr_modeling_all_saveDT_SVM(features, label)
8999 3000 3000
Decision Tree
0
acc: 1.0
recall: 1.0
F1: 1.0
1
acc: 0.941
recall: 0.8997134670487106
F1: 0.876482903000698
2
acc: 0.9446666666666667
recall: 0.9019886363636364
F1: 0.8844011142061282
Random classifier
0
acc: 0.999888876541838
recall: 0.9995389580451821
F1: 0.9997694258704174
1
acc: 0.9576666666666667
recall: 0.9068767908309455
F1: 0.9088298636037329
2
acc: 0.9586666666666667
recall: 0.9019886363636364
F1: 0.9110473457675753
adaboost classifier
0
acc: 0.9161017890876764
recall: 0.8082065467957584
F1: 0.8228115465853088
1
acc: 0.9133333333333333
recall: 0.7965616045845272
F1: 0.8104956268221573
2
acc: 0.9206666666666666
recall: 0.7982954545454546
F1: 0.8252569750367107
Process finished with exit code 0
目前是不如随机森林的
看看能否调参


要不试试
分类器的个数
adaboost_clf = AdaBoostClassifier(n_estimators=1000)
8999 3000 3000
Decision Tree
0
acc: 1.0
recall: 1.0
F1: 1.0
1
acc: 0.9446666666666667
recall: 0.899171270718232
F1: 0.8869209809264306
2
acc: 0.9363333333333334
recall: 0.8802816901408451
F1: 0.8674531575294935
Random classifier
0
acc: 1.0
recall: 1.0
F1: 1.0
1
acc: 0.9623333333333334
recall: 0.9171270718232044
F1: 0.9215822345593339
2
acc: 0.9583333333333334
recall: 0.8929577464788733
F1: 0.9102656137832018
adaboost classifier
0
acc: 0.9314368263140349
recall: 0.8268600842302293
F1: 0.8513611178029391
1
acc: 0.9186666666666666
recall: 0.7983425414364641
F1: 0.8257142857142858
2
acc: 0.9173333333333333
recall: 0.7676056338028169
F1: 0.8146487294469357
还是一般
改成10000个分类器呢???
8999 3000 3000
Decision Tree
0
acc: 1.0
recall: 1.0
F1: 1.0
1
acc: 0.9423333333333334
recall: 0.9229691876750701
F1: 0.8839704896042926
2
acc: 0.9403333333333334
recall: 0.9098712446351931
F1: 0.8766368022053755
Random classifier
0
acc: 1.0
recall: 1.0
F1: 1.0
1
acc: 0.9633333333333334
recall: 0.9215686274509803
F1: 0.9228611500701263
2
acc: 0.9573333333333334
recall: 0.9127324749642346
F1: 0.9088319088319089
adaboost classifier
0
acc: 0.9516612956995222
recall: 0.8725671918443003
F1: 0.8964532254225186
1
acc: 0.9266666666666666
recall: 0.8361344537815126
F1: 0.8444130127298444
2
acc: 0.9286666666666666
recall: 0.8369098712446352
F1: 0.8453757225433526
Process finished with exit code 0
还有点提升
但是还是不如随机森林
所以分类器的数量不重要
那么基础分类器不是决策树咋样
换成SVC
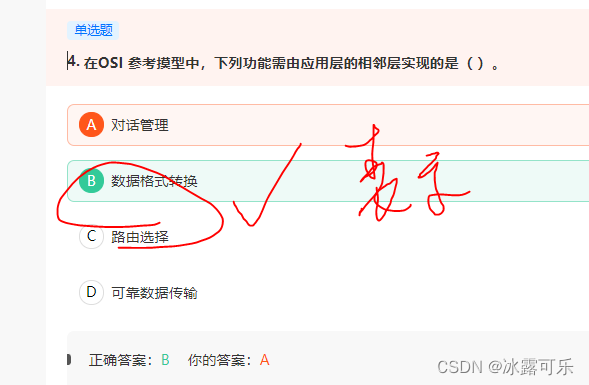
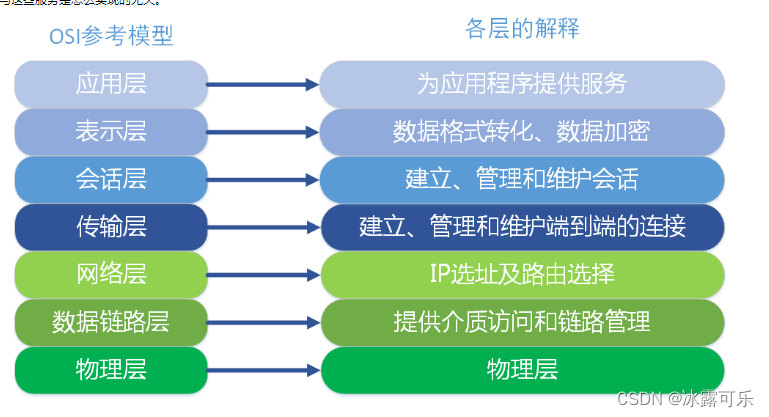
在OSI 参考摸型中,下列功能需由应用层的相邻层实现的是( )
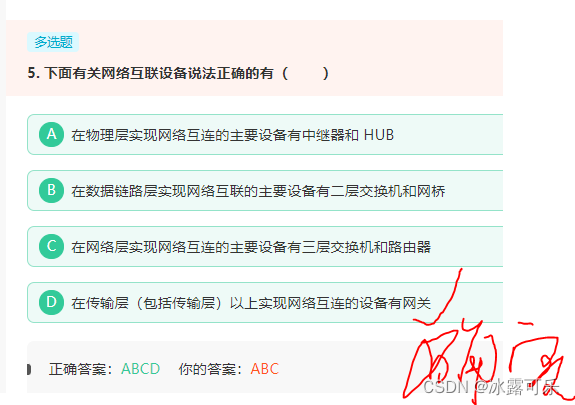
在传输层(包括传输层)以上实现网络互连的设备有网关
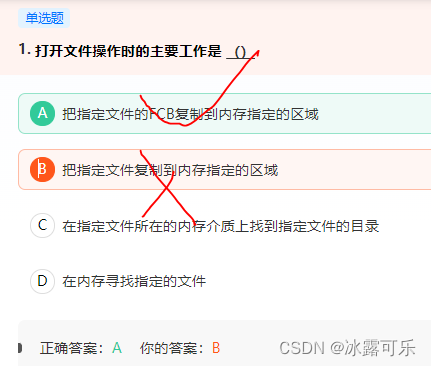
打开文件操作的目的:把指定文件的FCB复制到内存指定的区域
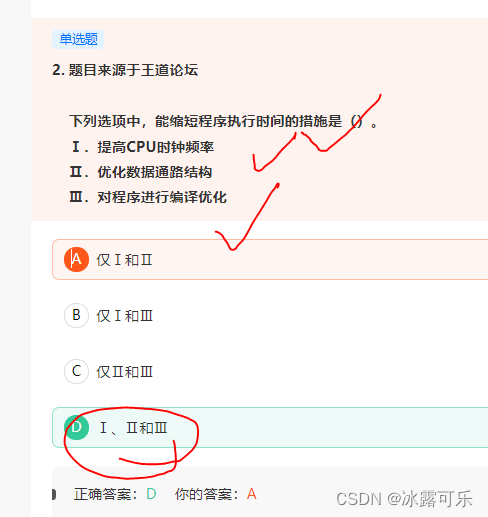
下列选项中,能缩短程序执行时间的措施是()。
Ⅰ.提高CPU时钟频率
Ⅱ.优化数据通路结构
Ⅲ.对程序进行编译优化
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
















 1660
1660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











