










 本文深入解析离散特征如性别、国籍和物品ID在推荐系统中的处理,对比one-hot编码与embedding技术。one-hot编码用于性别,而embedding应用于大规模类别,如物品ID,通过低维稠密向量提高效率。理解embedding的本质是参数矩阵乘以one-hot向量。
本文深入解析离散特征如性别、国籍和物品ID在推荐系统中的处理,对比one-hot编码与embedding技术。one-hot编码用于性别,而embedding应用于大规模类别,如物品ID,通过低维稠密向量提高效率。理解embedding的本质是参数矩阵乘以one-hot向量。
一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
提示:文章目录
文章目录
离散特征如何表示?one hot编码和embedding
前面的文章介绍了几种协同过滤的召回方法,
现在开始,后面几篇要介绍向量召回。
在讲向量召回之前,大家先熟悉一下离散特征的处理。
今儿个重点是one hot编码和embedding

离散特征在推荐系统中非常常见,
性别是离散特征,分为男女两种类别,
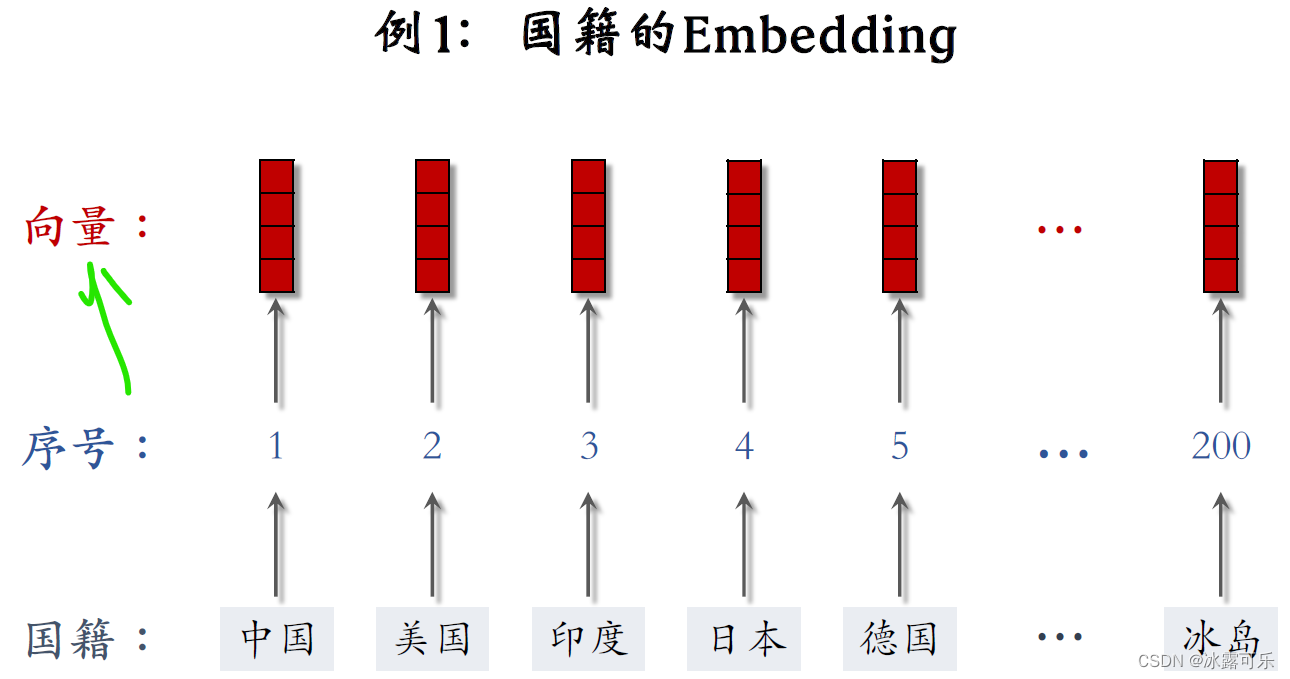
国籍是离散特征,比如中国、美国、印度,一共有200个左右的国家。
英文单词是离散特征,常见的英文单词有几万个;
物品ID是离散特征,比如小红书有几亿篇笔记,每篇笔记有一个ID,
这样的离散特征处理比较困难,因为类别数量实在太大了,
用户ID也一样,小红书有几亿个用户,每个用户有一个ID推荐,系统会把一个ID映射成一个向量。
离散特征的处理分两步,第一步是建立字典,把类别映射成序号。
以国籍特征为例,建立一个国家的字典,比如中国序号是一,美国序号是二,印度序号是三,

第二步是做向量化,把序号映射成向量。
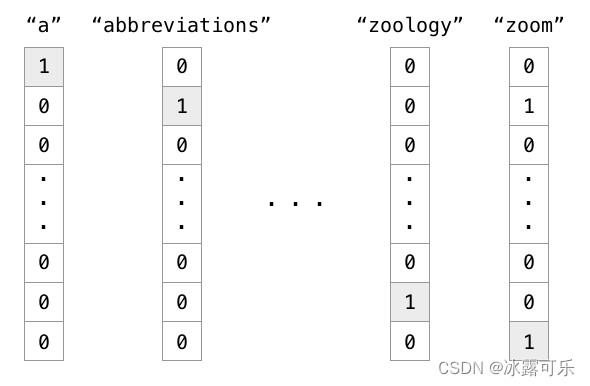
one hot编码是一种常见的方法,把序号映射成高维的稀疏向量。
比如有200个国家,每个国家被映射成一个200维的向量,序号对应的位置的元素是一,其他位置的元素都是零。
更高级的方法是embedding,把序号映射成低维稠密向量,比如处理国籍特征,每个国家被映射成一个八维的稠密向量。
后面的内容分两部分,先是one号的编码,然后是embedding。
One-Hot 编码
第一个例子是性别特征,性别分为男女两种。
那么字典里只有两个元素,男性的序号是一,女性的序号是二官号编码,
用二维向量表示性别,
如果用户不填性别,那么序号就是零,然后用全零向量表示,
如果用户性别是男,那么序号就是一,用向量10表示,
如果性别是女,序号就是二,用向量01表示。

第二个例子是国籍特征,假设有200个国籍。
比如中国、美国、印度等等。
字典里有200个国家,每个国家有一个序号,比如中国是一,美国是二,印度是三。
one hot编码用200位的系数向量表示国籍,
未知的国籍,序号是零用全零向量表示,
中国的序号是一弯号向量,只有第一个元素是一,其余元素全都是零。
美国的序号是二湾号向量,只有第二个元素是一,其余元素都是零。
同理,印度序号是三湾号向量,只有第三个元素是一。

one hot编码很常用,但是它有一定的局限性,
比如在自然语言处理的应用中,需要对单词做编码,新闻至少有几万个常见的单词,那么one hot向量的维度就是几万。
这个维度是很大的,实践中通常不会用这么高维的向量;

推进系统中需要对物品的ID做编码,物品的数量很大,比如小红书有几亿篇笔记,
那么one hot向量的维度就是几亿,在实践中更难处理。
在实践中,类别数量太大的时候,通常不用one hot编码。
对于性别,这样的离散特征类别数量很小,可以直接用one hot向量。
但是对于单词物品ID这样的离散特征类别数量巨大,用one hot向量并不合适。
embedding特征嵌入
更常见的做法是embedding特征嵌入,
即把每个类别映射成一个低维的稠密向量。
下面我介绍embedding,它是另一种把序号映射成向量的方法,embedding翻译成嵌入。
我用两个例子讲解embedding。
第一个例子是国籍,字典里有中国、美国、印度、日本、德国等200个国家。
字典把每个国家映射成一个序号,比如中国是一,美国是二,印度是三一共有200个序号。
embedding把每个序号映射成一个向量,这些向量都是低位向量,
比如向量大小都是四乘以一的一个向量就是对一个国家的表示,
未知国籍就用全零向量表示。
我们来分析一下参数的数量,结论是embedding的参数是一个矩阵,大小是向量维度乘以类别数量。
embedding得到的向量都是四维的,一共有200个国际,那么就有200个向量,
参数的数量是4乘以200等于800,
编程实现的话,可以用pytorch就可以搞定。
直接用系统提供的embedding层,
在训练神经网络的时候会自动做反向传播,学习embedding的参数
embedding层的参数是一个矩阵,矩阵的大小是向量维度乘以类别数量
embedding的输入是序号,比如美国的序号是二
embedding层的输出是个向量,即参数矩阵的一列,
比如美国对应参数矩阵的第二列

第二个例子是物品ID的embedding
展示物品的数据库里一共有1万部电影。
推荐系统的任务是给用户推荐电影
embedding向量的维度是16,也就是说,用一个16维的向量表成一部电影。

我们来思考一个问题,embedding层一共有多少参数?
参数的数量等于向量维度乘以类别数量
16乘以1万等于16万,
这就是embedding层参数的数量,
如果类别的数量不大,只有几百万,那么embedding层的实现是比较容易的。
但如果类别数量特别大,比如推荐系统中的物品数量有几十亿,那么embedding层的参数会特别大。
一个神经网络绝大多数的参数都在embedding层。
所以工业界深度学习系统都会对embedding层做很多优化,这是存储和计算效率的关键所在。
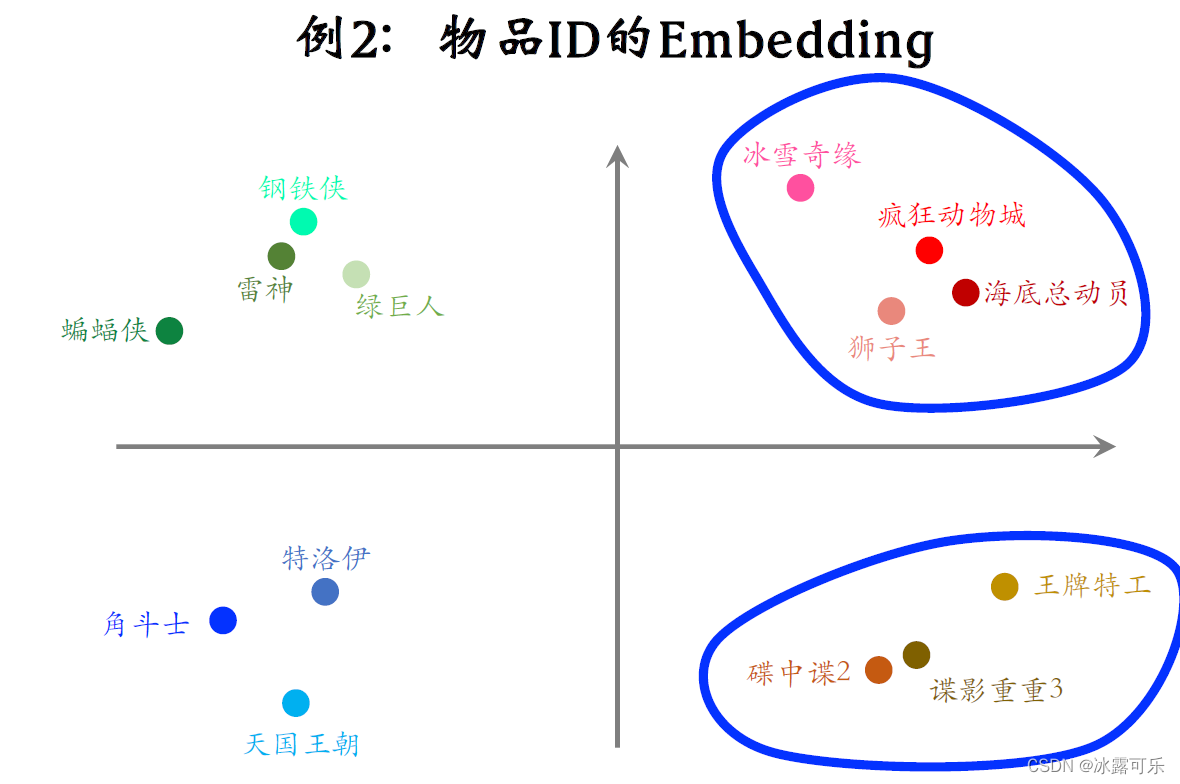
下面我画的示意图说明embedding得到的向量的物理意义。
推荐系统具体怎么样训练embedding层,我下节课再讲
图中的每个点表示一部电影的embedding,如果训练的好,从物品的embedding可以看出物品的特点。
比如右上角这些点都是动画片,它们的距离比较近,
右下角这些点都是间谍片,它们也离的比较近,
但是间谍片和动画片之间的距离会比较远。
最后讲讲embedding和one hot编码之间的关系,
embedding其实就是把one hot的向量乘到一个参数矩阵W上得到的精致向量。

W就是根据神经网络学出来的经典转移矩阵
举个例子,右边是一个one hot的向量,它的第三个元素是一,其余元素全都是零,
中间是embedding乘的参数矩阵W,把矩阵W和one hot向量相乘。
由于one号向量只有第三个元素非零,
所以矩阵向量乘法其实就是取出矩阵W的第三列,把第三列作为输出,
输出的向量就是参数矩阵×one hot向量。
从这个角度看,embedding其实就是矩阵向量乘法。
最后总结一下本文内容,讨论了离散特征的处理,有两种常用的离散特征处理方法,
一种是one hot编码,
一种是embedding
类别数量很大的情况下一般都用embedding,比较常见的例子是word embedding,用户ID embedding,物品ID embedding
word embedding
Embedding在数学上表示一个maping, f: X -> Y,
也就是一个function,其中该函数是injective
(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然)和structure-preserving (结构保存,
比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2)。
那么对于word embedding,就是将单词word映射到另外一个空间,
其中这个映射具有injective和structure-preserving的特点。
通俗的翻译可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,
那么该多维向量相当于嵌入到Y所属空间中,一个萝卜一个坑。
word embedding,就是找到一个映射或者函数,生成在一个新的空间上的表达,
该表达就是word representation。
推广开来,还有image embedding, video embedding, 都是一种将源数据映射到另外一个空间
跟你CNN提取图像特征一样。
用户ID embedding
后续咱再细细说这个怎么构建
物品ID embedding
后续咱再细细说这个怎么构建
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:one hot编码就是总共多少类别,每个类别序号对应位置是1,其余位置是0
embedding其实就是one hot向量×一个学习好的转移矩阵,使得独特的输入x,可以唯一映射到低纬度稠密向量空间的一个特征嵌入表示embedding y,这个转移矩阵W可以通过神经网络学习。


















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











