







半部秘籍–分类、回归、无监督与集成学习
1 分类器
1.1 常用分类器
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
#pip install xgboost -i https://pypi.tuna.tsinghua.edu.cn/simple
from xgboost.sklearn import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.svm import SVC
from sklearn.svm import LinearSVC
from sklearn import decomposition
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
from catboost import CatBoostClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.neural_network import MLPClassifier
from sklearn import cluster, mixture
from sklearn.neighbors import kneighbors_graph
from sklearn.multiclass import OneVsRestClassifier
from sklearn.naive_bayes import MultinomialNB
import lightgbm as lgb
classifiers={
'MLP':MLPClassifier(),
'RandomForest':RandomForestClassifier(),
'DecisionTree':DecisionTreeClassifier(),
'KNeighbors':KNeighborsClassifier(),
'Logistic':LogisticRegression(),
'AdaBoost':AdaBoostClassifier(),
'GaussianNB':GaussianNB(),
'LinearDis':LinearDiscriminantAnalysis(),
'QuadraticDis':QuadraticDiscriminantAnalysis(),
'SVM':SVC(),
'ExtraTrees':ExtraTreesClassifier(),
'Bagging':BaggingClassifier(DecisionTreeClassifier(6),
'XGB':XGBClassifier(),
'GradientBoosting':GradientBoostingClassifier(),
'GradientBoosting':GradientBoostingClassifier(),
'CatBoost':CatBoostClassifier(),
'OneVsRest':OneVsRestClassifier(AdaBoostClassifier()),
'Multion':MultinomialNB(),
'BalBagg':BalancedBaggingClassifier(base_estimator=DecisionTreeClassifier())
}
1.2 分类器评价
分类任务常见的评价指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 score、ROC曲线(Receiver Operating Characteristic Curve)等。
把正例正确分类为正例,表示为TP(true positive),把正例错误分类为负例,表示为FN(false negative),
把负例正确分类为负例,表示为TN(true negative), 把负例错误分类为正例,表示为FP(false positive)
精确率和召回率可以从混淆矩阵中计算而来,precision = TP/(TP + FP), recall = TP/(TP +FN)。
准确率是分类正确的样本占总样本个数的比例
准确率是分类问题中最简单直观的评价指标,但存在明显的缺陷。比如如果样本中有99%的样本为正样本,那么分类器只需要一直预测为正,就可以得到99%的准确率,但其实际性能是非常低下的。也就是说,当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
在多分类问题中一般不直接使用整体的分类准确率,而是使用每个类别下的样本准确率的算术平均作为模型的评估指标。
1.2.1 准确率
准确率是分类问题中最简单直观的评价指标,但存在明显的缺陷。比如如果样本中有99%的样本为正样本,那么分类器只需要一直预测为正,就可以得到99%的准确率,但其实际性能是非常低下的。也就是说,当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
在多分类问题中一般不直接使用整体的分类准确率,而是使用每个类别下的样本准确率的算术平均作为模型的评估指标。
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
print(accuracy_score(y_true, y_pred)) # 0.5
print(accuracy_score(y_true, y_pred, normalize=False)) # 2
1.2.2 精确率
精确率指模型预测为正的样本中实际也为正的样本占被预测为正的样本的比例。
Macro Average: 宏平均是指在计算均值时使每个类别具有相同的权重,最后结果是每个类别的指标的算术平均值。 Micro Average: 微平均是指计算多分类指标时赋予所有类别的每个样本相同的权重,将所有样本合在一起计算各个指标。
‘weighted’: 为每个标签计算指标,并通过各类占比找到它们的加权均值(每个标签的正例数).它解决了’macro’的标签不平衡问题;它可以产生不在精确率和召回率之间的F-score.
‘samples’: 为每个实例计算指标,找到它们的均值(只在多标签分类的时候有意义,并且和函数accuracy_score不同).
当average参数为None时,得到的结果是每个类别的precision。
from sklearn.metrics import precision_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print(precision_score(y_true, y_pred, average='macro'))
print(precision_score(y_true, y_pred, average='micro'))
print(precision_score(y_true, y_pred, average='weighted'))
print(precision_score(y_true, y_pred, average=None))
1.2.3 召回率
召回率指实际为正的样本中被预测为正的样本所占实际为正的样本的比例。 sklearn中recall_score方法和precision_score方法的参数说明都是一样的
Recall和Precision只有计算公式不同,它们average参数为’macro’,‘micro’,'weighted’和None时的计算方式都是相同的,
from sklearn.metrics import recall_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print(recall_score(y_true, y_pred, average='macro'))
print(recall_score(y_true, y_pred, average='micro'))
print(recall_score(y_true, y_pred, average='weighted'))
print(recall_score(y_true, y_pred, average=None))
1.2.4 混淆矩阵
横为true label 竖为predict
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
# 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import plot_confusion_matrix
# import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
class_names = iris.target_names
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# Run classifier, using a model that is too regularized (C too low) to see
# the impact on the results
classifier = svm.SVC(kernel='linear', C=0.01).fit(X_train, y_train)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
titles_options = [("Confusion matrix, without normalization", None),
("Normalized confusion matrix", 'true')]
for title, normalize in titles_options:
disp = plot_confusion_matrix(classifier, X_test, y_test,
display_labels=class_names,
cmap=plt.cm.Blues,
normalize=normalize)
disp.ax_.set_title(title)
print(title)
print(disp.confusion_matrix)
plt.show()
1.2.5 分类报告
包含:precision/recall/fi-score/均值/分类个数
# 分类报告:precision/recall/fi-score/均值/分类个数
from sklearn.metrics import classification_report
y_true = [0, 2, 2, 2, 0,1,4,3,4]
y_pred = [0, 0, 2, 2, 0,2,3,4,2]
target_names = ['class 0', 'class 1', 'class 2', 'class 5', 'class 6']
print(classification_report(y_true, y_pred, target_names=target_names))
1.2.6 F1
F1 score是精确率和召回率的调和平均值,F1 score越高,说明模型越稳健。
F1 score的最好值为1,最差值为0. 精确率和召回率对F1 score的相对贡献是相等的. F1 score的计算公式为: F1 = 2 * (precision * recall) / (precision + recall)
from sklearn.metrics import f1_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print(f1_score(y_true, y_pred, average='macro')) # 0.26666666666666666
print(f1_score(y_true, y_pred, average='micro')) # 0.3333333333333333
print(f1_score(y_true, y_pred, average='weighted')) # 0.26666666666666666
print(f1_score(y_true, y_pred, average=None)) # [0.8 0. 0. ]
1.2.7 kappa score
kappa score是一个介于(-1, 1)之间的数. score>0.8意味着好的分类;0或更低意味着不好(实际是随机标签)
from sklearn.metrics import cohen_kappa_score
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
cohen_kappa_score(y_true, y_pred)
1.2.8 海明距离
from sklearn.metrics import hamming_loss
y_pred = [1, 2, 3, 4]
y_true = [2, 2, 3, 4]
hamming_loss(y_true, y_pred)
1.2.9 Jaccard距离
import numpy as np
from sklearn.metrics import jaccard_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
jaccard_score(y_true, y_pred,average='macro')
1.2.10 铰链损失
铰链损失(Hinge loss)一般用来使“边缘最大化”(maximal margin)。损失取值在0~1之间,当取值为0,表示多分类模型分类完全准确,取值为1表明完全不起作用。
from sklearn.metrics import hinge_loss
y_pred = [0, 1,0,1,1]
y_true = [0, 1,1,0,0]
hinger = hinge_loss(y_true,y_pred)
print(hinger)
1.2.11 P-R曲线
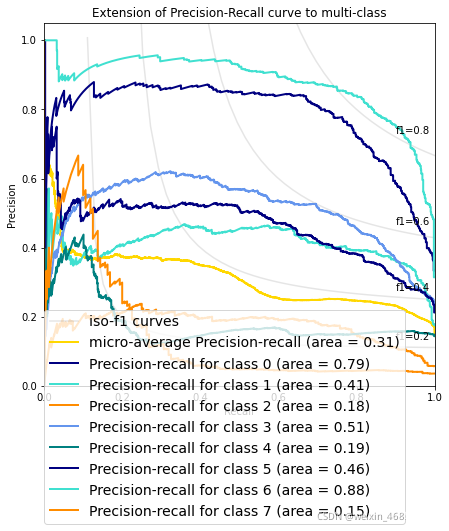
评价一个模型的好坏,不能仅靠精确率或者召回率,最好构建多组精确率和召回率,绘制出模型的P-R曲线。 下面说一下P-R曲线的绘制方法。P-R曲线的横轴是召回率,纵轴是精确率。P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。整条P-R曲线是通过将阈值从高到低移动而生成的。原点附近代表当阈值最大时模型的精确率和召回率。
import numpy as np
from sklearn.metrics import precision_recall_curve
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
precision, recall, thresholds = precision_recall_curve( y_true, y_scores)
print(precision,'\n', recall,'\n', thresholds)
例一:二分类
#二分类曲线
from sklearn.datasets import make_classification
from sklearn.metrics import (precision_recall_curve,PrecisionRecallDisplay)
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import average_precision_score
X, y = make_classification(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
clf = SVC(random_state=0)
clf.fit(X_train, y_train)
SVC(random_state=0)
predictions = clf.predict(X_test)
precision, recall, _ = precision_recall_curve(y_test, predictions)
disp = PrecisionRecallDisplay(precision=precision, recall=recall)
disp.plot()
average_precision = average_precision_score(y_test, predictions)
print('Average precision-recall score: {0:0.2f}'.format(
average_precision))
例二:多分类
def plot_precision_recall_curve(Y_test,y_score,n_classes):
# For each class
precision = dict()
recall = dict()
average_precision = dict()
print("be sure of y_true.shape=(,n_classes),y_pred.shape=(,n_classes)")
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(Y_test[:, i],
y_score[:, i])
average_precision[i] = average_precision_score(Y_test[:, i], y_score[:, i])
# A "micro-average": quantifying score on all classes jointly
precision["micro"], recall["micro"], _ = precision_recall_curve(Y_test.ravel(),
y_score.ravel())
average_precision["micro"] = average_precision_score(Y_test, y_score,
average="micro")
print('Average precision score, micro-averaged over all classes: {0:0.2f}'
.format(average_precision["micro"]))
#Plot the micro-averaged Precision-Recall curve
plt.figure()
plt.step(recall['micro'], precision['micro'], where='post')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title(
'Average precision score, micro-averaged over all classes: AP={0:0.2f}'
.format(average_precision["micro"]))
#Plot Precision-Recall curve for each class and iso-f1 curves
plt.figure(figsize=(7, 8))
f_scores = np.linspace(0.2, 0.8, num=4)
lines = []
labels = []
for f_score in f_scores:
x = np.linspace(0.01, 1)
y = f_score * x / (2 * x - f_score)
l, = plt.plot(x[y >= 0], y[y >= 0], color='gray', alpha=0.2)
plt.annotate('f1={0:0.1f}'.format(f_score), xy=(0.9, y[45] + 0.02))
lines.append(l)
labels.append('iso-f1 curves')
l, = plt.plot(recall["micro"], precision["micro"], color='gold', lw=2)
lines.append(l)
labels.append('micro-average Precision-recall (area = {0:0.2f})'
''.format(average_precision["micro"]))
'''
# setup plot details
colors = cycle(['navy', 'turquoise', 'darkorange', 'cornflowerblue', 'teal'])
for i, color in zip(range(n_classes), colors):
l, = plt.plot(recall[i], precision[i], color=color, lw=2)
lines.append(l)
labels.append('Precision-recall for class {0} (area = {1:0.2f})'
''.format(i, average_precision[i]))
'''
for i in range(n_classes):
l, = plt.plot(recall[i], precision[i],lw=2)
lines.append(l)
labels.append('Precision-recall for class {0} (area = {1:0.2f})'
''.format(i, average_precision[i]))
fig = plt.gcf()
fig.subplots_adjust(bottom=0.25)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Extension of Precision-Recall curve to multi-class')
plt.legend(lines, labels, loc=(0, -.38), prop=dict(size=14))
plt.show()
1.2.12 ROC曲线和AUC
例一:二分类
#!/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegressionCV
from sklearn import metrics
from sklearn.preprocessing import label_binarize
from sklearn import datasets
if __name__ == '__main__':
np.random.seed(0)
iris = datasets.load_iris()
x = iris.data
y = iris.target
print(x.shape,y.shape)
print(y[:10])
print(set(y))
print(y.shape)
print(y[:10])
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size = 0.6, random_state = 0)
Y = label_binarize(y_test, classes=[0, 1, 2])
n_classes = Y.shape[1]
alpha = np.logspace(-2, 2, 20) #设置超参数范围
model = LogisticRegressionCV(Cs = alpha, cv = 3, penalty = 'l2') #使用L2正则化
model.fit(x_train, y_train)
print('超参数:', model.C_)
# 计算属于各个类别的概率,返回值的shape = [n_samples, n_classes]
y_score = model.predict_proba(x_test)
# 1、调用函数计算micro类型的AUC
print('调用函数auc:', metrics.roc_auc_score(Y, y_score, average='micro'))
# 2、手动计算micro类型的AUC
#首先将矩阵y_one_hot和y_score展开,然后计算假正例率FPR和真正例率TPR
fpr, tpr, thresholds = metrics.roc_curve(Y.ravel(),y_score.ravel())
auc = metrics.auc(fpr, tpr)
print('手动计算auc:', auc)
#绘图
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
#FPR就是横坐标,TPR就是纵坐标
plt.plot(fpr, tpr, c = 'r', lw = 2, alpha = 0.7, label = u'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=13)
plt.ylabel('True Positive Rate', fontsize=13)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title(u'鸢尾花数据Logistic分类后的ROC和AUC', fontsize=17)
plt.show()
例二:多分类
def plot_roc_curve(y_test,y_score,n_classes,y_prob=None):
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3213
3213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









