







数据集:鸢尾属植物数据集
包括了三类不同的鸢尾属植物:Iris Setosa,Iris Versicolour,Iris Virginica。每类收集了50个样本。
sepallength:萼片长度
sepalwidth:萼片宽度
petallength:花瓣长度
petalwidth:花瓣宽度
以上四个特征的单位都是厘米(cm)。
1
导入鸢尾属植物数据集,保持文本不变。
loadtxt()和genfromtxt()都可以用来读取文本文件。
genfromtxt()比loadtxt()更加强大,可对缺失数据进行处理。
- np.loadtxt()
loadtxt(fname, dtype=float, comments=’#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding=‘bytes’, max_rows=None)
参数:
fname:文件路径。
dtype=float:数据类型,默认为float。
comments=’#’: 字符串或字符串组成的列表,默认为’#’,表示注释字符集开始的标志。
skiprows=0:跳过多少行,一般跳过第一行表头。
usecols=None:元组(元组内数据为列的数值索引), 用来指定要读取数据的列(第一列为0)。
unpack=False:当加载多列数据时是否需要将数据列进行解耦赋值给不同的变量。 - np.genfromtxt(path,delimiter=’,’,dtype=None,names=True)
功能:从文本文件加载数据,并按指定方式处理缺少的值(是面向结构数组和缺失数据处理的。)
参数:dtype默认float类型。delimiter是指分隔符。names = True表示第一行为列名。
>>> import numpy as np
>>> path = r'D:\wy\data mining\202011datawhale\iris.data.txt'
>>> a = np.loadtxt(path,dtype='object',delimiter=',',skiprows=1)
>>> print(a[:5])
[['5.1' '3.5' '1.4' '0.2' 'Iris-setosa']
['4.9' '3.0' '1.4' '0.2' 'Iris-setosa']
['4.7' '3.2' '1.3' '0.2' 'Iris-setosa']
['4.6' '3.1' '1.5' '0.2' 'Iris-setosa']
['5.0' '3.6' '1.4' '0.2' 'Iris-setosa']]
>>> print(a[-5:])
[['6.7' '3.0' '5.2' '2.3' 'Iris-virginica']
['6.3' '2.5' '5.0' '1.9' 'Iris-virginica']
['6.5' '3.0' '5.2' '2.0' 'Iris-virginica']
['6.2' '3.4' '5.4' '2.3' 'Iris-virginica']
['5.9' '3.0' '5.1' '1.8' 'Iris-virginica']]
2
求出鸢尾属植物萼片长度的平均值、中位数和标准差(第1列,sepallength)
平均值:
numpy.mean(a[, axis=None, dtype=None, out=None, keepdims=np._NoValue)])
中位数:
numpy.median(a, axis=None, out=None, overwrite_input=False, keepdims=False)
标准差:
numpy.std(a[, axis=None, dtype=None, out=None, ddof=0, keepdims=np._NoValue])
CODE:
>>> SL = np.loadtxt(path, dtype = 'float', delimiter = ',', skiprows = 1, usecols = [0])
>>> print(SL[:5])
[5.1 4.9 4.7 4.6 5. ]
>>> print(SL[-5:])
[6.7 6.3 6.5 6.2 5.9]
>>> SL_mean = np.mean(SL)
>>> print(SL_mean)
5.843333333333334
>>> SL_median = np.median(SL)
>>> print(SL_median)
5.8
>>> SL_std = np.std(SL)
>>> print(SL_std)
0.8253012917851409
3
创建一种标准化形式的鸢尾属植物萼片长度,其值正好介于0和1之间,这样最小值为0,最大值为1(第1列,sepallength).
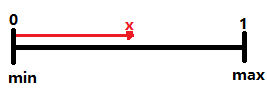
所以x=(a[i]-min)/(max-min)
>>> SL_max = np.amax(SL)
>>> print(SL_max)
7.9
>>> SL_min = np.amin(SL)
>>> print(SL_min)
4.3
>>> x = (SL-SL_min)/(SL_max - SL_min)
>>> print(x[0:10])
[0.22222222 0.16666667 0.11111111 0.08333333 0.19444444 0.30555556
0.08333333 0.19444444 0.02777778 0.16666667]
>>> print(x[:5])
[0.22222222 0.16666667 0.11111111 0.08333333 0.19444444]
>>> print(x[-5:])
[0.66666667 0.55555556 0.61111111 0.52777778 0.44444444]
4
找到鸢尾属植物萼片长度的第5和第95百分位数(第1列,sepallength)。
- np.percentile(a, q, axis=None)
功能:计算分位数
参数:
a:array,用来算分位数的对象,可以是多维的数组。
q:介于0-100的float,用来计算是几分位的参数,如四分之一位就是25,如要算两个位置的数就[25,75]。
axis:坐标轴的方向,一维的就不用考虑了,多维的就用这个调整计算的维度方向,取值范围0/1。
>>> SL_per = np.percentile(SL,[5,95])
>>> print(SL_per)
[4.6 7.255]
5
把iris_data数据集中的20个随机位置修改为np.nan值
- np.random.randint(low, high=None, size=None)
返回一个随机整型数,范围从低(包括)到高(不包括),即[low, high)。
如果没有写参数high的值,则返回[0,low)的值。
>>> test = np.loadtxt(path, dtype = 'object', delimiter = ',', skiprows = 1)
>>> print(test[:5])
[['5.1' '3.5' '1.4' '0.2' 'Iris-setosa']
['4.9' '3.0' '1.4' '0.2' 'Iris-setosa']
['4.7' '3.2' '1.3' '0.2' 'Iris-setosa']
['4.6' '3.1' '1.5' '0.2' 'Iris-setosa']
['5.0' '3.6' '1.4' '0.2' 'Iris-setosa']]
>>> i , j = test.shape
>>> print(i,j)
150 5
>>> np.random.seed(20201201)#随机数种子
>>> test[np.random.randint(i,size = 20), np.random.randint(j, size = 20)] = np.nan
>>> print(test[:5])
[['5.1' '3.5' '1.4' '0.2' 'Iris-setosa']
['4.9' '3.0' '1.4' '0.2' 'Iris-setosa']
['4.7' '3.2' '1.3' '0.2' 'Iris-setosa']
[nan '3.1' '1.5' '0.2' 'Iris-setosa']
['5.0' '3.6' '1.4' '0.2' 'Iris-setosa']]
>>> print(test[100:105])
[['6.3' '3.3' '6.0' '2.5' 'Iris-virginica']
['5.8' nan '5.1' '1.9' nan]
['7.1' '3.0' '5.9' '2.1' 'Iris-virginica']
['6.3' '2.9' '5.6' '1.8' 'Iris-virginica']
[nan '3.0' '5.8' '2.2' 'Iris-virginica']]
6
在iris_data的sepallength中查找缺失值的个数和位置(第1列)
-
np.isnan(x)
功能:判断x是否有空值 -
np.where(condition,x,y)
功能: 判断是否满足条件,满足条件(condition),输出x,不满足输出y。
如果只有条件,没有x,y,则输出满足条件(非0)的元素的坐标。坐标以tuple的形式给出。
CODE
>>> import numpy as np
>>> path = r'D:\wy\data mining\202011datawhale\iris.data.txt'
>>> test = np.loadtxt(path, dtype = 'object', delimiter = ',', skiprows = 1)
>>> i,j = test.shape#把数组的行数、列数赋值给i,j
>>> np.random.seed(20201201)
#给20个位置赋值为nan
>>> test[np.random.randint(i,size = 20),np.random.randint(j, size = 20)] = np.nan
>>> print(test[100:105])
[['6.3' '3.3' '6.0' '2.5' 'Iris-virginica']
['5.8' nan '5.1' '1.9' nan]
['7.1' '3.0' '5.9' '2.1' 'Iris-virginica']
['6.3' '2.9' '5.6' '1.8' 'Iris-virginica']
[nan '3.0' '5.8' '2.2' 'Iris-virginica']]
>>> test0 = test[:,0]#sepallength为数组的第一列
>>> test0 = np.array(test0,dtype = np.float)#将类型由object转为float
>>> test0.dtype
dtype('float64')
>>> test.dtype
dtype('O')
>>> x = np.isnan(test0)#判断第一列有多少个为nan,如果是nan,则返回True,不是则返回False。
>>> print(x)
[False False False True False False False False False False False False
False False False False False True False False False False False False
False False False False False False False False False False False False
False False False False True False False False False False False False
False False False False False False False False False False False False
False False False False False False False False False False False False
False False False False False False False False False False False False
False False False True False False False False False False False False
False False False False False False False False True False False False
False False False False False False False False False False False False
False False False False False False False False False False False False
False False False False False False False False False False False False
False False False False False False]
>>> print(sum(x))#150个数,相加,就可以得到有多少个nan。
5
>>> print(np.where(x))
(array([ 3, 17, 40, 87, 104], dtype=int64),)
7
筛选具有 sepallength(第1列)< 5.0 并且 petallength(第3列)> 1.5 的 iris_data行.
- np.logical_and/or/not(x,y)
功能:与或非
>>> SL = np.loadtxt(path, delimiter = ',', dtype = 'float', skiprows = 1, usecols = [0])
>>> SL.shape
(150,)
>>> print(SL[:5])
[5.1 4.9 4.7 4.6 5. ]
>>> PL = np.loadtxt(path, delimiter = ',', dtype = 'float', skiprows = 1, usecols = [2])
>>> rows = np.where(np.logical_and(SL<5.0,PL>1.5))
>>> print(rows)
(array([ 11, 24, 29, 30, 57, 106], dtype=int64),)
>>> irisdata = np.loadtxt(path, delimiter =',', dtype = 'object',skiprows = 1)
>>> print(irisdata[rows])
[['4.8' '3.4' '1.6' '0.2' 'Iris-setosa']
['4.8' '3.4' '1.9' '0.2' 'Iris-setosa']
['4.7' '3.2' '1.6' '0.2' 'Iris-setosa']
['4.8' '3.1' '1.6' '0.2' 'Iris-setosa']
['4.9' '2.4' '3.3' '1.0' 'Iris-versicolor']
['4.9' '2.5' '4.5' '1.7' 'Iris-virginica']]
8
选择没有任何 nan 值的 iris_data行。
【知识点:逻辑函数、搜索】
如何从numpy数组中删除包含缺失值的行?















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









