







官方提供了一部分的框架的 sink。除此以外,需要用户自定义实现 sink.
一.kafka sink
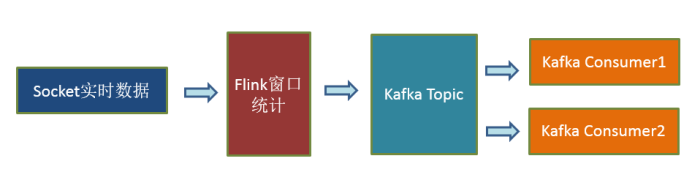
示例:
1.启动zk、kafka:
$ zkServer.sh start
$ cd /usr/local/kafka
$ bin/kafka-server-start.sh config/server.properties

2.在kafka上创建一个topic t2:

3.在realtime工程的pom.xml文件中添加如下依赖(如果之前已添加则忽略):
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.11.3</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.3</version>
</dependency>
4.编写代码如下:

5.开启ubuntu端的nc控制台:
6.运行IDEA程序,在nc控制台不断输入文本:

此时可以看到Kafka的对应topic中已经有计算后的数据:的输出如下:

7. 最终代码
package com.edu.neusoft.bigdata.flink.sink;
import com.edu.neusoft.bigdata.flink.entity.WordCount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class KafkaSink {
public static void main(String[] args) throws Exception {
//1.初始化env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.source
DataStreamSource<String> socketSource = env.socketTextStream("192.168.237.128", 9001, "\n");
//3.transformation
DataStream<String> stream = socketSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(word);
}
}
}).map(new MapFunction<String, WordCount>() {
@Override
public WordCount map(String word) throws Exception {
return new WordCount(word, 1);
}
})
.keyBy("word")
.timeWindow(Time.seconds(5),Time.seconds(1))
.sum("count")
.map(w -> w.toString());
//
//4.sink
//Kafka配置
String brokerList = "192.168.237.128:9092";
String topic = "t2";
Properties prop = new Properties();
prop.setProperty("bootstrap.servers",brokerList);
//初始化FlinkKafkaProducer
FlinkKafkaProducer011<String> kafkaProducer = new FlinkKafkaProducer011<>(brokerList, topic, new SimpleStringSchema());
stream.addSink(kafkaProducer);
stream.print().setParallelism(1);
// stream.print().setParallelism(1);
//5.运行env
env.execute("SocketWindowWordCount2Kafka");
}
}
二.MySQL sink
注意:Flink并未直接提供MySQL可用的Sink,所以要通过自定义Sink的方式实现一个MysqlSink。

在jdbc里最耗时的是建立连接.

1.启动MySQL服务:
$ sudo service mysql stop
$ sudo service mysql start
可以通过执行如下命令,查看服务是否启动成功:
$ sudo netstat -tap | grep mysql

也可以通过如下命令查看服务是否启动成功:
$ sudo service mysql status

2.开启MySQL客户端(这里采用MySQL workbench),创建一个数据realtime:
并在该realtime库下创建一个表wordcount:
CREATE TABLE wordcount (
word varchar(50) COLLATE utf8_unicode_ci DEFAULT NULL,
count int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci

3. 在realtime工程的pom.xml中添加如下依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.40</version>
</dependency>
4.编写代码如下:

还是除了sink部分其他都和之前Kafka sink一样,这里可以看到addsink需要的是一个sinkfunction。那么问题来了sinkfunction到底是个什么?

我们按住CTRL键点击addsink查看它的源码,所以我们就可以知道addsink传进去的是一个sinkfunction实现类的对象
然后我们在点击sinkfunction,发现它是一个interface(接口),

然后我们按住CTRL+f3查看实现的方法都有什么,发现是invoke


所以说白了我们就是要实现一个sinkfunction的接口类实现里面的invoke方法,invoke里写jdbc的代码。然后我们按住f4查看它继承的体系,
然后我们假如点击richsinkfunction,发现它是继承了richsinkfunction,它是一个abstract抽象类,所以它底下还有相应的实现类

那这样的话我们就可以写mysqlsinkfunction这个接口,这里有一个要实现的方法override implement

这个invoke,它主要干什么我们自己说了算,我们必须要实现的方法就是连接mysql

invoke里连接mysql主要分三步骤,那么我们看一下invoke方法的说明

到这里的代码
package com.edu.neusoft.bigdata.flink.sink;
import com.edu.neusoft.bigdata.flink.entity.WordCount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class MySQLSink {
public static void main(String[] args) throws Exception {
//1.初始化env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.source
DataStreamSource<String> socketSource = env.socketTextStream("192.168.237.128", 9001, "\n");
//3.transformation
DataStream<WordCount> stream = socketSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(word);
}
}
}).map(new MapFunction<String, WordCount>() {
@Override
public WordCount map(String word) throws Exception {
return new WordCount(word, 1);
}
})
.keyBy("word")
.timeWindow(Time.seconds(5),Time.seconds(1))
.sum("count");
//
//4.sink
MysqlSinkFunction sink = new MysqlSinkFunction();
stream.addSink(sink);
stream.print();
//5.运行env
env.execute("SocketWindowWordCount2Kafka");
}
}
class MysqlSinkFunction implements SinkFunction<WordCount>{
private Connection connection = null;
private PreparedStatement preparedStatement;
String drivername = "com.mysql.jdbc.Driver";
String dburl = "jdbc:mysql://192.168.237.128:3306/realtime?serverTimezone=GMT%2B8&useSSL=false";
String username = "root";
String password = "hadoop";
String sql = "insert into wordcount(`word`,`count`) values(?,?)";
@Override
public void invoke(WordCount w, Context context) throws Exception {
//1.建立connection
if (connection == null) {
Class.forName(drivername);
connection = DriverManager.getConnection(dburl, username, password);
}
if (preparedStatement == null) {
preparedStatement = connection.prepareStatement(sql);
}
//执行insert
preparedStatement.setString(1, w.getWord());
preparedStatement.setInt(2, w.getCount());
preparedStatement.executeUpdate();
//关闭连接
if (preparedStatement != null) {
preparedStatement.close();
}
preparedStatement = null;
if (connection != null) {
connection.close();
}
connection = null;
}
}
其实写到这里问们就完成我们要实现的方法了,但是在实际生产中的数据瞬间这个程序就会挂掉,因为每执行一个sql语句都会创建一个连接断开一个连接,成本代价太高,这样就非常的慢。那我们应该怎么改进呢,我们可不可以按照一个线程创建一个连接,这样我们就会涉及到一个叫生命周期的东西。

我们现在实现最核心的代码是invoke,注释里写道invoke会把拿到的值一条一条的处理,然后我们刚刚按f4查看继承体系时发现它继承了一个叫RichSinkFunction,点进去一看是一个抽象类aabstract class,抽象类不能直接new。RichSinkFunction处了implements一个sinkfunction还extends了一个叫AbstratRichFunction,那这个类是什么呢

点进去它也是一个抽象类,它的方法里有一个叫 Default life cycle methods(生命周期)

那么我们重新编写这个类,这回我们extends那个叫RichSinkFunction。这回我们实现两个功能一个是invoke一个是生命周期。


5.最终代码
package com.edu.neusoft.bigdata.flink.sink;
import com.edu.neusoft.bigdata.flink.entity.WordCount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class MySQLSink {
public static void main(String[] args) throws Exception {
//1.初始化env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.source
DataStreamSource<String> socketSource = env.socketTextStream("192.168.237.128", 9001, "\n");
//3.transformation
DataStream<WordCount> stream = socketSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(word);
}
}
}).map(new MapFunction<String, WordCount>() {
@Override
public WordCount map(String word) throws Exception {
return new WordCount(word, 1);
}
})
.keyBy("word")
.timeWindow(Time.seconds(5),Time.seconds(1))
.sum("count");
//
//4.sink
MysqlSinkFunction sink = new MysqlSinkFunction();
stream.addSink(sink);
stream.print();
//5.运行env
env.execute("SocketWindowWordCount2Kafka");
}
}
class MysqlSinkFunction extends RichSinkFunction<WordCount> {
private Connection connection = null;
private PreparedStatement preparedStatement;
String drivername = "com.mysql.jdbc.Driver";
String dburl = "jdbc:mysql://192.168.237.128:3306/realtime?serverTimezone=GMT%2B8&useSSL=false";
String username = "root";
String password = "hadoop";
@Override
public void open(Configuration parameters) throws Exception {
//建立连接connection
String sql = "insert into wordcount(`word`,`count`) values(?,?)";
if (connection == null) {
Class.forName(drivername);
connection = DriverManager.getConnection(dburl, username, password);
}
if (preparedStatement == null) {
preparedStatement = connection.prepareStatement(sql);
}
}
@Override
public void close() throws Exception {
//关闭连接
if (preparedStatement != null) {
preparedStatement.close();
}
preparedStatement = null;
if (connection != null) {
connection.close();
}
connection = null;
}
@Override
public void invoke(WordCount w, SinkFunction.Context context) throws Exception {
//逐条insert
preparedStatement.setString(1, w.getWord());
preparedStatement.setInt(2, w.getCount());
preparedStatement.executeUpdate();
}
}
6.开启ubuntu端的nc控制台
7.运行IDEA程序,在nc控制台不断输入文本:

此时可以看到IDEA控制台的输出如下:

8.观察MySQL workbench客户端,可以看到Flink产生的数据已经被实时存储在MySQL中:















 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









