









哈工大操作系统公开课
操作系统需要有计算机组成原理基础和汇编语言基础
上半部分看这个,包含操作系统启动、操作系统接口、多进程管理、信号量、死锁处理等相关内容。
操作系统上半部分
如果是开发的小伙伴想快速补课,可以看这个文章,写的很好
操作系统快速补课(开发人员版本)
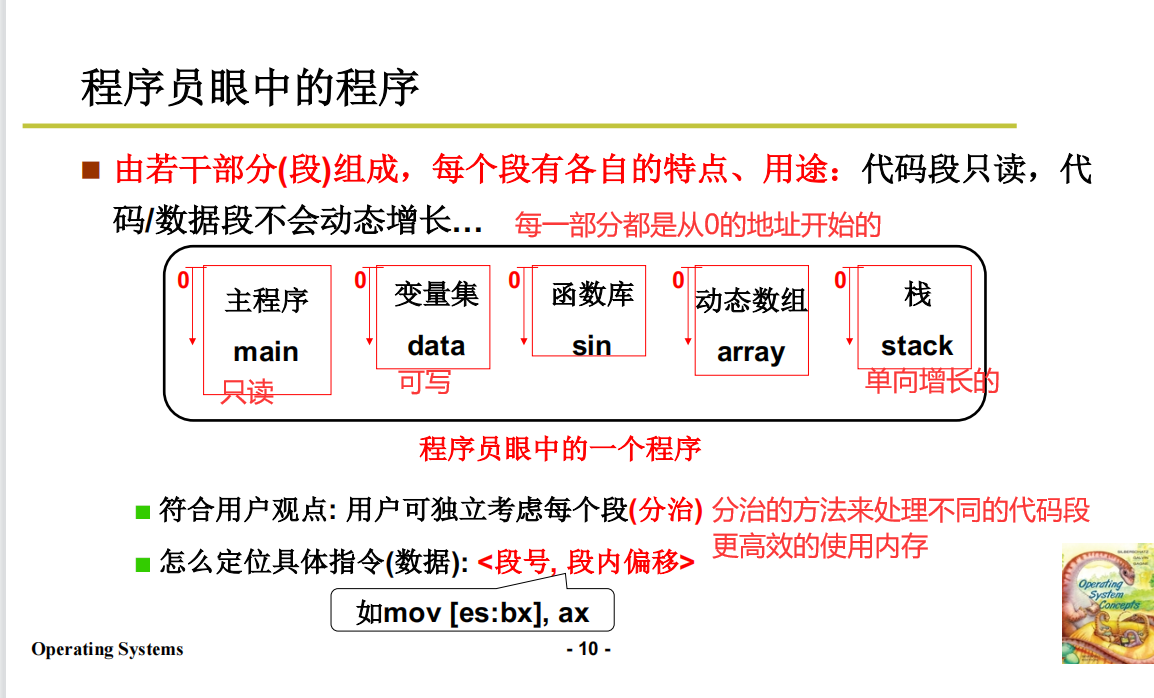
内存的使用与分段
如何让内存用起来
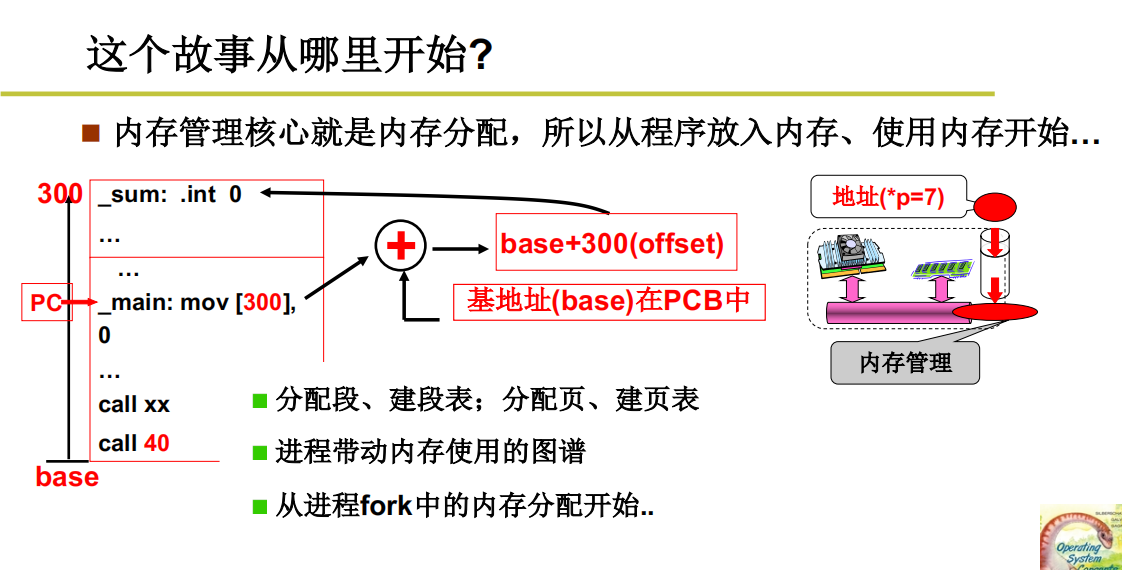
从计算机开始工作开始,将程序放在内存中,指针指向内存地址取指执行。就是使用内存的开始。
那如何让程序放入内存?就是利用汇编指令。
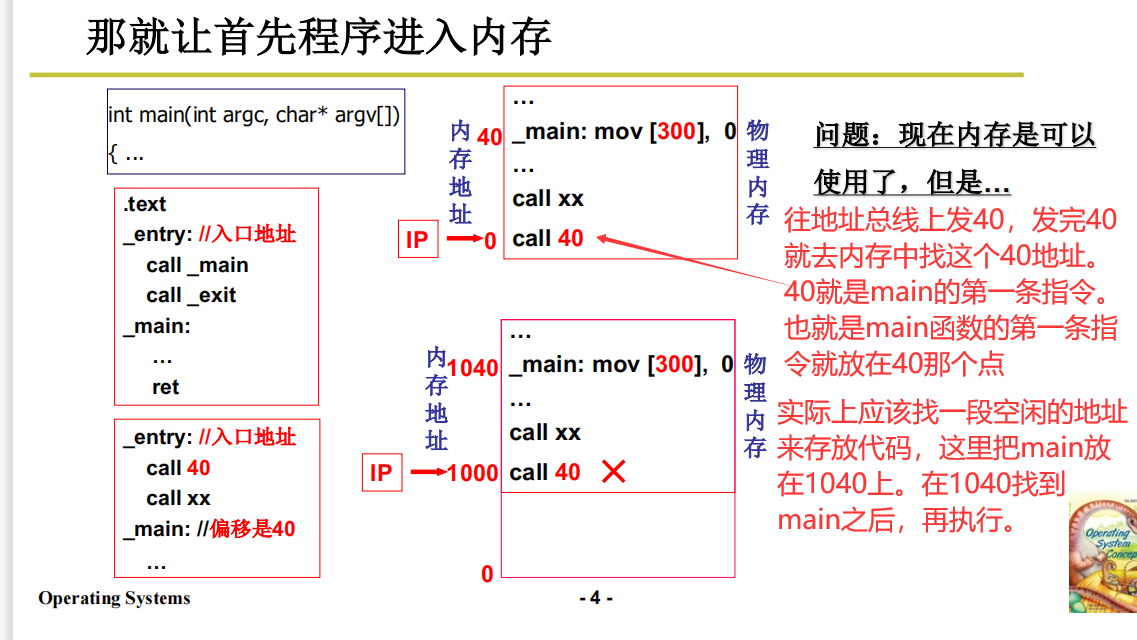
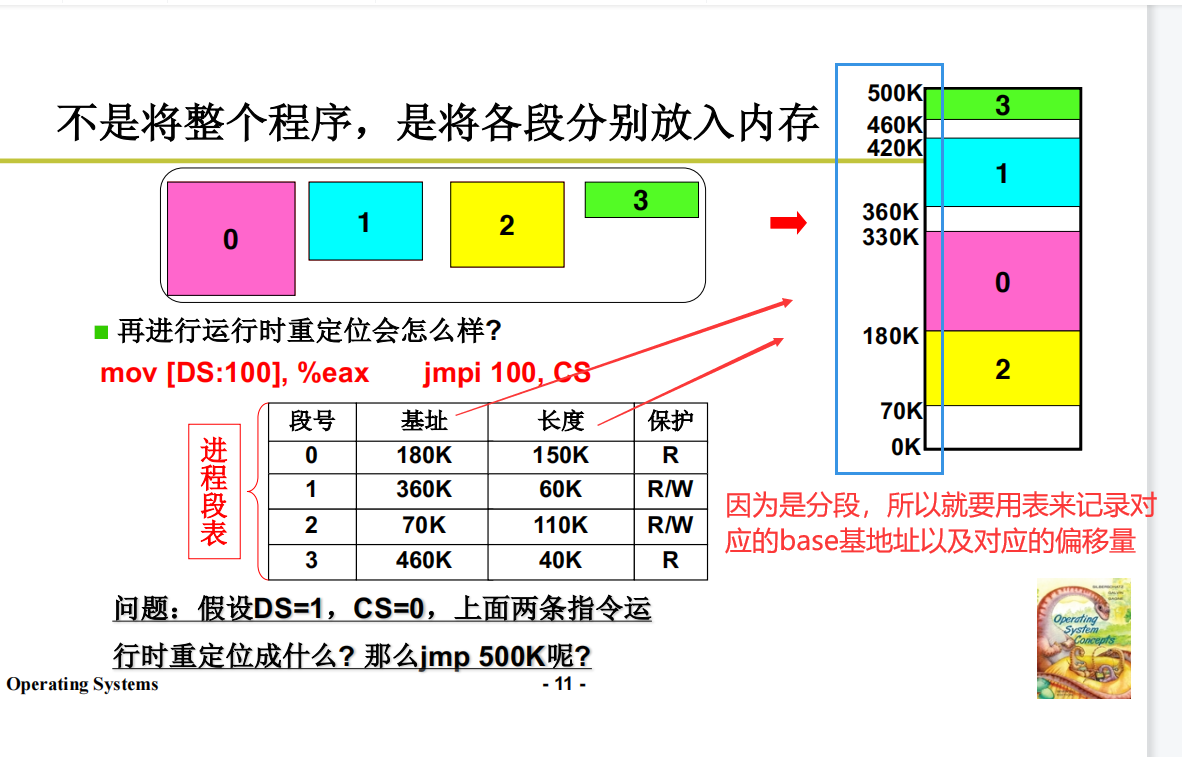
地址重定位(找内存空位)

交换机制
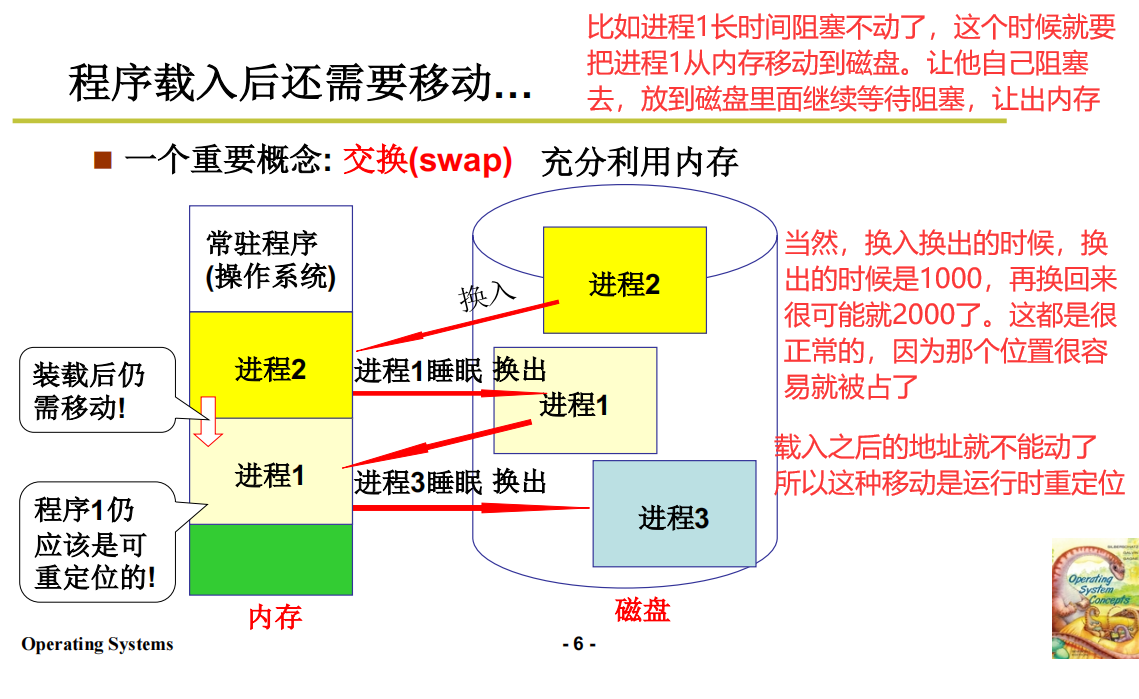
由此引出,运行时重定位。不管你放在哪里,我都是运行的时候再找空闲的物理地址。
运行时重定位
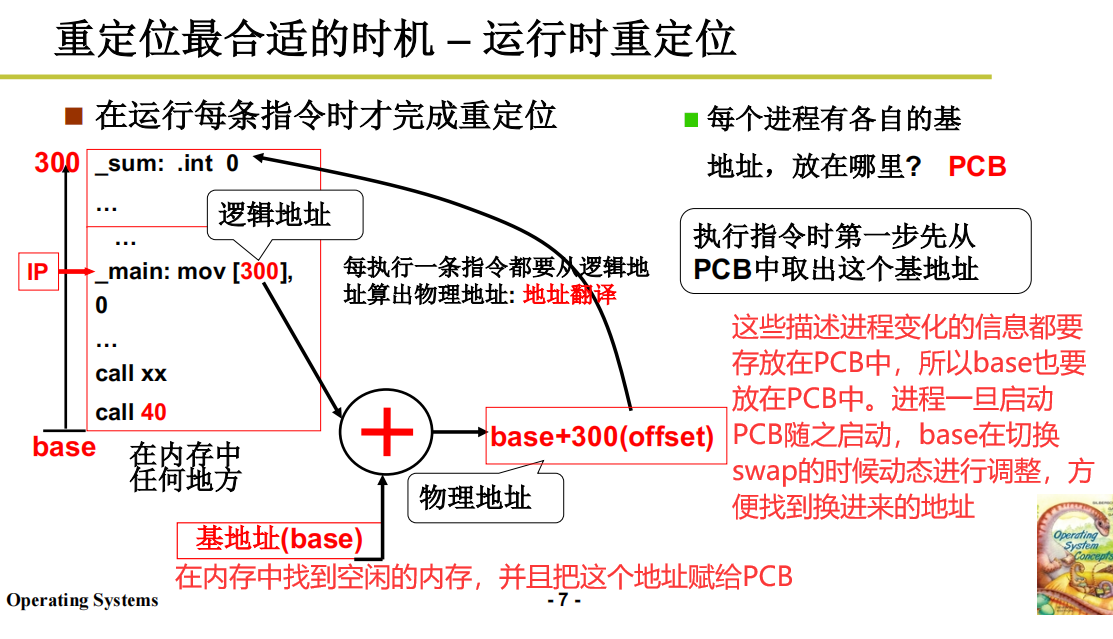
捋一下:把一个程序放到内存中(空闲单元),把这段空闲地址的base基地址拿出来,放给进程的PCB。把程序放到刚刚找到的空闲内存里,在上下文切换的时候,PCB的base基地址就变成了基地址寄存器。每次执行的时候就进行动态的翻译,找到实际的物理内存的地址。

分段
分段是由编译来做的,不归我们管
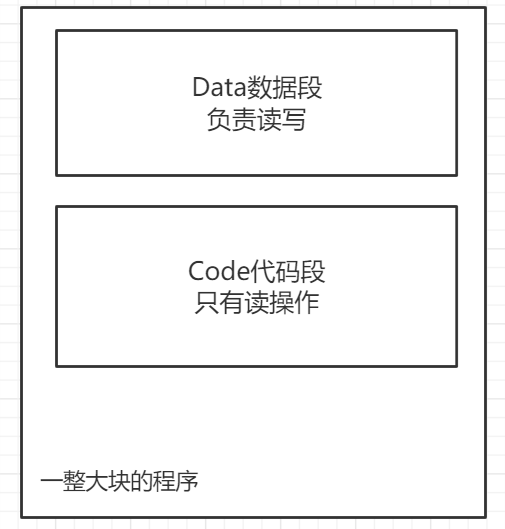
先说结论,代码大体可以分为两个段落:
符合分治的思想,分而治之,让其更好的操作和读写。后面的代码分段就是依托于这种思想进行的分段操作。
- Data数据段,负责读写
- Code代码段,负责读操作
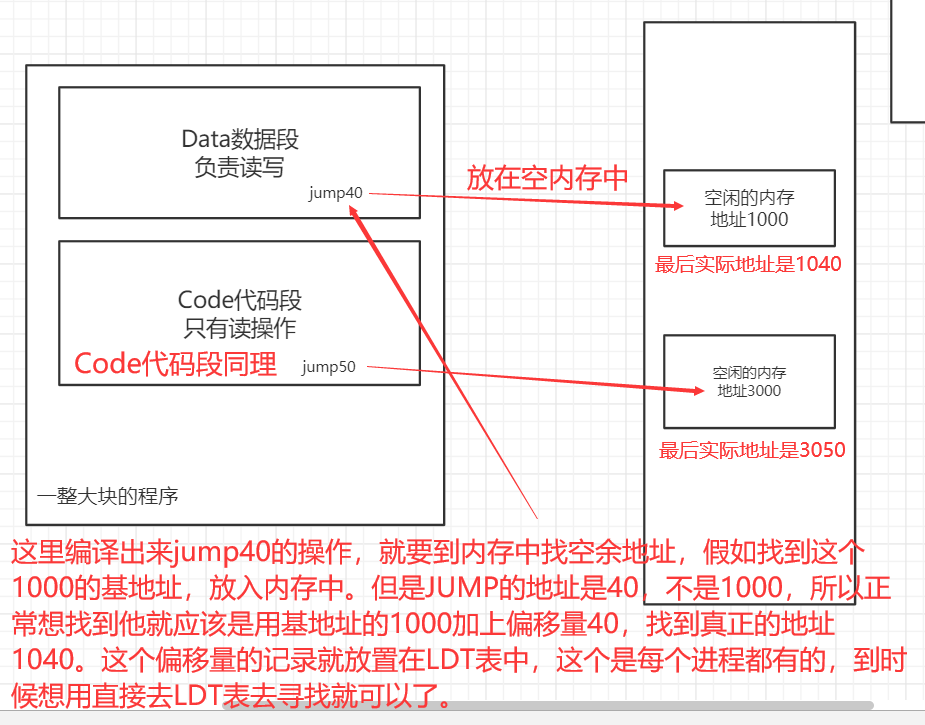
那么整个程序载入内存的时候,先找到空闲的地址,找到空闲地址,将base地址放到PCB中。上面的内容是把整段的程序放进内存,而这里是把程序分段放入内存中。
捋一下分段存储LDT表,整个重定位到真实的内存地址的过程:
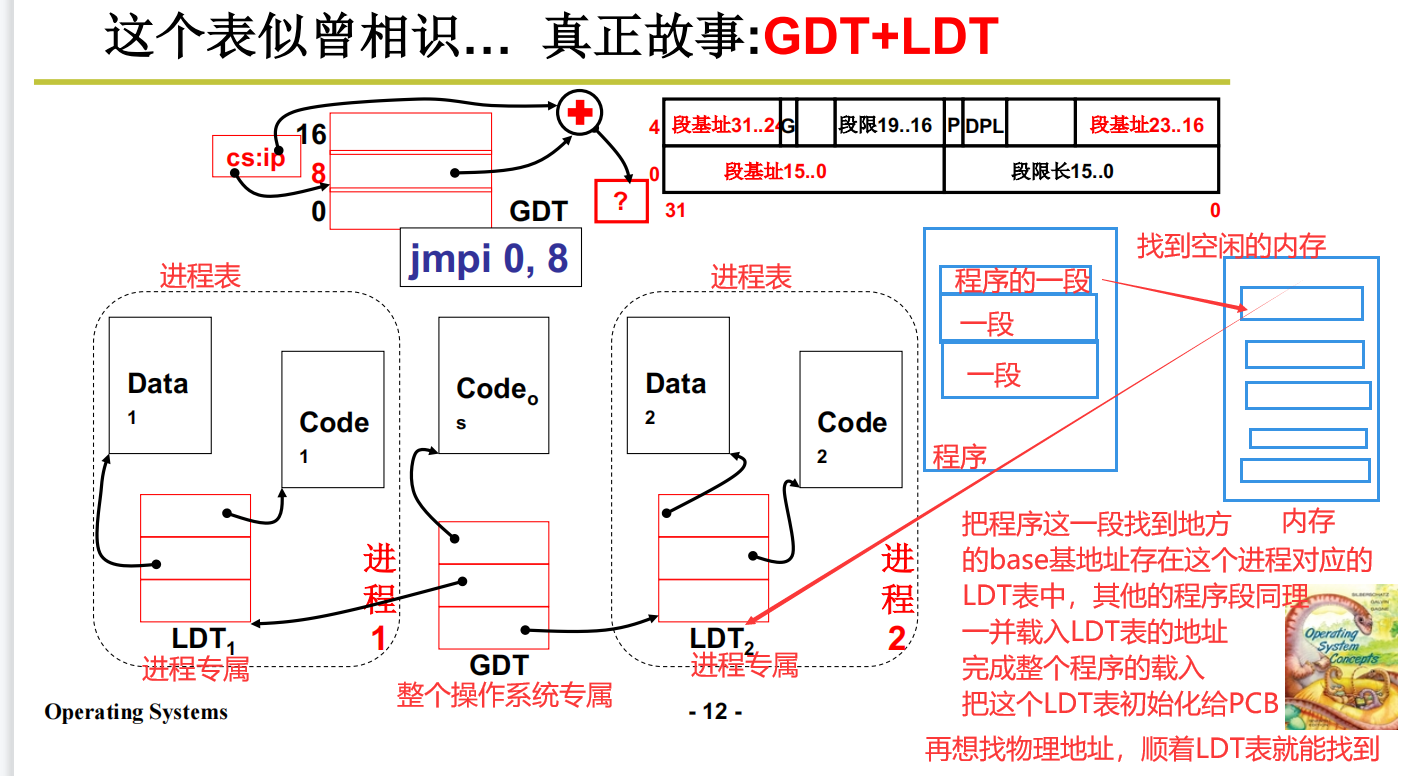
GDT & LDT
这俩玩意是干啥的?GDT是找LDT的,LDT是记录进程端程序如何重定位。因为LDT是跟线程相关的,所以LDT是放在PCB中的,也就是每个PCB中都有一套LDT
GDT表(GDT Global Descriptor Table全局描述表),实际上就是操作系统对应的段表,粗略的理解一下可以把他认为是操作系统级别的,整理这些下面的LDT表地址的集合。
LDT表(linear Data Table 线性数据表)实际上对应的该是每个进程所对应的段表,粗略的理解一下可以把他认为是进程级别的,记录分段程序基地址的表,取出来真实地址的时候就把LDT表作为依据。并且,由于LDT是进程相关的,所以LDT是放在PCB中的。
捋一遍思路:
分段出来的程序,其中某一段,在内存中找到空余的内存区域,把这段程序放进去。放进去之后会有一个base的基地址。这个base基地址会被存到LDT表中(每个进程一个)。等到用这个代码的时候上哪找呢?会根据汇编指令的地址做一个加和。比如base是1000加和一个偏移量200,最终得到的内存地址偏移到1200,去1200的位置找就可以找到。最后LDT去哪找?LDT作为线程级别的直接找肯定不好找,要直接去GDT表找就可以了。
内存分区与分页
温故知新,如何管理好内存?
管理好内存就是让他良好的运行起来,让程序写入到内存,写入之后让CPU对内存进行取指执行。通过不断的取指执行就可以完成对于内存的良好管理。
我们知道,代码应该分段为Data数据段和Code代码段。这两个数据段要在内存中找空出来的内存区域放进去,所以这个空的内存区域怎么找非常重要。也就是这章节的重点,操作系统是怎么找这么一段空闲分区,一旦找到,就把分段的内容读入内存中。
内存分区
接下来的问题是内存怎么割?
这样就可以将程序的各个段载入到相应的内存分区中了
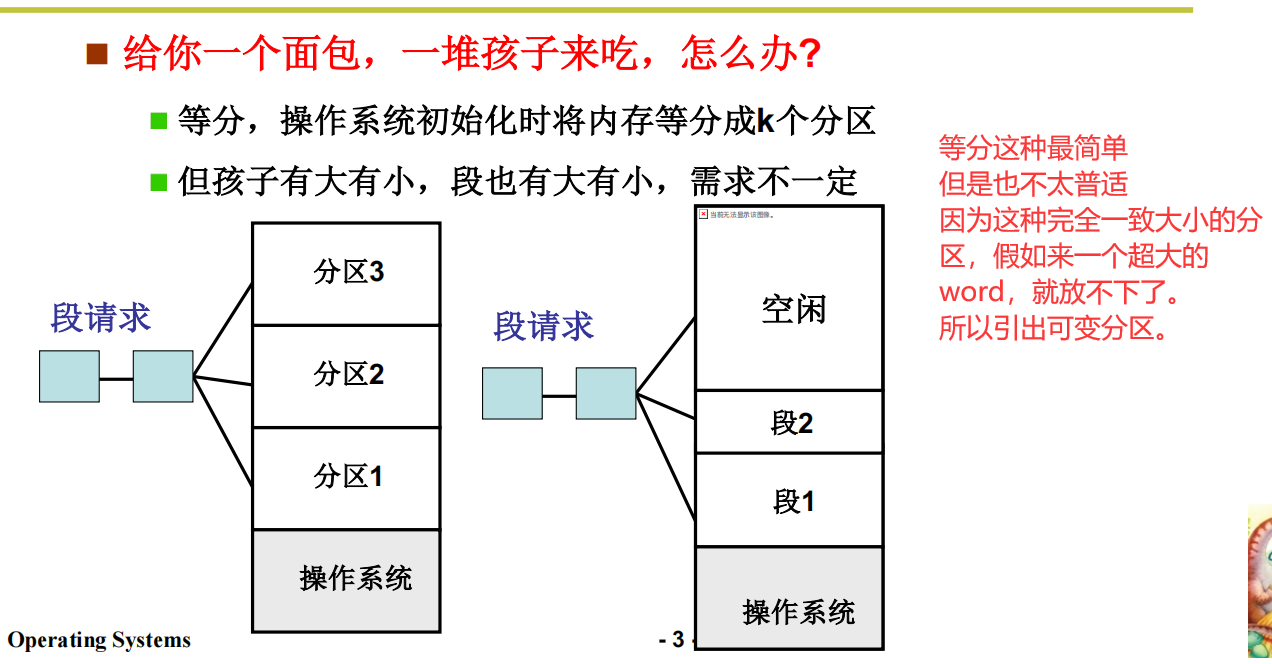
固定分区 与 可变分区
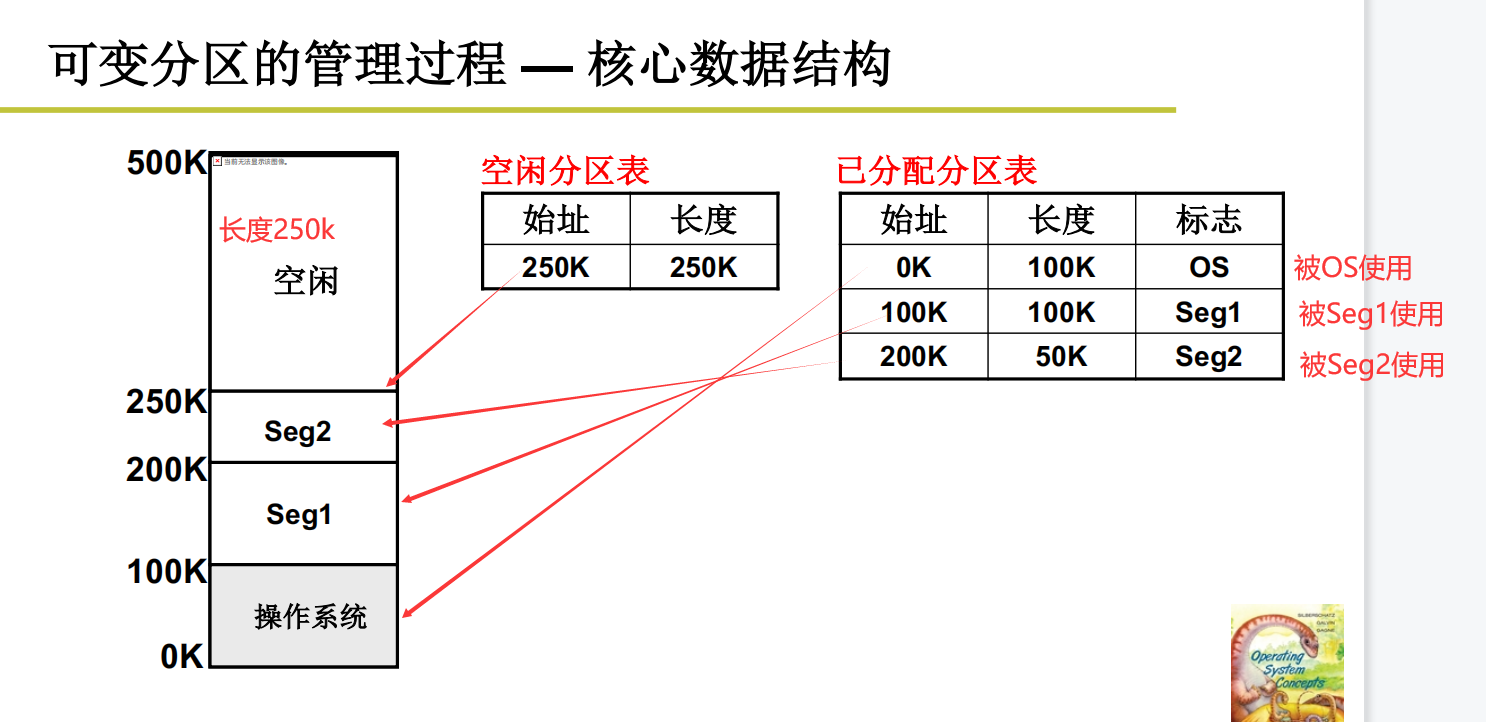
请求分区(申请内存)
对请求进行分配,这个还是挺简单的
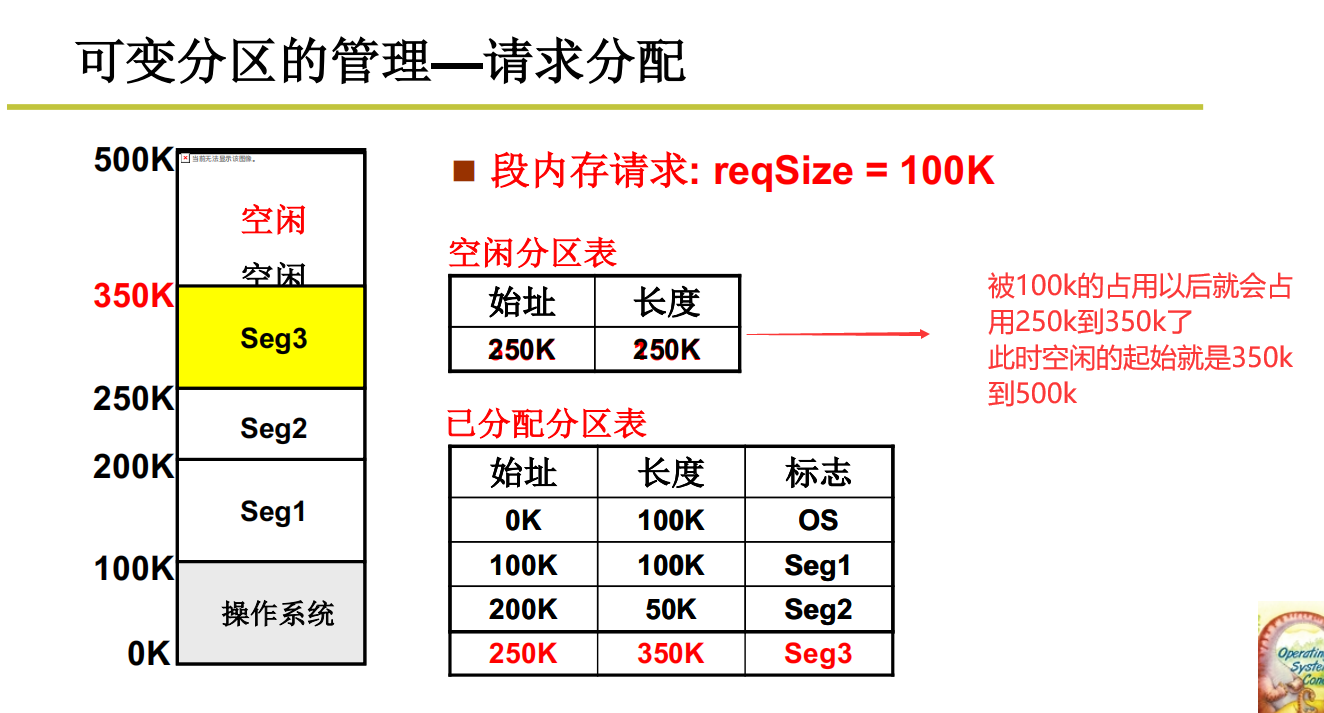
释放分区(释放内存)
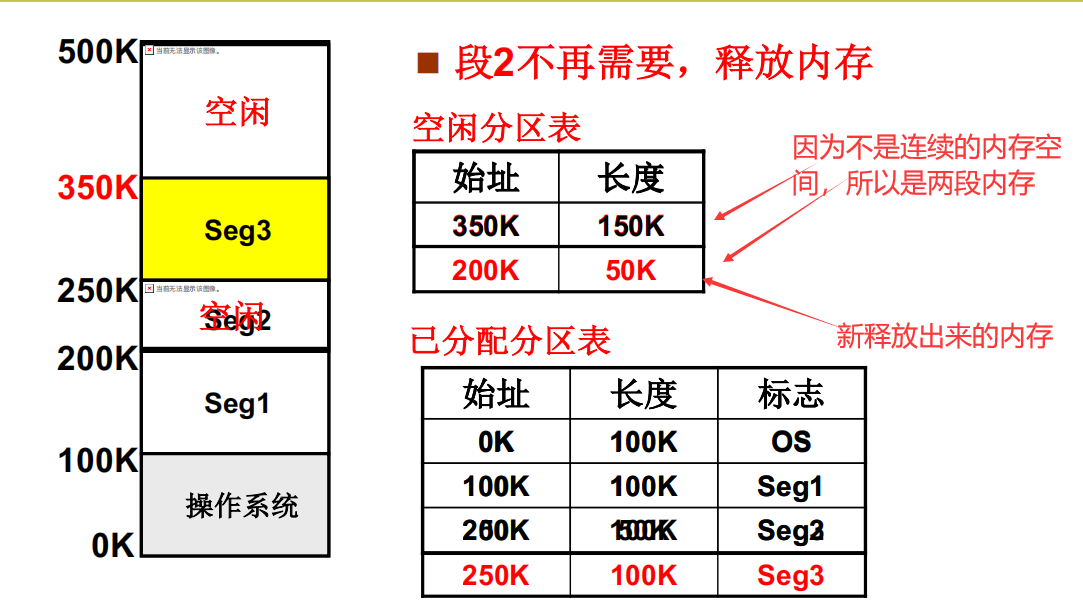
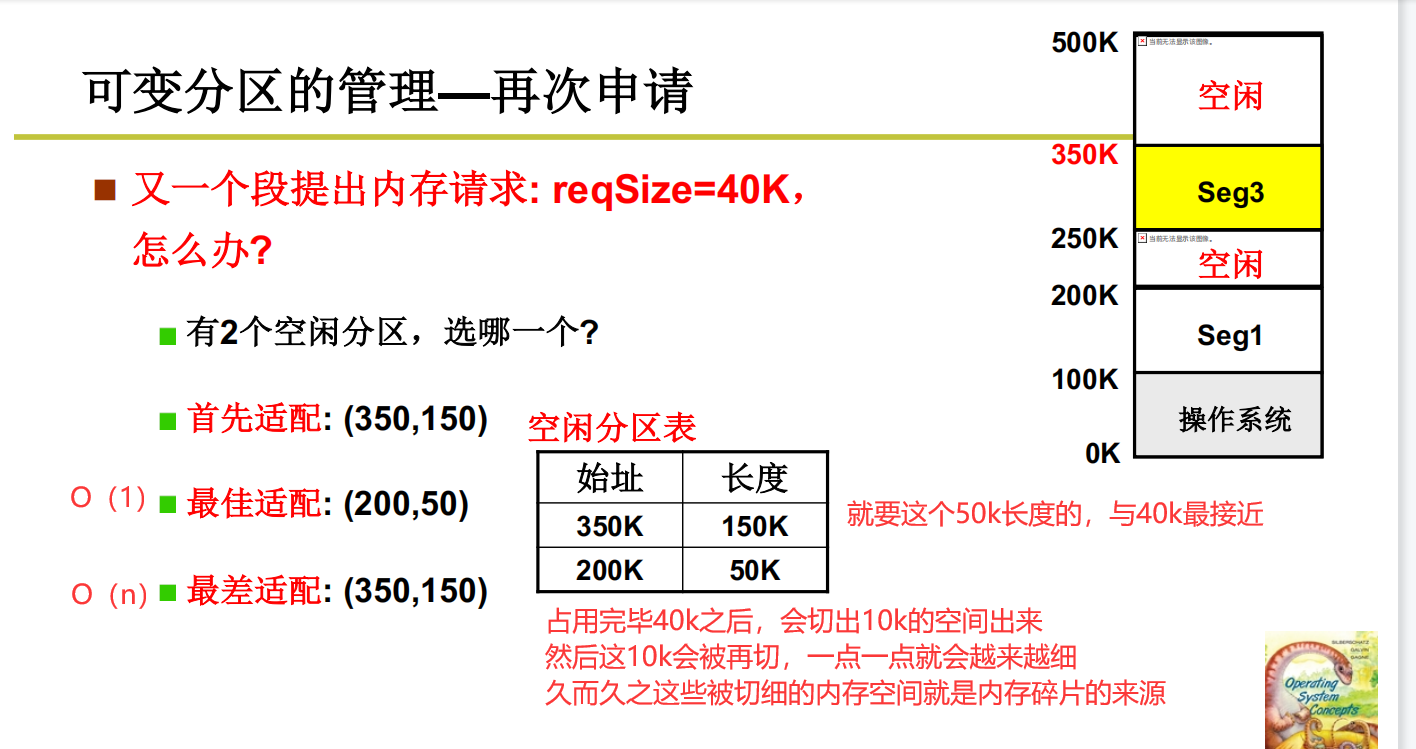
再次申请内存(怎么选空闲的内存)
先说结论,先找满足条件的内存,然后找与当前内存最接近的内存空间作为申请的空间。这样,操作系统就可以使用内存了,并且在此基础上操作系统就可以取指执行,就构成了一个最小的操作系统。
内存分页
可变分区造成的内存碎片问题
基于上面的分割操作,就会在不断分割的过程中产生大量的内存碎片

解决方案
内存分页的思想,把每页分为4K的大小,就像一个一个小格子,需要多少分配多少,一定程度上避免了内存浪费的情况出现。

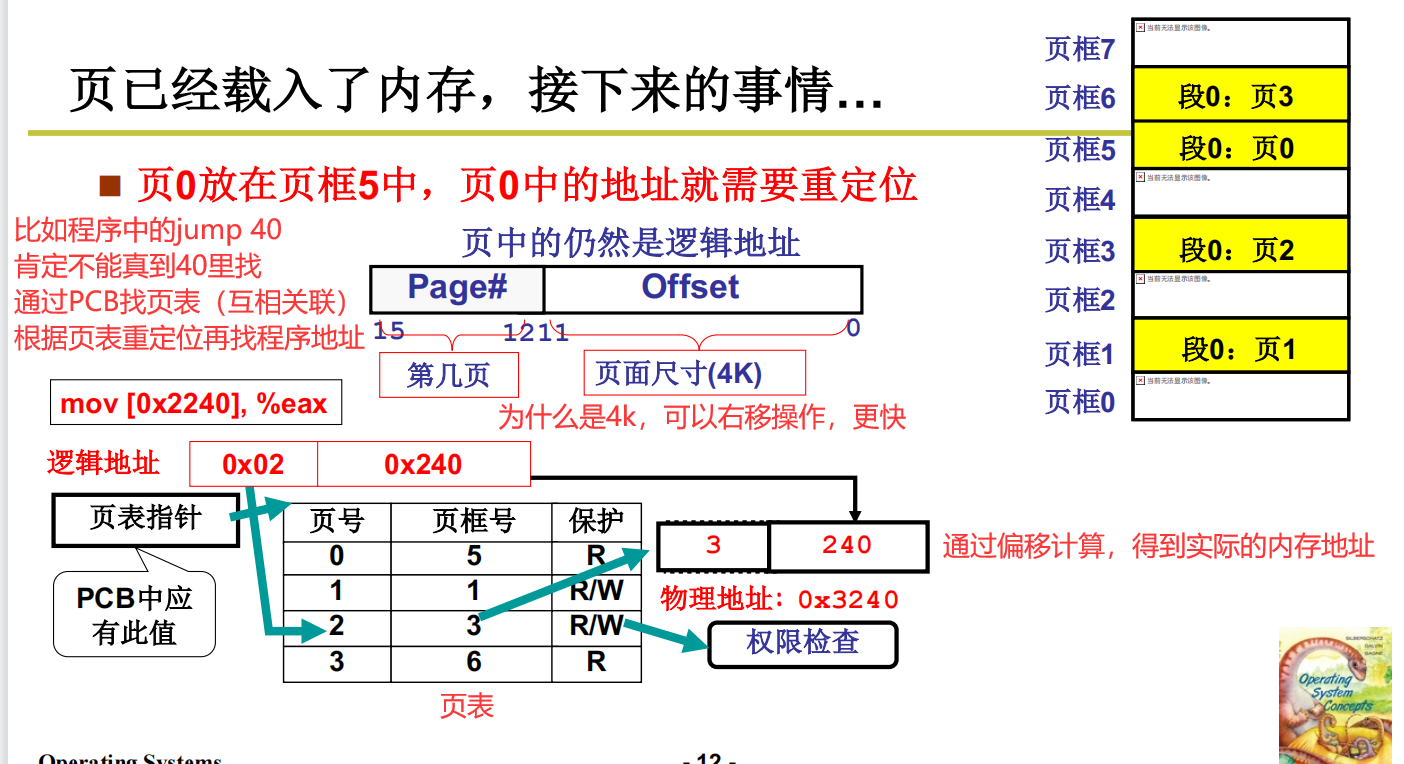
在页表中重定位
页表的功能就是根据逻辑页找到物理页
多级页表与快表
多级页表
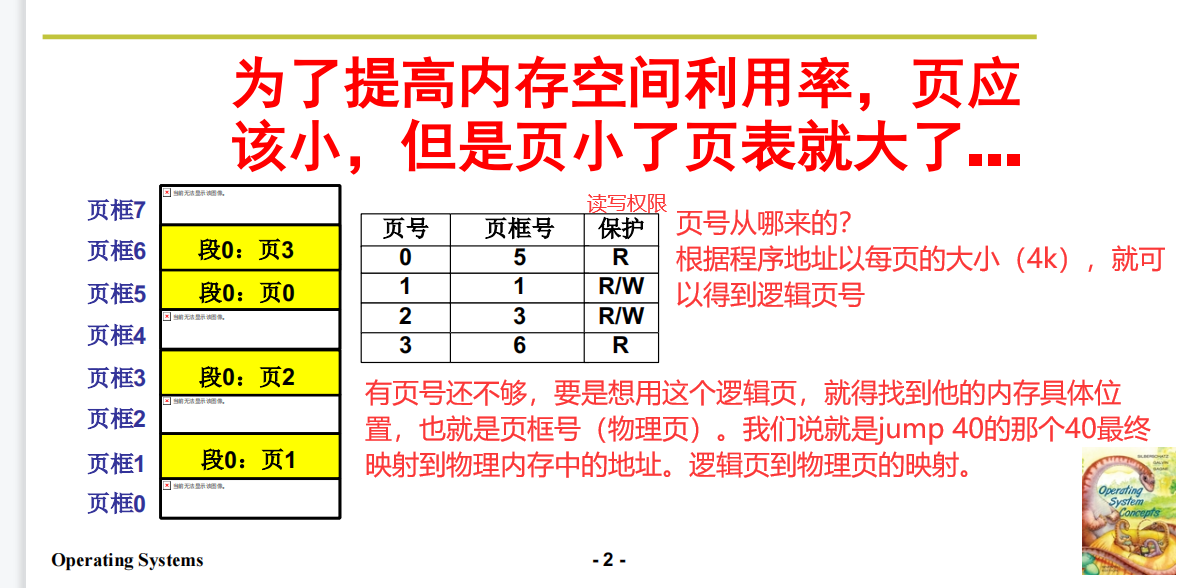
页与页表的取舍
为了提高内存空间利用率,页应该小,但是页小了页表就大了,二者之间应该有所取舍。
页小,那么页表里面要存的页就越多,页表就越大
页表过大带来的问题

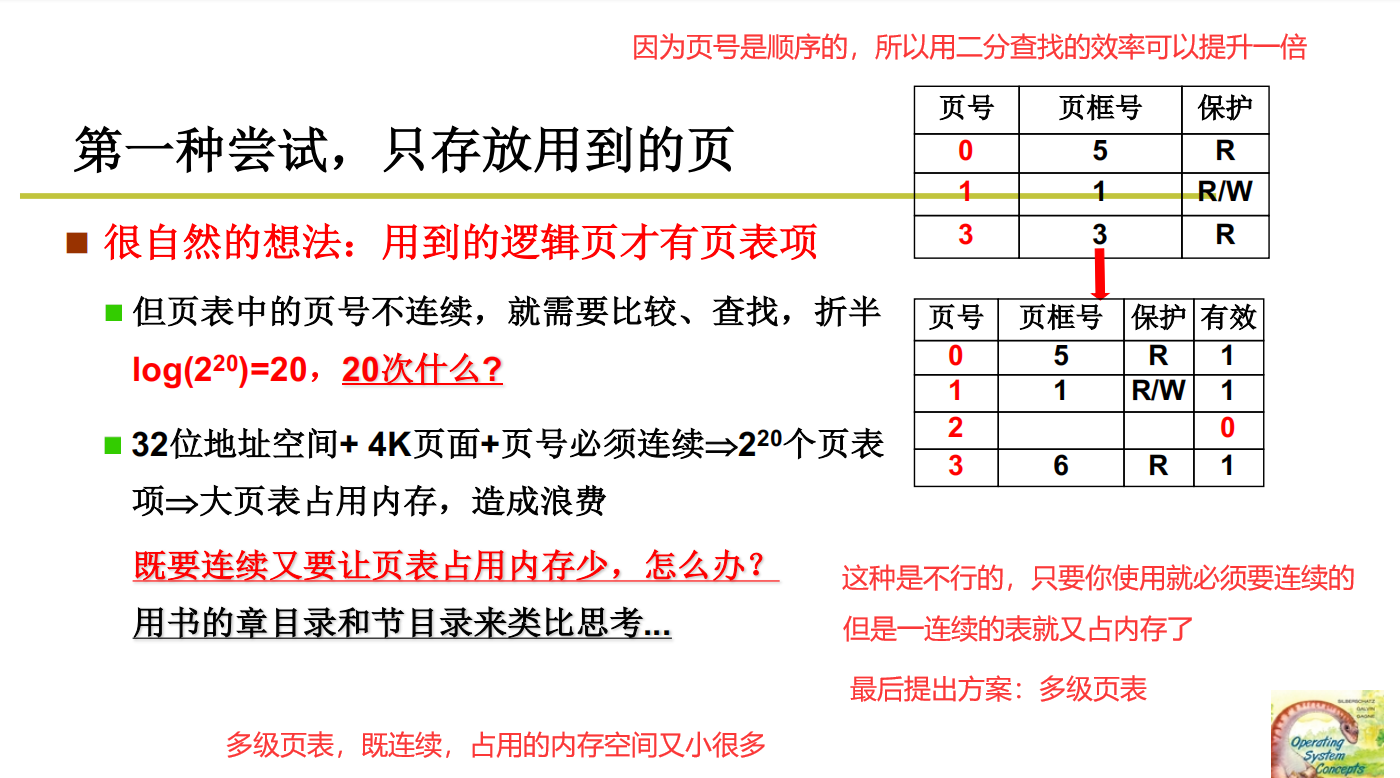
单集页表(行不通)
这种是不行的,无法做到取舍
解决方案就是多级页表
多级页表
第二种尝试:多级页表,即页目录表(章)+页表(节)
多级目录:就比如启动是第一章,系统接口是第二章,多进程管理是第三章等等
不需要一节一节的往下找,每一节每一节的去看,这就代表了不需要的内容就不用放入内存,节约了页表空间以及物理内存。节省了大量的时间。而且还保持了连续。
打个直观的比喻,我想访问第五章的第一节。那么我只需要把前四章的标题地址载入(保持五个章节的连续),再把第五章第一节的内容载入到内存。这样既保持了内存空间上的连续,又保证了不那么耗费空间,因为其他不需要的部分没有被载入而是被跳过了。

TLB快表
TLB的出现就是为了给查询多级页表之前做一层缓存加速
这种思想就是给页表再加一层缓存,因为寄存器的速度是非常非常快的。
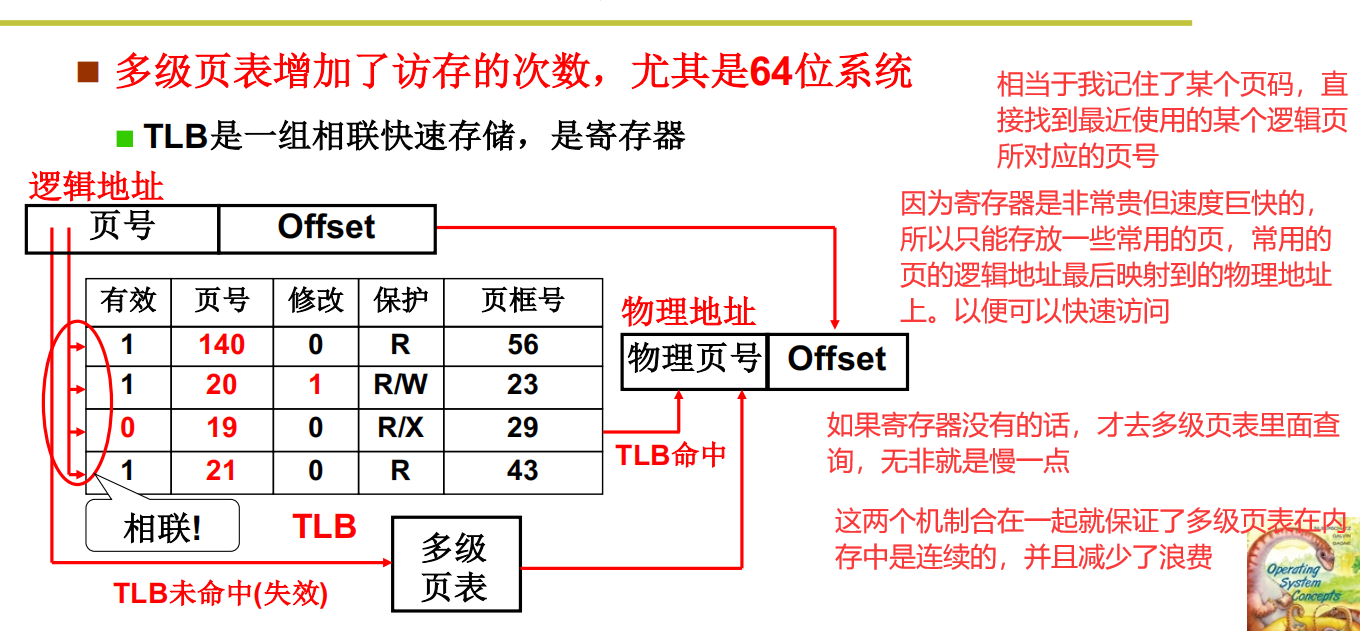

正是这种快表+多级页表的机制,来实现了一个空间高效的分页机制,同时兼顾了时间的快速。
段页结合的实际内存管理
段对于程序来说非常友好,而页对于物理内存来说也是非常友好的。把二者结合起来就是非常高效的使用手段了。
段、页结合: 程序员希望用段,物理内存希望用页
回顾
分段是怎么工作的?

分页是如何工作的?
能不能把二者组合一下?
大概的思路就是这样的
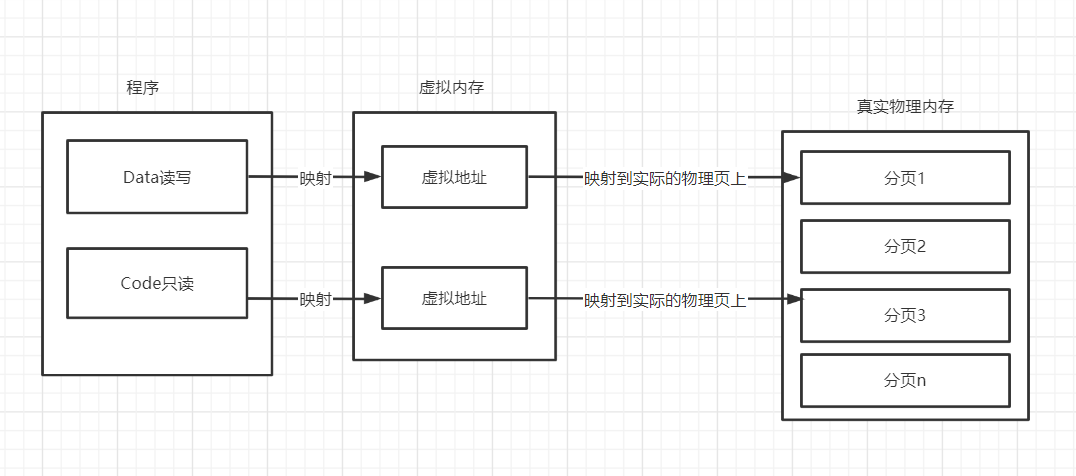
段页结合
现在虚拟内存中分段分配给程序段,再通过映射映射到内存的一页一页中,一个映射映射多个页。

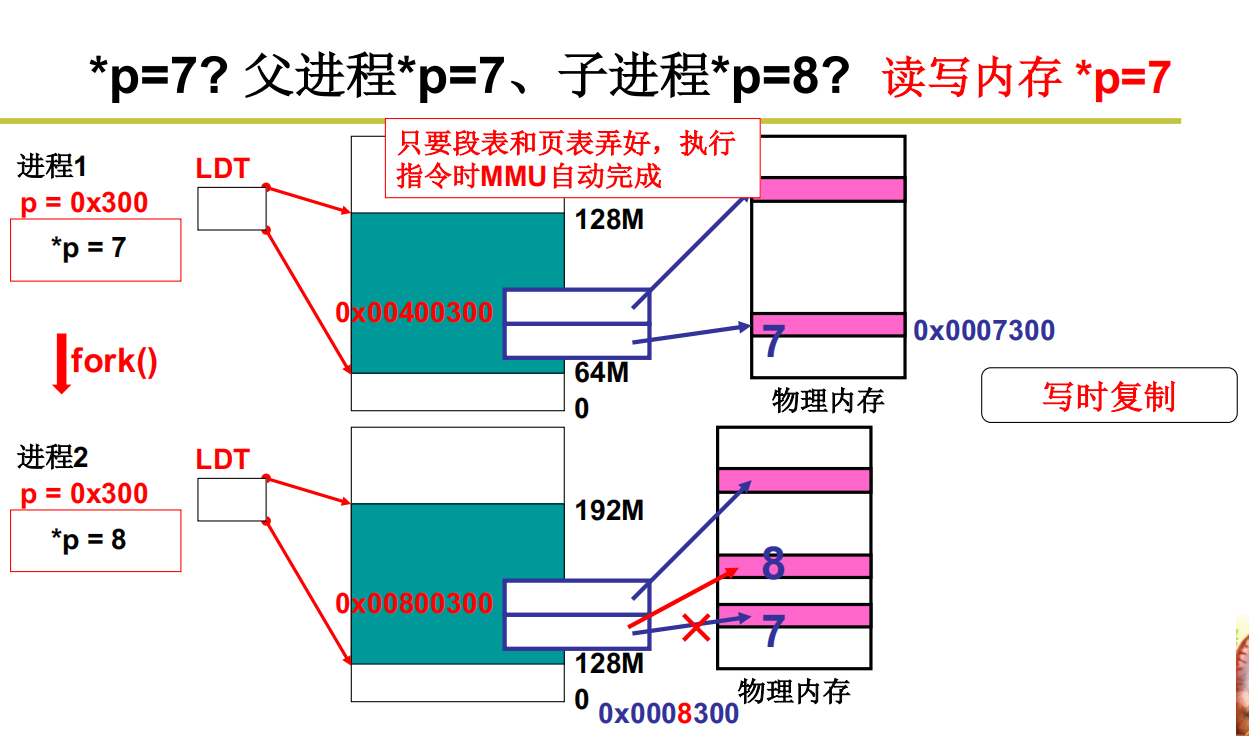
段、页同时存在是的重定位(地址翻译)
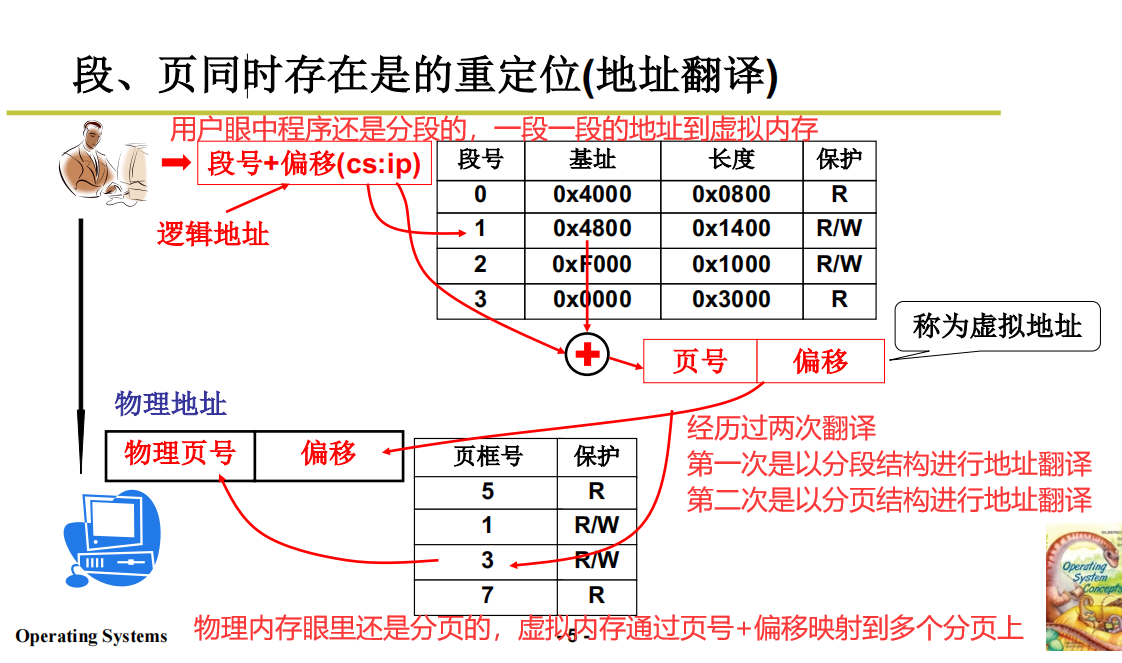
段页结合的流程(源码流程)
注意,那个p->的意思是PCB,把LDT的内容存入PCB
在进程切换的同时进行PCB的切换
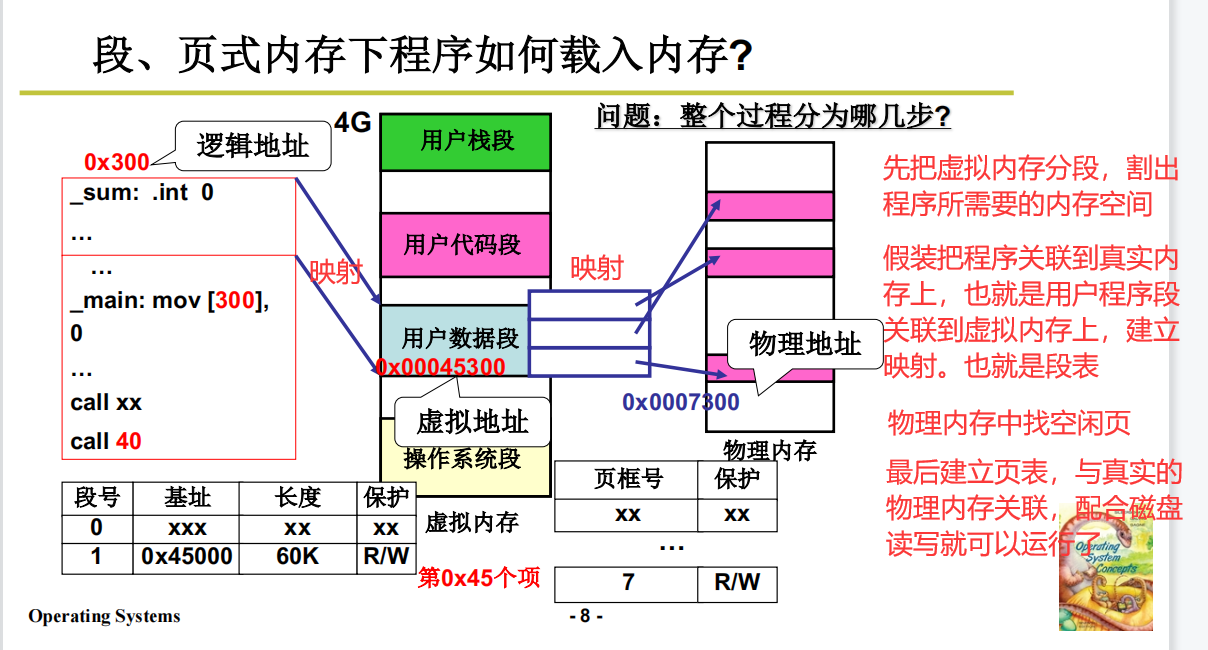
这里分割虚拟内存

虚拟地址示意图
这里是分配虚拟内存,建段表

这里是分配内存,建页表
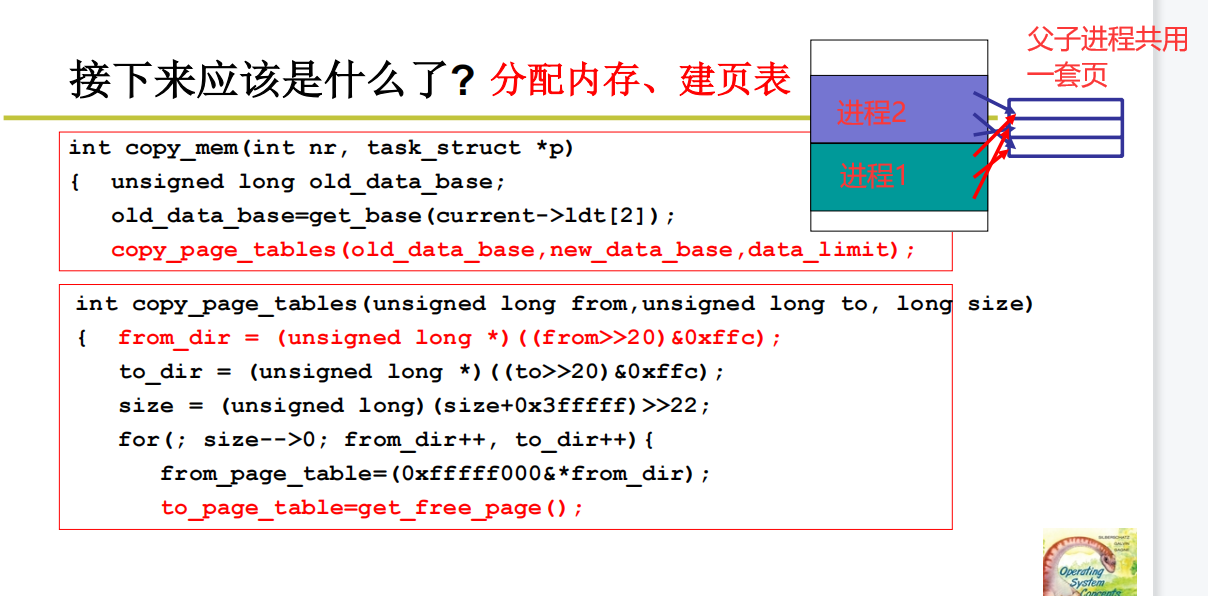
解释相关函数
已经看不懂了
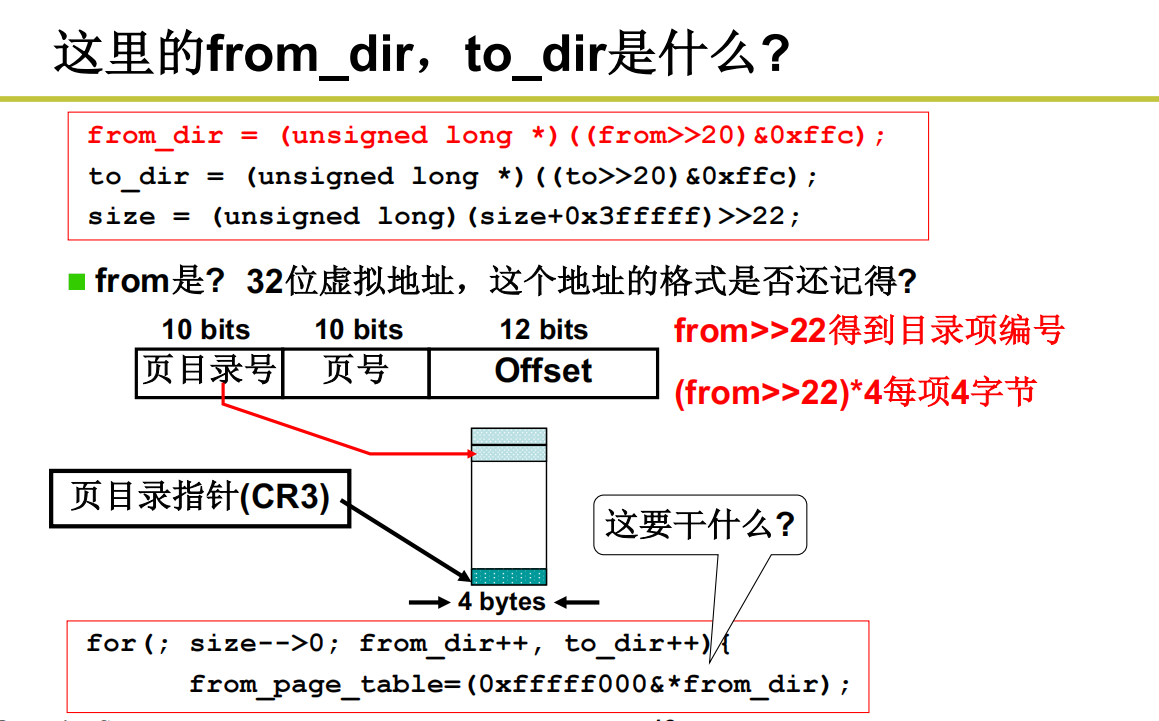
from_dir,to_dir
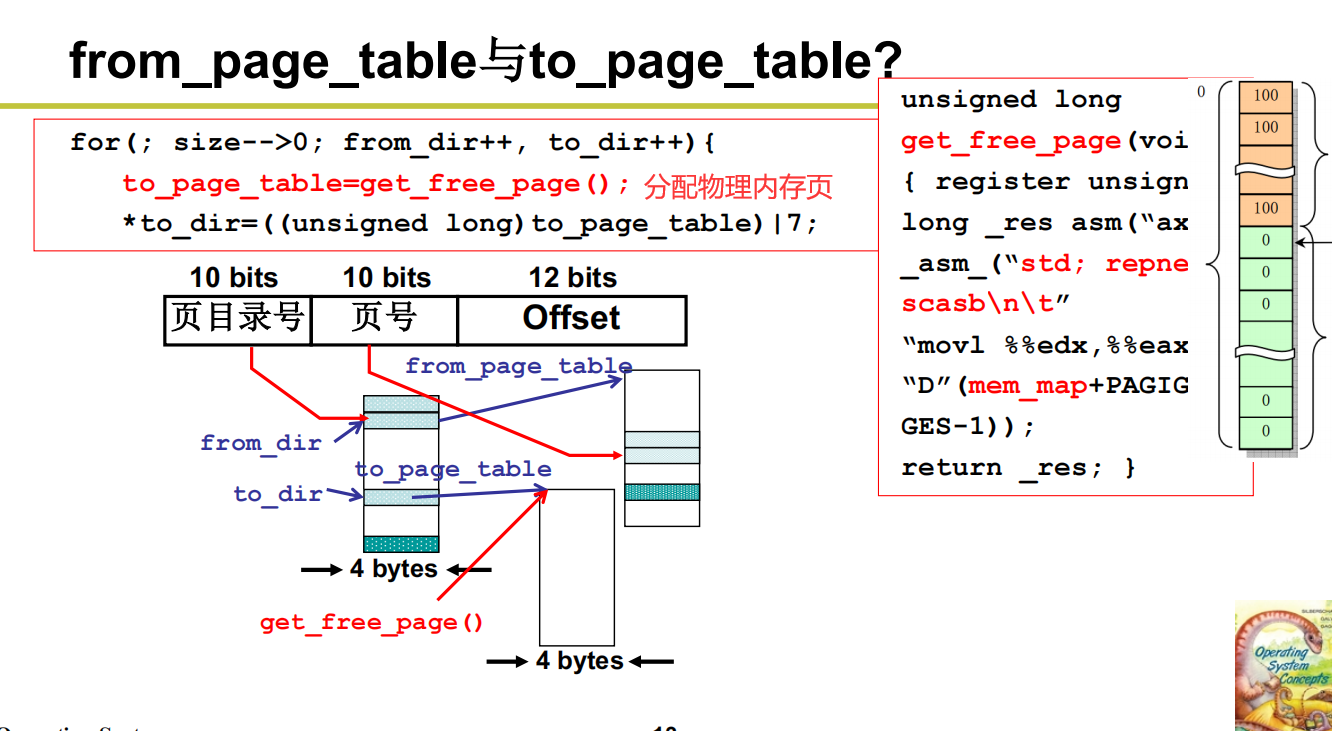
from_page_table与to_page_table
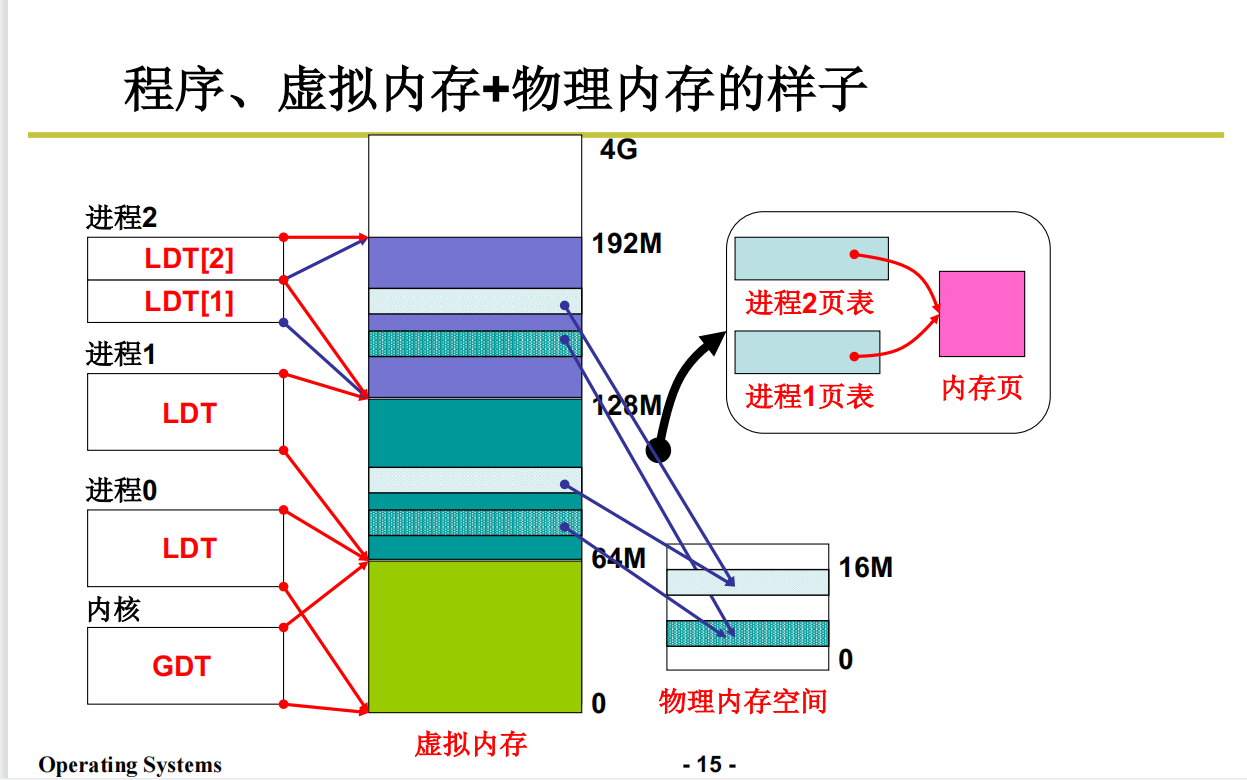
程序、虚拟内存+物理内存的样子
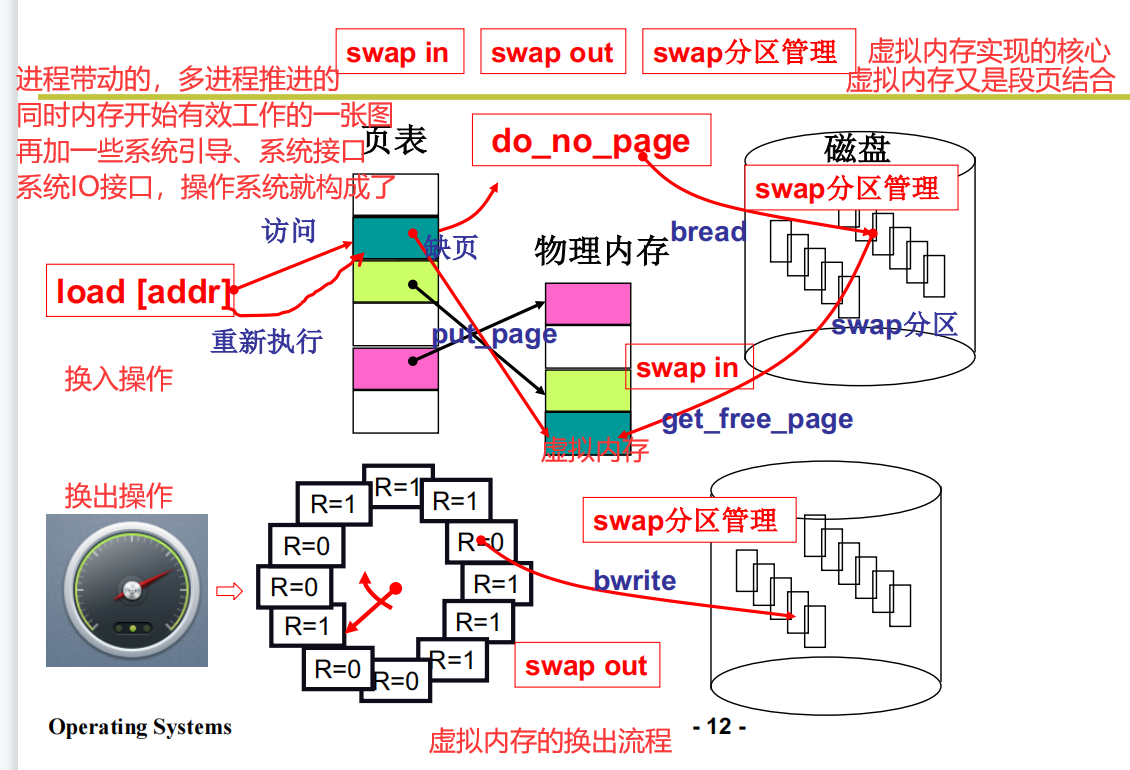
内存的换入(Swap)
从分段开始,到分页提升内存效率。再到利用虚拟内存分段分页合并。进而大幅提升空间时间效率。那么虚拟内存怎么实现?就是虚拟内存。
为了实现虚拟内存,就应该换入换出机制
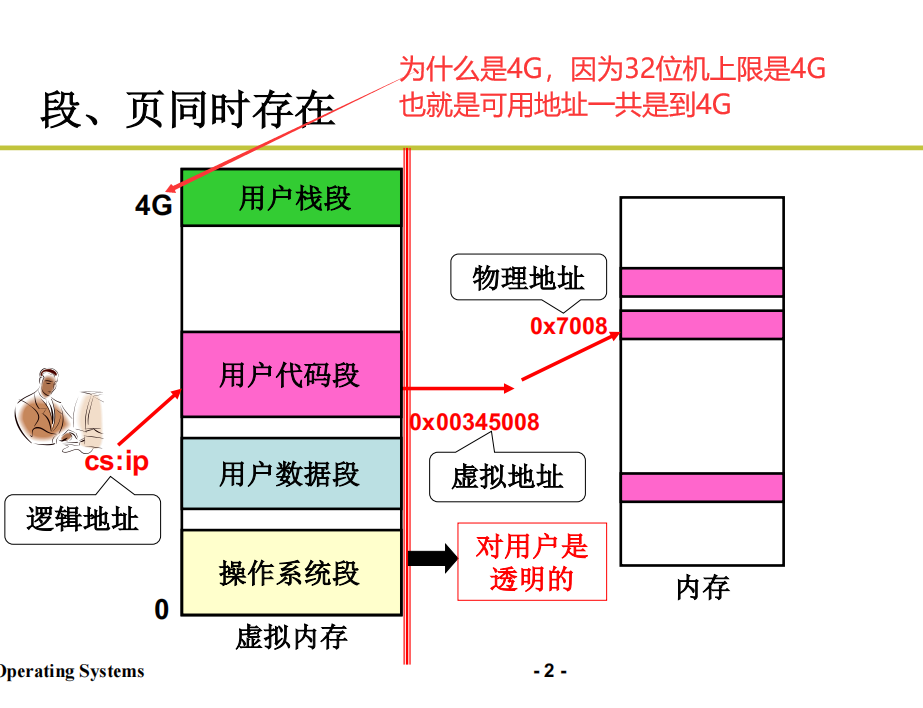
32位系统默认给用户分配的就是4G
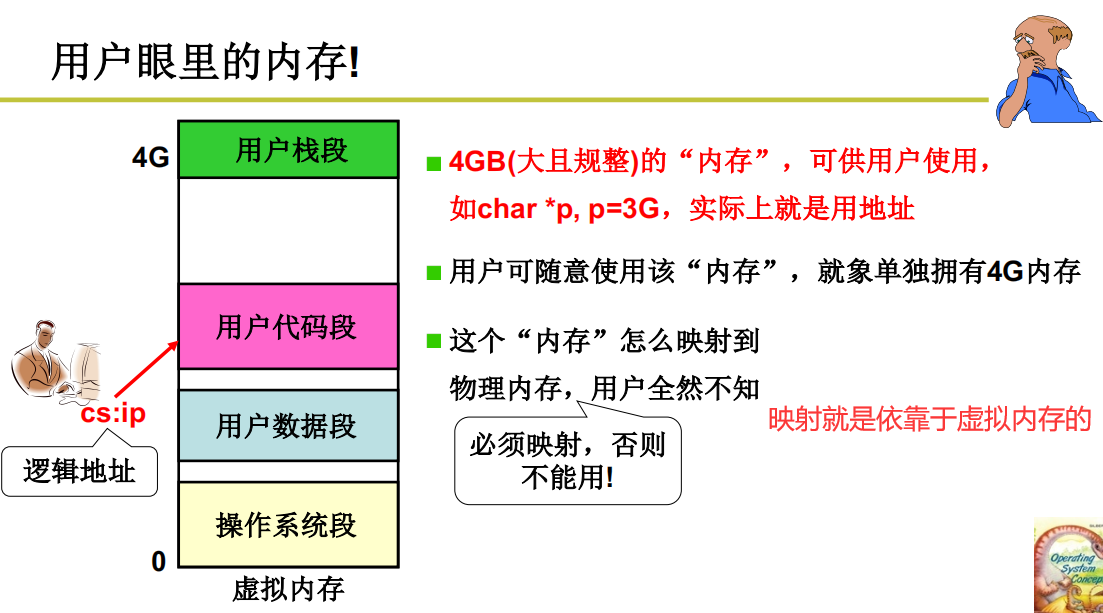
用换入、换出实现“大内存”
请求的时候才会换入操作,并且简历映射
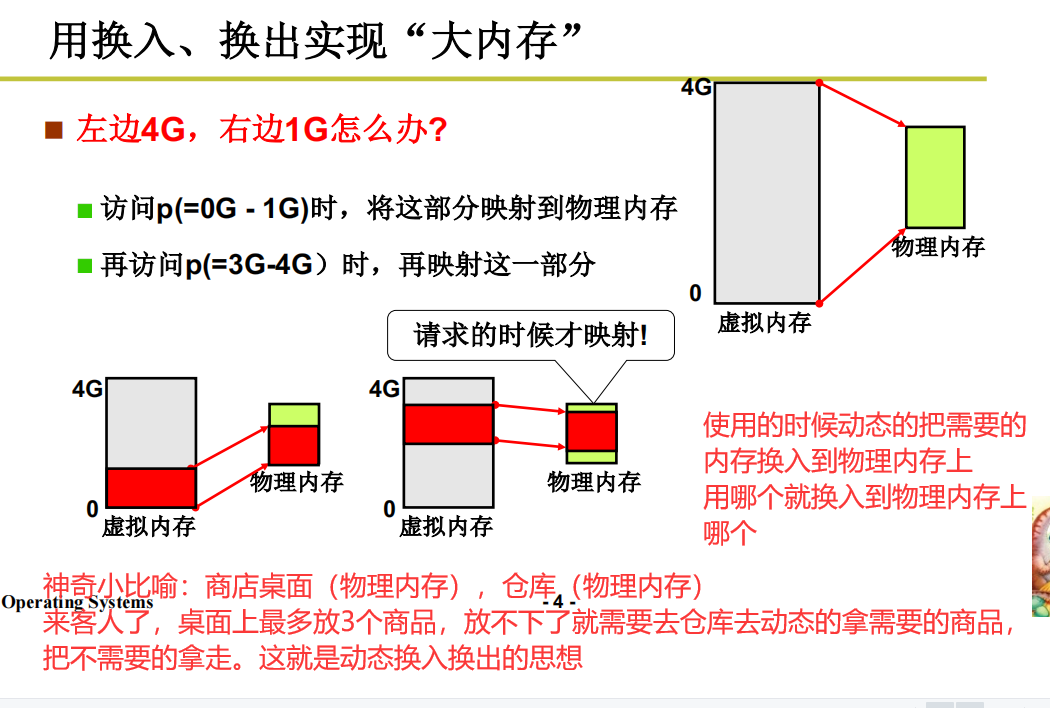
请求调页
为什么请求调页而不是请求调段

解答:因为调页的颗粒度更细,每页都是4k。本着需要什么就调用加载什么的原则就会很快很精准的调用。如果是调段,那么颗粒度无法保证,比如我想调用一个10k的东西,但是这个10k的东西在10m的段内,段本身无法再分割,只能载入10m的内容,就无法保证效率
请求调页的实现过程
从开始中断请求开始
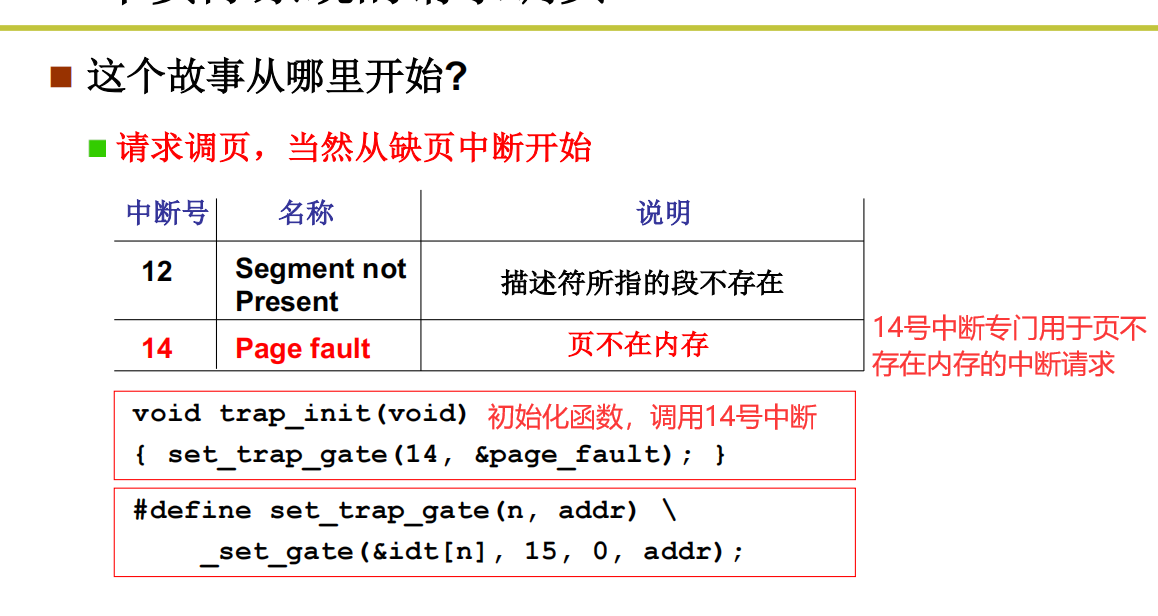
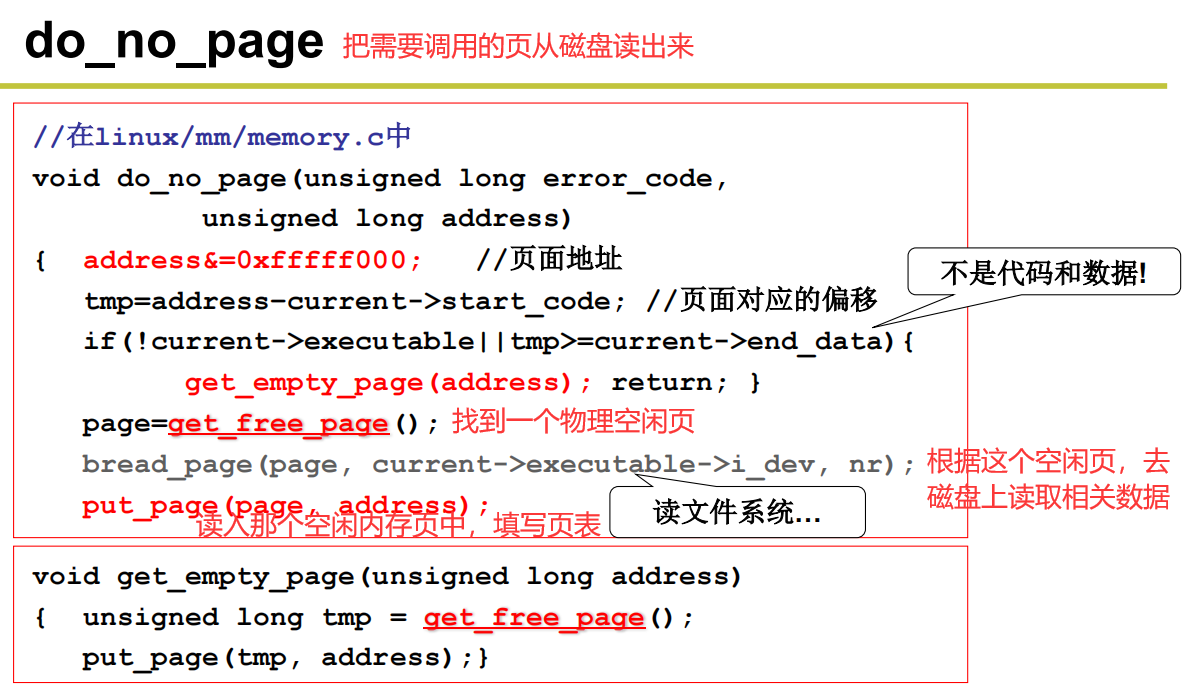
处理缺页中断

收到调用的请求,对缺的页进行处理,去磁盘读取,读取好了再载入内存

内存换出(Swap Out)
有换入,就应该有换出!
换出也是为了实现虚拟内存的。之前说有换入,那么满了怎么办,就得把内存进行换出。
选哪一页进行换出,这种算法就是这一节的重点。

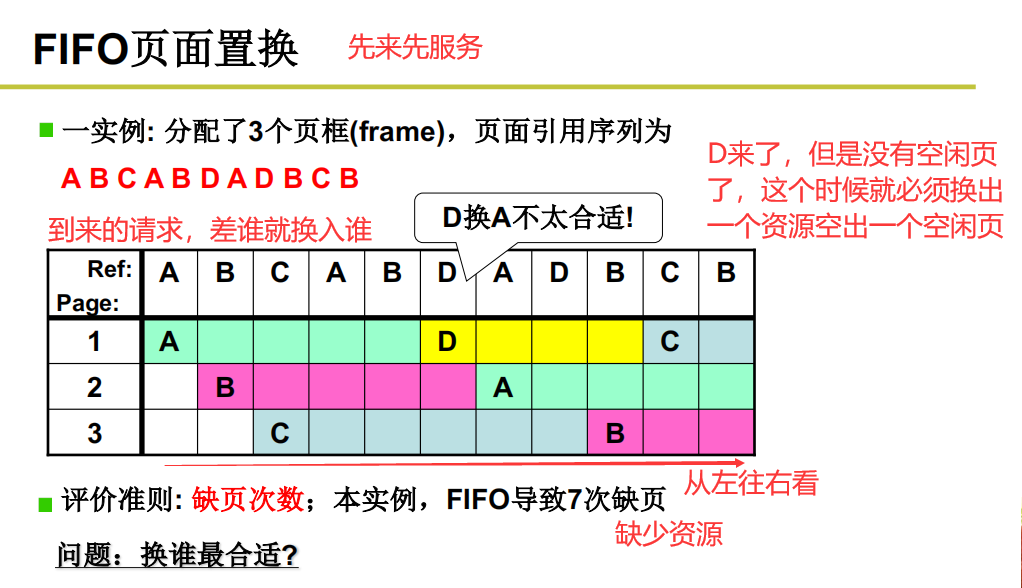
FIFO页面置换
这种算法是把内存中最早换入的缓存给换掉
这种算法不是很明智的,就好像商店总摆一些冷门商品,每次来客人了总要去仓库现找。就不是很好。
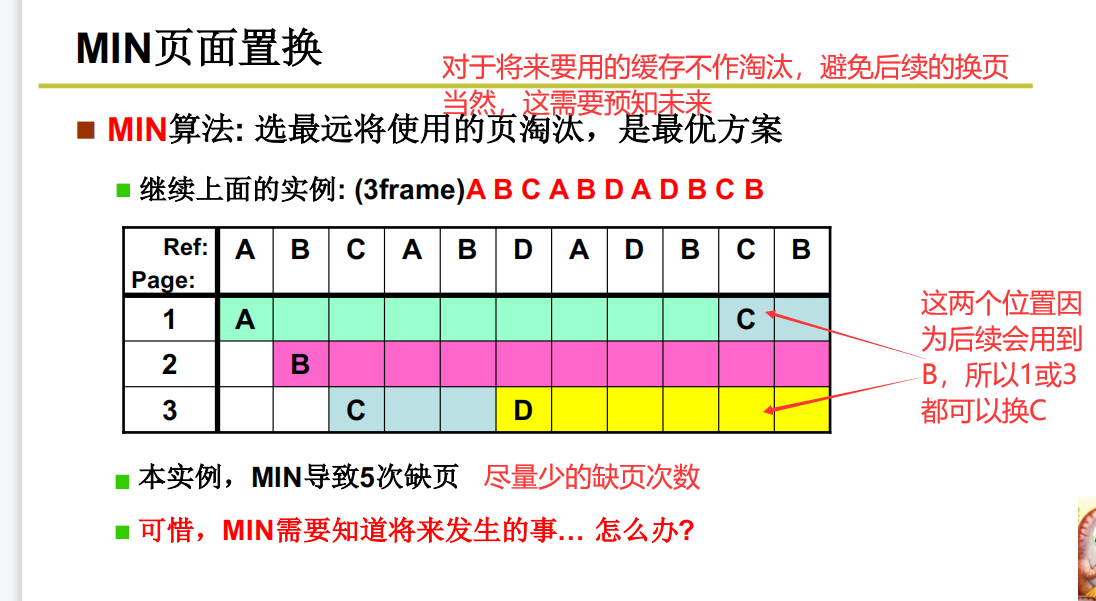
MIN页面置换(最优,但无法实现)
这个算法最优,但是需要预知未来要进行调页的应用,这显然是不可能的,所以只有理论,不太现实。
LRU页面置换
LRU算法(Least Recently Used 最近最少使用)就是利用过去来预知未来。把最近用的最少使用的页淘汰掉就完事了。达到上面MIN算法的一种近似。
依据就是程序对于内存使用的局限性,会反复使用一段内存。预测未来一段时间这个内存也会使用这段内存里的资源,调页也在这段内存中实现
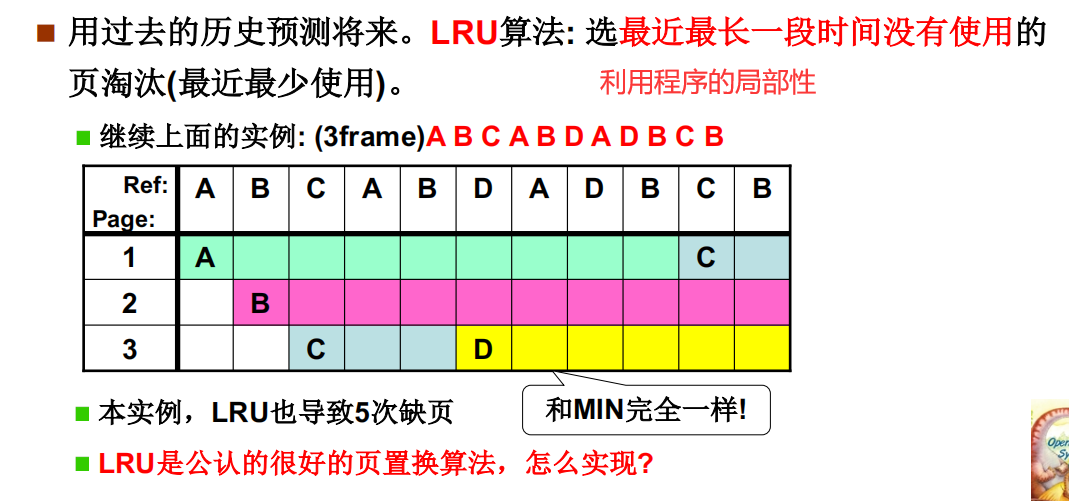
LRU的实现的思路
时间戳实现(不可行)
维护时间戳每次都要访问内存,代价太大。不推荐
这玩意写写Demo,维护个一两个进程还可以玩玩,一旦放入操作系统里跑,成千上万的进程一起用这个算法维护一定会崩掉。
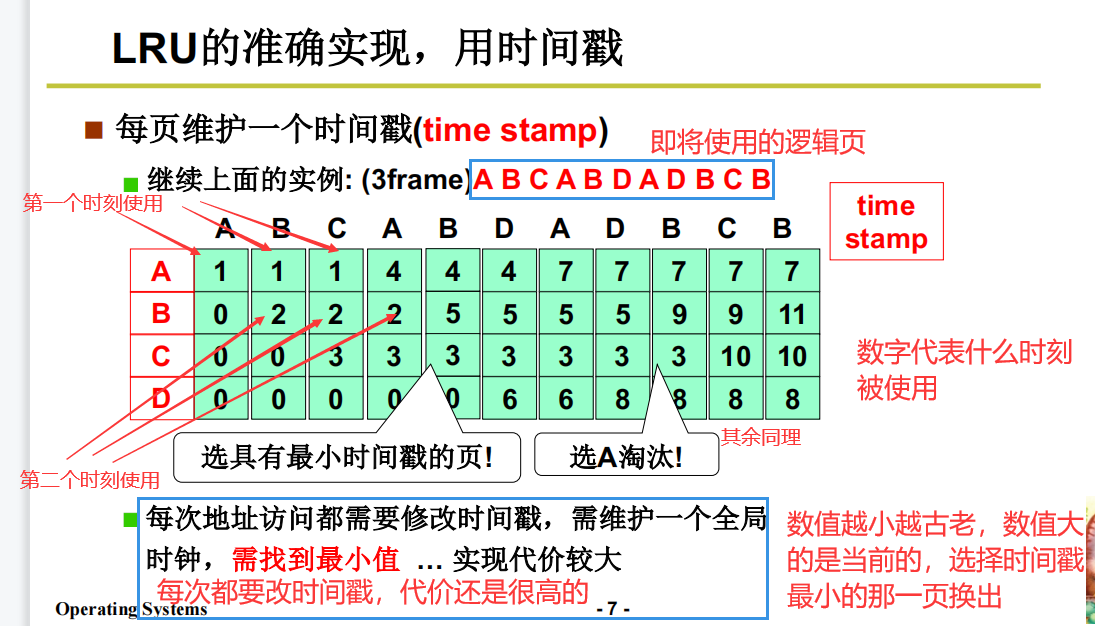
页码栈实现(代价较大)
这玩意写写Demo,维护个一两个进程还可以玩玩,一旦放入操作系统里跑,成千上万的进程一起用这个算法维护一定会崩掉。

LRU近似实现 - 将时间计数变为是和否
也叫Clock算法
这个0和1是由MMU来进行实现。是硬件级别的,只要访问就可以进行更改,不再需要维护一个复杂的数据结构。
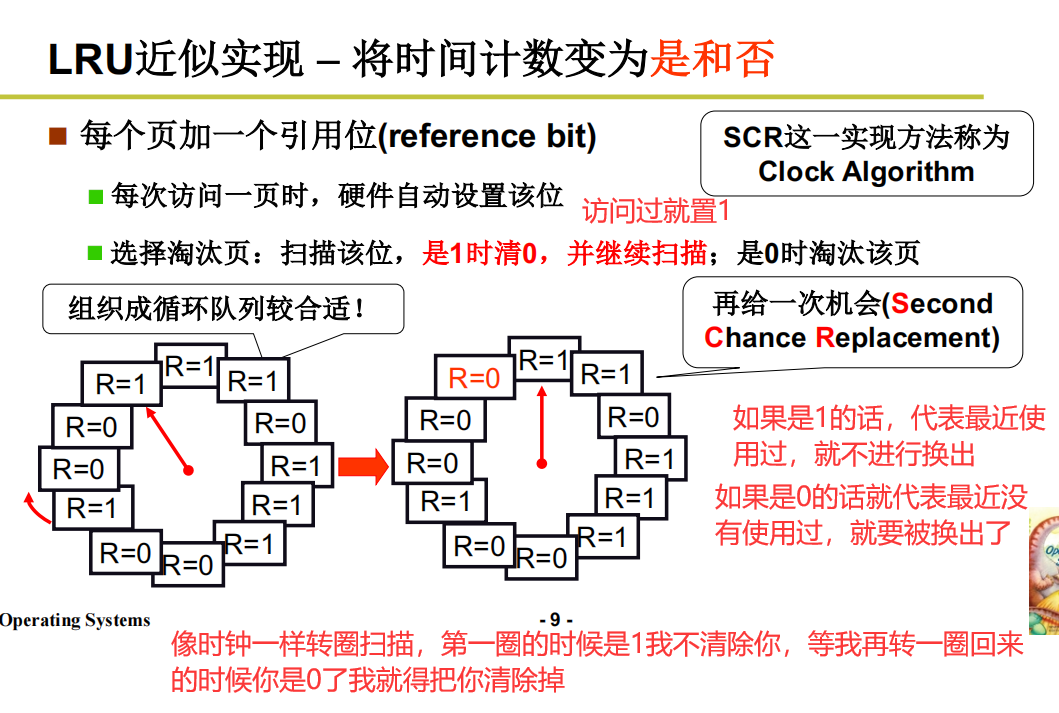
针对Clock算法的改进(操作系统可实现)
这个算法就可以放在操作系统里工作了。比较有实际意义

附带问题
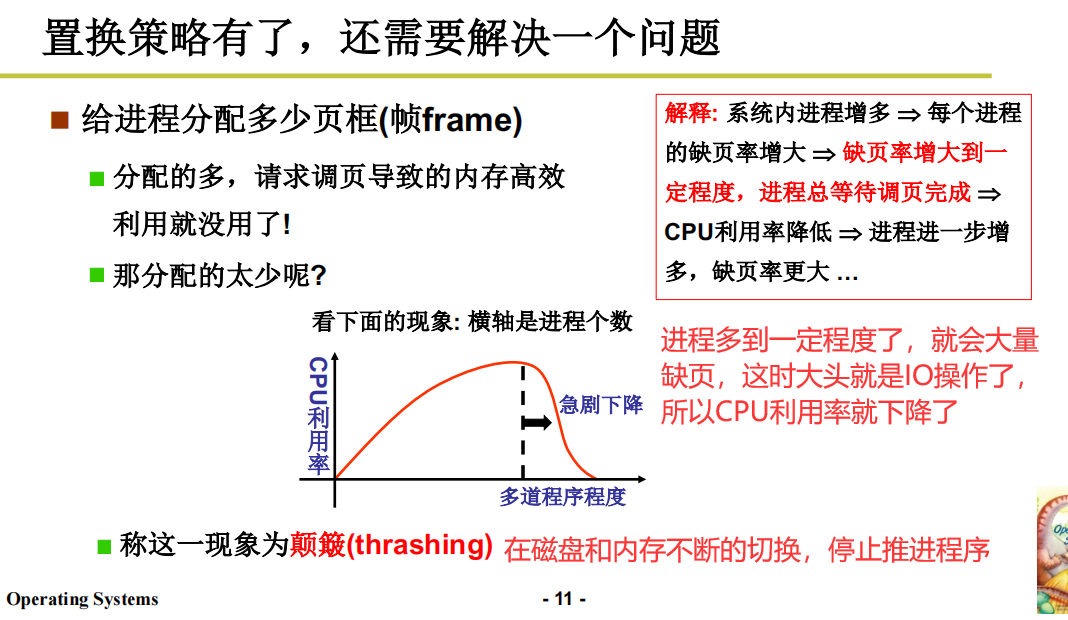
总结
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









