









一、相关库:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split#用来随机划分样本数据为训练集和测试集
from sklearn.metrics import classification_report#主要分类指标报告
LogisticRegression和LogisticRegressionCV的主要区别是LogisticRegressionCV使用了交叉验证来选择正则化系数C。而LogisticRegression需要自己每次指定一个正则化系数。
二、函数:
1、train_test_split():
train_X,test_X,train_y,test_y =
train_test_split(train_data,train_target,test_size=0.2,random_state=0)
#train_data:待划分样本数据,即X
#train_target:待划分样本数据的结果,即y(标签)
#test_size:测试数据占样本数据的比例,如0.2表示训练集:测试集=8:2;如果是整数就是测试集样本数量
#random_state:设置随机数种子,保证每次都是同一个随机数;若为0或不填,则每次得到数据都不一样
2、LogisticRegression():
# 使用 lr 类,初始化模型
clf = LogisticRegression(
penalty="l2", C=1.0, random_state=None, solver="liblinear", max_iter=4000,
multi_class='ovr')
| Logistics Regression参数名称 | 含义 |
|---|---|
| penalty | 正则化类型,L1或L2,默认L2 |
| C | 正则化系数λ的倒数,默认1.0 |
| random_state | 设置随机数种子,默认无 |
| solver | 选择优化算法,只有五个可选参数,即newton-cg,lbfgs,liblinear,sag,saga,默认为liblinear |
| max_iter | 算法收敛的最大迭代次数,默认100 |
| multi_class | 选择分类方式,可选参数为ovr和multinomial,默认为ovr,两者区别主要在多元逻辑回归上 |
| class_weight | 指定分类的权重,参数支持的类型有字典或 ‘balanced’,默认值为 None;如果不指定该参数,表示对所有样本都有相同的权重;如果为’balanced’,样本权重会根据分类样本比例进行自适应 |
3、fit():
#使用训练数据来学习(拟合),不需要返回值,训练的结果都在对象内部变量中
clf.fit(X_train, y_train)
4、模型(w0+w1 *x1+…+wn *xn)的属性:
clf.intercept_:w0
clf.coef_:w1-wn
5、score():
#用训练好的模型在测试集上进行评分(0~1)1代表最好
print(clf.score(X_test,y_test))
6、classification_report():
y_pred = clf.predict(X_test)#使用测试集数据来预测,返回值为预测分类数据
target_names=['class 0','class 1']#指定标签名称,默认无
print(classification_report(y_test, y_pred,target_names=target_names,sample_weight=None))
#y_test:真实数据的分类标签
#y_pred:模型预测的分类标签
#sample_weight:不同数据点在评估结果中所占的权重
示例:
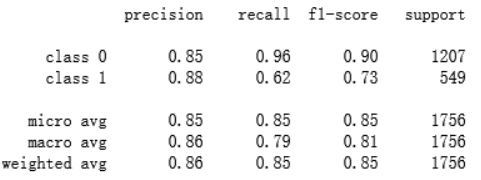
precision:正确预测为正的,占全部预测为正的比例,即TP / (TP+FP)
recall:正确预测为正的,占全部真实为正的比例,TP / (TP+FN)
F1-score:2 * precision*recall / (precision+recall)(前两者的调和平均数)
micro avg:分类正确的样本数与分类所有样本数的比值
示例中 micro avg =(0.96 * 1207 + 0.62 * 549)/(1207 + 549) =0.85
macro avg:所有类的算术平均值
示例中 macro avg = 1/2 *(0.90+0.73)=0.81
weighted avg:所有标签结果的加权平均值















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









