







Redis7分布式缓存之高阶
- 一. Redis单线程 VS 多线程(入门篇)
- 二. Bigkey
- 三、缓存双写一致性之更新策略探讨
- 四. Redis与MySQL数据双写一致性工程落地案例
- 五. 案例落地实战bitmap/hyperloglog/GEO
一. Redis单线程 VS 多线程(入门篇)
1.Redis为什么选择单线程?
① 是什么
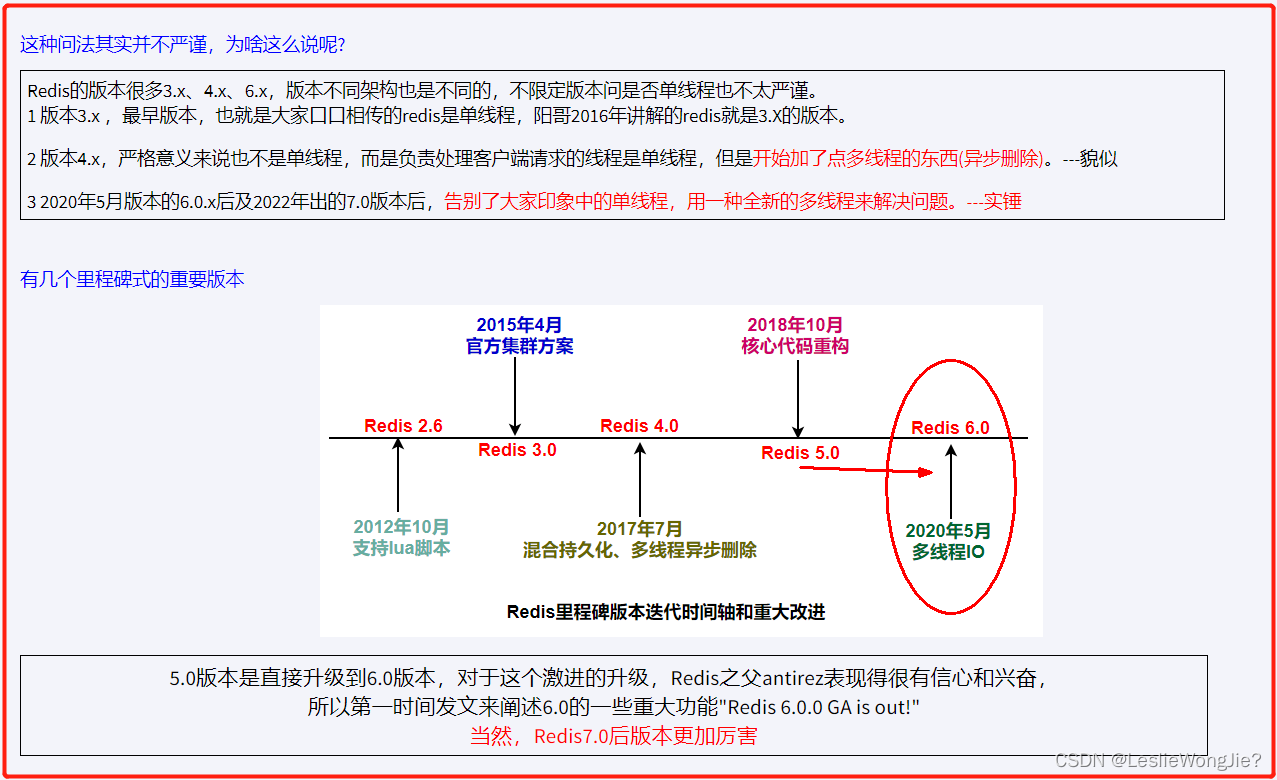
② 厘清一个事实我们通常说Redis是单线程究竟何意?
③ Redis3.x单线程时代但性能依旧很快的主要原因

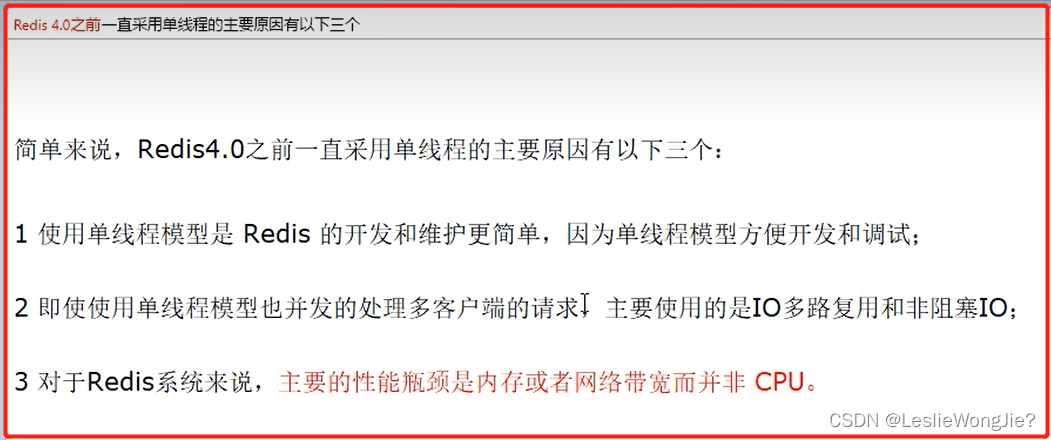
④Redis 4.0之前一直采用单线程的主要原因有以下三个
2. 既然单线程这么好,为什么逐渐又加入了多线程特性?
① 单线程也有单线程的苦恼
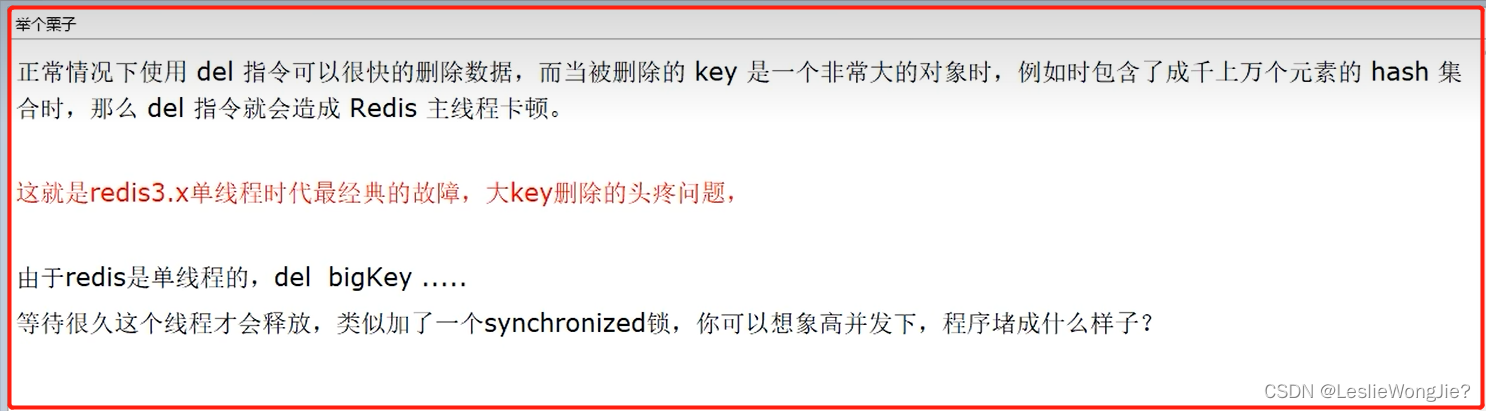
② 如何解决

案例
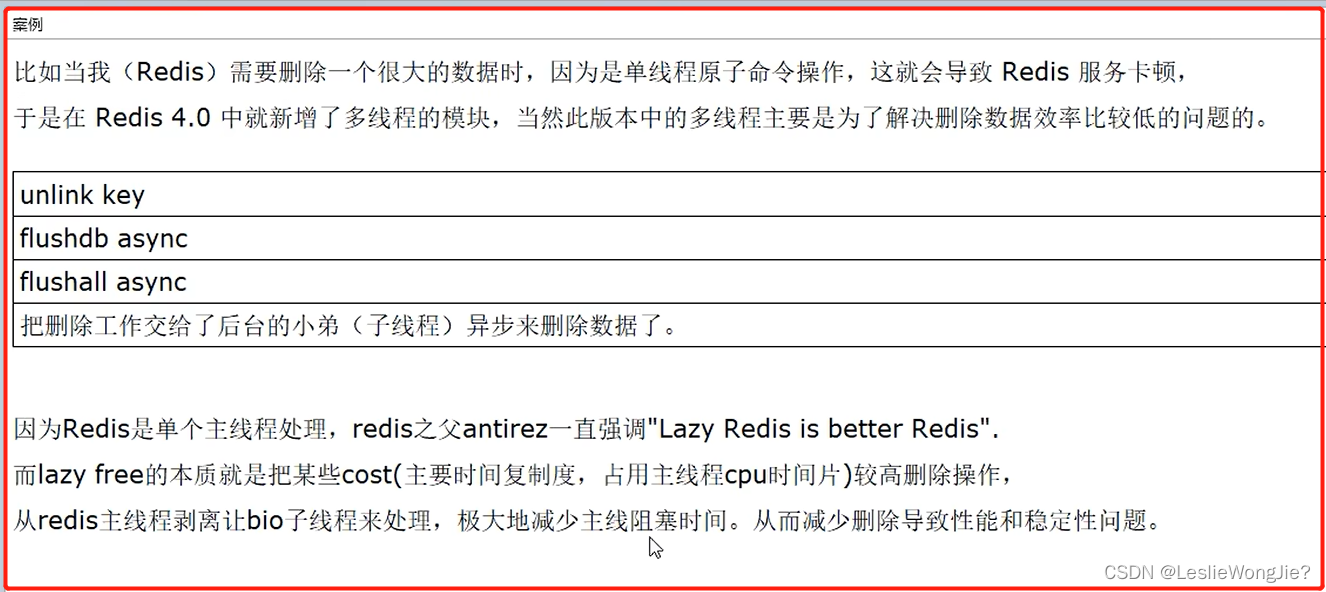
3. redis6/7的多线程特性和IO多路复用入门篇
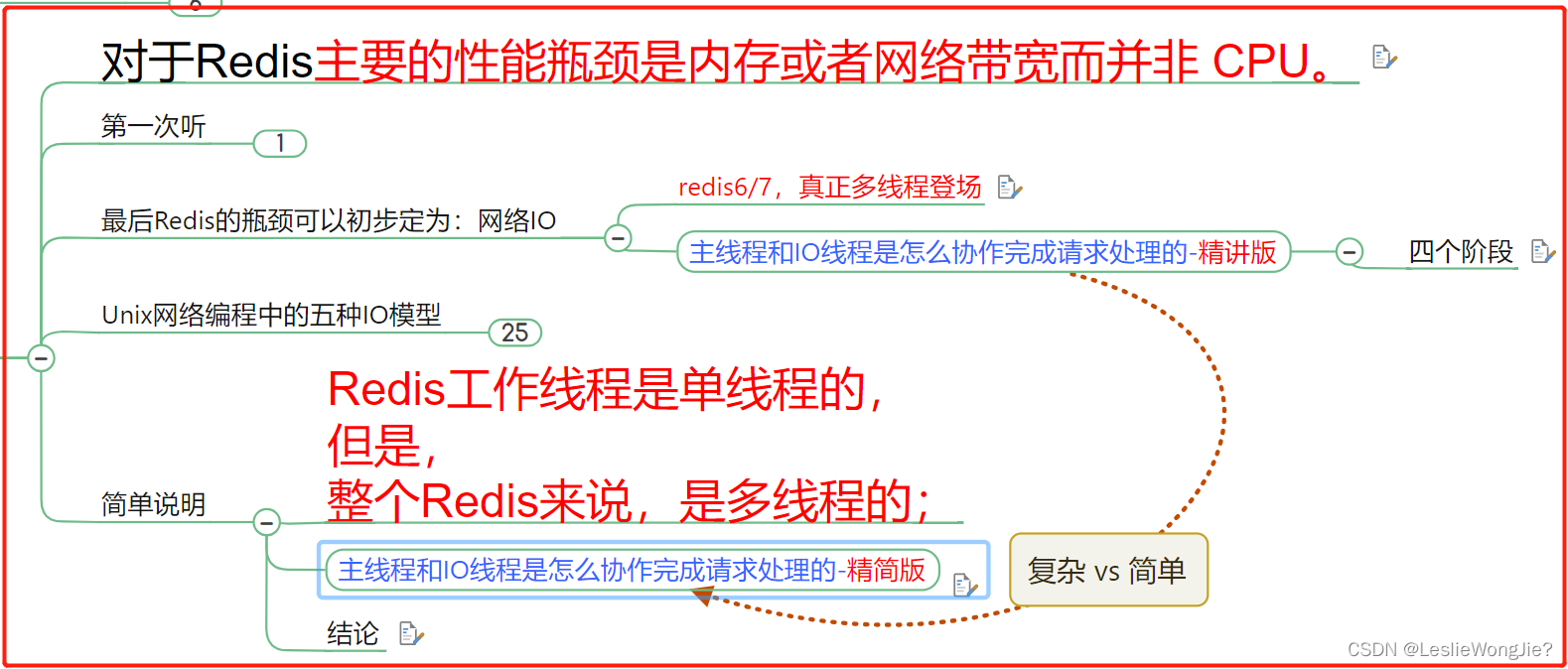
① 对于Redis主要的性能瓶颈是内存或者网络带宽而并非 CPU。
② 最后Redis的瓶颈可以初步定为: 网络IO
Ⅰ redis6/7,真正多线程登场

Ⅱ 主线程和IO线程是怎么协作完成请求处理的-精讲版

4. Jnix网终编程中的五种IO模型
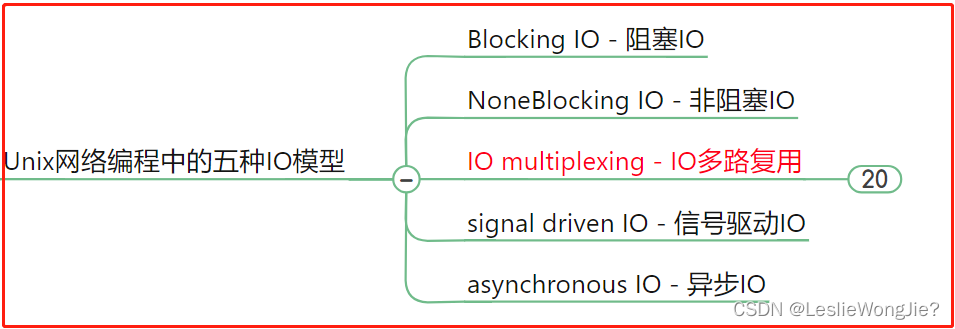
① lO multiplexing - lO多路复用
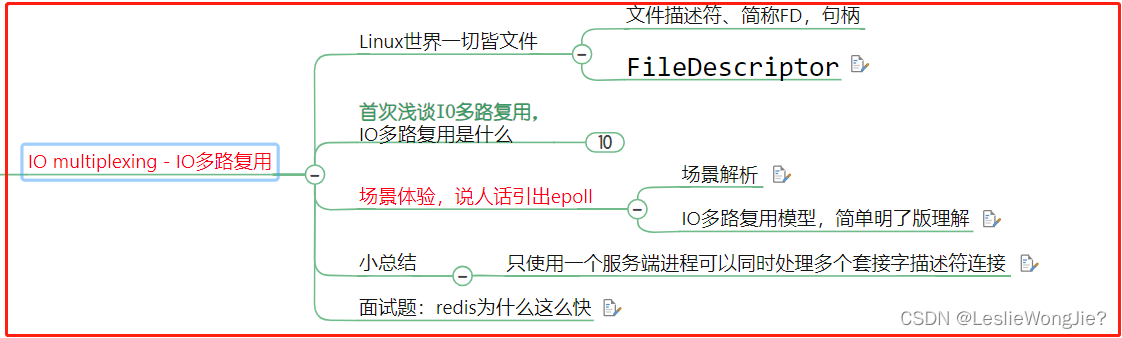
Ⅰ FileDescriptor
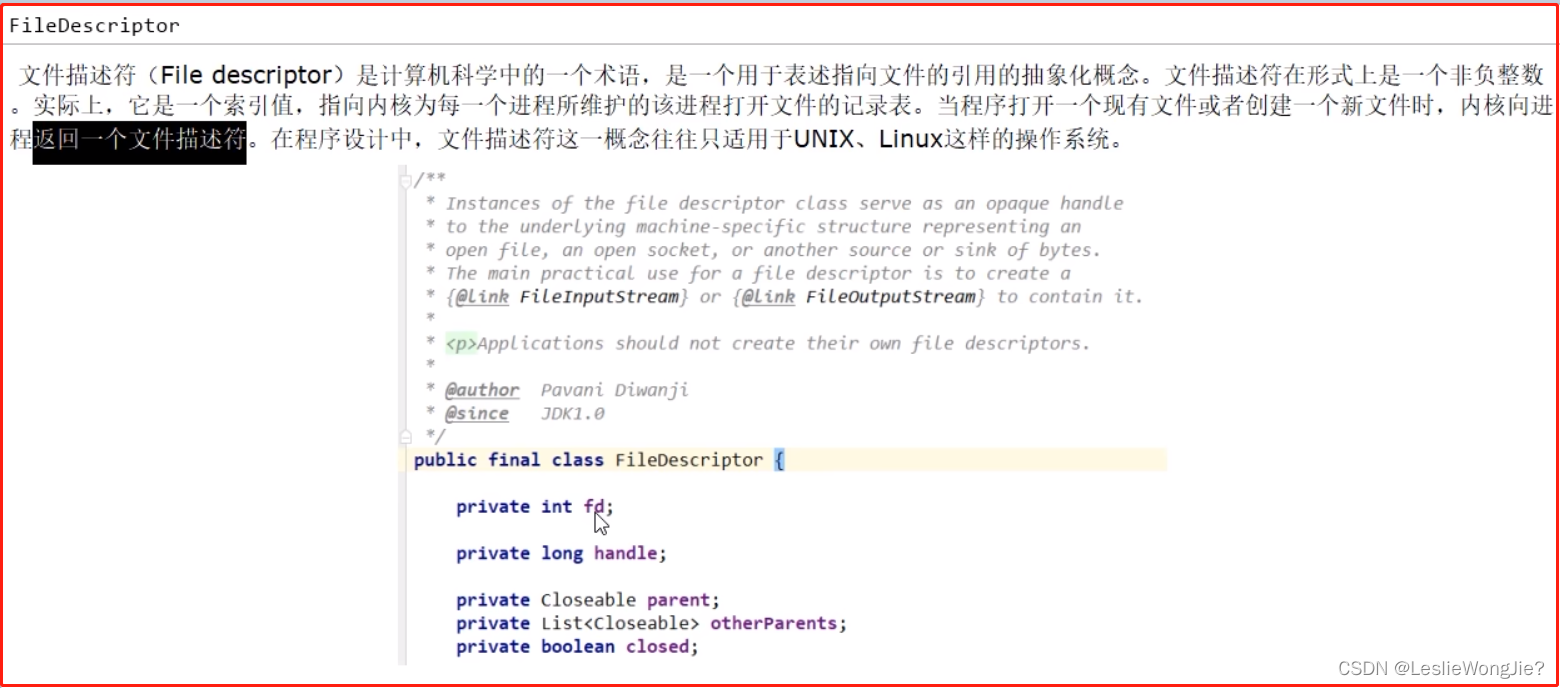
Ⅱ 首次浅谈I0多路复用l0多路复用是什么

Ⅲ 场景体验,说人话引出epoll

场景解析
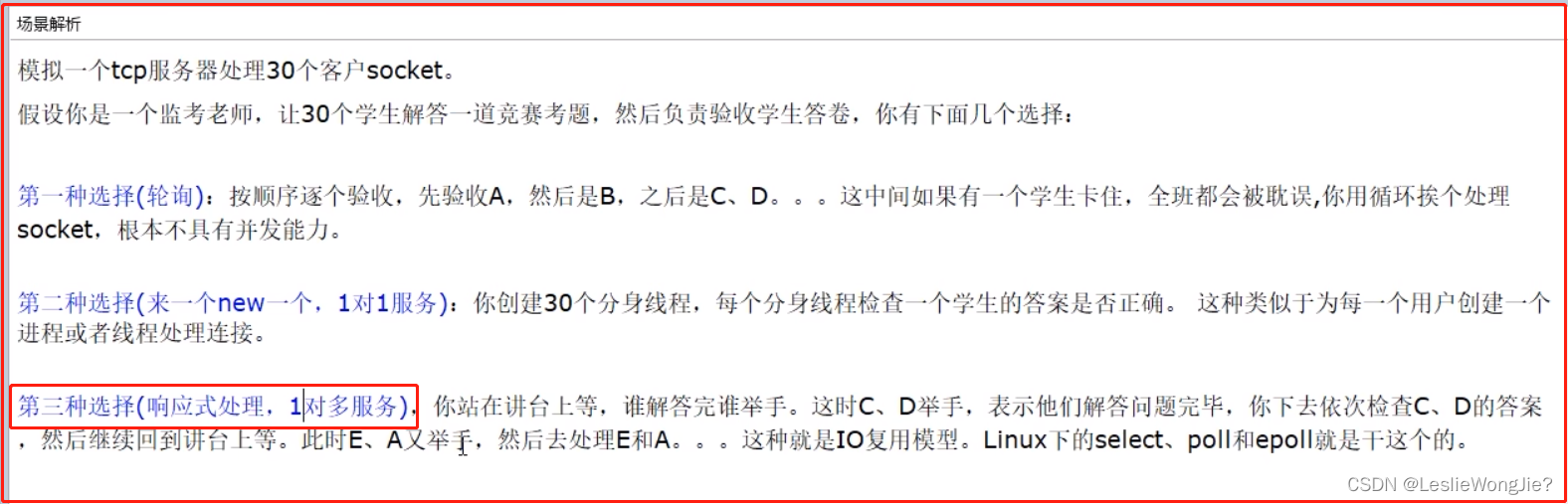
IO多路复用模型,简单明了版理解

Ⅳ 小总结


Ⅴ redis为什么这么快
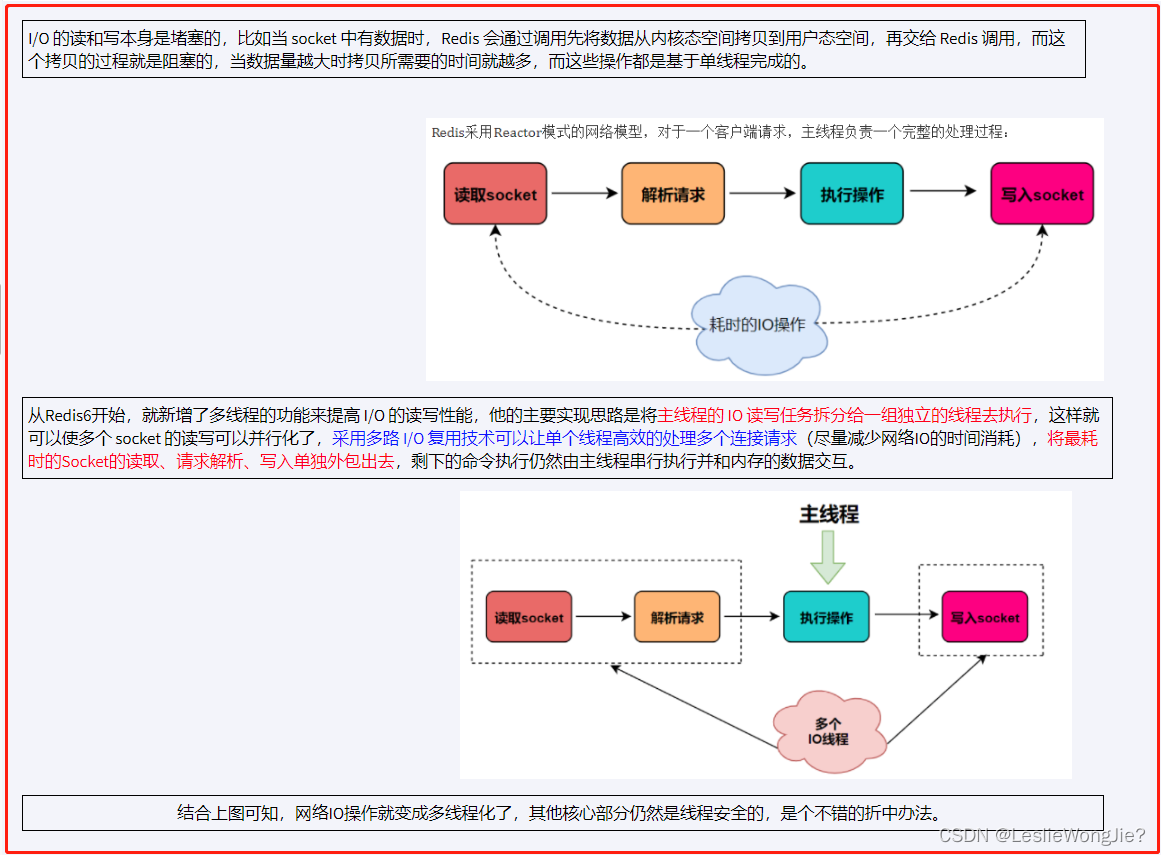
5. 简单说明:Redis工作线程是单线程的;但是,整个Redis来说,是多线程的
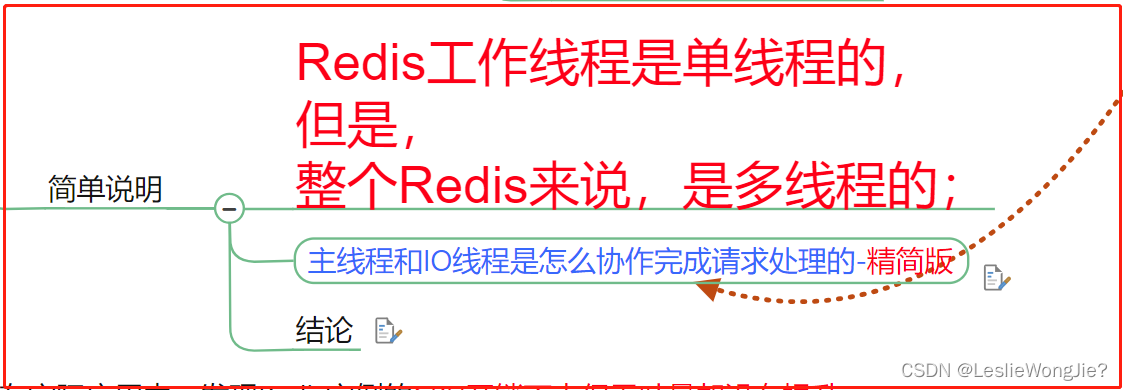
① 主线程和IO线程是怎么协作完成请求处理的-精简版
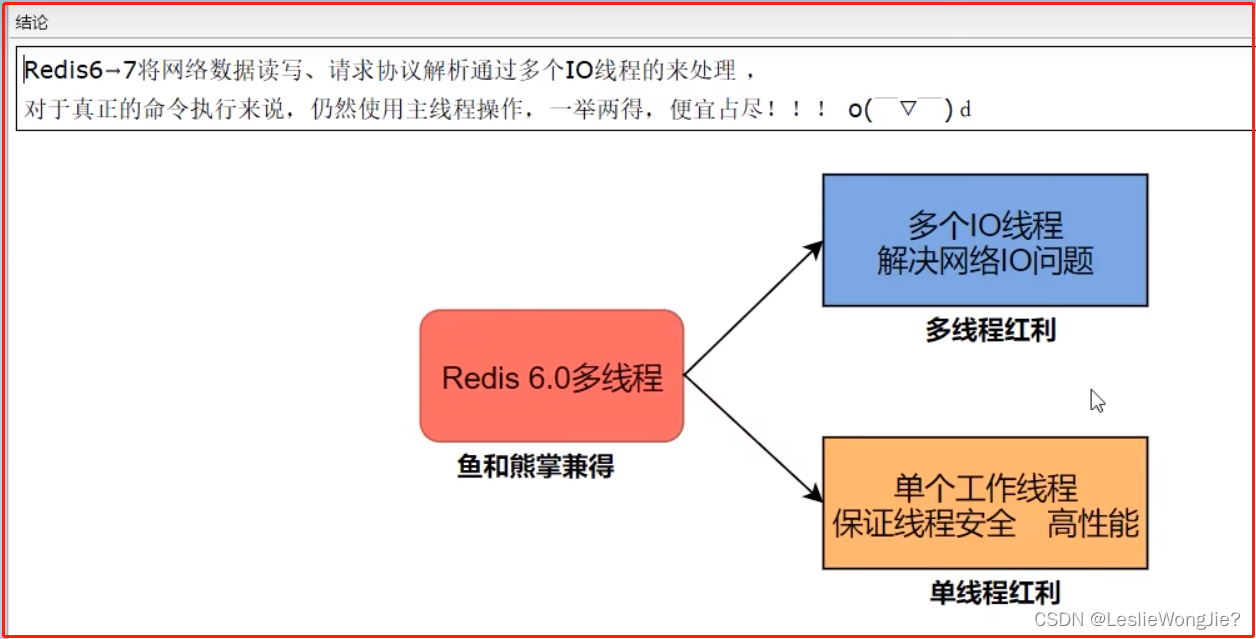
② 结论
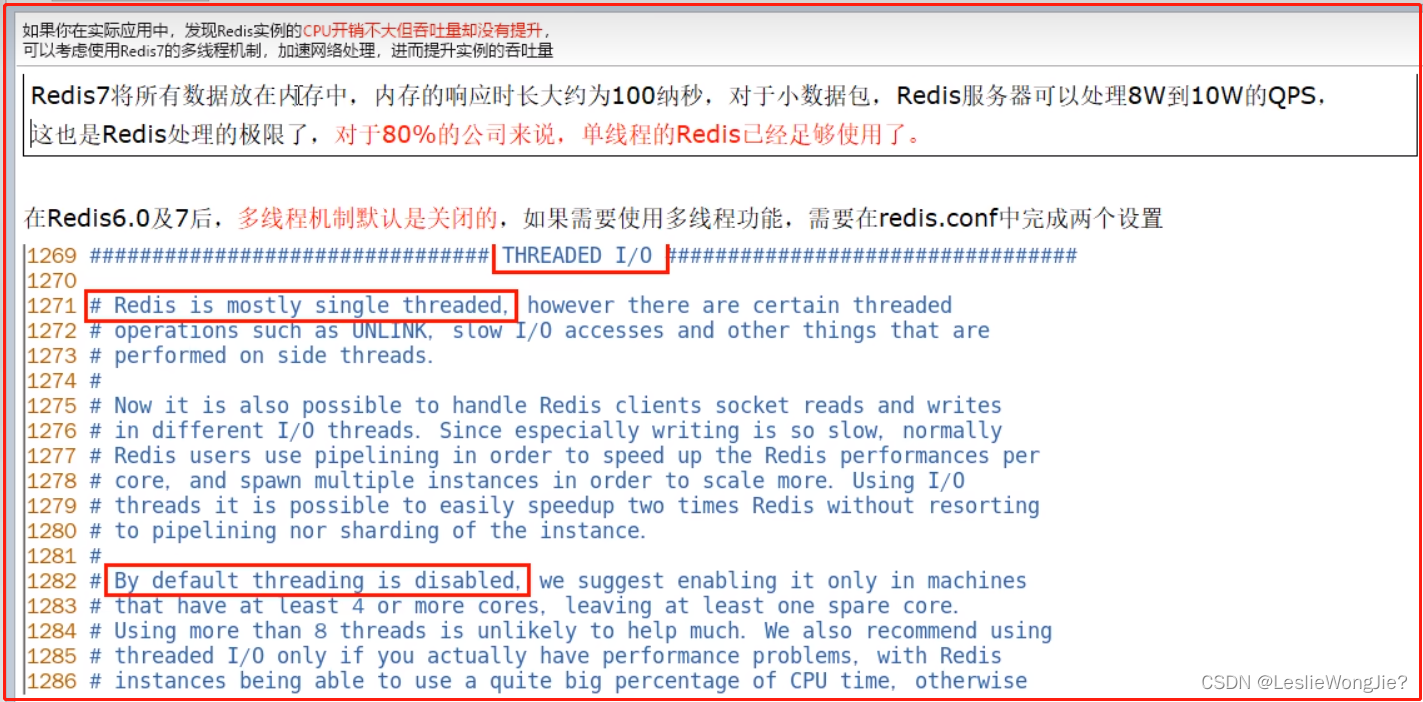
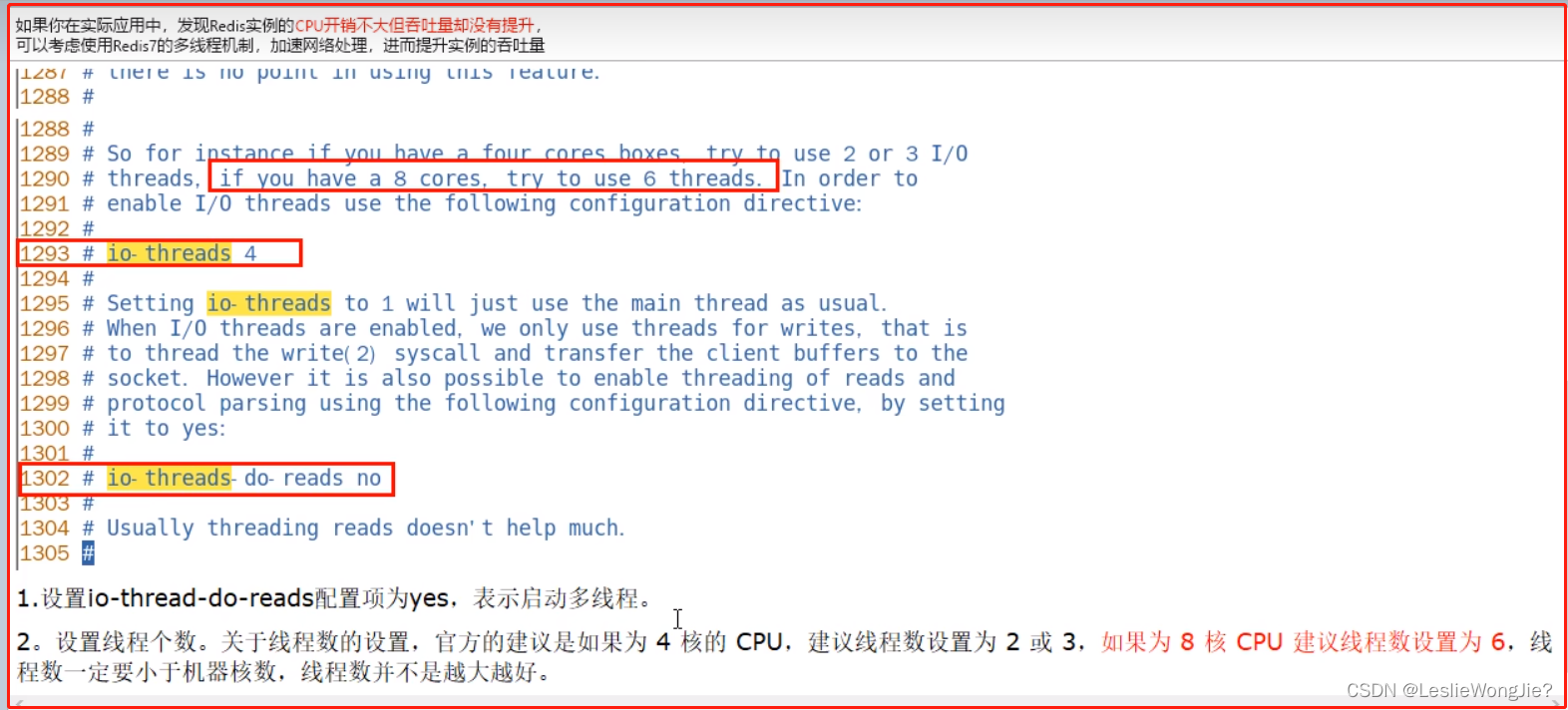
6. Redis7默认是否开启了多线程?

二. Bigkey

1. Morekey案例
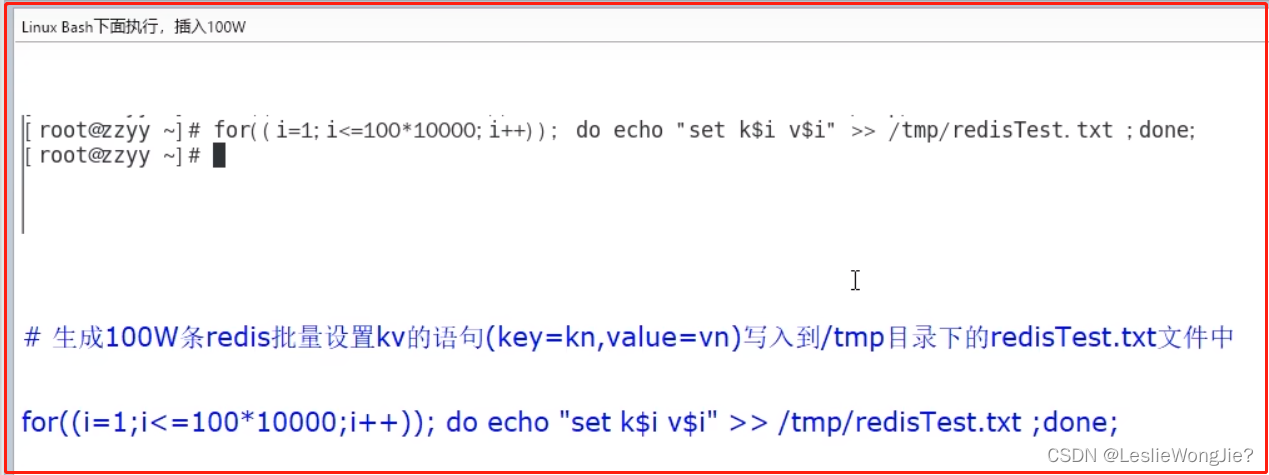
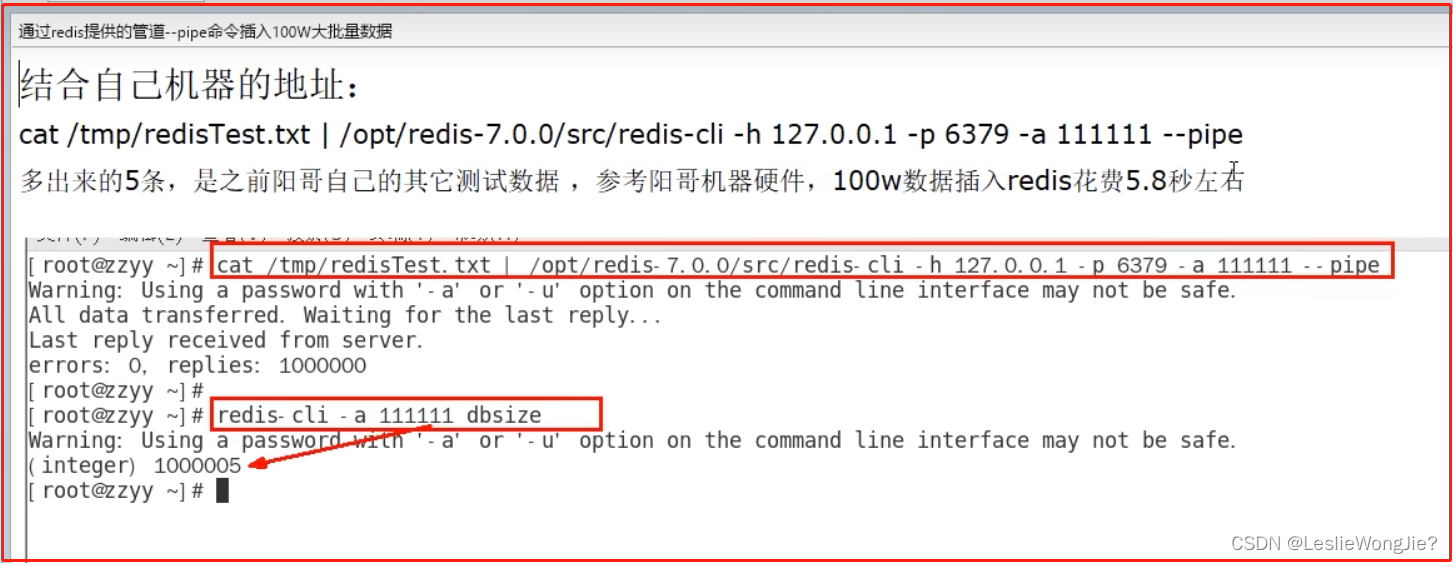
① 大批量往redis里面插入2000W测试数据key


② 某快递巨头真实生产案例新闻

keys* 你试试100W花费多少秒遍历查询
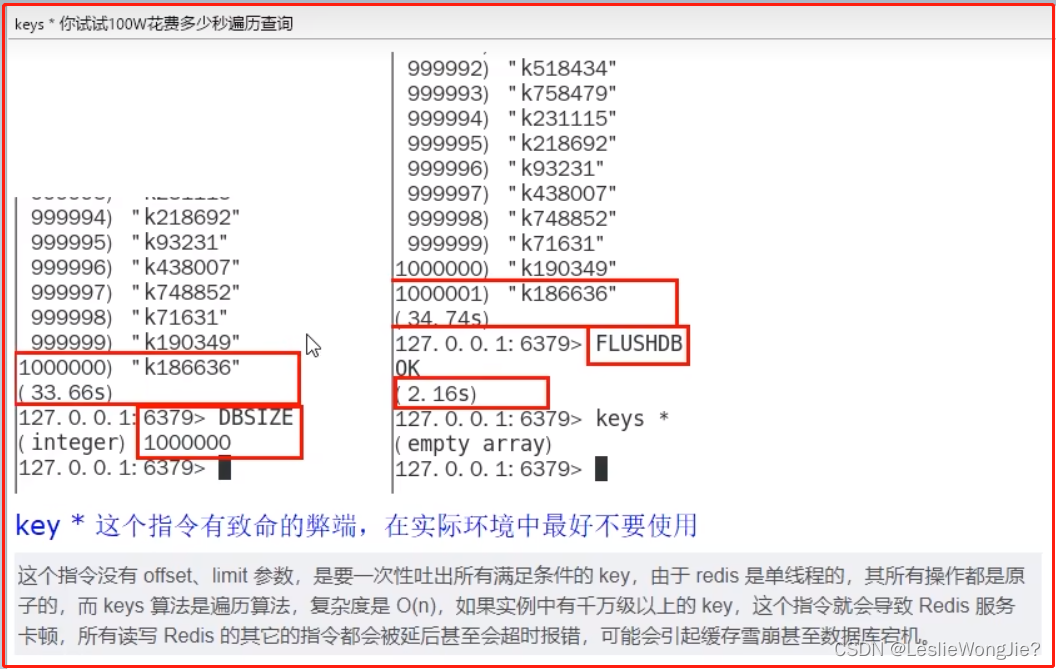
生产上限制keys */flushdb/flushall等危险命令以防止误删误用?
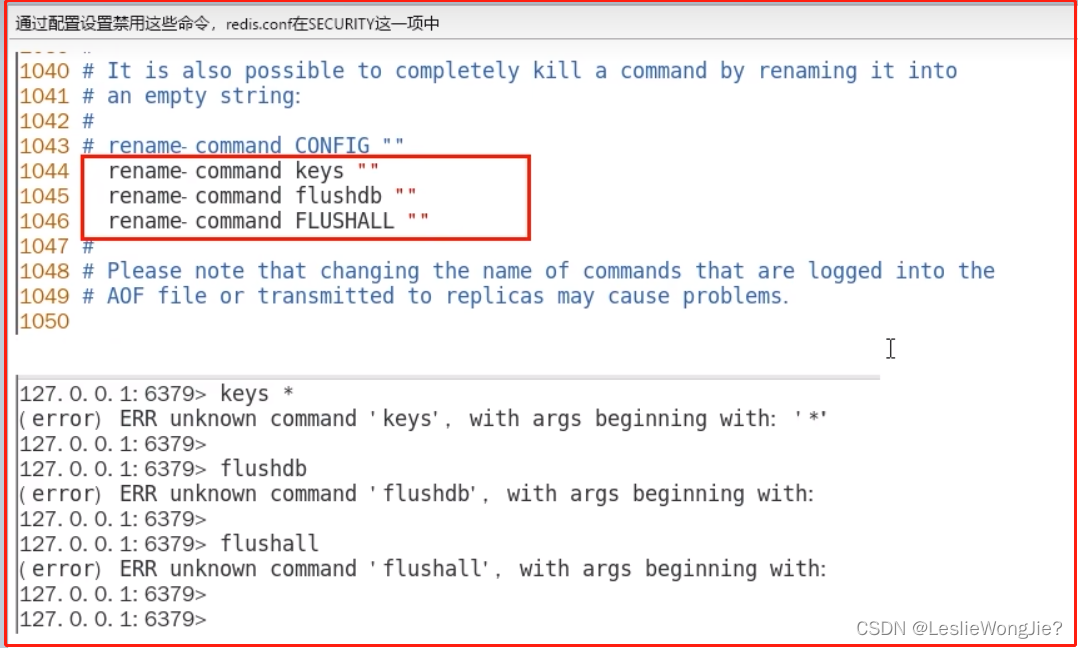
③ 不用keys *避免卡顿,那该用什么
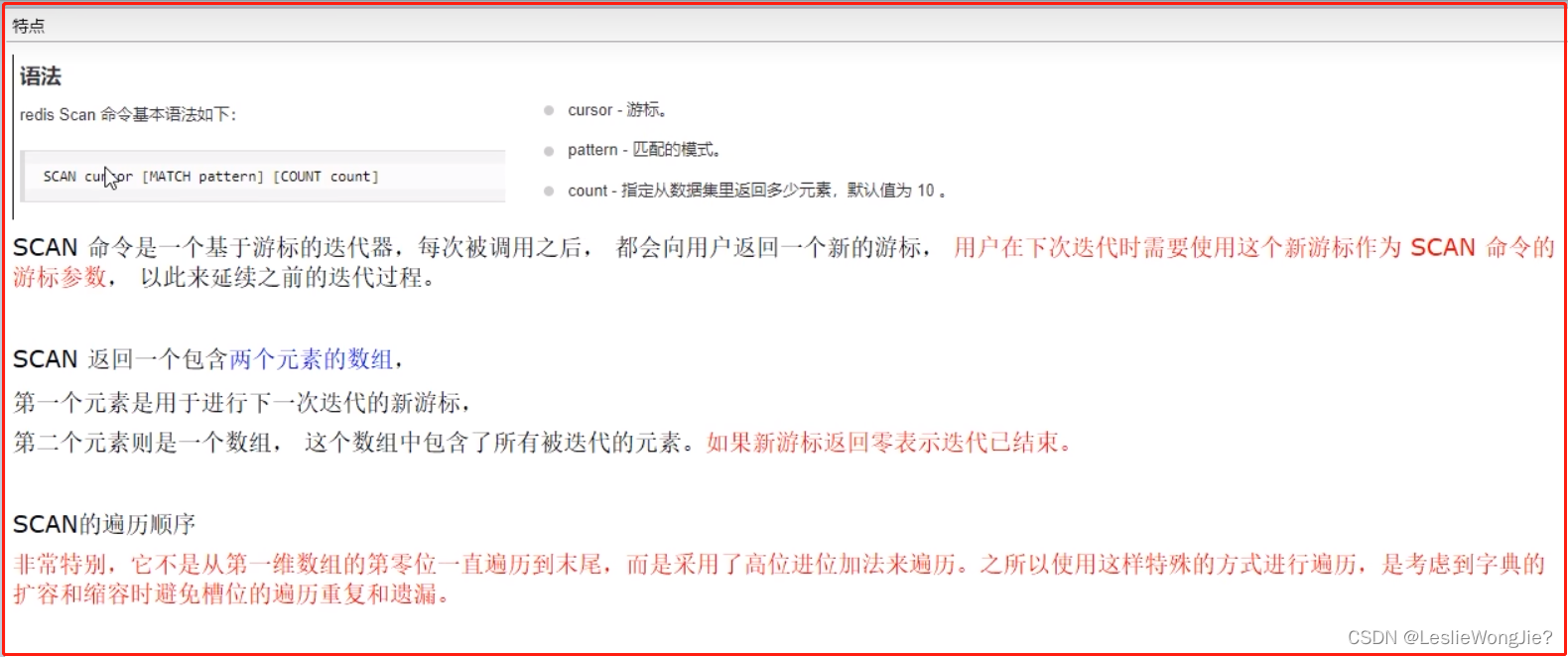
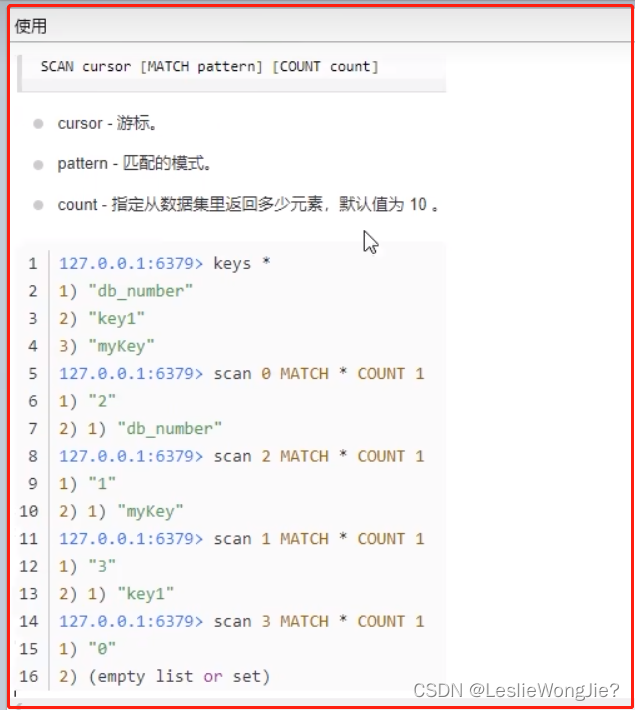
Scan 命令用于迭代数据库中的数据库键

2. BigKey案例
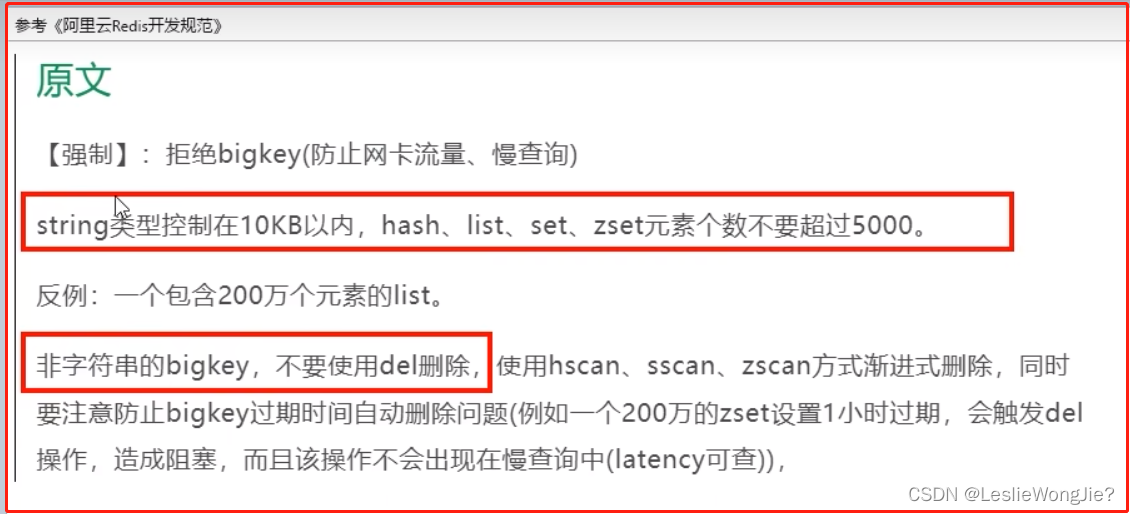
① 多大算big
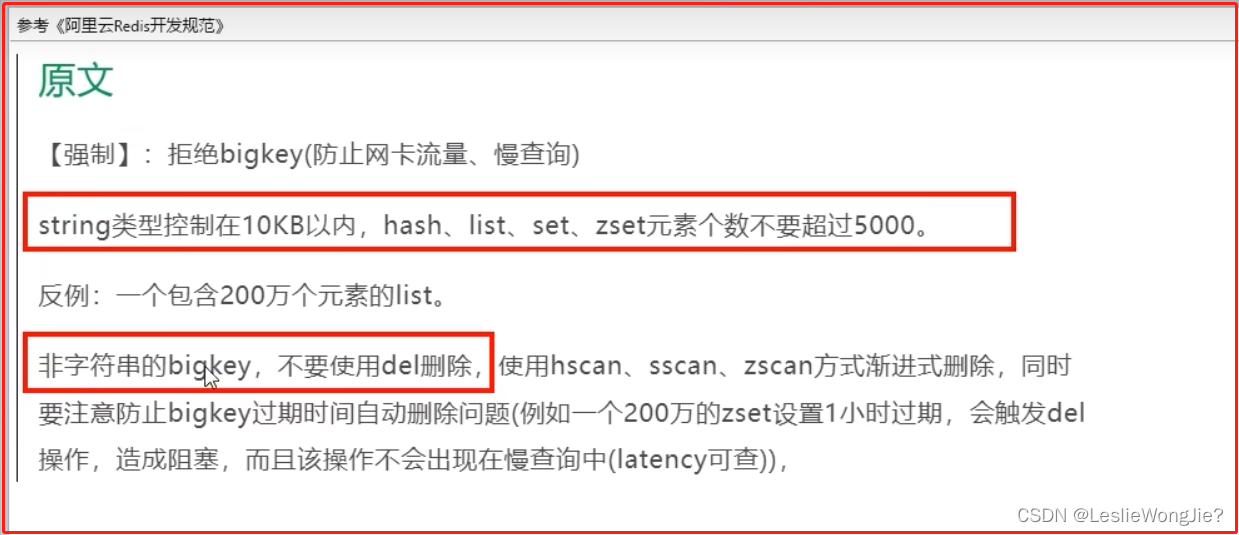
参考《阿里云Redis开发规范》
string和二级结构


② 有那些危害

③ 如何产生

④ 如何发现

redis-cli --bigkeys
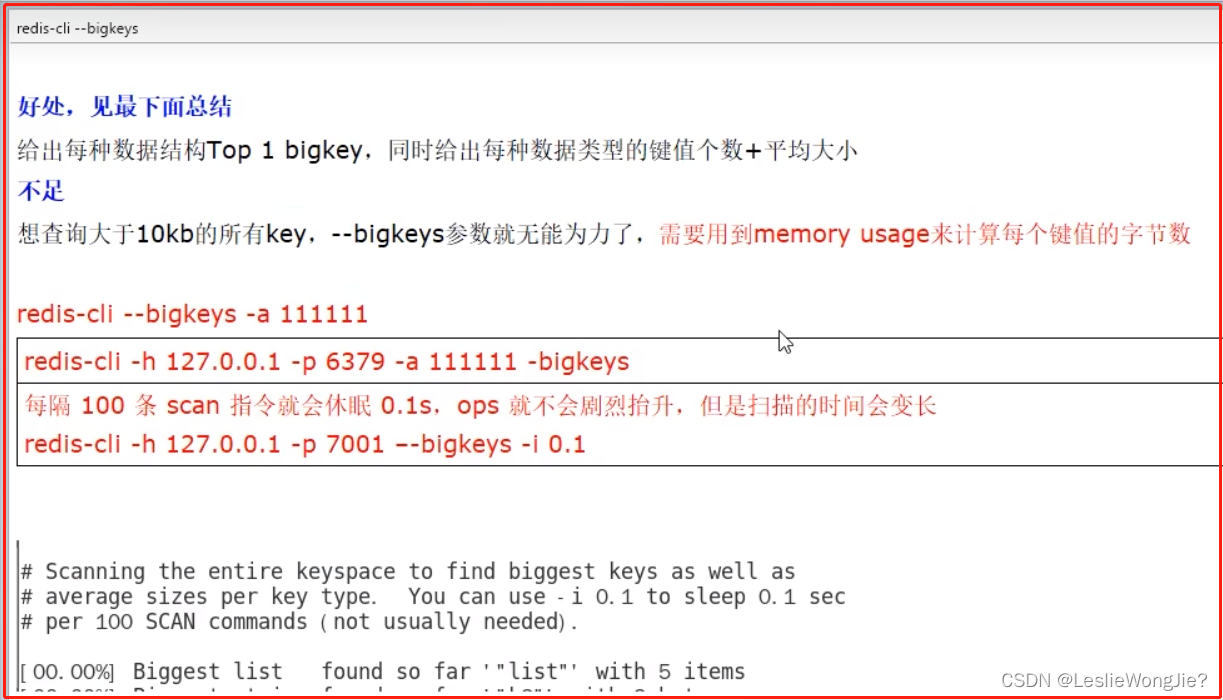

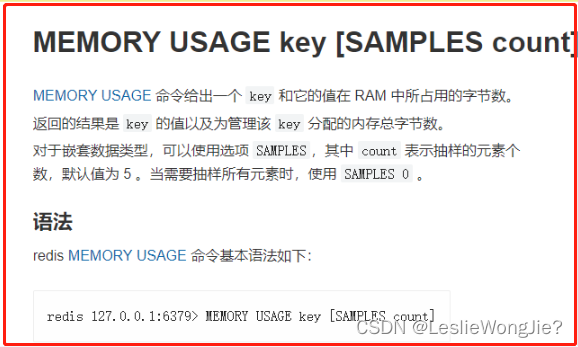
MEMORY USAGE 键

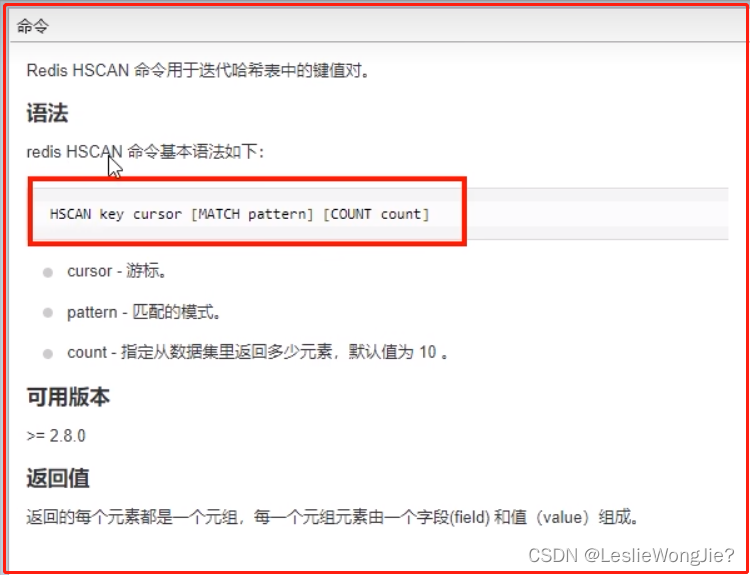
⑤ 如何删除

Ⅰ String
一般用del,如果过于庞大unlink
Ⅱ hash
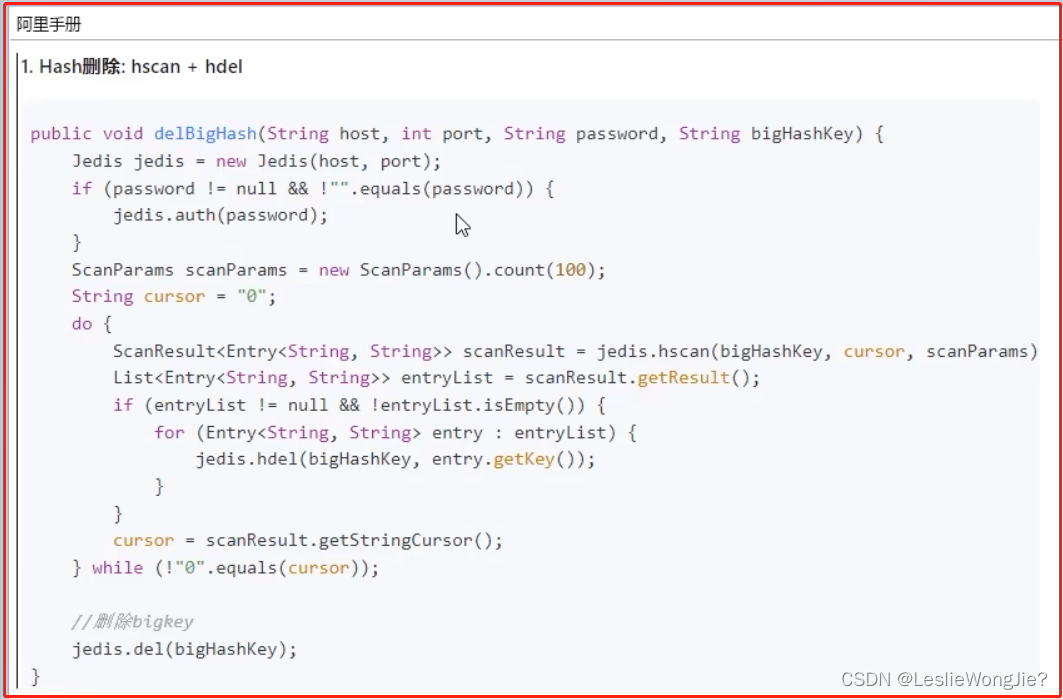
Ⅲ list
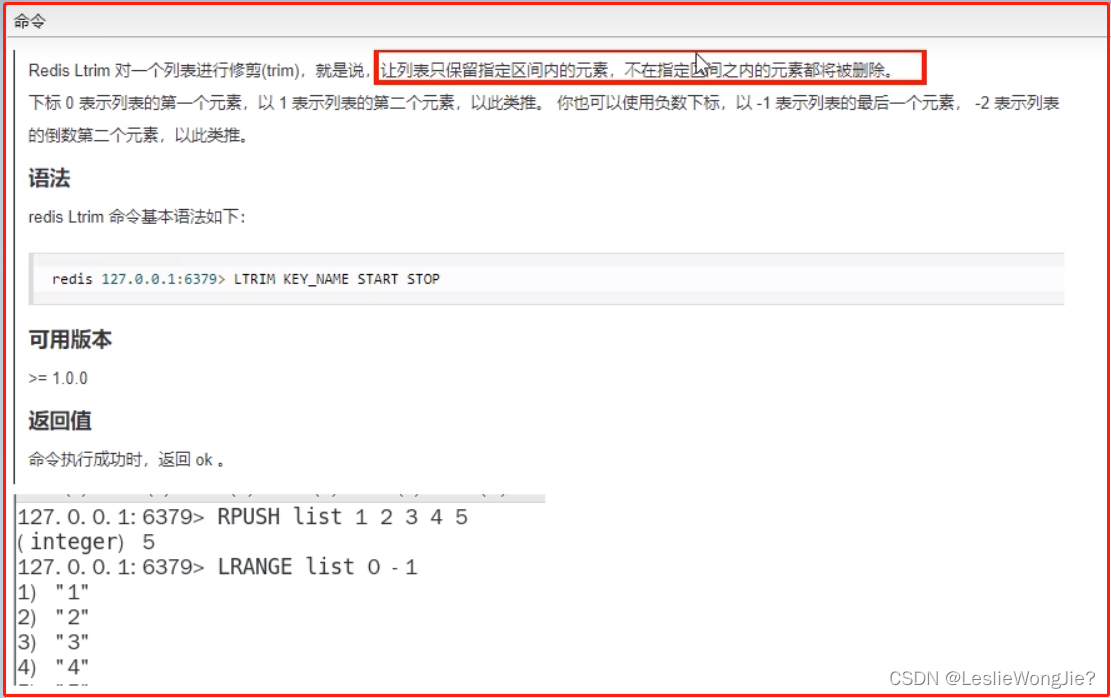
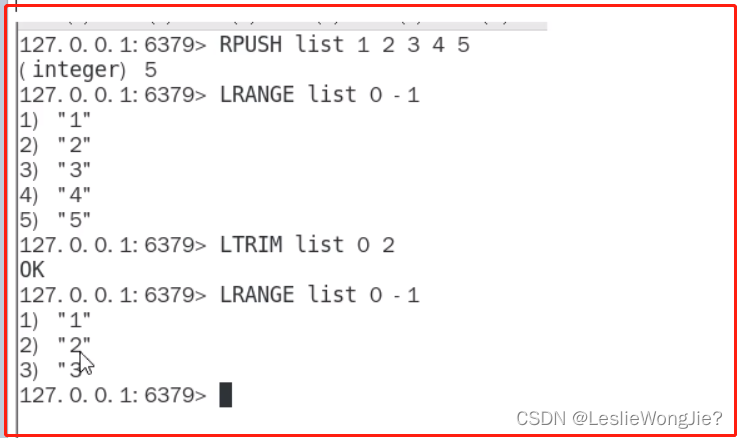
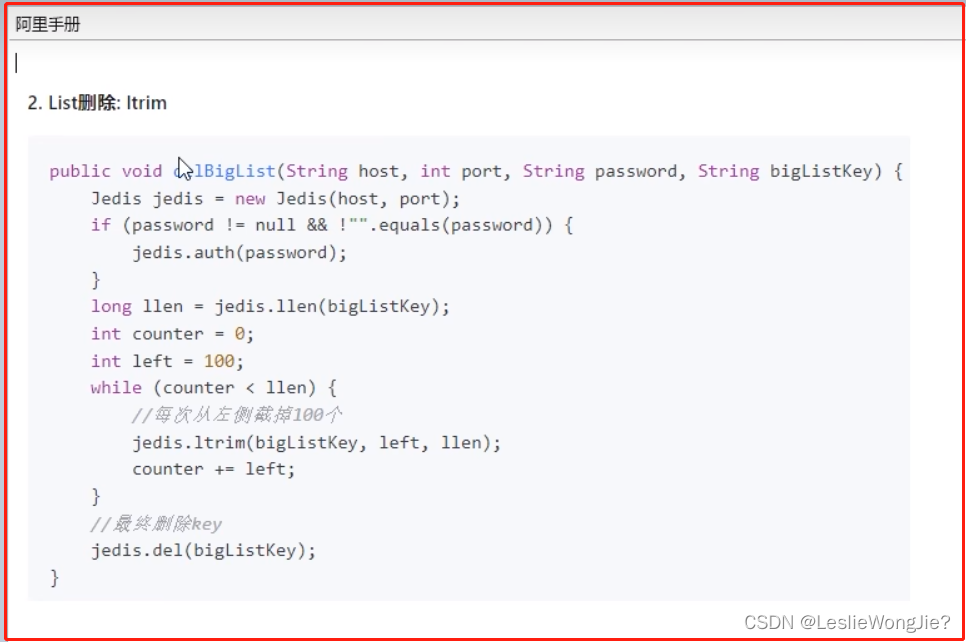
Ⅳ set
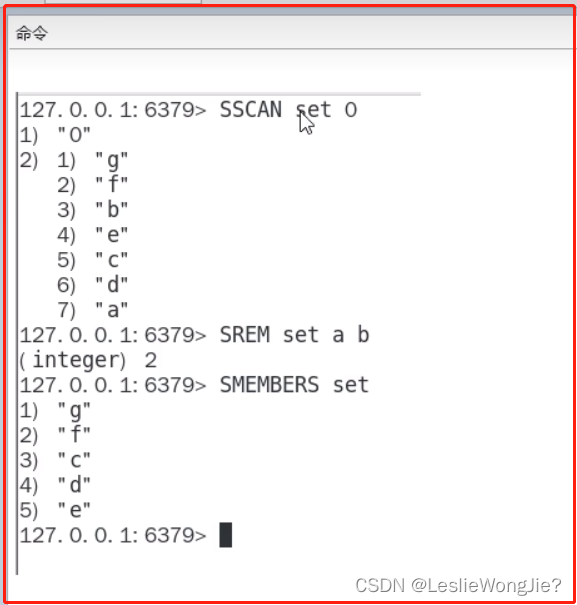
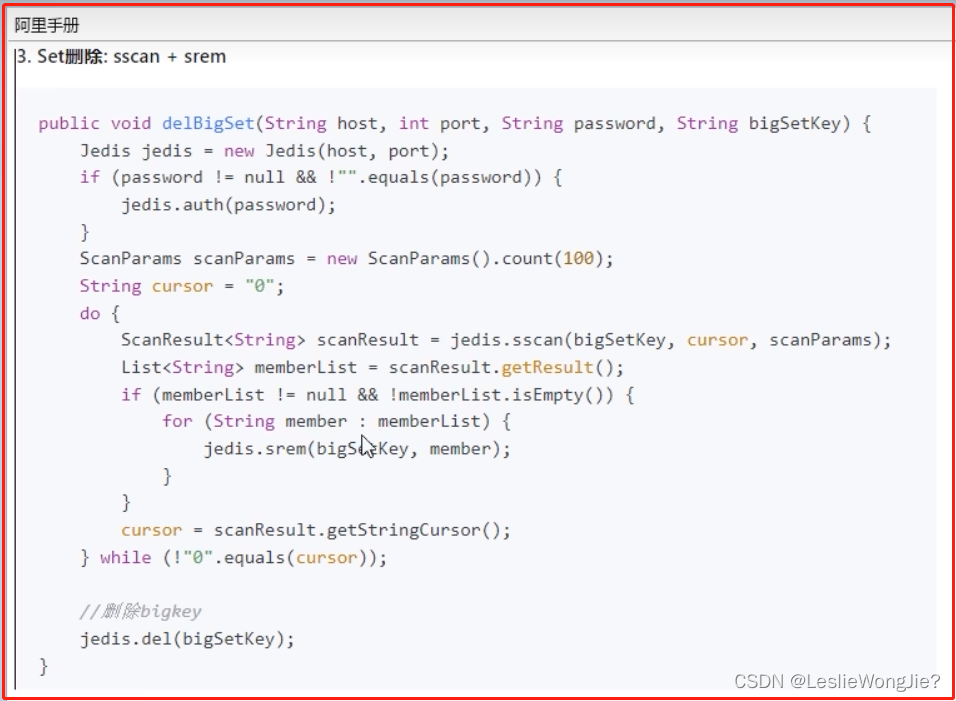
Ⅴ zset
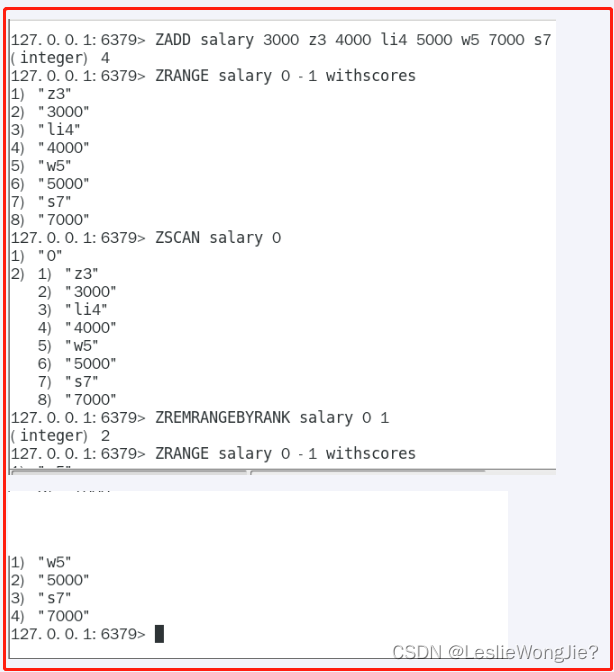
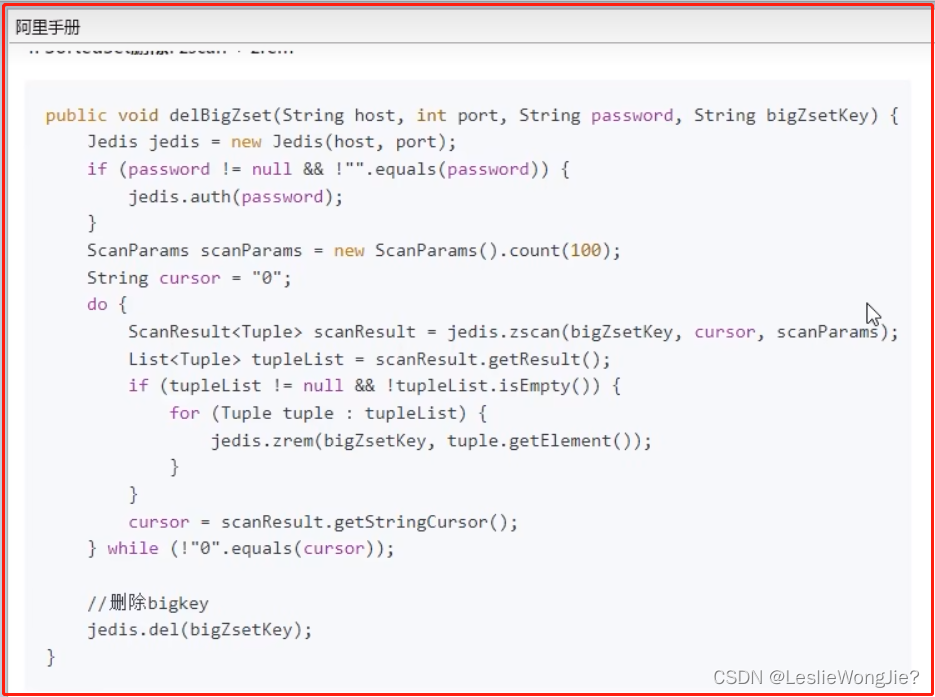
3. Bigkey生产调优



三、缓存双写一致性之更新策略探讨
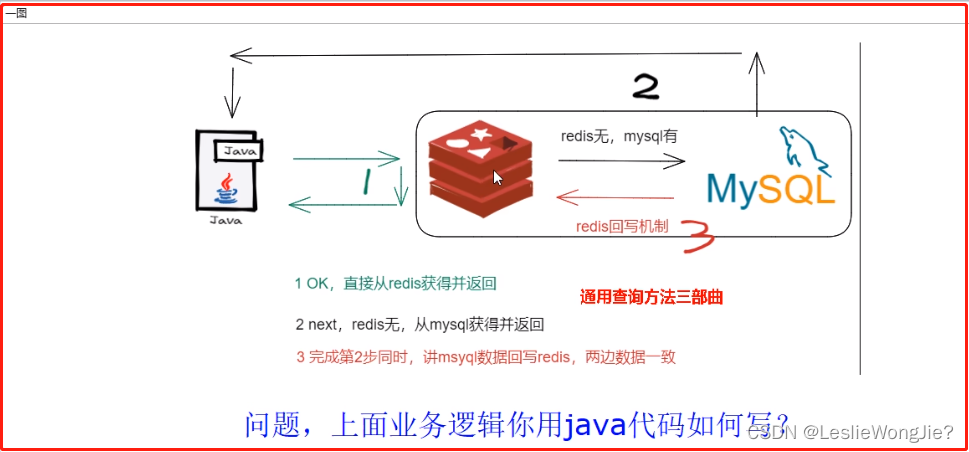
1. 缓存双写一致性,谈谈你的理解
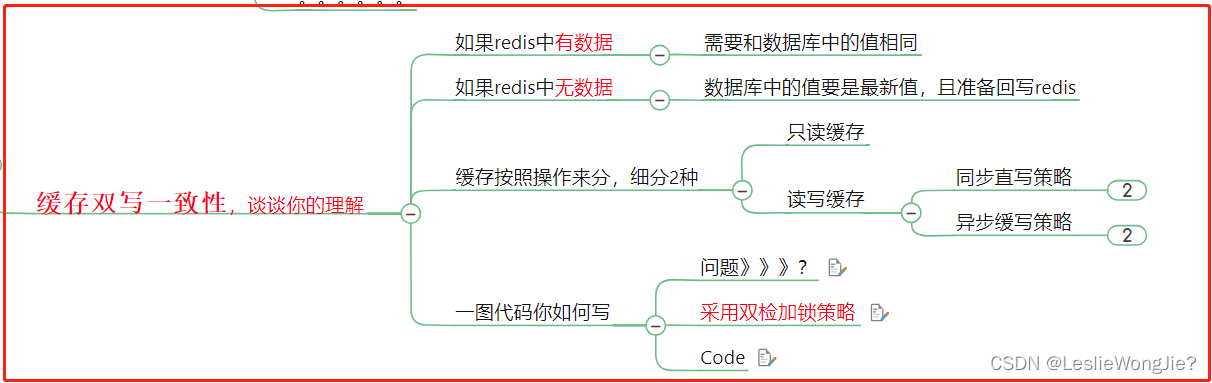
读写缓存

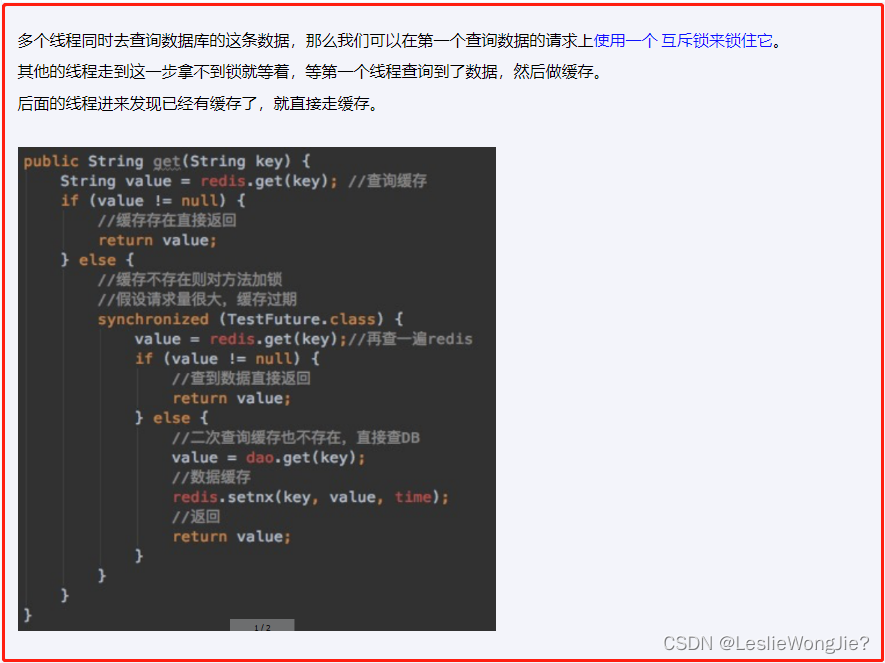
采用双检加锁策略

@Service
@Slf4j
public class UserService {
public static final String CACHE_KEY_USER = "user:";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
/**
* 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行
* @param id
* @return
*/
public User findUserById(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
{
//2 redis里面无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if(user == null)
{
//3.1 redis+mysql 都无数据
//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis
return user;
}else{
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
}
}
return user;
}
/**
* 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。
* @param id
* @return
*/
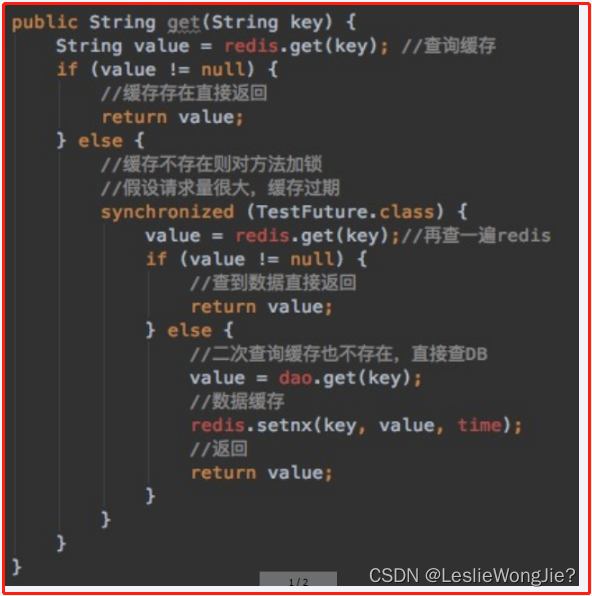
public User findUserById2(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,
// 第1次查询redis,加锁前
user = (User) redisTemplate.opsForValue().get(key);
if(user == null) {
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class){
//第2次查询redis,加锁后
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysql拿数据(mysql默认有数据)
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
return null;
}else{
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
}
}
}
}
return user;
}
}
2. 数据库和缓存一致性的几种更新策略
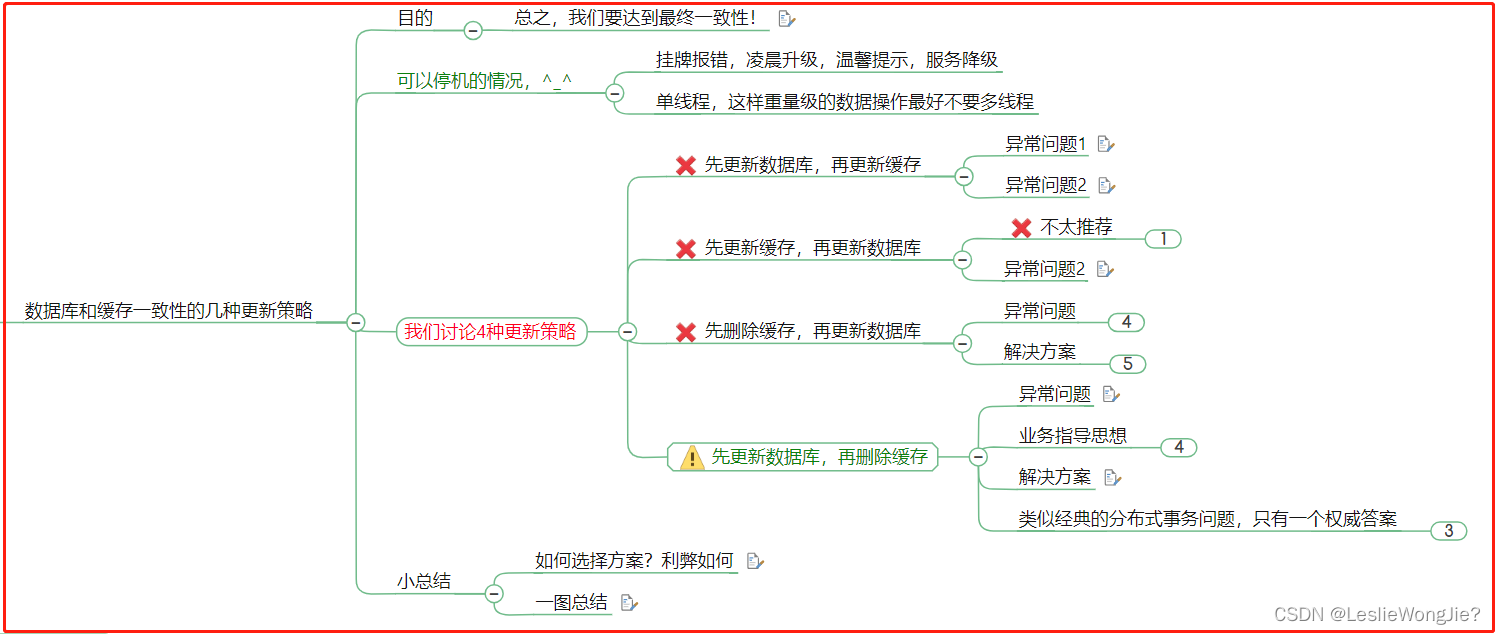

先更新数据库,再更新缓存
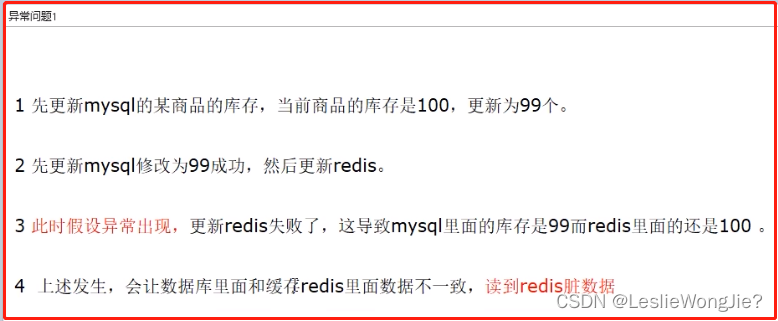
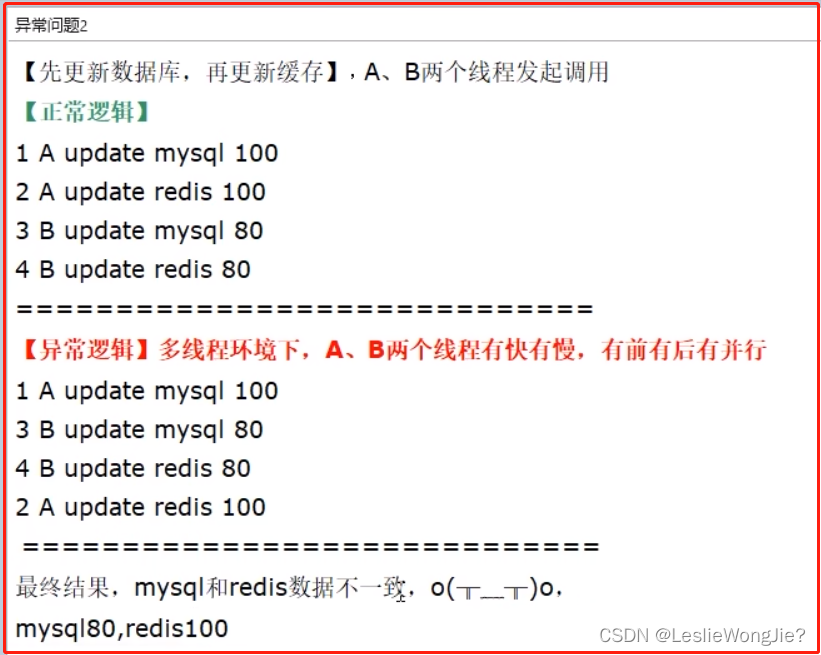
先更新缓存,再更新数据库


先删除缓存,再更新数据库

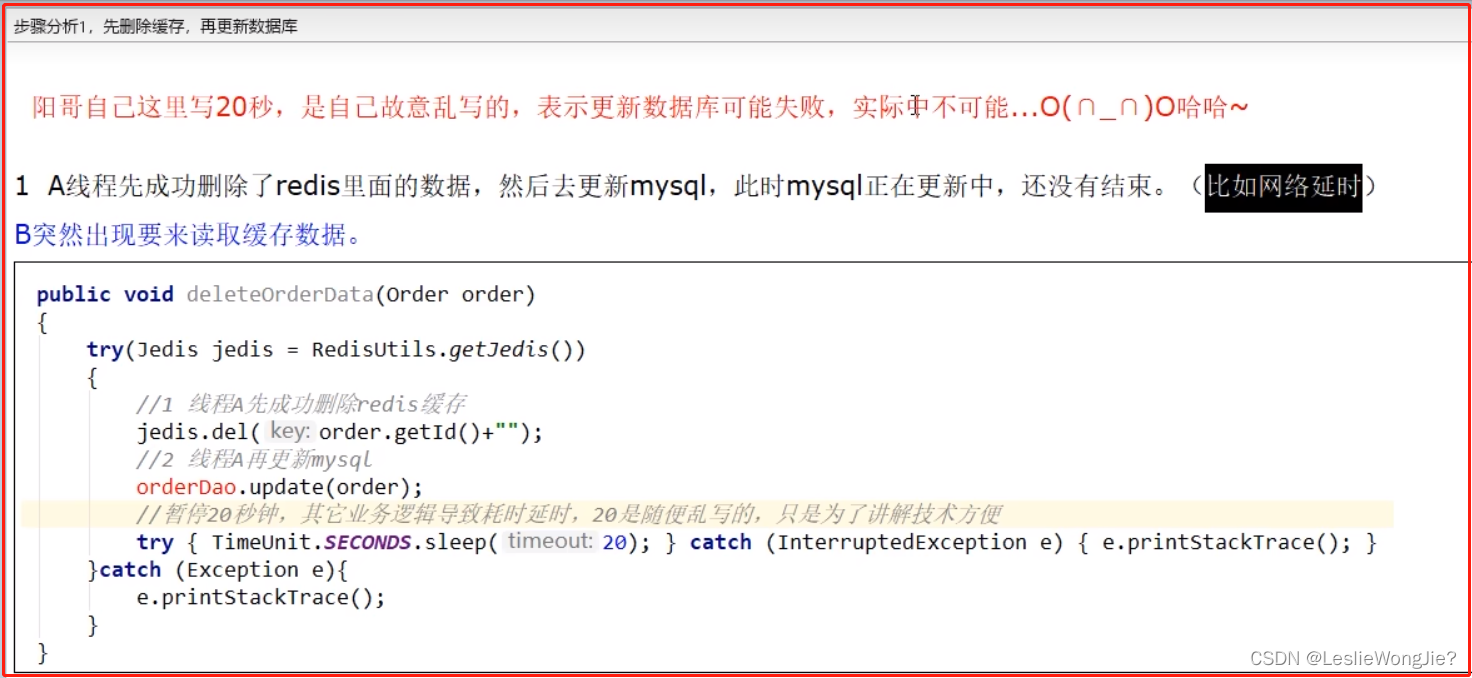
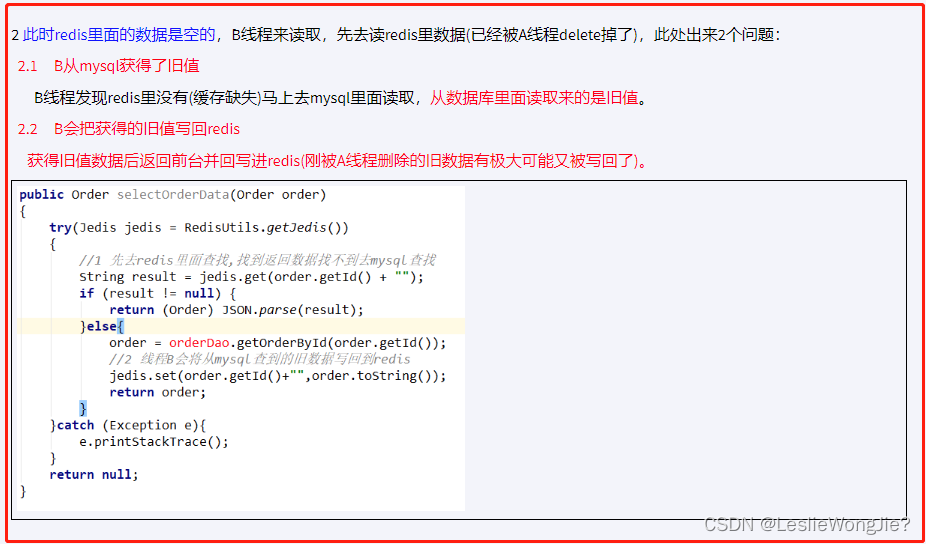
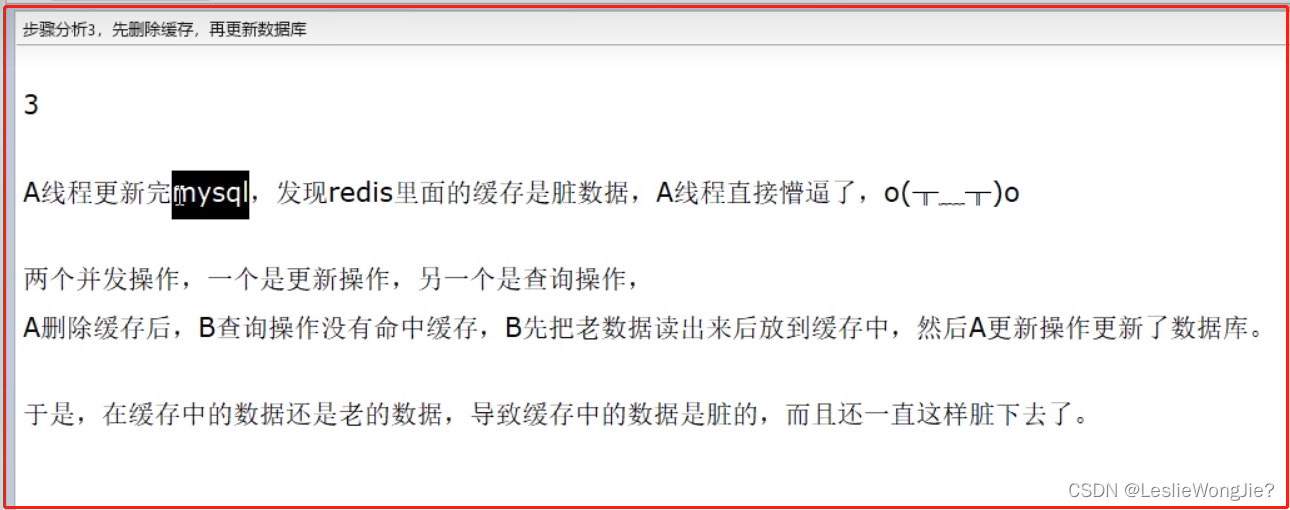
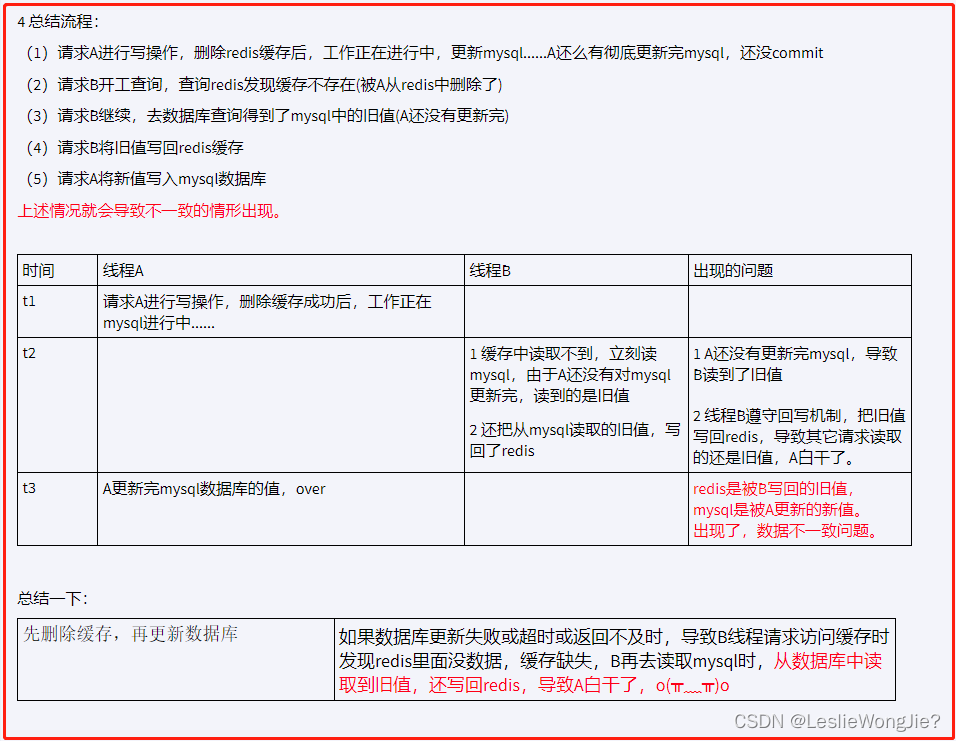
解决方法
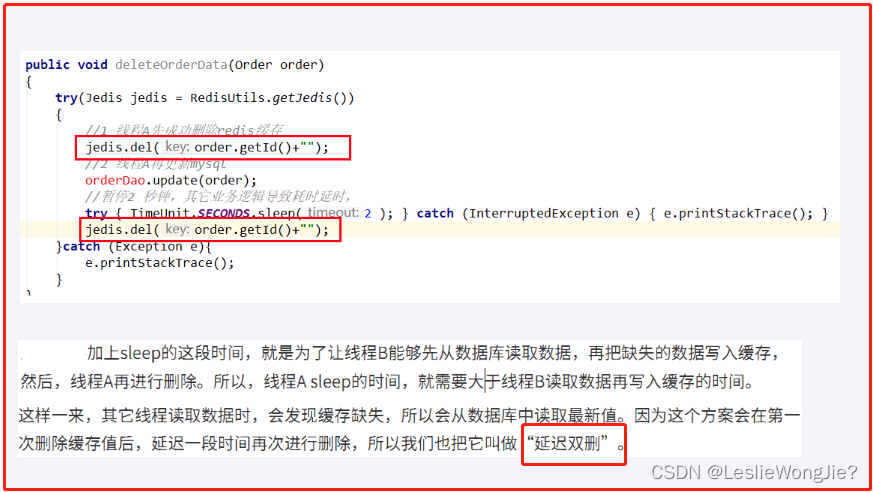
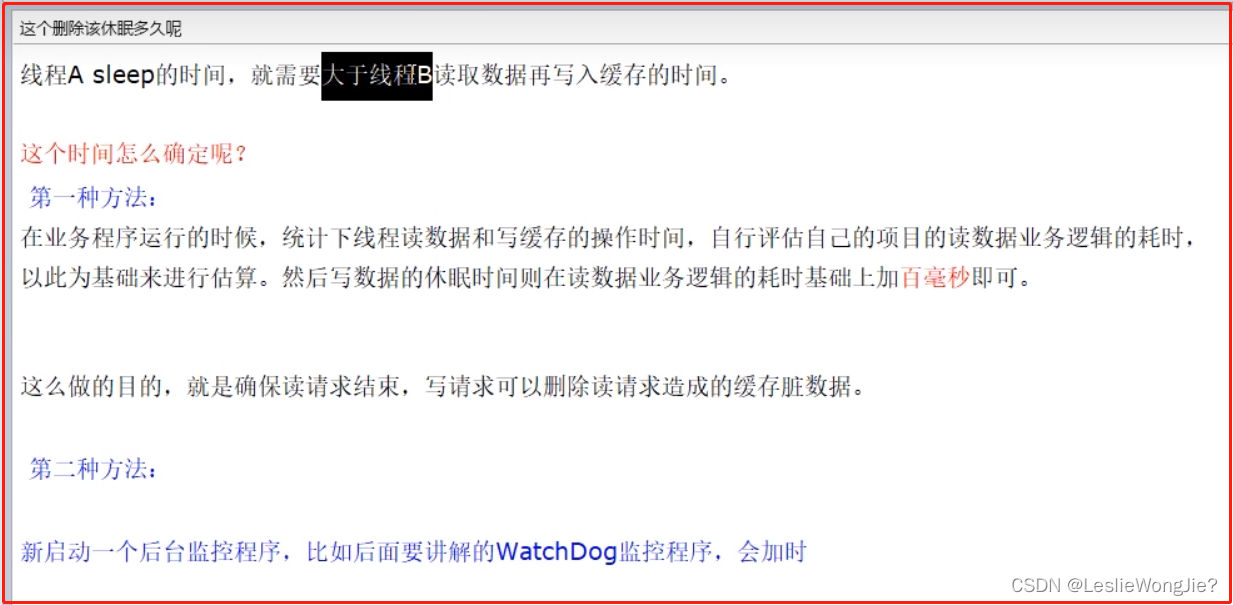
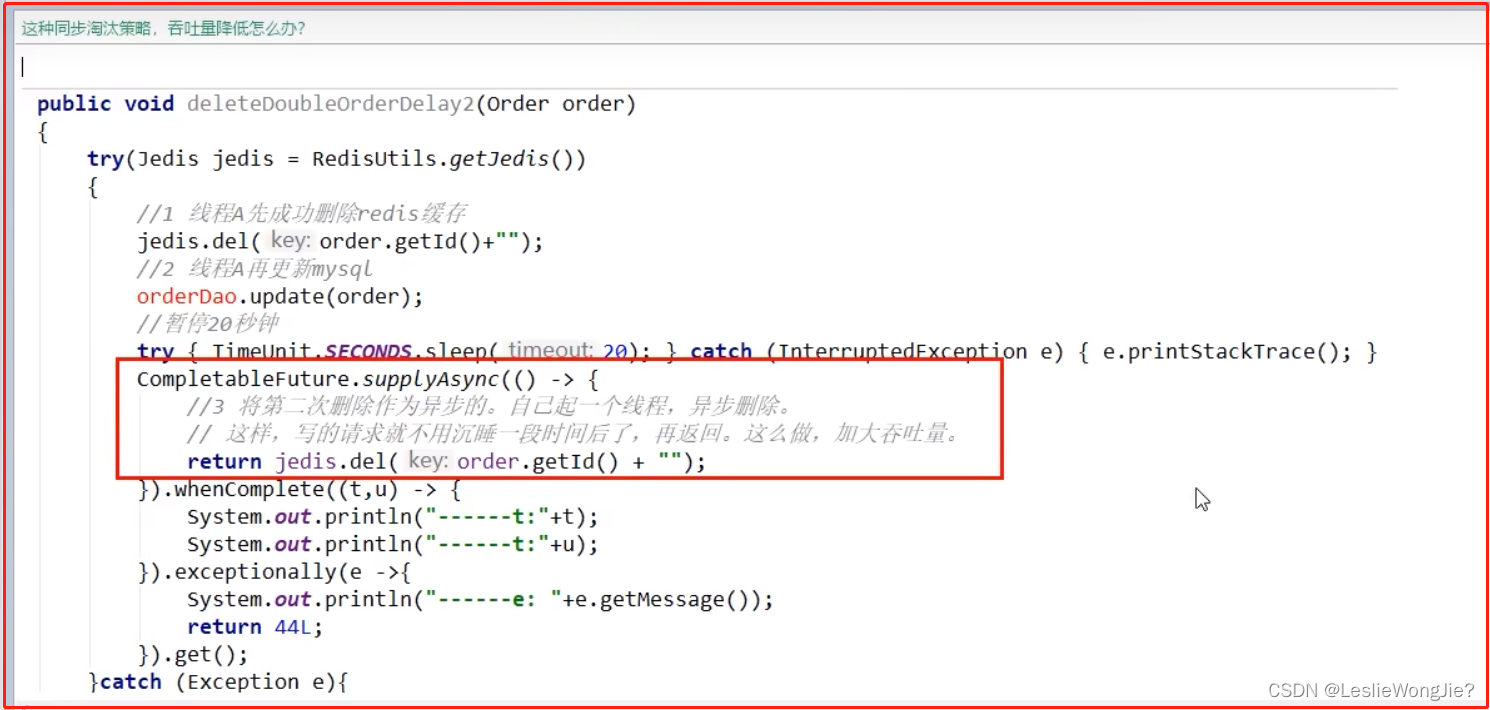
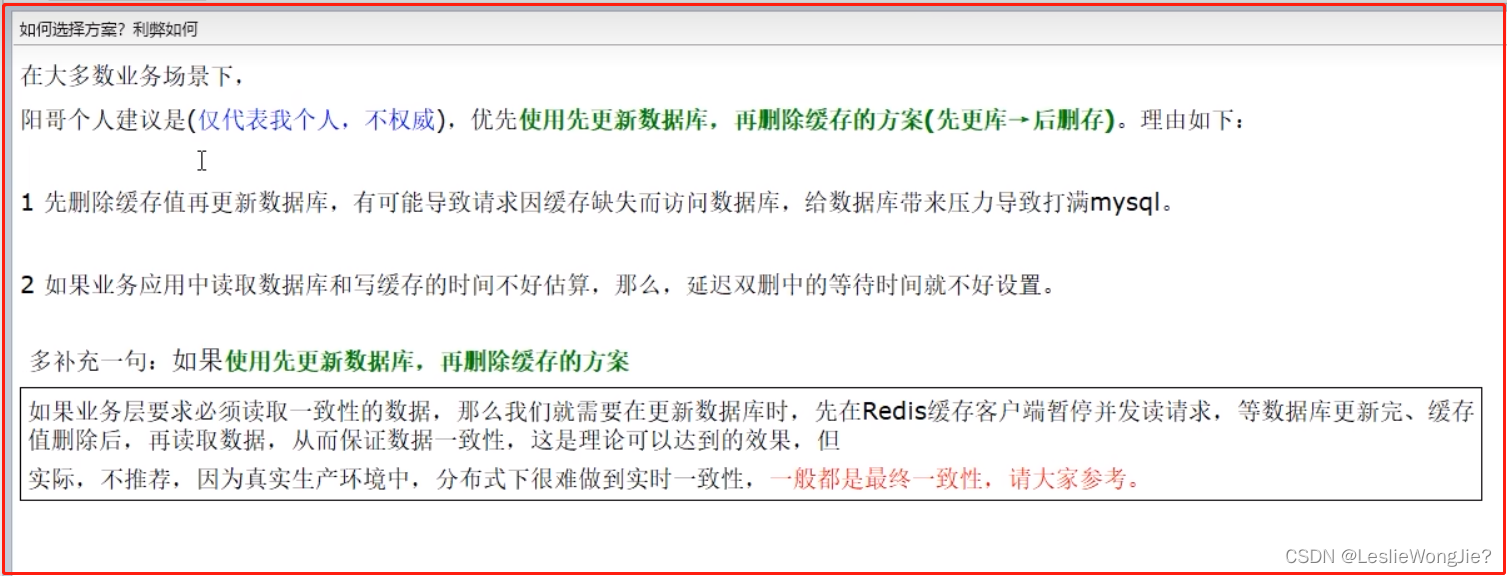
更新策略之 先更新数据库,再删除缓存

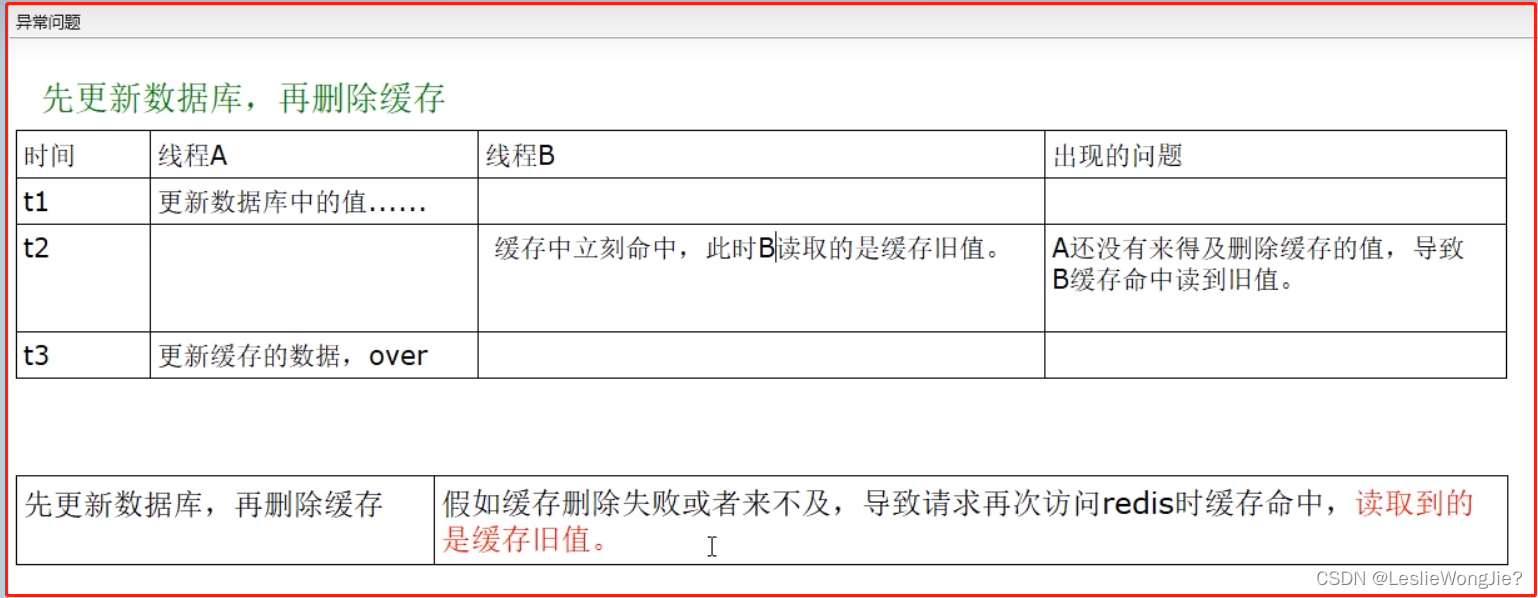
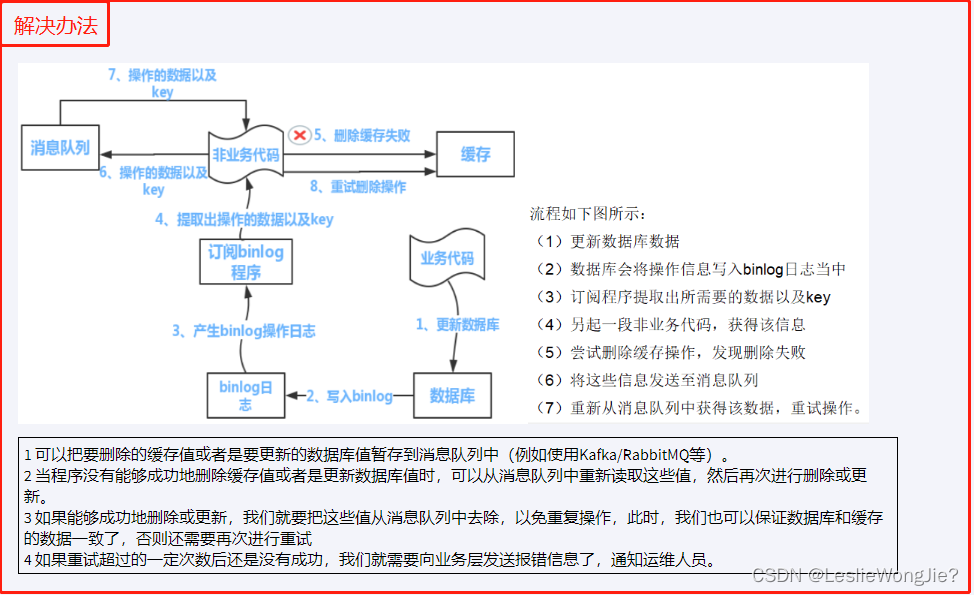
3.小总结


四. Redis与MySQL数据双写一致性工程落地案例
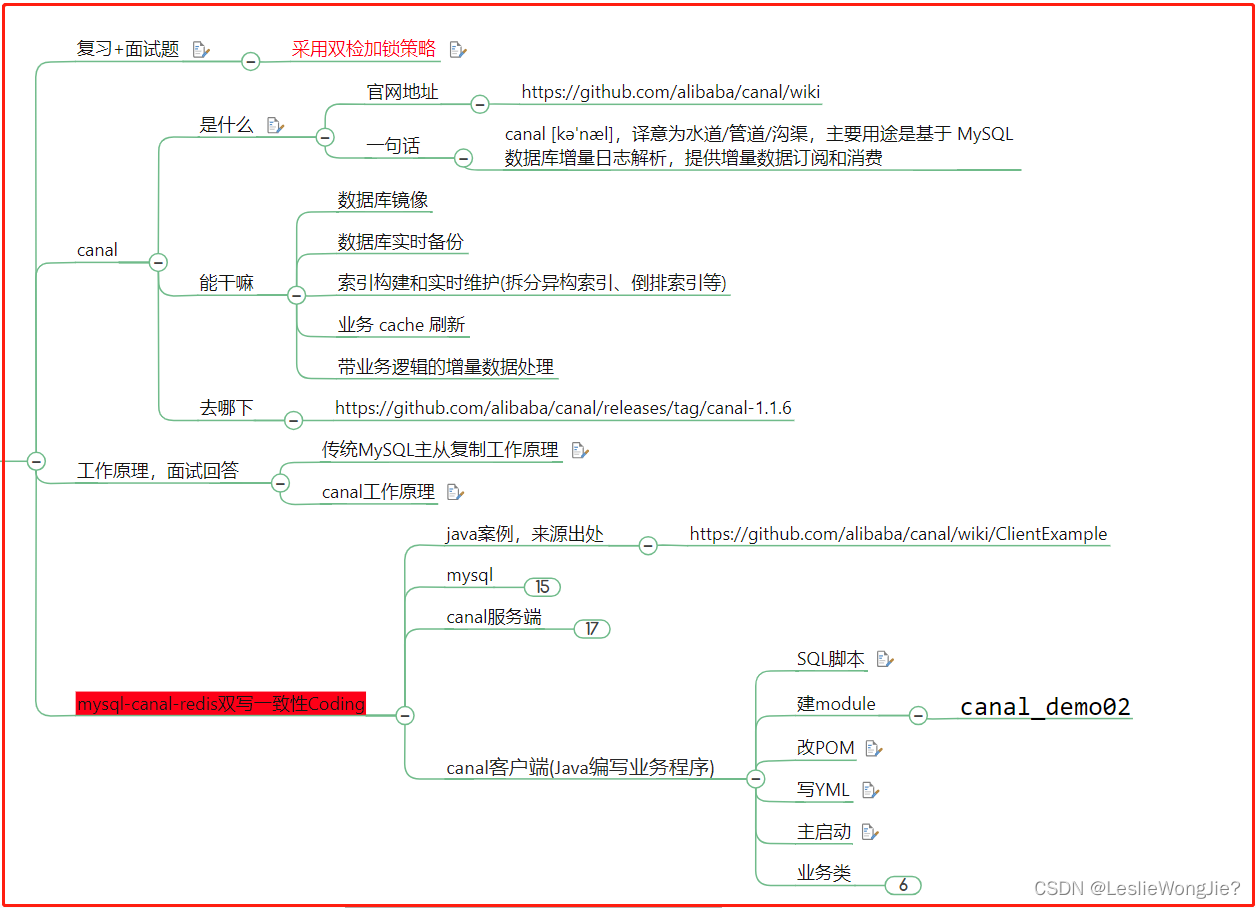
1. 复习+面试题

2. canal

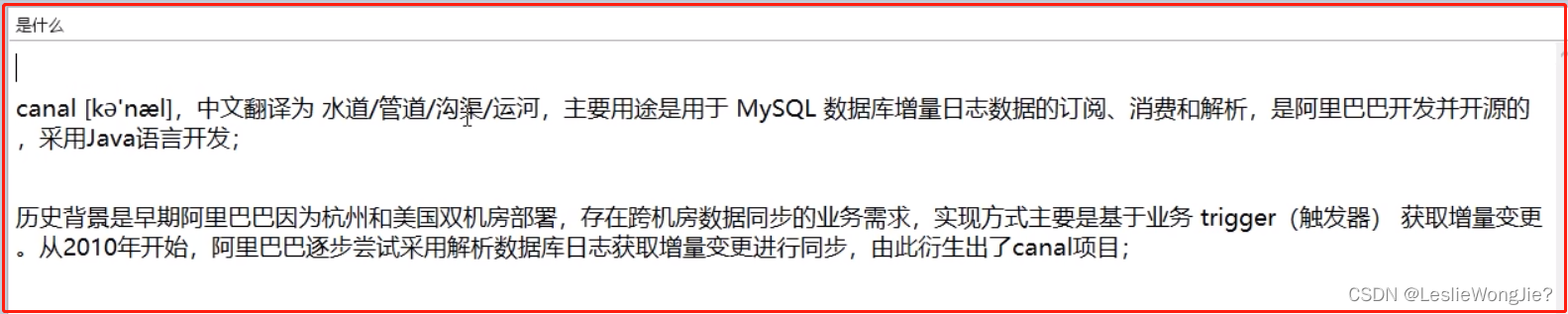
① 是什么
3. 工作原理

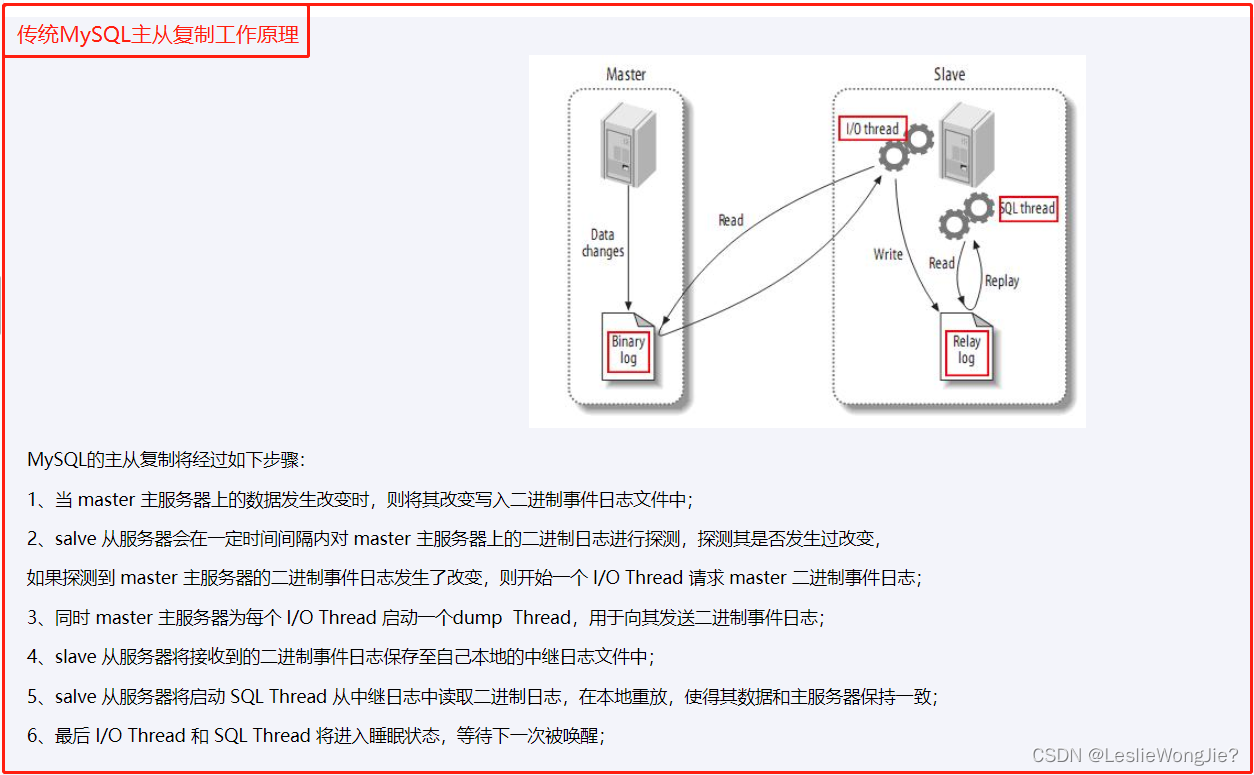
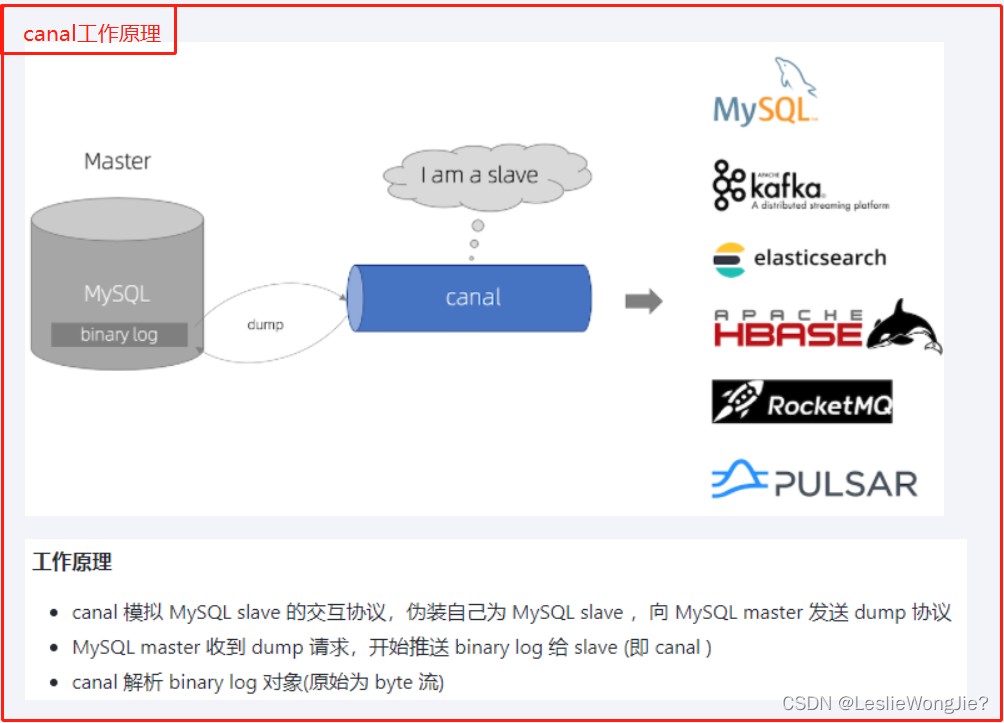
4. mysql-canal-redis双写一致性Coding
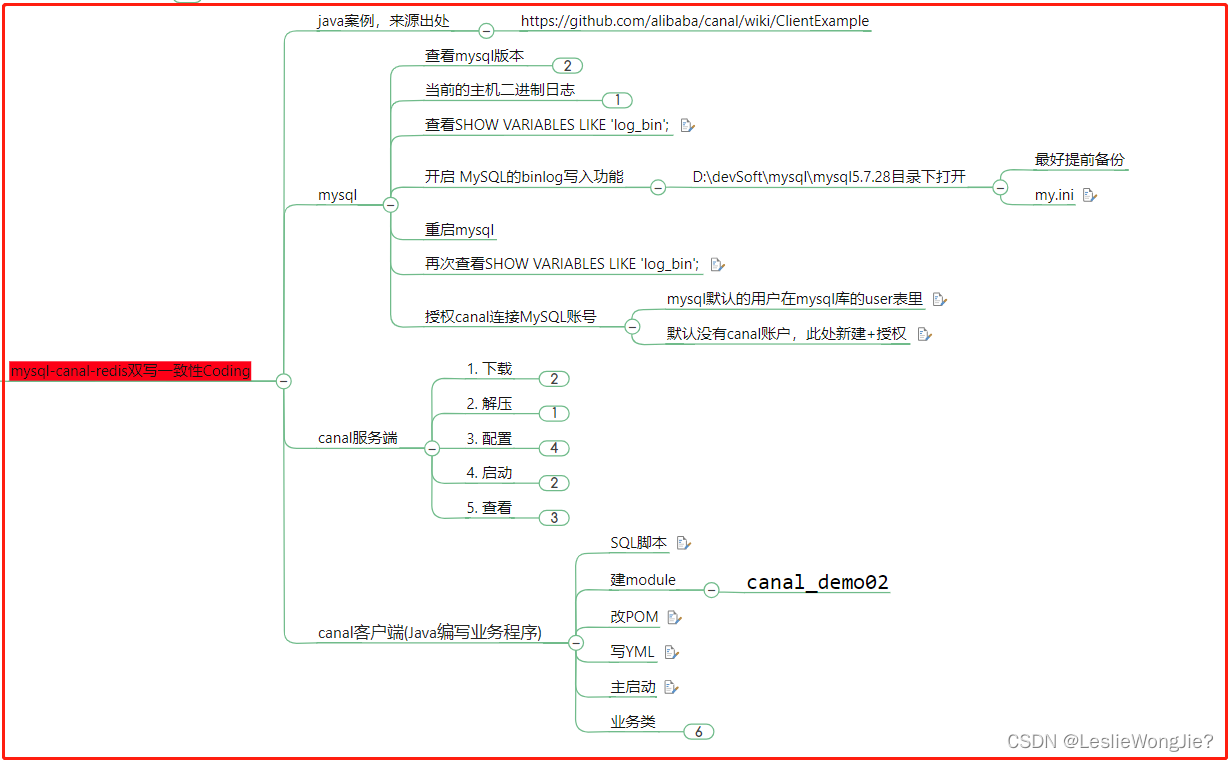
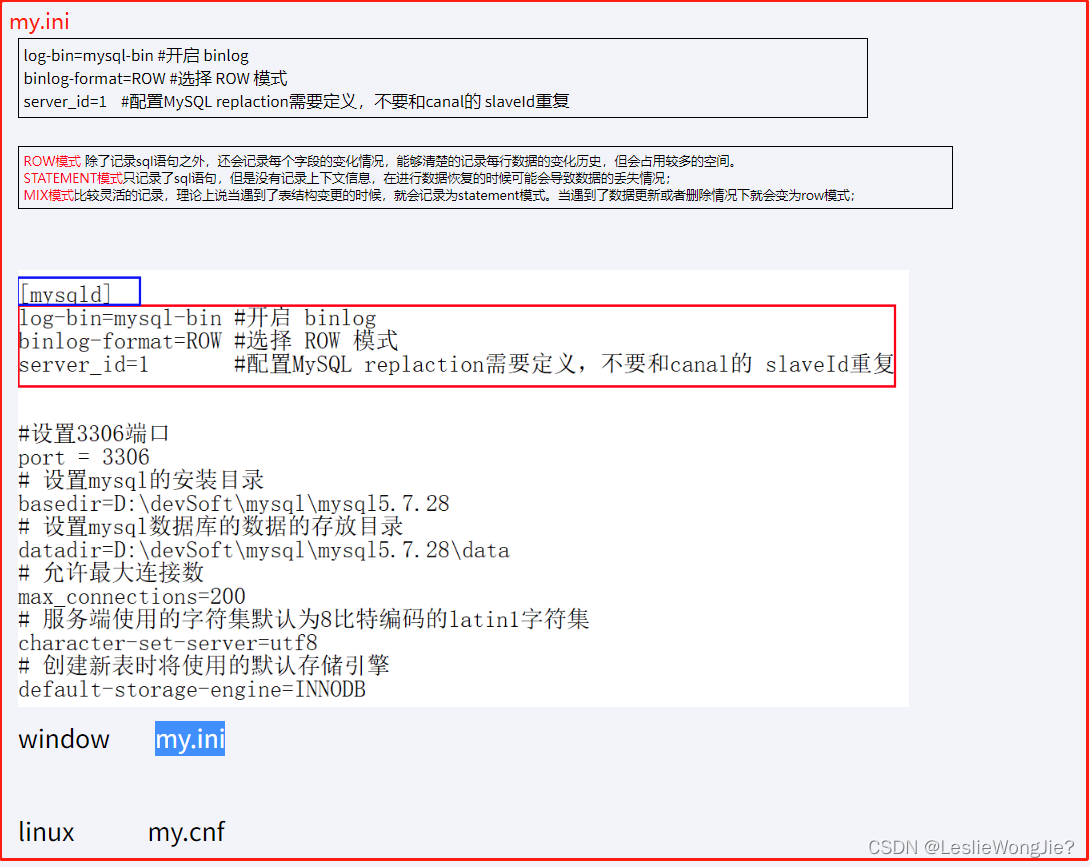















 1539
1539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









