







Redis
⼀、Redis介绍
Redis就是一个用C语言开发的、基于内存结构进行键值对数据存储的、高性能的、非关系型NoSQL数据库
1、Redis的产生背景
2008年萨尔瓦多——开发一个进行网站实时统计软件项目(LLOOGG),项目的实时统计功能需要频繁的进行数据库的读写(对数据库的读写要求很高—数千次/s),MySQL满足不了项目的需求,萨尔瓦多就使用C语言自定义了一个数据存储系统—Redis。后来萨尔瓦多不满足仅仅在LLOOGG这个项目中使用redis,就对redis进行产品化并进行开源,以便让更多的⼈能够使用。
2、Redis支持的数据类型
Redis是基于键值对进行数据存储的,但是value可以是多种数据类型:
- string 字符串
- hash 映射
- list 列表(队列)
- set 集合
- zset ⽆序集合
3、Redis特点
- 基于内存存储,数据读写效率很高
- Redis本身支持持久化
- Reids虽然基于key-value存储,但是支持多种数据类型
- Redis支持集群、支持主从模式
4、Redis应用场景
- 缓存:在绝大多数的互联网项目中,为了提供数据的访问速度、降低数据库的访问压力,我们可以使用redis作为缓存来实现
- 点赞、排行榜、计数器等功能:对数据实时读写要求比较高,但是对数据库的⼀致性要求并不是太高的功能场景
- 分布式锁:基于redis的操作特性可以实现分布式锁功能
- 分布式会话:在分布式系统中可以使用redis实现
session(共享缓存) - 消息中间件:可以使用redis实现应用之间的通信
5、Redis的优缺点
- 5.1 优点
- redis是基于内存结构,性能极高(读 110000次/秒,写 81000次/秒)
- redis基于键值对存储,但是支持多种数据类型
- redis的所有操作都是原子性,可以通过
lua脚本将多个操作合并为⼀个原子操作(Redis
的事务) - reids是基于单线程操作,但是其多路复用实现了高性能读写
- 5.2 缺点
- 缓存数据与数据库数据必须通过两次写操作才能保持数据的⼀致性
- 使用缓存会存在缓存穿透、缓存击穿及缓存雪崩等问题,需要处理
- redis可以作为数据库使用进行数据的持久存储,存在丢失数据的⻛险
二、Redis安装及配置
基于Linux环境安装
注意: 要安装gcc环境:yum -y install gcc
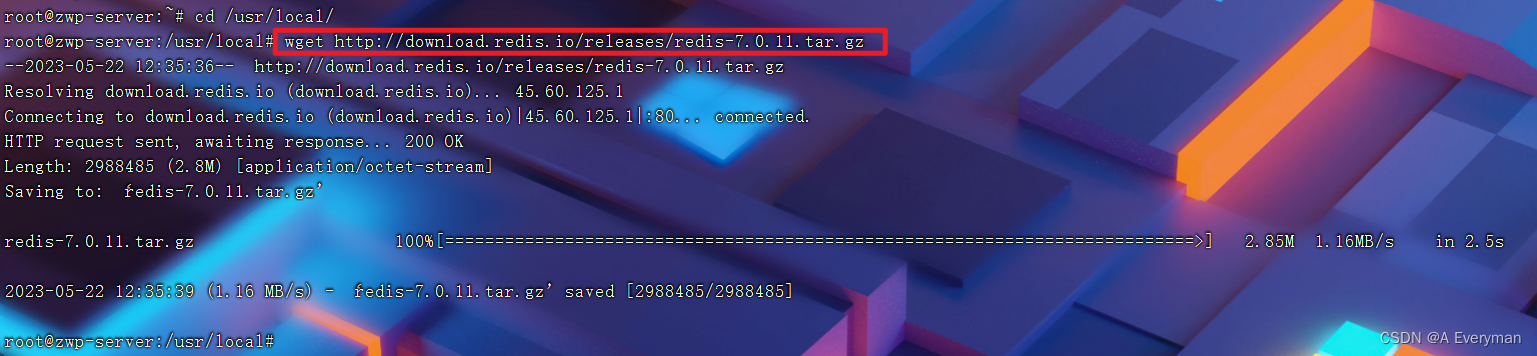
1、下载安装包
wget http://download.redis.io/releases/redis-7.0.11.tar.gz
2、安装
(1). 解压
tar -zxvf redis-7.0.11.tar.gz
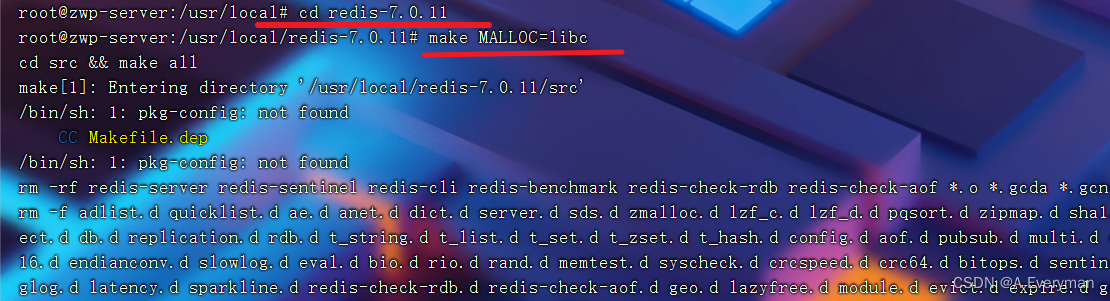
(2). 编译
root@zwp-server:/usr/local:: cd redis-7.0.11
root@zwp-server:/usr/local/redis-7.0.11:: make MALLOC=libc
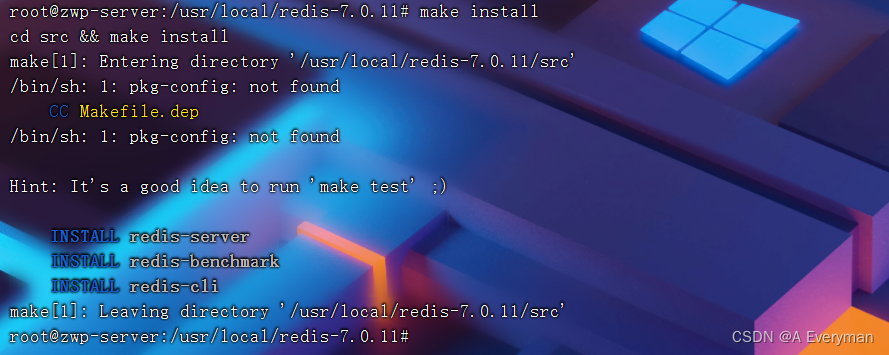
(3). 安装
root@zwp-server:/usr/local/redis-7.0.11:: make install
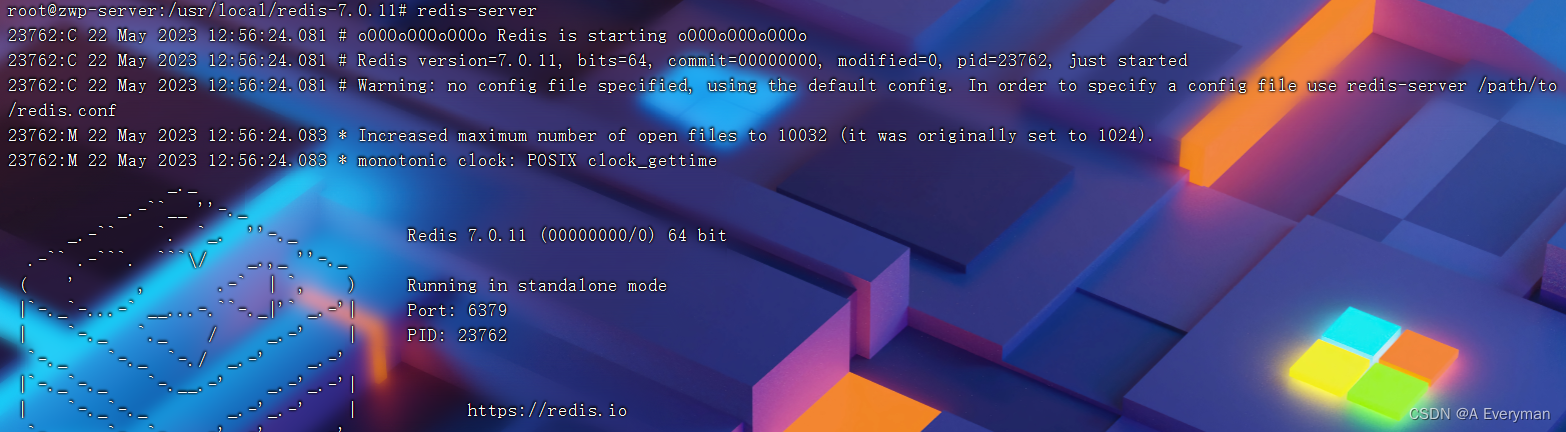
3、启动
# 当完成redis安装之后,就可以执行redis相关的指令
redis-server # 启动redis服务
redis-server & # 后台-启动redis服务
# redis-cli 启动redis操作客户端(命令行客户端)
4、配置
-
使用
redis-server指令启动 redis 服务的时候,可以在指令后添加 redis 配置文件的路径,以设置 redis 是以何种配置进行启动redis-server redis-6380.conf & ## redis以redis-6380.conf文件中的配置来启动 -
如果不指定配置文件的名字,则按照redis的默认配置启动(默认配置 ≠
redis.conf) -
可以通过创建 redis 根目录下
redis.conf来创建多个配置文件,启动多个服务。redis-server redis-6380.conf & ## 第一个服务 redis-server redis-6390.conf & ## 第二个服务
redis常用配置:
## 设置redis实例(服务)为守护模式,默认值为no,可以设置为yes
daemonize no
## 设置当前redis实例启动后保存进程id的文件路径
pidfile /var/run/redis_6379.pid
## 设置redis实例的启动端口(默认6379)
port 6379
## 设置当前redis实例是否开启保护模式---【设置为no,允许远程访问】
protected-mode yes
## 设置允许访问当前redis实例的ip地址列表---【允许远程访问,需要注释掉bind】
bind 127.0.0.1
## 设置连接密码(去掉 # 号,修改密码即可)
requirepass foobared
## 设置redis实例中数据库的个数(默认16个,编号0-15)
databases 16
## 设置最大并发数量
maxclients 10000
## 设置客户端和redis建立连接的最大空闲时间,设置为0表示不限制
timeout 0
三、Redis基本使用
1、string常用指令
## 设置值/修改值 如果key存在则进⾏修改
set key value
## 取值
get key
## 批量添加
mset k1 v1 [k2 v2 k3 v3 ...]
## 批量取值
mget k1 [k2 k3...]
## ⾃增和⾃减
incr key ## 在key对应的value上⾃增 +1
decr key ## 在key对应的value上⾃减 -1
incrby key v ## 在key对应的value上+v
decrby key v ## 在key对应的value上-v
## 添加键值对,并设置过期时间(TTL)
setex key time(seconds) value
## 设置值,如果key不存在则成功添加,如果key存在则添加失败(不做修改操作)
setnx key value
## 在指定的key对应value拼接字符串
append key value
## 获取key对应的字符串的⻓度
strlen key
2、hash常用指令
## 向key对应的hash中添加键值对
hset key field value
## 从key对应的hash获取field对应的值
hget key field
## 向key对应的hash结构中批量添加键值对
hmset key f1 v1 [f2 v2 ...]
## 从key对应的hash中批量获取值
hmget key f1 [f2 f3 ...]
## 在key对应的hash中的field对应value上加v
hincrby key field v
## 获取key对应的hash中所有的键值对
hgetall key
## 获取key对应的hash中所有的field
hkeys key
## 获取key对应的hash中所有的value
hvals key
## 检查key对应的hash中是否有指定的field
hexists key field
## 获取key对应的hash中键值对的个数
hlen key
## 向key对应的hash结构中添加f-v,如果field在hash中已经存在,则添加失败
hsetnx key field value
3、list常用指令
## 存储数据
lpush key value # 在key对应的列表的左侧添加数据value
rpuhs key value # 在key对应的列表的右侧添加数据value
## 获取数据
lpop key # 从key对应的列表的左侧取⼀个值
rpop key # 从key对应的列表的右侧取⼀个值
## 修改数据
lset key index value #修改key对应的列表的索引位置的数据(索引从左往右,从0开始)
## 查看key对应的列表中索引从start开始到stop结束的所有值
lrange key start stop
## 查看key对应的列表中index索引对应的值
lindex key index
## 获取key对应的列表中的元素个数
llen key
## 从key对应的列表中截取key在[start,stop]范围的值,不在此范围的数据⼀律被清除掉
ltrim key start stop
## 从k1右侧取出⼀个数据存放到k2的左侧
rpoplpush k1 k2
4、set常用指令
## 存储元素 :在key对应的集合中添加元素,可以添加1个,也可以同时添加多个元素
sadd key v1 [v2 v3 v4...]
## 遍历key对应的集合中的所有元素
smembers key
## 随机从key对于听的集合中获取⼀个值(出栈)
spop key
## 交集
sinter key1 key2
## 并集
sunion key1 key2
## 差集
sdiff key1 key2
## 从key对应的集合中移出指定的value
srem key value
## 检查key对应的集合中是否有指定的value
sismember key value
5、zset常用指令
- zset 有序不可重复集合
## 存储数据(score存储位置必须是数值,可以是float类型的任意数字;member元素不允许重复)
zadd key score member [score member...]
## 查看key对应的有序集合中索引[start,stop]数据——按照score值由⼩到⼤(start 和 stop指的不是score,⽽是元素在有序集合中的索引)
zrange key start top
##查看member元素在key对应的有序集合中的索引
zscore key member
## 获取key对应的zset中的元素个数
zcard key
## 获取key对应的zset中,score在[min,max]范围内的member个数
zcount key min max
## 从key对应的zset中移除指定的member
zrem key6 member
## 查看key对应的有序集合中索引[start,stop]数据——按照score值由⼤到⼩
zrevrange key start stop
6、key相关指令
## 查看redis中满⾜pattern规则的所有的key(keys *)
keys pattern
## 查看指定的key谁否存在
exists key
## 删除指定的key-value对
del key
## 获取当前key的存活时间(如果没有设置过期返回-1,设置过期并且已经过期返回-2)
ttl key
## 设置键值对过期时间
expire key seconds
pexpire key milliseconds
## 取消键值对过期时间
persist key
7、db常用指令
- redis的键值对是存储在数据库中的——db
- redis中默认有16个db,编号 0-15
## 切换数据库
select index
## 将键值对从当前db移动到⽬标db
move key index
## 清空当前数据库数据
flushdb
## 清所有数据库的k-v
flushall
## 查看当前db中k-v个数
dbsize
## 获取最后⼀次持久化操作时间
lastsave
四、Redis的持久化
Redis是基于内存操作,但作为⼀个数据库也具备数据的持久化能力;但是为了实现高效的读写操作,并不会即时进行数据的持久化,而是按照⼀定的规则进行持久化操作的——持久化策略
- Redis提供了两中持久化策略:
- RDB (Redis DataBase)
- AOF(Append Only File)
1、RDB
在满足特定的redis操作条件时,将内存中的数据以
数据快照的形式存储到rdb文件中
-
原理:
RDB是redis默认的持久化策略,当redis中的写操作达到指定的次数、同时距离上⼀次持久化达到指定的时间就会将redis内存中的数据生成数据快照,保存在指定的rdb文件中。 -
默认触发持久化条件:
900s 1次:当操作次数达到1次,900s就会进行持久化300s 10次:当操作次数达到10次,300s就会进行持久化60s 10000次:当操作次数达到10000次,60s就会进行持久化
-
我们可以通过修改
redis.conf⽂件,来设置RDB策略的触发条件:## rdb持久化开关 rdbcompression yes ## 配置redis的持久化策略 save 900 1 save 300 10 save 60 10000 ## 指定rdb数据存储的⽂件 dbfilename dump.rdb -
RED持久化细节分析:
缺点- 如果redis出现故障,存在数据丢失的风险,丢失上⼀次持久化之后的操作数据;
- RDB采用的是数据快照形式进行持久化,不适合实时性持久化;
- 如果数据量巨大,在RDB持久化过程中⽣成数据快照的子进程执行时间过长,会导致redis卡顿,因此save时间周期设置不宜过短;
优点
- 但是在数据量较小的情况下,执比速度⽐较快;
- 由于RDB是以数据快照的形式进行保存的,我们可以通过拷贝rdb文件轻松实现redis数据移植
2、AOF
Apeend Only File,当达到设定触发条件时,将redis执行的
写操作指令存储在aof文件中,Redis默认未开启aof持久化
-
原理:
Redis将每⼀个成功的写操作写入到aof文件中,当redis重启的时候就执行aof文件中的指令以恢复数据 -
配置:
## 开启AOF appendonly yes ## 设置触发条件(三选⼀) appendfsync always ## 只要进⾏成功的写操作,就执⾏aof appendfsync everysec ## 每秒进⾏⼀次aof appendfsync no ## 让redis执⾏决定aof ## 设置aof⽂件路径 appendfilename "appendonly.aof" -
AOF细节分析:
- 也可以通过拷贝aof文件进行redis数据移植
- aof存储的指令,而且会对指令进行整理;而RDB直接生成数据快照,在数据量不大时RDB比较快
- aof是对指令文件进行增量更新,更适合实时性持久化
- redis官方建议同时开启2中持久化策略,如果同时存在aof文件和rdb文件的情况下aof优先
五、Java应用连接Redis
1、设置redis允许远程连接
Java应用连接Redis,首先要将我们的Redis设置允许远程连接;
注意:放行6379端口
- 修改
redis.conf
## 关闭保护模式
protected-mode no
## 将bind注释掉(如果不注释,默认为 bind 127.0.0.1 只能本机访问)
# bind 127.0.0.1
## 密码可以设置(也可以不设置)
# requirepass 123456
- 重启redis
redis-server redis.conf
2、在普通Maven工程连接Redis
使用jedis客户端连接
- 添加Jedis依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.4.0</version>
</dependency>
- 使用案例
public static void main (String[] args) {
//1.连接redis
Jedis jedis = new Jedis("127.0.0.1", 6379);
//2.操作
String s = jedis.set("key1", new Gson().toJson(value));
System.out.println(s);
//3.关闭连接
jedis.close();
}
- redis远程可视化客户端
-
Redis desktop manager
-
github地址:https://github.com/uglide/RedisDesktopManager/releases
-
3、在SpringBoot工程连接Redis
- 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
-
配置redis
application.yml文件件配置redis的连接信息
spring: redis: host: 127.0.0.1 port: 6379 database: 0 password: -
使用redis客户端连接redis
直接在service中注入RedisTemplate或者StringRedisTemplate,就可以使用此对象完成redis操作
4、Spring Data Redis
- 不同数据结构的添加操作
//1.string
//添加数据 set key value
stringRedisTemplate.boundValueOps("str")).set(jsonstr);
//2.hash
stringRedisTemplate.boundHashOps("hash").put("keyId", jsonstr);
//3.list
stringRedisTemplate.boundListOps("list").leftPush("AAA");
//4.set
stringRedisTemplate.boundSetOps("s1").add("v1");
//5.zset
stringRedisTemplate.boundZSetOps("z1").add("v1", 1.2);
- string类型的操作方法
//添加数据 set key value
stringRedisTemplate.boundValueOps("k1").set(jsonstr);
//添加数据时指定过期时间 setex key 300 value
stringRedisTemplate.boundValueOps("101").set(jsonstr, 300);
//设置指定key的过期时间 expire key 20
stringRedisTemplate.boundValueOps("102").expire(20, TimeUnit.SECONDS);
//添加数据 setnx key value
Boolean absent = stringRedisTemplate.boundValueOps("103").setIfAbsent(jsonstr);
- 不同数据类型的取值操作
//string
String o = stringRedisTemplate.boundValueOps("101").get();
//hash
Object v = stringRedisTemplate.boundHashOps("hash").get("101");
//list
String s1 = stringRedisTemplate.boundListOps("list").leftPop();
String s2 = stringRedisTemplate.boundListOps("list").rightPop();
String s3 = stringRedisTemplate.boundListOps("list").index(1);
//set
Set<String> vs = stringRedisTemplate.boundSetOps("s1").members();
//zset
Set<String> vs2 = stringRedisTemplate.boundZSetOps("z1").range(0, 5);
六、使用Redis做缓存存在的问题
使用redis做为缓存在高并发场景下有可能出现缓存击穿、缓存穿透、缓存雪崩等问题
1、 缓存击穿
大量的并发请求同时访问同⼀个在redis中不存在的数据,就会导致⼤量的请求绕过redis同时并发访问数据库,对数据库造成了高并发访问压⼒。
解决方案:使用 双重检测锁 解决缓存击穿问题。
2、缓存穿透
大量的请求⼀个数据库中不存在的数据,首先在redis中无法命中,最终所有的请求都会访问数据库,同样会导致数据库承受巨大的访问压力。
解决方案:当从数据库查询到⼀个null时,写⼀个非空的数据到redis,并设置过期时间。
3、缓存雪崩
缓存大量的数据集中过期,导致请求这些数据的大量的并发请求会同时访问数据库。
解决方案:
- ① 将缓存中的数据设置成不同的过期时间;
- ② 在访问洪峰到达前缓存热点数据,过期时间设置到流量最低的时段。
七、Redis高级应用
使用redis作为缓存数据库使用目的是为了提升数据加载速度、降低对数据库的访问压力,我们需要保证redis的可用性。
- 主从配置
- 哨兵模式
- 集群配置
1、主从配置
在多个redis实例建立起主从关系,当
主redis中的数据发生变化,从redis中的数据也会同步变化。
- 通过主从配置可以实现redis数据的备份(
从redis就是对主redis的备份),保证数据的安全性; - 通过主从配置可以实现redis的读写分离
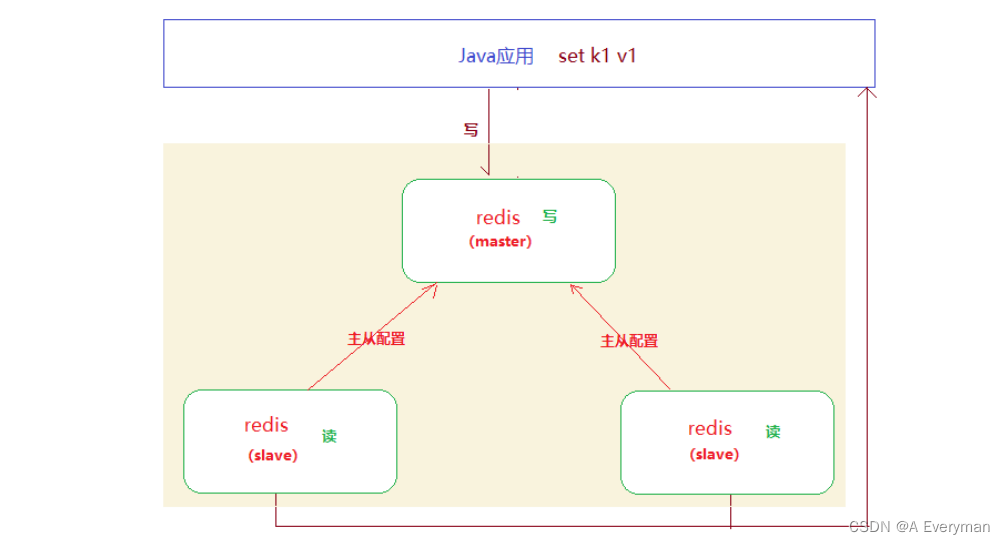
主从配置示例 - 启动三个redis实例
## 在redis⽬录下创建 msconf ⽂件夹
[root@redis]# mkdir msconf
## 拷⻉redis.conf⽂件 到 msconf⽂件夹 ---> redis-master.conf
[root@redis]# cat redis.conf |grep -v "#" | grep -v "^$" > msconf/redis-master.conf
## 修改 redis-master.conf 端⼝及远程访问设置
[root@redis]# vim redis-master.conf
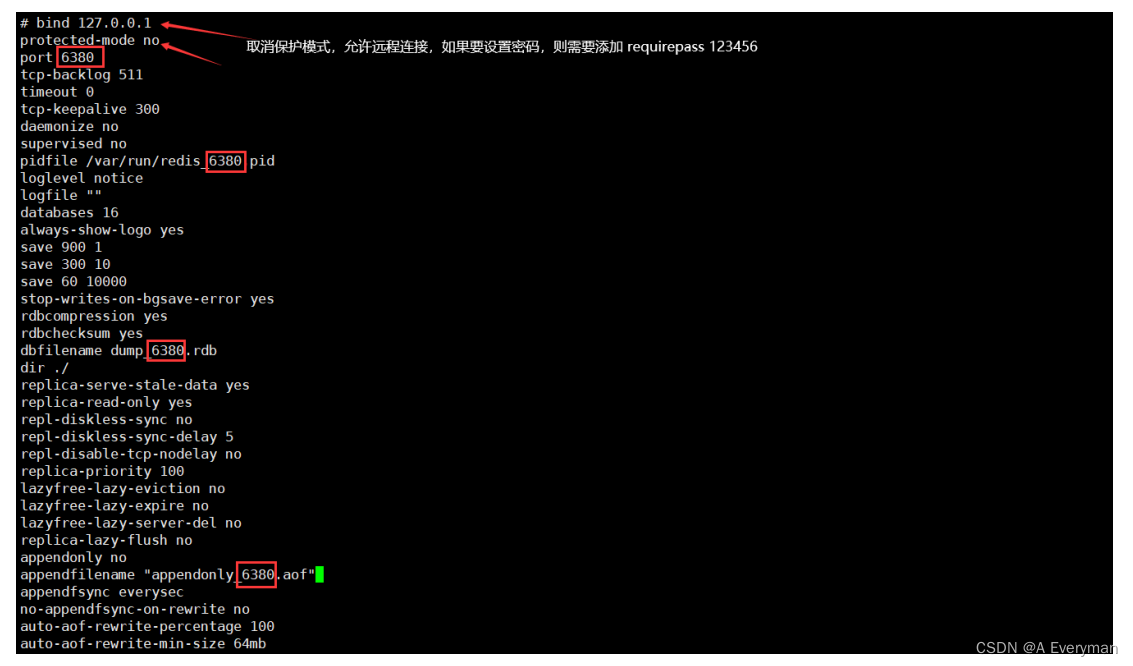
# 将 redis-master.conf 拷⻉两份分别为:redis-slave1.conf redis-slave2.conf
[root@msconf]# sed 's/6380/6381/g' redis-master.conf > redis-slave1.conf
[root@msconf]# sed 's/6380/6382/g' redis-master.conf > redis-slave2.conf
## 修改redis-slave1.conf redis-slave2.conf,设置“跟从”---127.0.0.1 6380
[root@msconf]# vim redis-slave1.conf
[root@msconf]# vim redis-slave2.conf

## 启动三个redis实例
[root@msconf]# redis-server redis-master.conf &
[root@msconf]# redis-server redis-slave1.conf &
[root@msconf]# redis-server redis-slave2.conf &
2、哨兵模式
⽤于监听主库,当确认主库宕机之后,从备库(从库)中选举⼀个转备为主
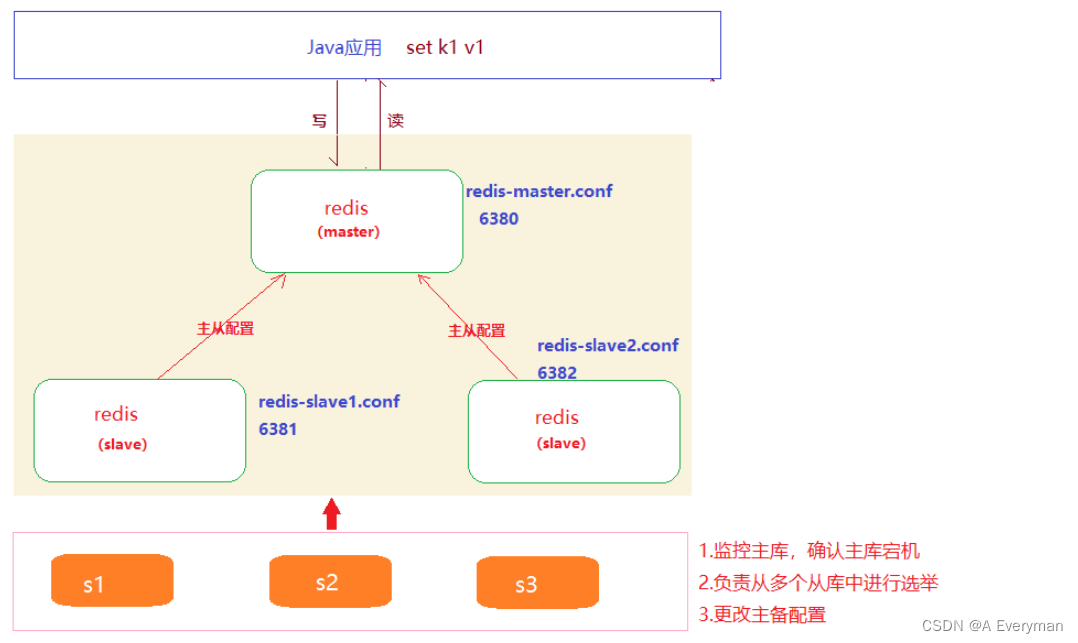
- 哨兵模式配置
##⾸先实现三个redis实例之间的主从配置(如上)
## 创建并启动三个哨兵
## 拷⻉sentinel.conf⽂件三份:sentinel-26380.conf sentinel-26382.conf sentinel-26382.conf
## 创建sentinelconf⽬录
[root@redis]# mkdir sentinelconf
## 拷⻉sentinel.conf⽂件到 sentinelconf⽬录:sentinel-26380.conf
[root@redis]# cat sentinel.conf | grep -v "#" | grep -v "^$" > sentinelconf/sentinel-26380.conf
[root@redis]# cd sentinelconf/
## 编辑 sentinelconf/sentinel-26380.conf⽂件
[root@sentinelconf]# vim sentinel-26380.conf
port 26380
daemonize no
pidfile "/var/run/redis-sentinel-26380.pid"
logfile ""
dir "/tmp"
sentinel deny-scripts-reconfig yes
# 此处配置默认的主库的ip 和端⼝ 最后的数字是哨兵数量的⼀半多⼀个
sentinel monitor mymaster 127.0.0.1 6380 2
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
protected-mode no
[root@sentinelconf]# sed 's/26380/26381/g' sentinel-26380.conf >sentinel-26381.conf
[root@sentinelconf]# sed 's/26380/26382/g' sentinel-26380.conf >sentinel-26382.conf
- 测试:
启动 主redis
启动 备1redis
启动 备2redis
再依次启动三个哨兵:
[root@sentinelconf]# redis-sentinel sentinel-26380.conf
3、集群配置
高可用:保证redis⼀直处于可用状态,即时出现了故障也有备用方案保证可用性
高并发:⼀个redis实例已经可以⽀持多达11w并发读操作或者8.1w并发写操作;但是如果对于有更高并发需求的应用来说,我们可以通过读写分离 、 集群配置来解决高并发问题
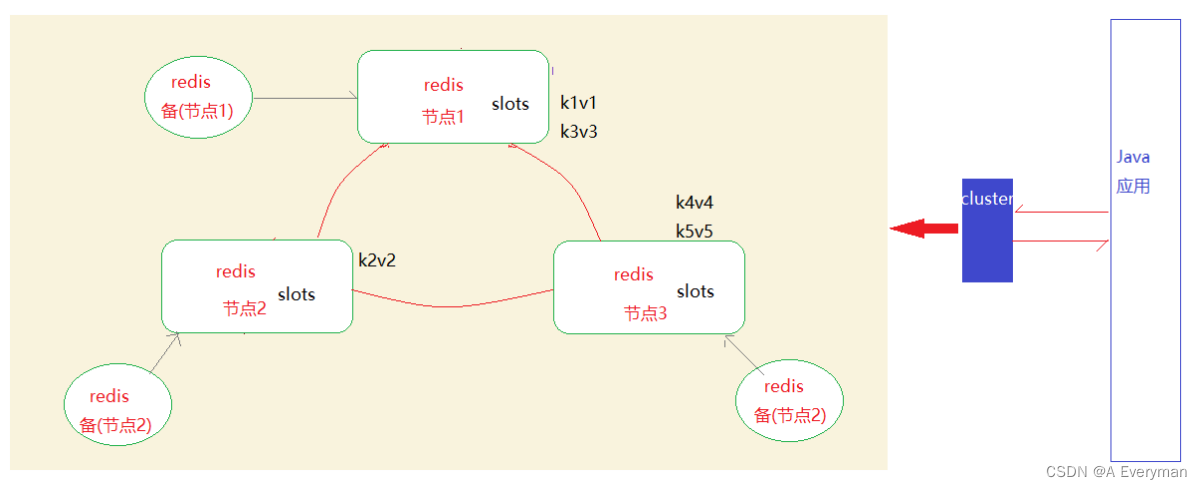
Redis集群
- Redis集群中每个节点是对等的,无中心结构
- 数据按照slots分布式存储在不同的redis节点上,节点中的数据可共享,可以动态调整数据的分布
- 可扩展性强,可以动态增删节点,最多可扩展⾄1000+节点
- 集群每个节点通过主备(哨兵模式)可以保证其高可用性
3.1、集群搭建
[root@~]# cd /usr/local/redis
[root@redis]# mkdir cluster-conf
[root@redis]# cat redis.conf | grep -v "#"|grep -v "^$" > cluster-conf/redis-7001.conf
[root@redis]# cd cluster-conf/
[root@cluster-conf]# ls
redis-7001.conf
[root@cluster-conf]# vim redis-7001.conf

- 拷贝6个⽂件,端口分别为 7001-7006
[root@cluster-conf]# sed 's/7001/7002/g' redis-7001.conf > redis-7002.conf
[root@cluster-conf]# sed 's/7001/7003/g' redis-7001.conf > redis-7003.conf
[root@cluster-conf]# sed 's/7001/7004/g' redis-7001.conf > redis-7004.conf
[root@cluster-conf]# sed 's/7001/7005/g' redis-7001.conf > redis-7005.conf
[root@cluster-conf]# sed 's/7001/7006/g' redis-7001.conf > redis-7006.con
- 启动6个redis实例
[root@cluster-conf]# redis-server redis-7001.conf &
[root@cluster-conf]# redis-server redis-7002.conf &
[root@cluster-conf]# redis-server redis-7003.conf &
[root@cluster-conf]# redis-server redis-7004.conf &
[root@cluster-conf]# redis-server redis-7005.conf &
[root@cluster-conf]# redis-server redis-7006.conf &
- 查看6个实例是否启动
[root@cluster-conf]# ps -ef|grep redis
- 启动集群
[root@cluster-conf]# redis-cli --cluster create 47.96.11.185:7001 47.96.11.185:7002 47.96.11.185:7003 47.96.11.185:7004 47.96.11.185:7005 47.96.11.185:7006 --cluster-replicas 1
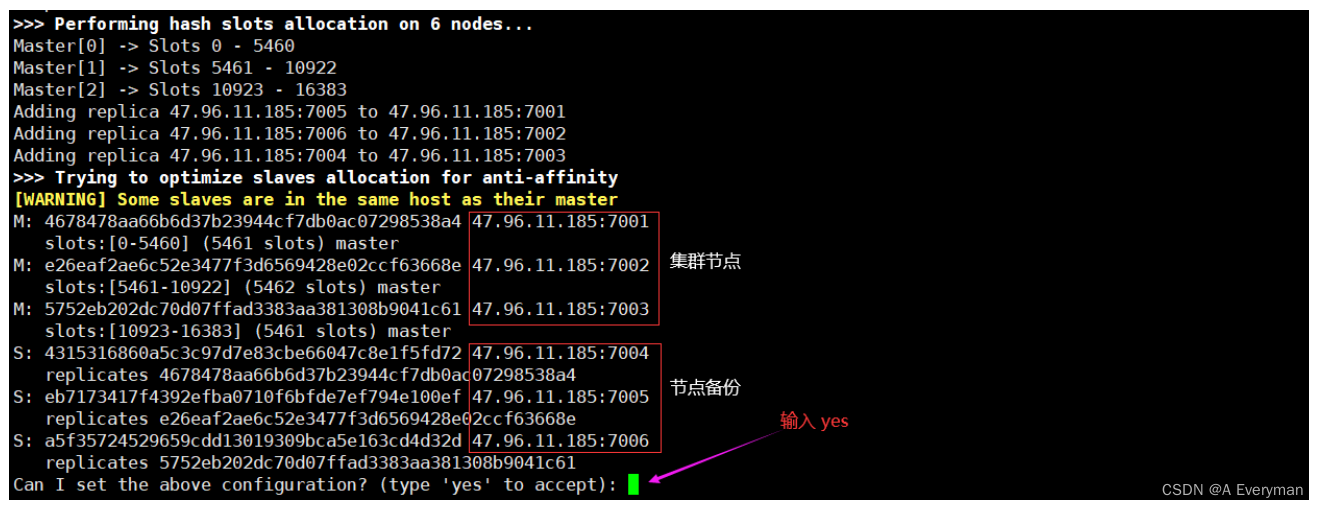
- 连接集群
[root@cluster-conf]# redis-cli -p 7001 -c
3.2、集群管理
- 如果集群启动失败:等待节点加⼊
- 云服务器检查安全组是否放行redis实例端⼝,以及+10000的端⼝
- Linux防火墙是否放行redis服务(关闭防火墙)
- Linux状态(top)---- 更换云主机操作系统
- redis配置文件错误
- 创建集群:
[root@theo cluster-conf]# redis-cli --cluster create 47.96.11.185:7001 47.96.11.185:7002 47.96.11.185:7003 47.96.11.185:7004 47.96.11.185:7005 47.96.11.185:7006 --clusterreplicas 1
- 查看集群状态
[root@theo cluster-conf]# redis-cli --cluster info 47.96.11.185:7001
47.96.11.185:7001 (4678478a...) -> 2 keys | 5461 slots | 1 slaves.
47.96.11.185:7002 (e26eaf2a...) -> 0 keys | 5462 slots | 1 slaves.
47.96.11.185:7003 (5752eb20...) -> 1 keys | 5461 slots | 1 slaves.
[OK] 3 keys in 3 masters.
0.00 keys per slot on average.
- 平衡节点的数据槽数
[root@theo cluster-conf]# redis-cli --cluster rebalance 47.96.11.185:7001
>>> Performing Cluster Check (using node 47.96.11.185:7001)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold.
- 迁移节点槽
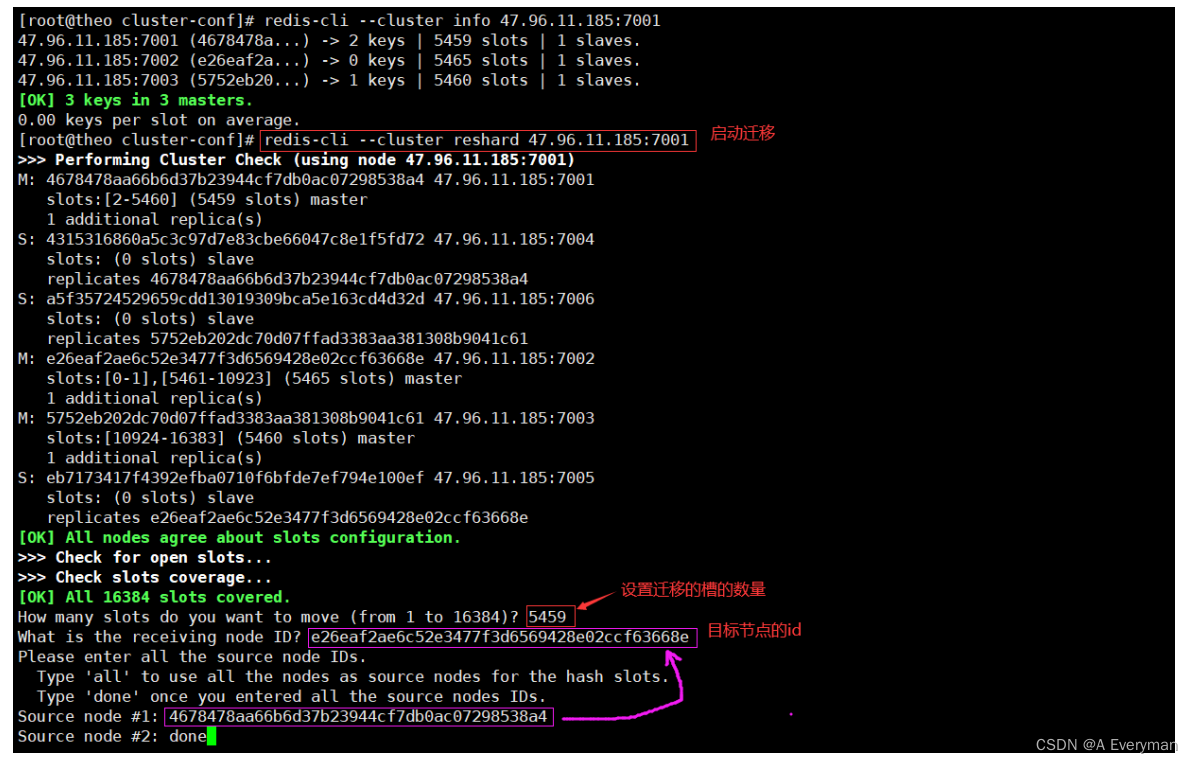
- 删除节点
[root@theo cluster-conf]# redis-cli --cluster del-node 47.96.11.185:7001 4678478aa66b6d37b23944cf7db0ac07298538a4
>>> Removing node 4678478aa66b6d37b23944cf7db0ac07298538a4 from
cluster 47.96.11.185:7001
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
[root@theo cluster-conf]# redis-cli --cluster info 47.96.11.185:7002
47.96.11.185:7002 (e26eaf2a...) -> 1 keys | 8192 slots | 2 slaves.
47.96.11.185:7003 (5752eb20...) -> 2 keys | 8192 slots | 1 slaves.
[OK] 3 keys in 2 masters.
0.00 keys per slot on average.
- 添加节点
[root@theo cluster-conf]# redis-cli --cluster add-node 47.96.11.185:7007 47.96.11.185:7002
3.3、SpringBoot应用配置集群
spring:
redis:
cluster:
nodes: 47.96.11.185:7001,47.96.11.185:7002,47.96.11.185:7003
max-redirects: 3
八、Redis淘汰策略
Redis是基于内存结构进⾏数据缓存的,当内存资源消耗完毕,想要有新的数据缓存进来,必然要从Redis的内存结构中释放⼀些数据。如何进行数据的释放呢?----Redis的淘汰策略
Redis提供的 8 种淘汰策略
# volatile-lru -> 从设置了过期时间的数据中淘汰最久未使⽤的数据.
# allkeys-lru -> 从所有数据中淘汰最久未使⽤的数据.
# volatile-lfu -> 从设置了过期时间的数据中淘汰使⽤最少的数据.
# allkeys-lfu -> 从所有数据中淘汰使⽤最少的数据.
# volatile-random -> 从设置了过期时间的数据中随机淘汰⼀批数据.
# allkeys-random -> 从所有数据中随机淘汰⼀批数据.
# volatile-ttl -> 淘汰过期时间最短的数据.
# noeviction -> 不淘汰任何数据,当内存不够时直接抛出异常.
理解两个算法名词:
LRU最久最近未使用LFU最近最少使用
















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









