






一、Python
1.Pytorch训练图像分类模型
… …
2.Pytorch图像分类模型转ONNX
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/3/16 13:15
# @Author : LingJiaXiaoHu
# @File : main.py
# @Software: win11 pytorch(GPU版本) python3.9.16
# 1.导入工具包
import torch
from torchvision import models
# 2.有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
# 3.载入ImageNet预训练PyTorch图像分类模型
#model = models.resnet18(pretrained=True)
model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT) # 新的用法
model = model.eval().to(device)
# 4.构造一个输入图像Tensor
x = torch.randn(1, 3, 256, 256).to(device)
# 5.输入Pytorch模型推理预测,获得1000个类别的预测结果
output = model(x)
output.shape
# 6.Pytorch模型转ONNX格式
with torch.no_grad():
torch.onnx.export(
model, # 要转换的模型
x, # 模型的任意一组输入
'resnet18_imagenet.onnx', # 导出的 ONNX 文件名
opset_version=11, # ONNX 算子集版本
input_names=['input'], # 输入 Tensor 的名称(自己起名字)
output_names=['output'] # 输出 Tensor 的名称(自己起名字)
)
# 7.验证onnx模型导出成功
import onnx
# 读取 ONNX 模型
onnx_model = onnx.load('resnet18_imagenet.onnx')
# 检查模型格式是否正确
onnx.checker.check_model(onnx_model)
print('无报错,onnx模型载入成功')
# 8.以可读的形式打印计算图
print(onnx.helper.printable_graph(onnx_model.graph))
# 使用Netron可视化模型结构
# Netron:https://netron.app
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/3/16 13:24
# @Author : LingJiaXiaoHu
# @File : main.py
# @Software: win11 pytorch(GPU版本) python3.9.16
# 1.导入工具包
import torch
from torchvision import models
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
# 2.导入训练好的模型
model = torch.load('checkpoint/fruit30_pytorch_20220814.pth')
model = model.eval().to(device)
# 3.构造一个输入图像Tensor
x = torch.randn(1, 3, 256, 256).to(device)
# 4.输入Pytorch模型推理预测,获得30个类别的预测结果
output = model(x)
print(output.shape)
# 5.Pytorch模型转ONNX模型
x = torch.randn(1, 3, 256, 256).to(device)
with torch.no_grad():
torch.onnx.export(
model, # 要转换的模型
x, # 模型的任意一组输入
'resnet18_fruit30.onnx', # 导出的 ONNX 文件名
opset_version=11, # ONNX 算子集版本
input_names=['input'], # 输入 Tensor 的名称(自己起名字)
output_names=['output'] # 输出 Tensor 的名称(自己起名字)
)
# 6.验证onnx模型导出成功
import onnx
# 读取 ONNX 模型
onnx_model = onnx.load('resnet18_fruit30.onnx')
# 检查模型格式是否正确
onnx.checker.check_model(onnx_model)
print('无报错,onnx模型载入成功')
# 7.以可读的形式打印计算图
print(onnx.helper.printable_graph(onnx_model.graph))
# 使用Netron可视化模型结构
# Netron:https://netron.app
3.ONNX Runtime部署图像分类模型
3.1预测单张图片
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/3/16 13:57
# @Author : LingJiaXiaoHu
# @File : 预测单张图像.py
# @Software: win11 pytorch(GPU版本) python3.9.16
# 1.导入工具包
import onnxruntime
import numpy as np
from PIL import Image
import torch
import torch.nn.functional as F
from torch import tensor
from torchvision import transforms
# 2.载入 onnx 模型,获取 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession('resnet18_fruit30.onnx')
# 3.构造输入,获取输出结果
x = torch.randn(1, 3, 256, 256).numpy()
print(x.shape)
# onnx runtime 输入
ort_inputs = {'input': x}
# onnx runtime 输出
ort_output = ort_session.run(['output'], ort_inputs)[0]
#注意,输入输出张量的名称需要和 torch.onnx.export 中设置的输入输出名对应
print(ort_output.shape)
# 4.预处理
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 5.载入测试图像
img_path = 'test_bananan.jpg'
# 用 pillow 载入
img_pil = Image.open(img_path)
print(img_pil)
# 6.运行预处理
input_img = test_transform(img_pil)
print(input_img.shape)
torch.Size([3, 256, 256])
input_tensor = input_img.unsqueeze(0).numpy()
print(input_tensor.shape)
# 7.ONNX Runtime预测
# ONNX Runtime 输入
ort_inputs = {'input': input_tensor}
# ONNX Runtime 输出
pred_logits = ort_session.run(['output'], ort_inputs)[0]
pred_logits = torch.tensor(pred_logits)
print(pred_logits.shape)
torch.Size([1, 30])
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
print(pred_softmax.shape)
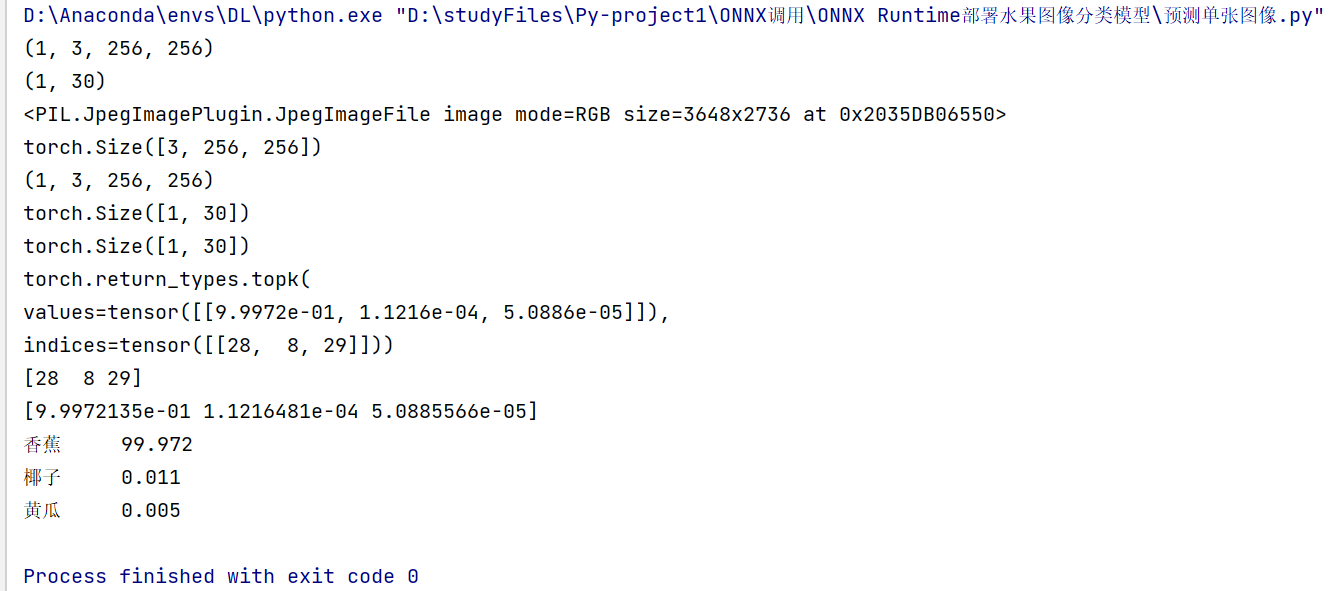
# 8.解析预测结果
# 取置信度最大的 n 个结果
n = 3
top_n = torch.topk(pred_softmax, n)
print(top_n)
# 预测类别
pred_ids = top_n.indices.numpy()[0]
print(pred_ids)
# 预测置信度
confs = top_n.values.numpy()[0]
print(confs)
# 9.打印预测结果
# 载入类别和对应 ID
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
# print(idx_to_labels)
for i in range(n):
class_name = idx_to_labels[pred_ids[i]] # 获取类别名称
confidence = confs[i] * 100 # 获取置信度
text = '{:<6} {:>.3f}'.format(class_name, confidence)
print(text)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/3/16 13:57
# @Author : LingJiaXiaoHu
# @File : 预测单张图像.py
# @Software: win11 pytorch(GPU版本) python3.9.16
# 1.导入工具包
import onnxruntime
import numpy as np
from PIL import Image
import torch
import torch.nn.functional as F
from torch import tensor
from torchvision import transforms
import pandas as pd
# 2.载入 onnx 模型,获取 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession('resnet18_imagenet.onnx')
# 3.构造输入,获取输出结果
x = torch.randn(1, 3, 256, 256).numpy()
print(x.shape)
# onnx runtime 输入
ort_inputs = {'input': x}
# onnx runtime 输出
ort_output = ort_session.run(['output'], ort_inputs)[0]
#注意,输入输出张量的名称需要和 torch.onnx.export 中设置的输入输出名对应
print(ort_output.shape)
# 4.预处理
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 5.载入测试图像
img_path = 'banana1.jpg'
# 用 pillow 载入
img_pil = Image.open(img_path)
print(img_pil)
# 6.运行预处理
input_img = test_transform(img_pil)
print(input_img.shape)
torch.Size([3, 256, 256])
input_tensor = input_img.unsqueeze(0).numpy()
print(input_tensor.shape)
# 7.ONNX Runtime预测
# ONNX Runtime 输入
ort_inputs = {'input': input_tensor}
# ONNX Runtime 输出
pred_logits = ort_session.run(['output'], ort_inputs)[0]
pred_logits = torch.tensor(pred_logits)
print(pred_logits.shape)
torch.Size([1, 30])
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
print(pred_softmax.shape)
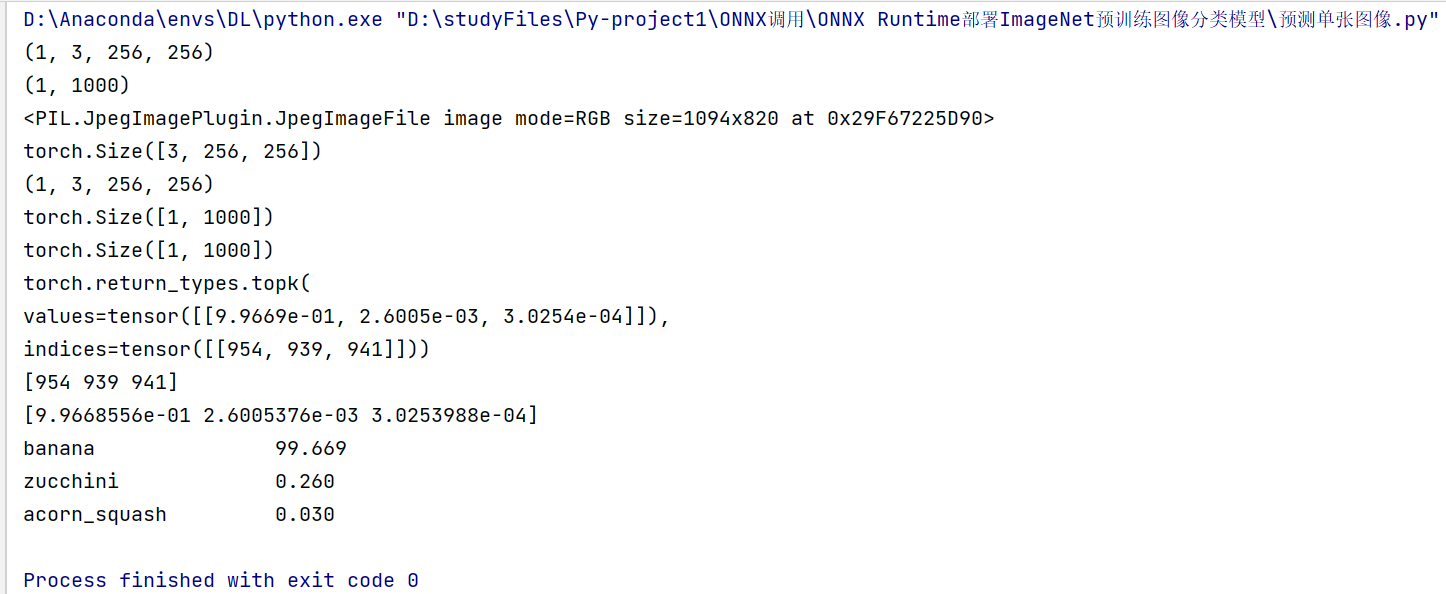
# 8.解析预测结果
# 取置信度最大的 n 个结果
n = 3
top_n = torch.topk(pred_softmax, n)
print(top_n)
# 预测类别
pred_ids = top_n.indices.numpy()[0]
print(pred_ids)
# 预测置信度
confs = top_n.values.numpy()[0]
print(confs)
# 9.打印预测结果
# 载入类别 ID 和 类别名称 对应关系
df = pd.read_csv('imagenet_class_index.csv')
idx_to_labels = {}
for idx, row in df.iterrows():
idx_to_labels[row['ID']] = row['class'] # 英文
# idx_to_labels[row['ID']] = row['Chinese'] # 中文
#print(idx_to_labels)
# 分别用英文和中文打印预测结果
for i in range(n):
class_name = idx_to_labels[pred_ids[i]] # 获取类别名称
confidence = confs[i] * 100 # 获取置信度
text = '{:<20} {:>.3f}'.format(class_name, confidence)
print(text)
3.2预测摄像头或视频
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/3/16 13:40
# @Author : LingJiaXiaoHu
# @File : 摄像头和视频-中文.py
# @Software: win11 pytorch(GPU版本) python3.9.16
# 1.导入工具包
import onnxruntime
import torch
from torchvision import transforms
import torch.nn.functional as F
import pandas as pd
import numpy as np
from PIL import Image, ImageFont, ImageDraw
import matplotlib.pyplot as plt
# 2.导入中文字体
# 导入中文字体,指定字号
font = ImageFont.truetype('SimHei.ttf', 32)
# 3.载入 onnx 模型,获取 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession('resnet18_fruit30.onnx')
# 4.载入类别和ID对应字典
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
print(idx_to_labels)
# 5.图像预处理
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 6.预测摄像头单帧画面
# 6.1调用摄像头获取一帧画面
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(0)
# 打开cap
cap.open(0)
time.sleep(1)
success, img_bgr = cap.read()
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
# 6.2画面转成 RGB 的 Pillow 格式
print(img_bgr.shape)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb)
print(img_pil)
# 6.3预处理
input_img = test_transform(img_pil)
input_tensor = input_img.unsqueeze(0).numpy()
# 6.4ONNX Runtime预测
# onnx runtime 输入
ort_inputs = {'input': input_tensor}
# onnx runtime 输出
pred_logits = ort_session.run(['output'], ort_inputs)[0]
pred_logits = torch.tensor(pred_logits)
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
print(pred_softmax.shape)
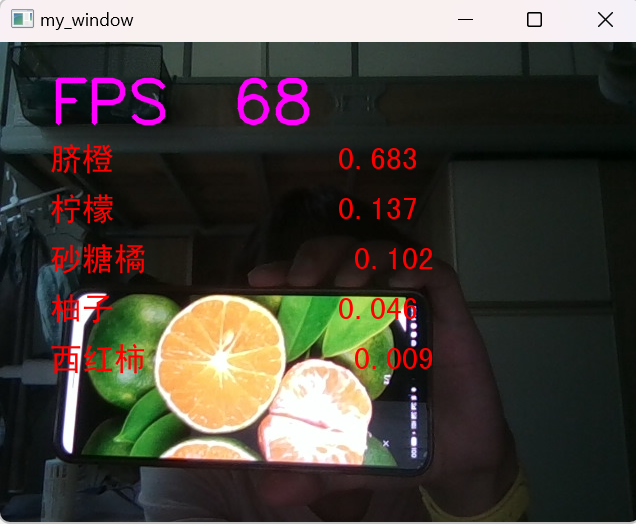
# 6.5解析top-n预测结果的类别和置信度
n = 5
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
# 6.6在图像上写中文
draw = ImageDraw.Draw(img_pil)
# 在图像上写字
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img = np.array(img_pil) # PIL 转 array
plt.imshow(img)
plt.show()
# 6.7.处理单帧画面的函数(中文)
# 处理帧函数
def process_frame(img):
'''
输入摄像头拍摄画面bgr-array,输出图像分类预测结果bgr-array
'''
# 记录该帧开始处理的时间
start_time = time.time()
## 画面转成 RGB 的 Pillow 格式
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb) # array 转 PIL
## 预处理
input_img = test_transform(img_pil) # 预处理
input_tensor = input_img.unsqueeze(0).numpy()
## onnx runtime 预测
ort_inputs = {'input': input_tensor} # onnx runtime 输入
pred_logits = ort_session.run(['output'], ort_inputs)[0] # onnx runtime 输出
pred_logits = torch.tensor(pred_logits)
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
## 解析top-n预测结果的类别和置信度
n = 5
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
## 在图像上写中文
draw = ImageDraw.Draw(img_pil)
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img = np.array(img_pil) # PIL 转 array
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) # RGB转BGR
# 记录该帧处理完毕的时间
end_time = time.time()
# 计算每秒处理图像帧数FPS
FPS = 1 / (end_time - start_time)
# 图片,添加的文字,左上角坐标,字体,字体大小,颜色,线宽,线型
img = cv2.putText(img, 'FPS ' + str(int(FPS)), (50, 80), cv2.FONT_HERSHEY_SIMPLEX, 2, (255, 0, 255), 4,
cv2.LINE_AA)
return img
# 6.8.调用摄像头获取每帧(模板)
# 调用摄像头逐帧实时处理模板
# 不需修改任何代码,只需修改process_frame函数即可
# 同济子豪兄 2021-7-8
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
# 无限循环,直到break被触发
while cap.isOpened():
# 获取画面
success, frame = cap.read()
if not success:
print('Error')
break
## !!!处理帧函数
frame = process_frame(frame)
# 展示处理后的三通道图像
cv2.imshow('my_window', frame)
if cv2.waitKey(1) in [ord('q'), 27]: # 按键盘上的q或esc退出(在英文输入法下)
break
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
# 按键盘上的q键退出
# 6.9.视频逐帧处理(模板)
import cv2
import numpy as np
import time
from tqdm import tqdm
# 视频逐帧处理代码模板
# 不需修改任何代码,只需定义process_frame函数即可
# 同济子豪兄 2021-7-10
def generate_video(input_path='videos/robot.mp4'):
filehead = input_path.split('/')[-1]
output_path = "out-" + filehead
print('视频开始处理', input_path)
# 获取视频总帧数
cap = cv2.VideoCapture(input_path)
frame_count = 0
while (cap.isOpened()):
success, frame = cap.read()
frame_count += 1
if not success:
break
cap.release()
print('视频总帧数为', frame_count)
# cv2.namedWindow('Crack Detection and Measurement Video Processing')
cap = cv2.VideoCapture(input_path)
frame_size = (cap.get(cv2.CAP_PROP_FRAME_WIDTH), cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# fourcc = int(cap.get(cv2.CAP_PROP_FOURCC))
# fourcc = cv2.VideoWriter_fourcc(*'XVID')
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
out = cv2.VideoWriter(output_path, fourcc, fps, (int(frame_size[0]), int(frame_size[1])))
# 进度条绑定视频总帧数
with tqdm(total=frame_count - 1) as pbar:
try:
while (cap.isOpened()):
success, frame = cap.read()
if not success:
break
# 处理帧
# frame_path = './temp_frame.png'
# cv2.imwrite(frame_path, frame)
try:
frame = process_frame(frame)
except:
print('报错!', error)
pass
if success == True:
# cv2.imshow('Video Processing', frame)
out.write(frame)
# 进度条更新一帧
pbar.update(1)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
except:
print('中途中断')
pass
cv2.destroyAllWindows()
out.release()
cap.release()
print('视频已保存', output_path)
generate_video(input_path='fruits_video.mp4')
D:\Anaconda\envs\DL\python.exe "D:\studyFiles\Py-project1\ONNX调用\ONNX Runtime部署水果图像分类模型\摄像头和视频-中文.py"
{0: '哈密瓜', 1: '圣女果', 2: '山竹', 3: '杨梅', 4: '柚子', 5: '柠檬', 6: '桂圆', 7: '梨', 8: '椰子', 9: '榴莲', 10: '火龙果', 11: '猕猴桃', 12: '石榴', 13: '砂糖橘', 14: '胡萝卜', 15: '脐橙', 16: '芒果', 17: '苦瓜', 18: '苹果-红', 19: '苹果-青', 20: '草莓', 21: '荔枝', 22: '菠萝', 23: '葡萄-白', 24: '葡萄-红', 25: '西瓜', 26: '西红柿', 27: '车厘子', 28: '香蕉', 29: '黄瓜'}
(480, 640, 3)
<PIL.Image.Image image mode=RGB size=640x480 at 0x1A765905AC0>
torch.Size([1, 30])
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/3/16 13:40
# @Author : LingJiaXiaoHu
# @File : 摄像头和视频-中文.py
# @Software: win11 pytorch(GPU版本) python3.9.16
# 1.导入工具包
import onnxruntime
import torch
from torchvision import transforms
import torch.nn.functional as F
import pandas as pd
import numpy as np
from PIL import Image, ImageFont, ImageDraw
import matplotlib.pyplot as plt
# 2.导入中文字体
# 导入中文字体,指定字号
font = ImageFont.truetype('SimHei.ttf', 32)
# 3.载入 onnx 模型,获取 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession('resnet18_imagenet.onnx')
# 4.载入类别和ID对应字典
# 载入ImageNet 1000图像分类标签
df = pd.read_csv('imagenet_class_index.csv')
idx_to_labels = {}
for idx, row in df.iterrows():
idx_to_labels[row['ID']] = row['Chinese']
print(idx_to_labels)
# 5.图像预处理
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 6.预测摄像头单帧画面
# 6.1调用摄像头获取一帧画面
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(0)
# 打开cap
cap.open(0)
time.sleep(1)
success, img_bgr = cap.read()
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
# 6.2画面转成 RGB 的 Pillow 格式
print(img_bgr.shape)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb)
print(img_pil)
# 6.3预处理
input_img = test_transform(img_pil)
input_tensor = input_img.unsqueeze(0).numpy()
# 6.4ONNX Runtime预测
# onnx runtime 输入
ort_inputs = {'input': input_tensor}
# onnx runtime 输出
pred_logits = ort_session.run(['output'], ort_inputs)[0]
pred_logits = torch.tensor(pred_logits)
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
print(pred_softmax.shape)
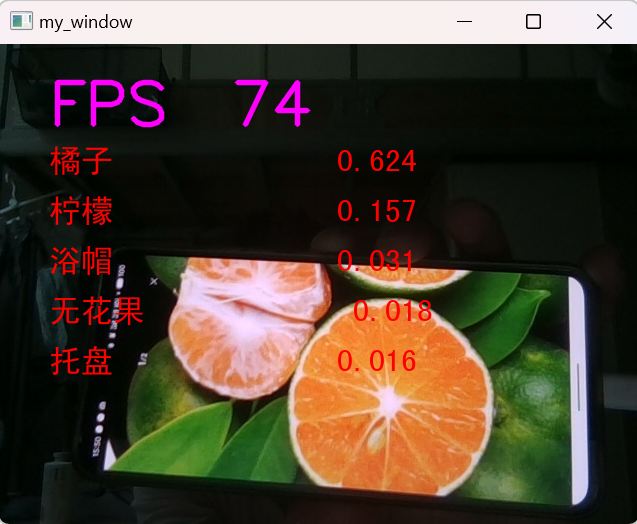
# 6.5解析top-n预测结果的类别和置信度
n = 5
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
# 6.6在图像上写中文
draw = ImageDraw.Draw(img_pil)
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
# 写中文:文字坐标,中文字符串,字体,rgba颜色
text = '{:<15} {:>.3f}'.format(pred_class, confs[i]) # 中文字符串
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img_rgb = np.array(img_pil) # PIL 转 array
plt.imshow(img_rgb)
plt.show()
# 6.7.处理单帧画面的函数(中文)
# 处理帧函数
# 处理帧函数
def process_frame(img_bgr):
# 记录该帧开始处理的时间
start_time = time.time()
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb) # array 转 PIL
## 预处理
input_img = test_transform(img_pil) # 预处理
input_tensor = input_img.unsqueeze(0).numpy()
## onnx runtime 预测
ort_inputs = {'input': input_tensor} # onnx runtime 输入
pred_logits = ort_session.run(['output'], ort_inputs)[0] # onnx runtime 输出
pred_logits = torch.tensor(pred_logits)
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
## 解析图像分类预测结果
n = 5
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
## 在图像上写中文
draw = ImageDraw.Draw(img_pil)
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
# 写中文:文字坐标,中文字符串,字体,rgba颜色
text = '{:<15} {:>.3f}'.format(pred_class, confs[i]) # 中文字符串
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img_rgb = np.array(img_pil) # PIL 转 array
img_bgr = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2BGR) # RGB转BGR
# 记录该帧处理完毕的时间
end_time = time.time()
# 计算每秒处理图像帧数FPS
FPS = 1 / (end_time - start_time)
# 图片,添加的文字,左上角坐标,字体,字体大小,颜色,线宽,线型
img_bgr = cv2.putText(img_bgr, 'FPS ' + str(int(FPS)), (50, 80), cv2.FONT_HERSHEY_SIMPLEX, 2, (255, 0, 255), 4,
cv2.LINE_AA)
return img_bgr
# 6.8.调用摄像头获取每帧(模板)
# 调用摄像头逐帧实时处理模板
# 不需修改任何代码,只需修改process_frame函数即可
# 同济子豪兄 2021-7-8
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
# 无限循环,直到break被触发
while cap.isOpened():
# 获取画面
success, frame = cap.read()
if not success:
print('Error')
break
## !!!处理帧函数
frame = process_frame(frame)
# 展示处理后的三通道图像
cv2.imshow('my_window', frame)
if cv2.waitKey(1) in [ord('q'), 27]: # 按键盘上的q或esc退出(在英文输入法下)
break
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
# 按键盘上的q键退出
# 6.9.视频逐帧处理(模板)
import cv2
import numpy as np
import time
from tqdm import tqdm
# 视频逐帧处理代码模板
# 不需修改任何代码,只需定义process_frame函数即可
# 同济子豪兄 2021-7-10
def generate_video(input_path='videos/robot.mp4'):
filehead = input_path.split('/')[-1]
output_path = "out-" + filehead
print('视频开始处理', input_path)
# 获取视频总帧数
cap = cv2.VideoCapture(input_path)
frame_count = 0
while (cap.isOpened()):
success, frame = cap.read()
frame_count += 1
if not success:
break
cap.release()
print('视频总帧数为', frame_count)
# cv2.namedWindow('Crack Detection and Measurement Video Processing')
cap = cv2.VideoCapture(input_path)
frame_size = (cap.get(cv2.CAP_PROP_FRAME_WIDTH), cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# fourcc = int(cap.get(cv2.CAP_PROP_FOURCC))
# fourcc = cv2.VideoWriter_fourcc(*'XVID')
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
out = cv2.VideoWriter(output_path, fourcc, fps, (int(frame_size[0]), int(frame_size[1])))
# 进度条绑定视频总帧数
with tqdm(total=frame_count - 1) as pbar:
try:
while (cap.isOpened()):
success, frame = cap.read()
if not success:
break
# 处理帧
# frame_path = './temp_frame.png'
# cv2.imwrite(frame_path, frame)
try:
frame = process_frame(frame)
except:
print('报错!', error)
pass
if success == True:
# cv2.imshow('Video Processing', frame)
out.write(frame)
# 进度条更新一帧
pbar.update(1)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
except:
print('中途中断')
pass
cv2.destroyAllWindows()
out.release()
cap.release()
print('视频已保存', output_path)
generate_video(input_path='video_4.mp4')
D:\Anaconda\envs\DL\python.exe "D:\studyFiles\Py-project1\ONNX调用\ONNX Runtime部署ImageNet预训练图像分类模型\摄像头和视频-中文.py"
{0: '丁鲷', 1: '金鱼', 2: '大白鲨', 3: '虎鲨', 4: '锤头鲨', 5: '电鳐', 6: '黄貂鱼', 7: '公鸡', 8: '母鸡', 9: '鸵鸟', 10: '燕雀', 11: '金翅雀', 12: '家朱雀', 13: '灯芯草雀', 14: '靛蓝雀,靛蓝鸟', 15: '蓝鹀', 16: '夜莺', 17: '松鸦', 18: '喜鹊', 19: '山雀', 20: '河鸟', 21: '鸢(猛禽)', 22: '秃头鹰', 23: '秃鹫', 24: '大灰猫头鹰', 25: '欧洲火蝾螈', 26: '普通蝾螈', 27: '水蜥', 28: '斑点蝾螈', 29: '蝾螈,泥狗', 30: '牛蛙', 31: '树蛙', 32: '尾蛙,铃蟾蜍,肋蟾蜍,尾蟾蜍', 33: '红海龟', 34: '皮革龟', 35: '泥龟', 36: '淡水龟', 37: '箱龟', 38: '带状壁虎', 39: '普通鬣蜥', 40: '美国变色龙', 41: '鞭尾蜥蜴', 42: '飞龙科蜥蜴', 43: '褶边蜥蜴', 44: '鳄鱼蜥蜴', 45: '毒蜥', 46: '绿蜥蜴', 47: '非洲变色龙', 48: '科莫多蜥蜴', 49: '非洲鳄,尼罗河鳄鱼', 50: '美国鳄鱼,鳄鱼', 51: '三角龙', 52: '雷蛇,蠕虫蛇', 53: '环蛇,环颈蛇', 54: '希腊蛇', 55: '绿蛇,草蛇', 56: '国王蛇', 57: '袜带蛇,草蛇', 58: '水蛇', 59: '藤蛇', 60: '夜蛇', 61: '大蟒蛇', 62: '岩石蟒蛇,岩蛇,蟒蛇', 63: '印度眼镜蛇', 64: '绿曼巴', 65: '海蛇', 66: '角腹蛇', 67: '菱纹响尾蛇', 68: '角响尾蛇', 69: '三叶虫', 70: '盲蜘蛛', 71: '蝎子', 72: '黑金花园蜘蛛', 73: '谷仓蜘蛛', 74: '花园蜘蛛', 75: '黑寡妇蜘蛛', 76: '狼蛛', 77: '狼蜘蛛,狩猎蜘蛛', 78: '壁虱', 79: '蜈蚣', 80: '黑松鸡', 81: '松鸡,雷鸟', 82: '披肩鸡,披肩榛鸡', 83: '草原鸡,草原松鸡', 84: '孔雀', 85: '鹌鹑', 86: '鹧鸪', 87: '非洲灰鹦鹉', 88: '金刚鹦鹉', 89: '硫冠鹦鹉', 90: '短尾鹦鹉', 91: '褐翅鸦鹃', 92: '蜜蜂', 93: '犀鸟', 94: '蜂鸟', 95: '鹟䴕', 96: '犀鸟', 97: '野鸭', 98: '红胸秋沙鸭', 99: '鹅', 100: '黑天鹅', 101: '大象', 102: '针鼹鼠', 103: '鸭嘴兽', 104: '沙袋鼠', 105: '考拉,考拉熊', 106: '袋熊', 107: '水母', 108: '海葵', 109: '脑珊瑚', 110: '扁形虫扁虫', 111: '线虫,蛔虫', 112: '海螺', 113: '蜗牛', 114: '鼻涕虫', 115: '海参', 116: '石鳖', 117: '鹦鹉螺', 118: '珍宝蟹', 119: '石蟹', 120: '招潮蟹', 121: '帝王蟹,阿拉斯加蟹,阿拉斯加帝王蟹', 122: '美国龙虾,缅因州龙虾', 123: '大螯虾', 124: '小龙虾', 125: '寄居蟹', 126: '等足目动物(明虾和螃蟹近亲)', 127: '白鹳', 128: '黑鹳', 129: '鹭', 130: '火烈鸟', 131: '小蓝鹭', 132: '美国鹭,大白鹭', 133: '麻鸦', 134: '鹤', 135: '秧鹤', 136: '欧洲水鸡,紫水鸡', 137: '沼泽泥母鸡,水母鸡', 138: '鸨', 139: '红翻石鹬', 140: '红背鹬,黑腹滨鹬', 141: '红脚鹬', 142: '半蹼鹬', 143: '蛎鹬', 144: '鹈鹕', 145: '国王企鹅', 146: '信天翁,大海鸟', 147: '灰鲸', 148: '杀人鲸,逆戟鲸,虎鲸', 149: '海牛', 150: '海狮', 151: '奇瓦瓦', 152: '日本猎犬', 153: '马尔济斯犬', 154: '狮子狗', 155: '西施犬', 156: '布莱尼姆猎犬', 157: '巴比狗', 158: '玩具犬', 159: '罗得西亚长背猎狗', 160: '阿富汗猎犬', 161: '猎犬', 162: '比格犬,猎兔犬', 163: '侦探犬', 164: '蓝色快狗', 165: '黑褐猎浣熊犬', 166: '沃克猎犬', 167: '英国猎狐犬', 168: '美洲赤狗', 169: '俄罗斯猎狼犬', 170: '爱尔兰猎狼犬', 171: '意大利灰狗', 172: '惠比特犬', 173: '依比沙猎犬', 174: '挪威猎犬', 175: '奥达猎犬,水獭猎犬', 176: '沙克犬,瞪羚猎犬', 177: '苏格兰猎鹿犬,猎鹿犬', 178: '威玛猎犬', 179: '斯塔福德郡牛头梗,斯塔福德郡斗牛梗', 180: '美国斯塔福德郡梗,美国比特斗牛梗,斗牛梗', 181: '贝德灵顿梗', 182: '边境梗', 183: '凯丽蓝梗', 184: '爱尔兰梗', 185: '诺福克梗', 186: '诺维奇梗', 187: '约克郡梗', 188: '刚毛猎狐梗', 189: '莱克兰梗', 190: '锡利哈姆梗', 191: '艾尔谷犬', 192: '凯恩梗', 193: '澳大利亚梗', 194: '丹迪丁蒙梗', 195: '波士顿梗', 196: '迷你雪纳瑞犬', 197: '巨型雪纳瑞犬', 198: '标准雪纳瑞犬', 199: '苏格兰梗', 200: '西藏梗,菊花狗', 201: '丝毛梗', 202: '软毛麦色梗', 203: '西高地白梗', 204: '拉萨阿普索犬', 205: '平毛寻回犬', 206: '卷毛寻回犬', 207: '金毛猎犬', 208: '拉布拉多猎犬', 209: '乞沙比克猎犬', 210: '德国短毛猎犬', 211: '维兹拉犬', 212: '英国谍犬', 213: '爱尔兰雪达犬,红色猎犬', 214: '戈登雪达犬', 215: '布列塔尼犬猎犬', 216: '黄毛,黄毛猎犬', 217: '英国史宾格犬', 218: '威尔士史宾格犬', 219: '可卡犬,英国可卡犬', 220: '萨塞克斯猎犬', 221: '爱尔兰水猎犬', 222: '哥威斯犬', 223: '舒柏奇犬', 224: '比利时牧羊犬', 225: '马里努阿犬', 226: '伯瑞犬', 227: '凯尔皮犬', 228: '匈牙利牧羊犬', 229: '老英国牧羊犬', 230: '喜乐蒂牧羊犬', 231: '牧羊犬', 232: '边境牧羊犬', 233: '法兰德斯牧牛狗', 234: '罗特韦尔犬', 235: '德国牧羊犬,德国警犬,阿尔萨斯', 236: '多伯曼犬,杜宾犬', 237: '迷你杜宾犬', 238: '大瑞士山地犬', 239: '伯恩山犬', 240: 'Appenzeller狗', 241: 'EntleBucher狗', 242: '拳师狗', 243: '斗牛獒', 244: '藏獒', 245: '法国斗牛犬', 246: '大丹犬', 247: '圣伯纳德狗', 248: '爱斯基摩犬,哈士奇', 249: '雪橇犬,阿拉斯加爱斯基摩狗', 250: '哈士奇', 251: '达尔马提亚,教练车狗', 252: '狮毛狗', 253: '巴辛吉狗', 254: '哈巴狗,狮子狗', 255: '莱昂贝格狗', 256: '纽芬兰岛狗', 257: '大白熊犬', 258: '萨摩耶犬', 259: '博美犬', 260: '松狮,松狮', 261: '荷兰卷尾狮毛狗', 262: '布鲁塞尔格林芬犬', 263: '彭布洛克威尔士科基犬', 264: '威尔士柯基犬', 265: '玩具贵宾犬', 266: '迷你贵宾犬', 267: '标准贵宾犬', 268: '墨西哥无毛犬', 269: '灰狼', 270: '白狼,北极狼', 271: '红太狼,鬃狼,犬犬鲁弗斯', 272: '狼,草原狼,刷狼,郊狼', 273: '澳洲野狗,澳大利亚野犬', 274: '豺', 275: '非洲猎犬,土狼犬', 276: '鬣狗', 277: '红狐狸', 278: '沙狐', 279: '北极狐狸,白狐狸', 280: '灰狐狸', 281: '虎斑猫', 282: '山猫,虎猫', 283: '波斯猫', 284: '暹罗暹罗猫,', 285: '埃及猫', 286: '美洲狮,美洲豹', 287: '猞猁,山猫', 288: '豹子', 289: '雪豹', 290: '美洲虎', 291: '狮子', 292: '老虎', 293: '猎豹', 294: '棕熊', 295: '美洲黑熊', 296: '冰熊,北极熊', 297: '懒熊', 298: '猫鼬', 299: '猫鼬,海猫', 300: '虎甲虫', 301: '瓢虫', 302: '土鳖虫', 303: '天牛', 304: '龟甲虫', 305: '粪甲虫', 306: '犀牛甲虫', 307: '象甲', 308: '苍蝇', 309: '蜜蜂', 310: '蚂蚁', 311: '蚱蜢', 312: '蟋蟀', 313: '竹节虫', 314: '蟑螂', 315: '螳螂', 316: '蝉', 317: '叶蝉', 318: '草蜻蛉', 319: '蜻蜓', 320: '豆娘,蜻蛉', 321: '优红蛱蝶', 322: '小环蝴蝶', 323: '君主蝴蝶,大斑蝶', 324: '菜粉蝶', 325: '白蝴蝶', 326: '灰蝶', 327: '海星', 328: '海胆', 329: '海参,海黄瓜', 330: '野兔', 331: '兔', 332: '安哥拉兔', 333: '仓鼠', 334: '刺猬,豪猪,', 335: '黑松鼠', 336: '土拨鼠', 337: '海狸', 338: '豚鼠,豚鼠', 339: '栗色马', 340: '斑马', 341: '猪', 342: '野猪', 343: '疣猪', 344: '河马', 345: '牛', 346: '水牛,亚洲水牛', 347: '野牛', 348: '公羊', 349: '大角羊,洛矶山大角羊', 350: '山羊', 351: '狷羚', 352: '黑斑羚', 353: '瞪羚', 354: '阿拉伯单峰骆驼,骆驼', 355: '骆驼', 356: '黄鼠狼', 357: '水貂', 358: '臭猫', 359: '黑足鼬', 360: '水獭', 361: '臭鼬,木猫', 362: '獾', 363: '犰狳', 364: '树懒', 365: '猩猩,婆罗洲猩猩', 366: '大猩猩', 367: '黑猩猩', 368: '长臂猿', 369: '合趾猿长臂猿,合趾猿', 370: '长尾猴', 371: '赤猴', 372: '狒狒', 373: '恒河猴,猕猴', 374: '白头叶猴', 375: '疣猴', 376: '长鼻猴', 377: '狨(美洲产小型长尾猴)', 378: '卷尾猴', 379: '吼猴', 380: '伶猴', 381: '蜘蛛猴', 382: '松鼠猴', 383: '马达加斯加环尾狐猴,鼠狐猴', 384: '大狐猴,马达加斯加大狐猴', 385: '印度大象,亚洲象', 386: '非洲象,非洲象', 387: '小熊猫', 388: '大熊猫', 389: '杖鱼', 390: '鳗鱼', 391: '银鲑,银鲑鱼', 392: '三色刺蝶鱼', 393: '海葵鱼', 394: '鲟鱼', 395: '雀鳝', 396: '狮子鱼', 397: '河豚', 398: '算盘', 399: '长袍', 400: '学位袍', 401: '手风琴', 402: '原声吉他', 403: '航空母舰', 404: '客机', 405: '飞艇', 406: '祭坛', 407: '救护车', 408: '水陆两用车', 409: '模拟时钟', 410: '蜂房', 411: '围裙', 412: '垃圾桶', 413: '攻击步枪,枪', 414: '背包', 415: '面包店,面包铺,', 416: '平衡木', 417: '热气球', 418: '圆珠笔', 419: '创可贴', 420: '班卓琴', 421: '栏杆,楼梯扶手', 422: '杠铃', 423: '理发师的椅子', 424: '理发店', 425: '牲口棚', 426: '晴雨表', 427: '圆筒', 428: '园地小车,手推车', 429: '棒球', 430: '篮球', 431: '婴儿床', 432: '巴松管,低音管', 433: '游泳帽', 434: '沐浴毛巾', 435: '浴缸,澡盆', 436: '沙滩车,旅行车', 437: '灯塔', 438: '高脚杯', 439: '熊皮高帽', 440: '啤酒瓶', 441: '啤酒杯 ', 442: '钟塔', 443: '(小儿用的)围嘴', 444: '串联自行车,', 445: '比基尼', 446: '装订册', 447: '双筒望远镜', 448: '鸟舍', 449: '船库', 450: '雪橇', 451: '饰扣式领带', 452: '阔边女帽', 453: '书橱', 454: '书店,书摊', 455: '瓶盖', 456: '弓箭', 457: '蝴蝶结领结', 458: '铜制牌位', 459: '奶罩', 460: '防波堤,海堤', 461: '铠甲', 462: '扫帚', 463: '桶', 464: '扣环', 465: '防弹背心', 466: '动车,子弹头列车', 467: '肉铺,肉菜市场', 468: '出租车', 469: '大锅', 470: '蜡烛', 471: '大炮', 472: '独木舟', 473: '开瓶器,开罐器', 474: '开衫', 475: '车镜', 476: '旋转木马', 477: '木匠的工具包,工具包', 478: '纸箱', 479: '车轮', 480: '取款机,自动取款机', 481: '盒式录音带', 482: '卡带播放器', 483: '城堡', 484: '双体船', 485: 'CD播放器', 486: '大提琴', 487: '移动电话,手机', 488: '铁链', 489: '围栏', 490: '链甲', 491: '电锯,油锯', 492: '箱子', 493: '衣柜,洗脸台', 494: '编钟,钟,锣', 495: '中国橱柜', 496: '圣诞袜', 497: '教堂,教堂建筑', 498: '电影院,剧场', 499: '切肉刀,菜刀', 500: '悬崖屋', 501: '斗篷', 502: '木屐,木鞋', 503: '鸡尾酒调酒器', 504: '咖啡杯', 505: '咖啡壶', 506: '螺旋结构(楼梯)', 507: '组合锁', 508: '电脑键盘,键盘', 509: '糖果,糖果店', 510: '集装箱船', 511: '敞篷车', 512: '开瓶器,瓶螺杆', 513: '短号,喇叭', 514: '牛仔靴', 515: '牛仔帽', 516: '摇篮', 517: '起重机', 518: '头盔', 519: '板条箱', 520: '小儿床', 521: '砂锅', 522: '槌球', 523: '拐杖', 524: '胸甲', 525: '大坝,堤防', 526: '书桌', 527: '台式电脑', 528: '有线电话', 529: '尿布湿', 530: '数字时钟', 531: '数字手表', 532: '餐桌板', 533: '抹布', 534: '洗碗机,洗碟机', 535: '盘式制动器', 536: '码头,船坞,码头设施', 537: '狗拉雪橇', 538: '圆顶', 539: '门垫,垫子', 540: '钻井平台,海上钻井', 541: '鼓,乐器,鼓膜', 542: '鼓槌', 543: '哑铃', 544: '荷兰烤箱', 545: '电风扇,鼓风机', 546: '电吉他', 547: '电力机车', 548: '电视,电视柜', 549: '信封', 550: '浓缩咖啡机', 551: '扑面粉', 552: '女用长围巾', 553: '文件,文件柜,档案柜', 554: '消防船', 555: '消防车', 556: '火炉栏', 557: '旗杆', 558: '长笛', 559: '折叠椅', 560: '橄榄球头盔', 561: '叉车', 562: '喷泉', 563: '钢笔', 564: '有四根帷柱的床', 565: '运货车厢', 566: '圆号,喇叭', 567: '煎锅', 568: '裘皮大衣', 569: '垃圾车', 570: '防毒面具,呼吸器', 571: '汽油泵', 572: '高脚杯', 573: '卡丁车', 574: '高尔夫球', 575: '高尔夫球车', 576: '狭长小船', 577: '锣', 578: '礼服', 579: '钢琴', 580: '温室,苗圃', 581: '散热器格栅', 582: '杂货店,食品市场', 583: '断头台', 584: '小发夹', 585: '头发喷雾', 586: '半履带装甲车', 587: '锤子', 588: '大篮子', 589: '手摇鼓风机,吹风机', 590: '手提电脑', 591: '手帕', 592: '硬盘', 593: '口琴,口风琴', 594: '竖琴', 595: '收割机', 596: '斧头', 597: '手枪皮套', 598: '家庭影院', 599: '蜂窝', 600: '钩爪', 601: '衬裙', 602: '单杠', 603: '马车', 604: '沙漏', 605: '手机,iPad', 606: '熨斗', 607: '南瓜灯笼', 608: '牛仔裤,蓝色牛仔裤', 609: '吉普车', 610: '运动衫,T恤', 611: '拼图', 612: '人力车', 613: '操纵杆', 614: '和服', 615: '护膝', 616: '蝴蝶结', 617: '大褂,实验室外套', 618: '长柄勺', 619: '灯罩', 620: '笔记本电脑', 621: '割草机', 622: '镜头盖', 623: '开信刀,裁纸刀', 624: '图书馆', 625: '救生艇', 626: '点火器,打火机', 627: '豪华轿车', 628: '远洋班轮', 629: '唇膏,口红', 630: '平底便鞋', 631: '洗剂', 632: '扬声器', 633: '放大镜', 634: '锯木厂', 635: '磁罗盘', 636: '邮袋', 637: '信箱', 638: '女游泳衣', 639: '有肩带浴衣', 640: '窨井盖', 641: '沙球(一种打击乐器)', 642: '马林巴木琴', 643: '面膜', 644: '火柴', 645: '花柱', 646: '迷宫', 647: '量杯', 648: '药箱', 649: '巨石,巨石结构', 650: '麦克风', 651: '微波炉', 652: '军装', 653: '奶桶', 654: '迷你巴士', 655: '迷你裙', 656: '面包车', 657: '导弹', 658: '连指手套', 659: '搅拌钵', 660: '活动房屋(由汽车拖拉的)', 661: 'T型发动机小汽车', 662: '调制解调器', 663: '修道院', 664: '显示器', 665: '电瓶车', 666: '砂浆', 667: '学士', 668: '清真寺', 669: '蚊帐', 670: '摩托车', 671: '山地自行车', 672: '登山帐', 673: '鼠标,电脑鼠标', 674: '捕鼠器', 675: '搬家车', 676: '口套', 677: '钉子', 678: '颈托', 679: '项链', 680: '乳头(瓶)', 681: '笔记本,笔记本电脑', 682: '方尖碑', 683: '双簧管', 684: '陶笛,卵形笛', 685: '里程表', 686: '滤油器', 687: '风琴,管风琴', 688: '示波器', 689: '罩裙', 690: '牛车', 691: '氧气面罩', 692: '包装', 693: '船桨', 694: '明轮,桨轮', 695: '挂锁,扣锁', 696: '画笔', 697: '睡衣', 698: '宫殿', 699: '排箫,鸣管', 700: '纸巾', 701: '降落伞', 702: '双杠', 703: '公园长椅', 704: '停车收费表,停车计时器', 705: '客车,教练车', 706: '露台,阳台', 707: '付费电话', 708: '基座,基脚', 709: '铅笔盒', 710: '卷笔刀', 711: '香水(瓶)', 712: '培养皿', 713: '复印机', 714: '拨弦片,拨子', 715: '尖顶头盔', 716: '栅栏,栅栏', 717: '皮卡,皮卡车', 718: '桥墩', 719: '存钱罐', 720: '药瓶', 721: '枕头', 722: '乒乓球', 723: '风车', 724: '海盗船', 725: '水罐', 726: '木工刨', 727: '天文馆', 728: '塑料袋', 729: '板架', 730: '犁型铲雪机', 731: '手压皮碗泵', 732: '宝丽来相机', 733: '电线杆', 734: '警车,巡逻车', 735: '雨披', 736: '台球桌', 737: '充气饮料瓶', 738: '花盆', 739: '陶工旋盘', 740: '电钻', 741: '祈祷垫,地毯', 742: '打印机', 743: '监狱', 744: '炮弹,导弹', 745: '投影仪', 746: '冰球', 747: '沙包,吊球', 748: '钱包', 749: '羽管笔', 750: '被子', 751: '赛车', 752: '球拍', 753: '散热器', 754: '收音机', 755: '射电望远镜,无线电反射器', 756: '雨桶', 757: '休闲车,房车', 758: '卷轴,卷筒', 759: '反射式照相机', 760: '冰箱,冰柜', 761: '遥控器', 762: '餐厅,饮食店,食堂', 763: '左轮手枪', 764: '步枪', 765: '摇椅', 766: '电转烤肉架', 767: '橡皮', 768: '橄榄球', 769: '直尺', 770: '跑步鞋', 771: '保险柜', 772: '安全别针', 773: '盐瓶(调味用)', 774: '凉鞋', 775: '纱笼,围裙', 776: '萨克斯管', 777: '剑鞘', 778: '秤,称重机', 779: '校车', 780: '帆船', 781: '记分牌', 782: '屏幕', 783: '螺丝', 784: '螺丝刀', 785: '安全带', 786: '缝纫机', 787: '盾牌,盾牌', 788: '皮鞋店,鞋店', 789: '障子', 790: '购物篮', 791: '购物车', 792: '铁锹', 793: '浴帽', 794: '浴帘', 795: '滑雪板', 796: '滑雪面罩', 797: '睡袋', 798: '滑尺', 799: '滑动门', 800: '角子老虎机', 801: '潜水通气管', 802: '雪橇', 803: '扫雪机,扫雪机', 804: '皂液器', 805: '足球', 806: '袜子', 807: '碟式太阳能,太阳能集热器,太阳能炉', 808: '宽边帽', 809: '汤碗', 810: '空格键', 811: '空间加热器', 812: '航天飞机', 813: '铲(搅拌或涂敷用的)', 814: '快艇', 815: '蜘蛛网', 816: '纺锤,纱锭', 817: '跑车', 818: '聚光灯', 819: '舞台', 820: '蒸汽机车', 821: '钢拱桥', 822: '钢滚筒', 823: '听诊器', 824: '女用披肩', 825: '石头墙', 826: '秒表', 827: '火炉', 828: '过滤器', 829: '有轨电车,电车', 830: '担架', 831: '沙发床', 832: '佛塔', 833: '潜艇,潜水艇', 834: '套装,衣服', 835: '日晷', 836: '太阳镜', 837: '太阳镜,墨镜', 838: '防晒霜,防晒剂', 839: '悬索桥', 840: '拖把', 841: '运动衫', 842: '游泳裤', 843: '秋千', 844: '开关,电器开关', 845: '注射器', 846: '台灯', 847: '坦克,装甲战车,装甲战斗车辆', 848: '磁带播放器', 849: '茶壶', 850: '泰迪,泰迪熊', 851: '电视', 852: '网球', 853: '茅草,茅草屋顶', 854: '幕布,剧院的帷幕', 855: '顶针', 856: '脱粒机', 857: '宝座', 858: '瓦屋顶', 859: '烤面包机', 860: '烟草店,烟草', 861: '马桶', 862: '火炬', 863: '图腾柱', 864: '拖车,牵引车,清障车', 865: '玩具店', 866: '拖拉机', 867: '拖车,铰接式卡车', 868: '托盘', 869: '风衣', 870: '三轮车', 871: '三体船', 872: '三脚架', 873: '凯旋门', 874: '无轨电车', 875: '长号', 876: '浴盆,浴缸', 877: '旋转式栅门', 878: '打字机键盘', 879: '伞', 880: '独轮车', 881: '直立式钢琴', 882: '真空吸尘器', 883: '花瓶', 884: '拱顶', 885: '天鹅绒', 886: '自动售货机', 887: '祭服', 888: '高架桥', 889: '小提琴,小提琴', 890: '排球', 891: '松饼机', 892: '挂钟', 893: '钱包,皮夹', 894: '衣柜,壁橱', 895: '军用飞机', 896: '洗脸盆,洗手盆', 897: '洗衣机,自动洗衣机', 898: '水瓶', 899: '水壶', 900: '水塔', 901: '威士忌壶', 902: '哨子', 903: '假发', 904: '纱窗', 905: '百叶窗', 906: '温莎领带', 907: '葡萄酒瓶', 908: '飞机翅膀,飞机', 909: '炒菜锅', 910: '木制的勺子', 911: '毛织品,羊绒', 912: '栅栏,围栏', 913: '沉船', 914: '双桅船', 915: '蒙古包', 916: '网站,互联网网站', 917: '漫画', 918: '纵横字谜', 919: '路标', 920: '交通信号灯', 921: '防尘罩,书皮', 922: '菜单', 923: '盘子', 924: '鳄梨酱', 925: '清汤', 926: '罐焖土豆烧肉', 927: '蛋糕', 928: '冰淇淋', 929: '雪糕,冰棍,冰棒', 930: '法式面包', 931: '百吉饼', 932: '椒盐脆饼', 933: '芝士汉堡', 934: '热狗', 935: '土豆泥', 936: '结球甘蓝', 937: '西兰花', 938: '菜花', 939: '绿皮密生西葫芦', 940: '西葫芦', 941: '小青南瓜', 942: '南瓜', 943: '黄瓜', 944: '朝鲜蓟', 945: '甜椒', 946: '刺棘蓟', 947: '蘑菇', 948: '绿苹果', 949: '草莓', 950: '橘子', 951: '柠檬', 952: '无花果', 953: '菠萝', 954: '香蕉', 955: '菠萝蜜', 956: '蛋奶冻苹果', 957: '石榴', 958: '干草', 959: '烤面条加干酪沙司', 960: '巧克力酱,巧克力糖浆', 961: '面团', 962: '瑞士肉包,肉饼', 963: '披萨,披萨饼', 964: '馅饼', 965: '卷饼', 966: '红葡萄酒', 967: '意大利浓咖啡', 968: '杯子', 969: '蛋酒', 970: '高山', 971: '泡泡', 972: '悬崖', 973: '珊瑚礁', 974: '间歇泉', 975: '湖边,湖岸', 976: '海角', 977: '沙洲,沙坝', 978: '海滨,海岸', 979: '峡谷', 980: '火山', 981: '棒球,棒球运动员', 982: '新郎', 983: '潜水员', 984: '油菜', 985: '雏菊', 986: '杓兰', 987: '玉米', 988: '橡子', 989: '玫瑰果', 990: '七叶树果实', 991: '珊瑚菌', 992: '木耳', 993: '鹿花菌', 994: '鬼笔菌', 995: '地星(菌类)', 996: '多叶奇果菌', 997: '牛肝菌', 998: '玉米穗', 999: '卫生纸 '}
(480, 640, 3)
<PIL.Image.Image image mode=RGB size=640x480 at 0x1C61D072B50>
torch.Size([1, 1000])
[ERROR:0@12.331] global obsensor_uvc_stream_channel.cpp:159 cv::obsensor::getStreamChannelGroup Camera index out of range
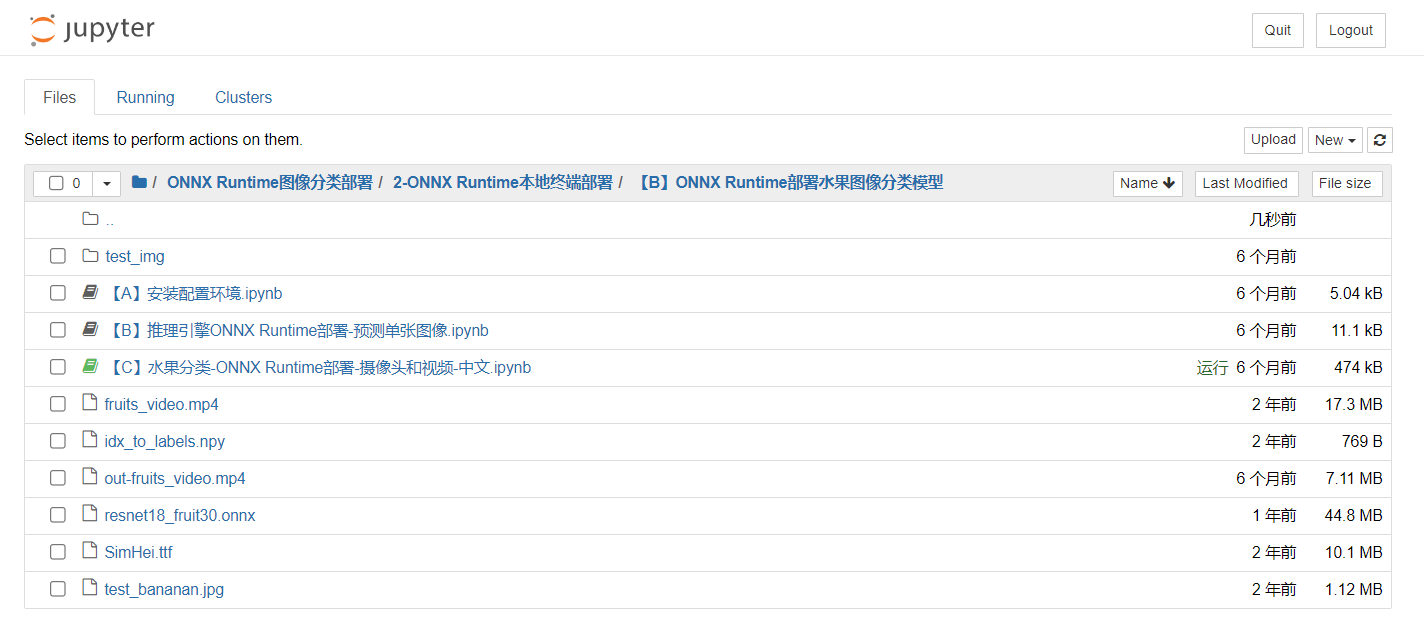
4.附:详细过程查看Jupyter
【A】安装配置环境.ipynb【B1】Pytorch图像分类模型转ONNX-ImageNet1000类.ipynb【B2】Pytorch图像分类模型转ONNX-水果30类.ipynb【Z】扩展阅读.ipynb
【A】安装配置环境.ipynb【B】推理引擎ONNX Runtime部署-预测单张图像.ipynb【C1】ImageNet-ONNX Runtime部署-摄像头和视频-英文.ipynb【C2】ImageNet-ONNX Runtime部署-摄像头和视频-中文.ipynbbanana1.jpgimagenet_class_index.csv
【A】安装配置环境.ipynb【B】推理引擎ONNX Runtime部署-预测单张图像.ipynb【C】水果分类-ONNX Runtime部署-摄像头和视频-中文.ipynbtest_bananan.jpg
二、C++
… …


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}